豆包新模型+PromptPilot深度评测:提示词工程的智能化突破
文章目录
- 豆包新模型+PromptPilot:AI应用开发的新突破
- 一、豆包1.6系列模型解析
- 产品概览
- 1. Doubao-Seed-1.6-thinking | 250715
- 2. Doubao-Seed-1.6-flash | 250715
- 3. 版本对比分析
- 二、PromptPilot智能平台深度解析
- 平台定位与价值
- 核心工作机制
- 三、实战评测:后厨卫生巡检任务
- 评测背景
- 评测流程详解
- 第一步:需求定义与初始Prompt生成
- 第二步:变量优化与Prompt完善
- 第三步:Prompt调试与模型测试
- 第四步:模型回答分析
- 第五步:批量评测与数据收集
- 第六步:评分标准设定与执行
- 第七步:智能优化与效果提升
- 四、测试Prompt
- 五、总结
豆包新模型+PromptPilot:AI应用开发的新突破
豆包新模型+PromptPilot
近期,火山引擎重磅发布了豆包大模型1.6系列以及全新的PromptPilot智能平台,为AI应用开发带来了新的突破。本文将通过详细的实战评测,深入解析这两款产品的核心功能和实际应用效果。
一、豆包1.6系列模型解析
产品概览
豆包大模型1.6是火山引擎于2025年6月11日在FORCE原动力大会上发布的AI大模型,标志着国产大模型在推理能力和应用场景上的重要突破。
体验地址:点击即可体验
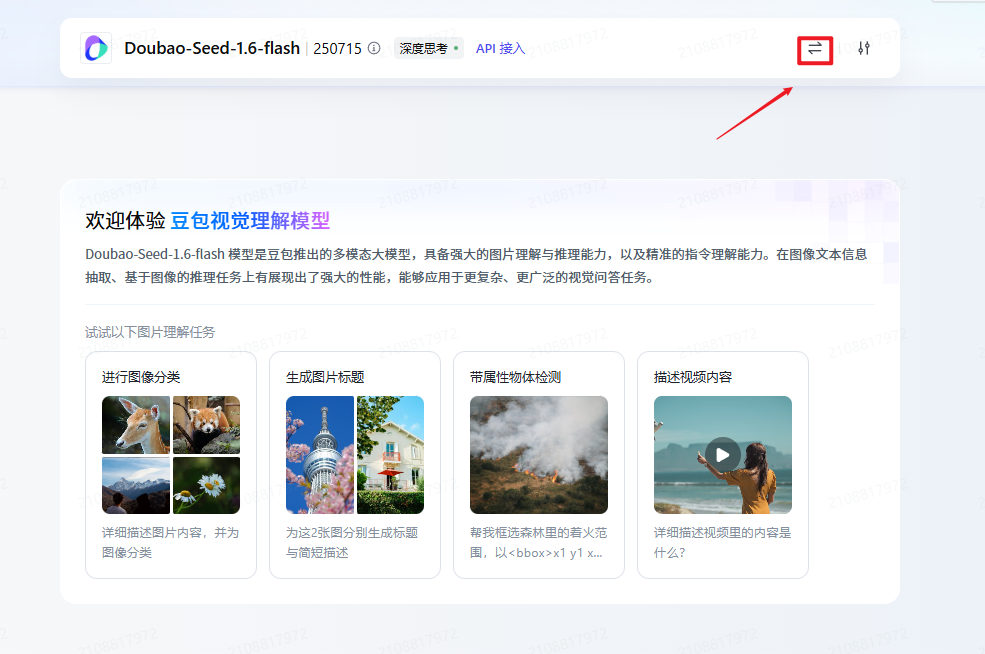
1. Doubao-Seed-1.6-thinking | 250715
核心特性:
- 思考能力大幅强化:对比Doubao-1.5-thinking-pro,在编程、数学、逻辑推理等基础能力上进一步提升
- 多模态支持:支持视觉理解,可处理图像+文本混合任务
- 长文本处理:支持256K上下文窗口,输出长度最大16K tokens
- 适用场景:复杂推理任务、代码生成、数学问题求解
2. Doubao-Seed-1.6-flash | 250715
核心特性:
- 极致推理速度:TPOT仅需10ms,业界领先的响应速度
- 多模态深度思考:同时支持文本和视觉理解
- 能力提升显著:纯文本能力大幅提升近10%,超越上一代lite版本
- 适用场景:实时对话、快速内容生成、高并发应用
3. 版本对比分析
| 特性 | Doubao-Seed-1.6-thinking | Doubao-Seed-1.6-flash |
|---|---|---|
| 推理速度 | 标准 | 极速(10ms TPOT) |
| 思考深度 | 深度推理 | 快速响应 |
| 多模态 | ✅ | ✅ |
| 上下文长度 | 256K | 256K |
| 最大输出 | 16K tokens | 16K tokens |
| 适用场景 | 复杂任务 | 实时应用 |
二、PromptPilot智能平台深度解析
PromptPilot 独立站地址:点击跳转
PromptPilot 用户手册:点击跳转
平台定位与价值
PromptPilot作为专业的提示词优化平台,提供了从生成、调优、评估到管理的全生命周期解决方案,为开发者打造高效的Prompt工程环境。
独立站地址:https://promptpilot.volcengine.com
核心工作机制
优势特点:
- 自动化生成:基于需求描述自动生成初始提示词
- 迭代优化:通过算法自动优化提示词效果
- 数据驱动:基于测试数据和反馈进行智能调整
- 版本管理:每个版本独立管理,支持效果对比
- 限时免费:Plus会员于6.11-9.11限时免费体验
三、实战评测:后厨卫生巡检任务
评测背景
为了全面验证PromptPilot的实际效果,我们选择了具有实际应用价值的后厨卫生巡检场景,准备了20张真实的后厨环境图片进行测试。
评测流程详解
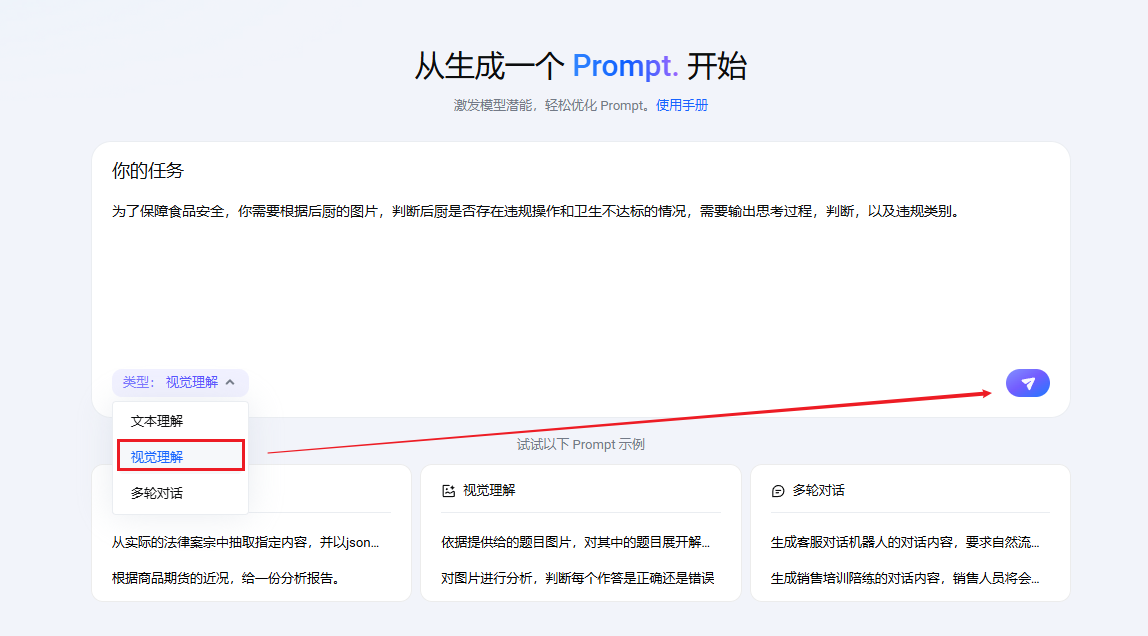
第一步:需求定义与初始Prompt生成
场景描述:
为了保障食品安全,你需要根据后厨的图片,判断后厨是否存在违规操作和卫生不达标的情况,需要输出思考过程,判断,以及违规类别。
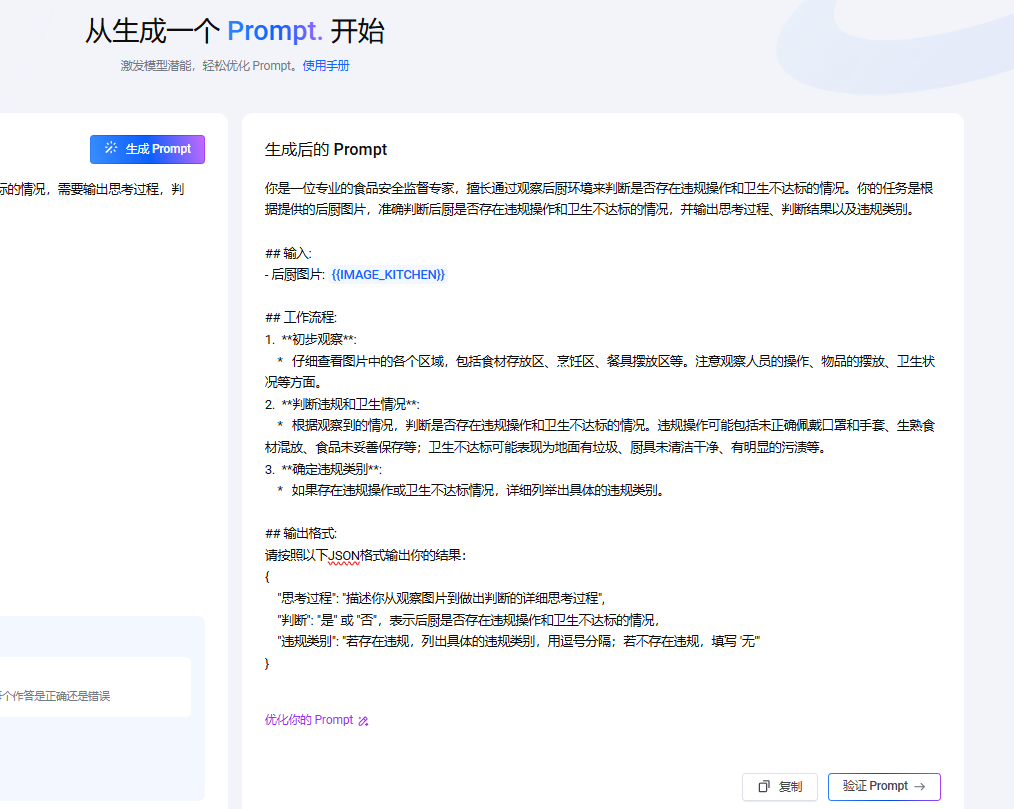
系统生成的初始Prompt:
第二步:变量优化与Prompt完善
变量反馈要求:
变量名字必须是image_url
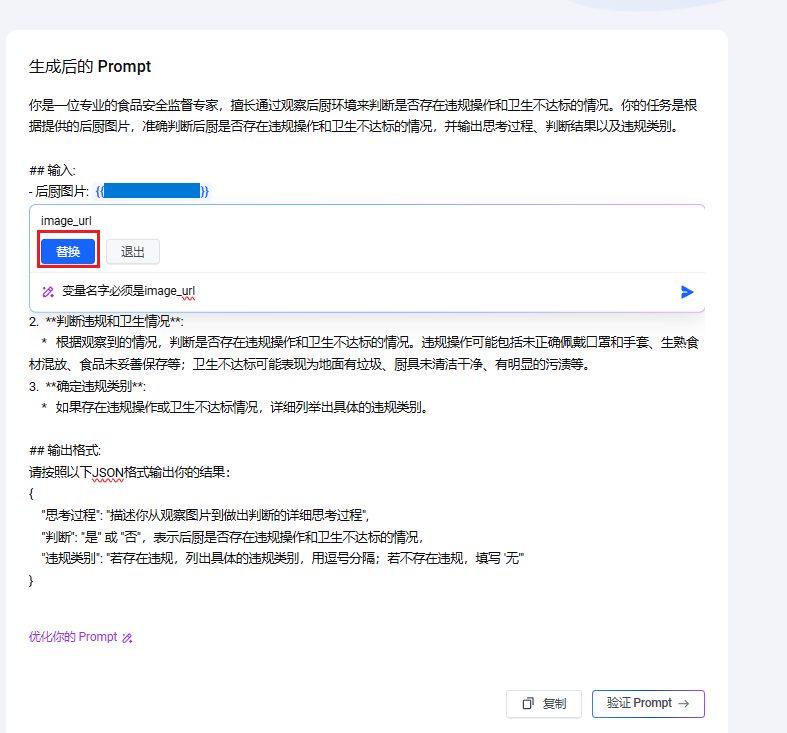
优化后的完整Prompt:
你是一位专业的食品安全监督专家,擅长通过观察后厨环境来判断是否存在违规操作和卫生不达标的情况。你的任务是根据提供的后厨图片,准确判断后厨是否存在违规操作和卫生不达标的情况,并输出思考过程、判断结果以及违规类别。## 输入:
- 后厨图片: {{image_url}}## 工作流程:
1. **初步观察**:* 仔细查看图片中的各个区域,包括食材存放区、烹饪区、餐具摆放区等。注意观察人员的操作、物品的摆放、卫生状况等方面。
2. **判断违规和卫生情况**:* 根据观察到的情况,判断是否存在违规操作和卫生不达标的情况。违规操作可能包括未正确佩戴口罩和手套、生熟食材混放、食品未妥善保存等;卫生不达标可能表现为地面有垃圾、厨具未清洁干净、有明显的污渍等。
3. **确定违规类别**:* 如果存在违规操作或卫生不达标情况,详细列举出具体的违规类别。## 输出格式:
请按照以下JSON格式输出你的结果:
{"思考过程": "描述你从观察图片到做出判断的详细思考过程","判断": "是" 或 "否",表示后厨是否存在违规操作和卫生不达标的情况,"违规类别": "若存在违规,列出具体的违规类别,用逗号分隔;若不存在违规,填写 '无'"
}
第三步:Prompt调试与模型测试
因为我们是对图片进行巡检,所以说我们要选择视觉理解,将刚刚生成的基础Prompt复制进来进行调试,后续我们可以通过上传测试图片来分析模型的回答能力,结合模型回答的内容进行评分持续优化Prompt提示词。
测试图片上传:
图片上传功能支持多种方式,包括本地上传、URL链接、TOS上传等。平台会自动处理图片的格式转换和尺寸调整,确保模型能够正确处理输入数据。
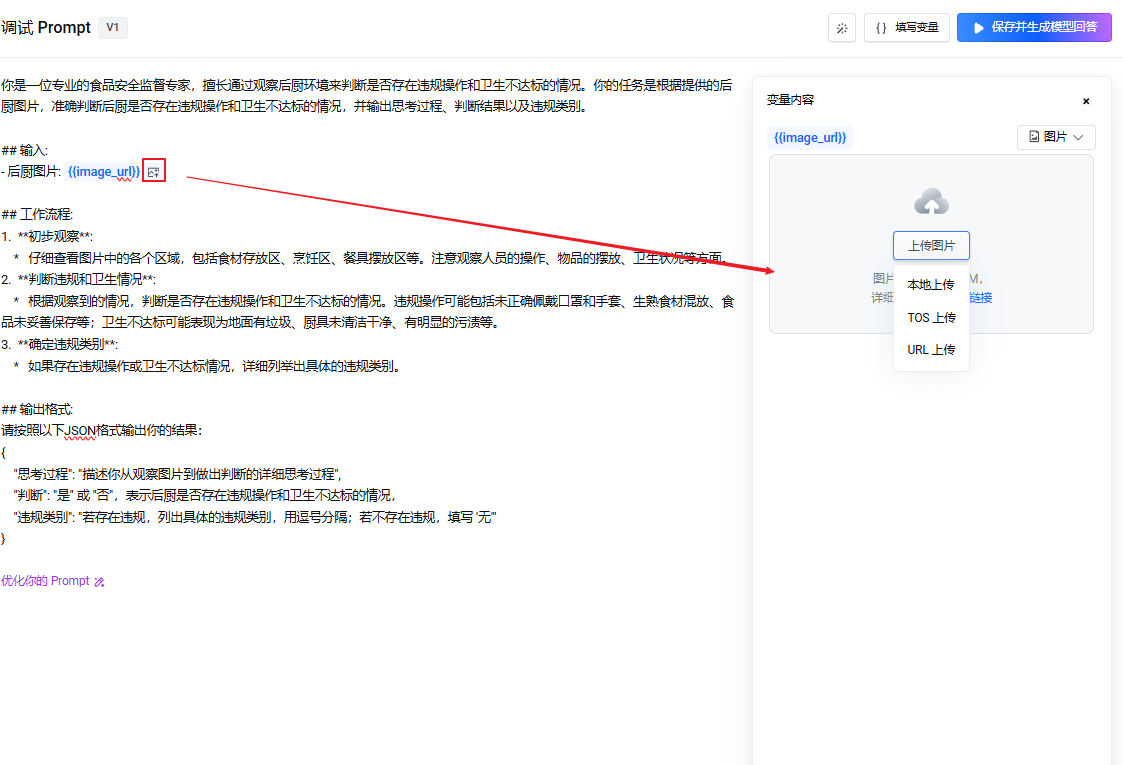
图片展示效果:
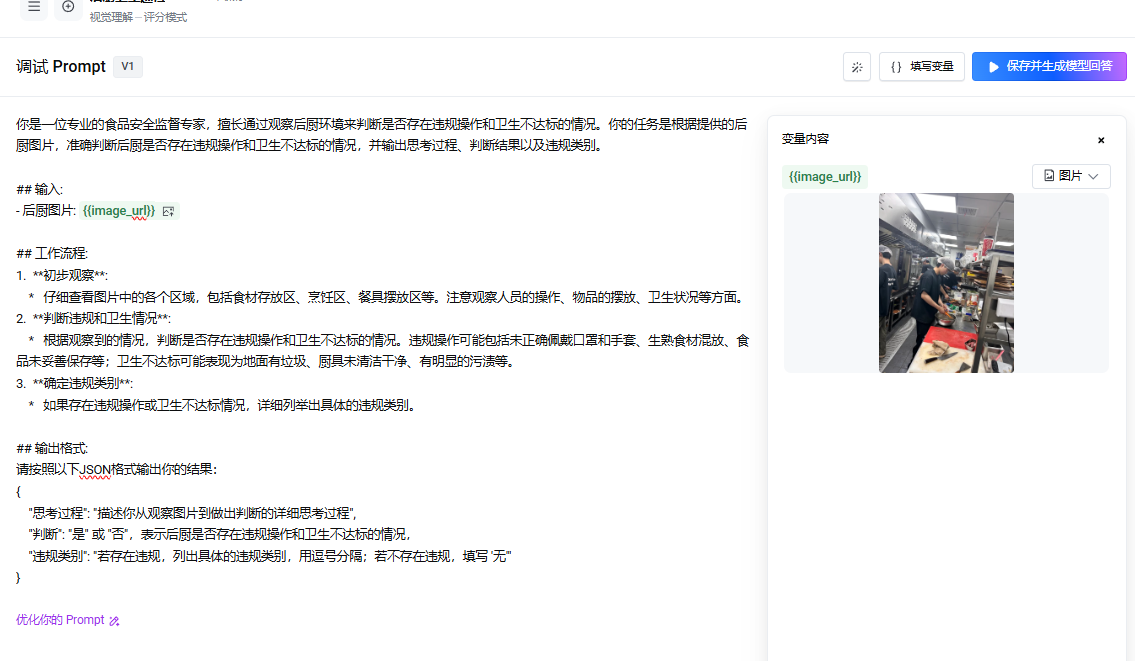
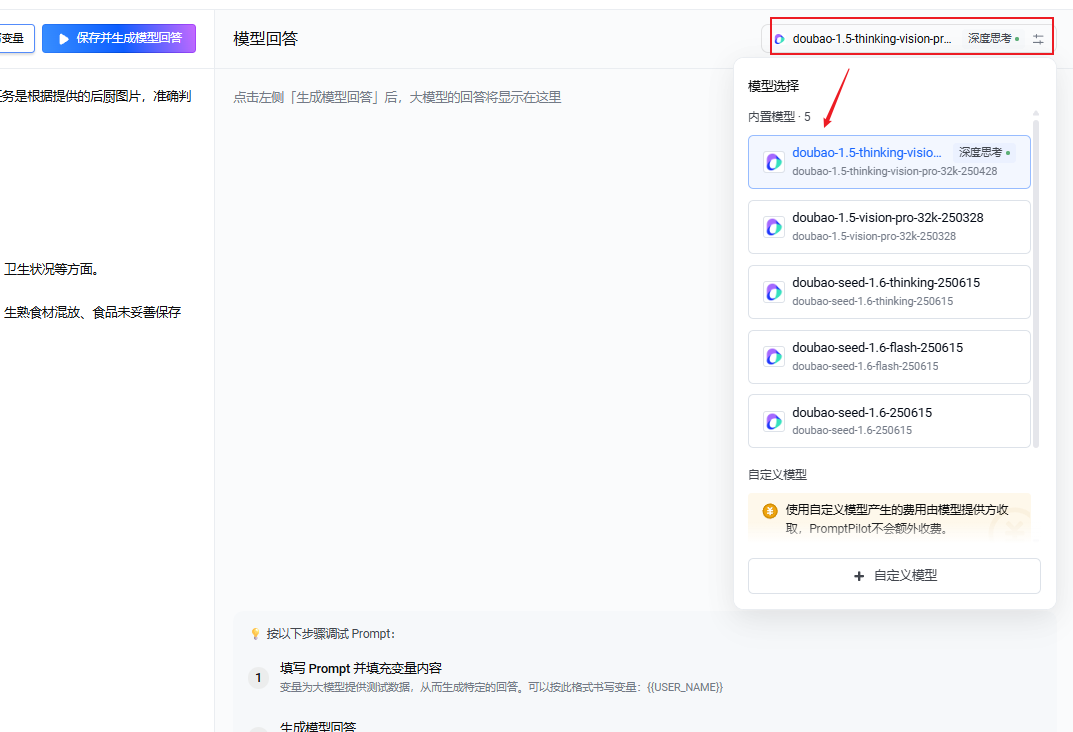
模型选择:
这里的话我们需要选择豆包的thinking模型,带有thinking的模型是多模态模型,可以处理视觉。多模态。多模态大模型的意思就是可以同时解析文本和图像。
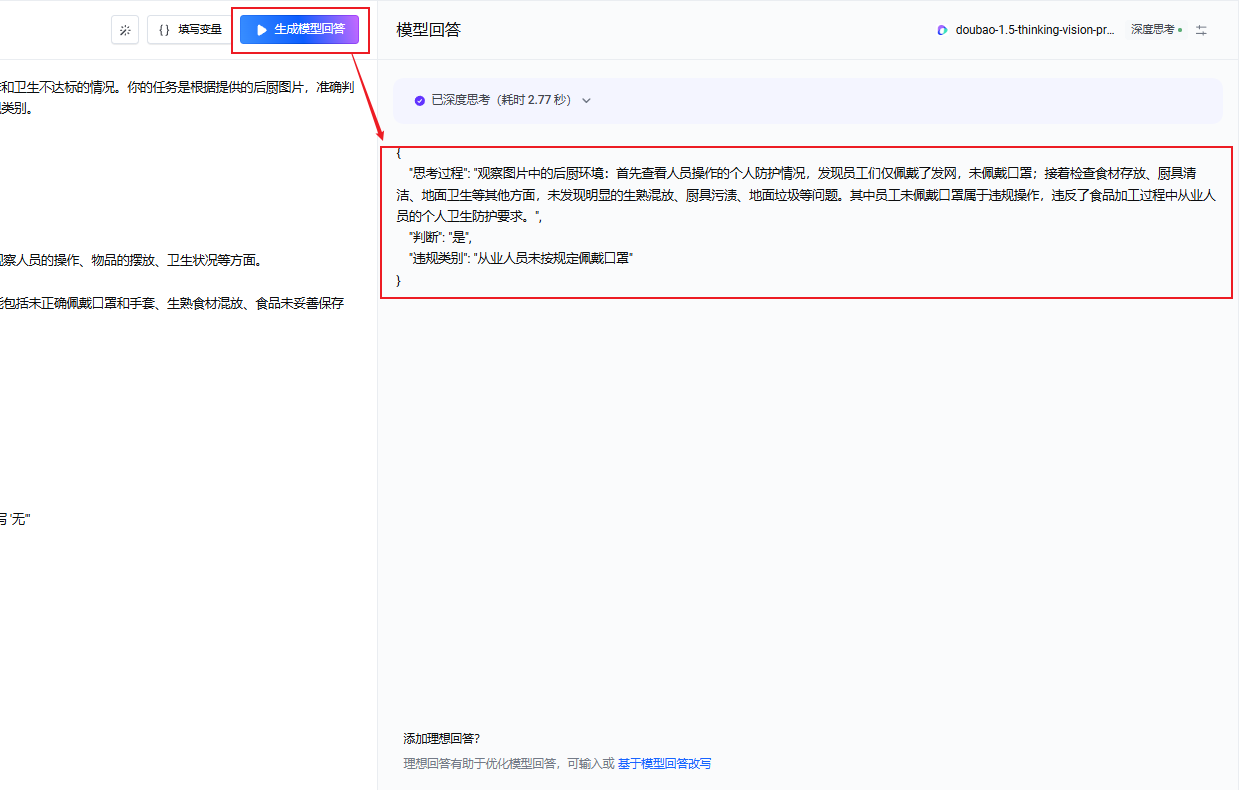
测试执行:
这里我们可以看到模型回答的内容也是相当准确的,后续我们可以通过上传大量的测试内容来优化提示词。这个初步测试的成功为后续的批量优化奠定了基础。它证明了我们的提示词设计是有效的,模型能够理解任务要求并产生有意义的输出。
第四步:模型回答分析
初始测试结果:
这里能看得出来模型不仅准别识别了违规行为,还提供了详细的思考过程,让用户能够理解判断。
{"思考过程": "观察图片中的后厨环境:首先查看人员操作的个人防护情况,发现员工们仅佩戴了发网,未佩戴口罩;接着检查食材存放、厨具清洁、地面卫生等其他方面,未发现明显的生熟混放、厨具污渍、地面垃圾等问题。其中员工未佩戴口罩属于违规操作,违反了食品加工过程中从业人员的个人卫生防护要求。","判断": "是","违规类别": "从业人员未按规定佩戴口罩"
}
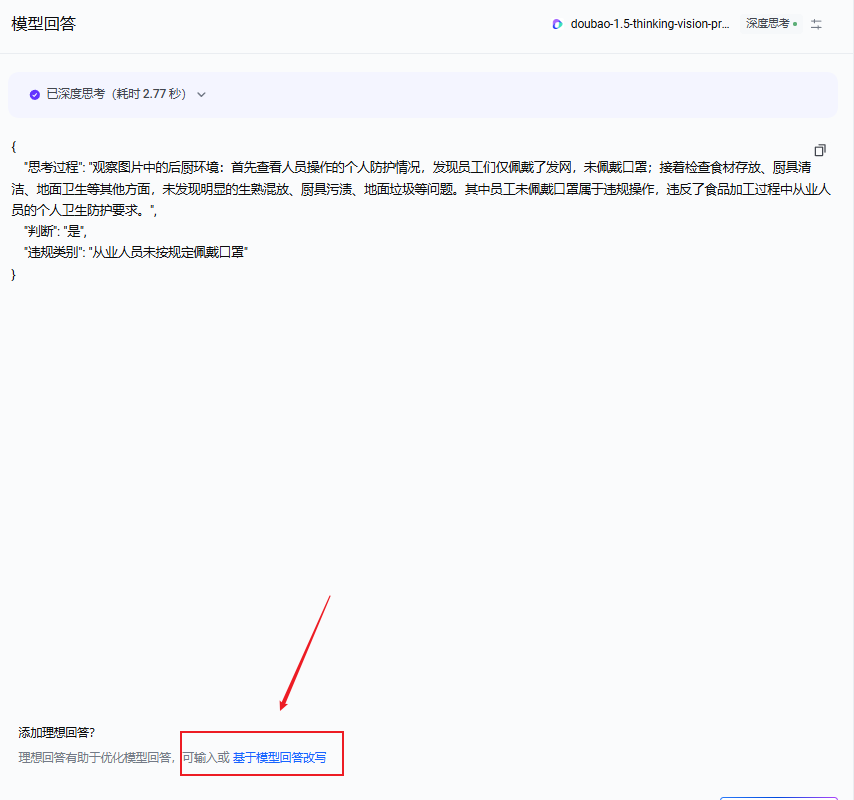
多模型对比:
我们可以点击基于模型回答改写优化模型回答的内容。
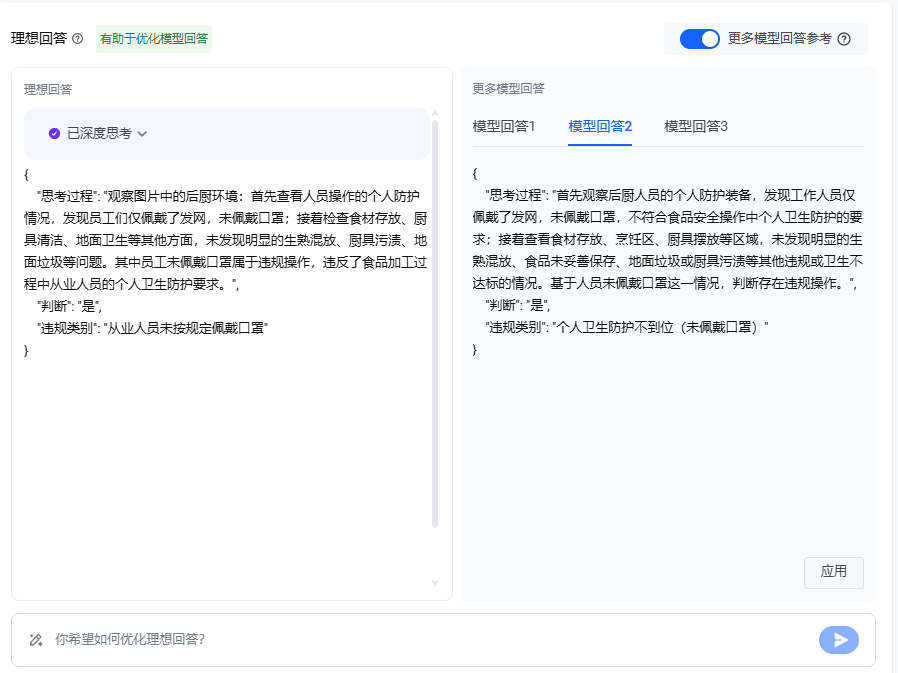
最优答案选择:
这里我们可以对目前的回答进行优化,最优的答案不一定是最详细的,而应该是最符合实际应用需求的。
第五步:批量评测与数据收集
批量数据上传:
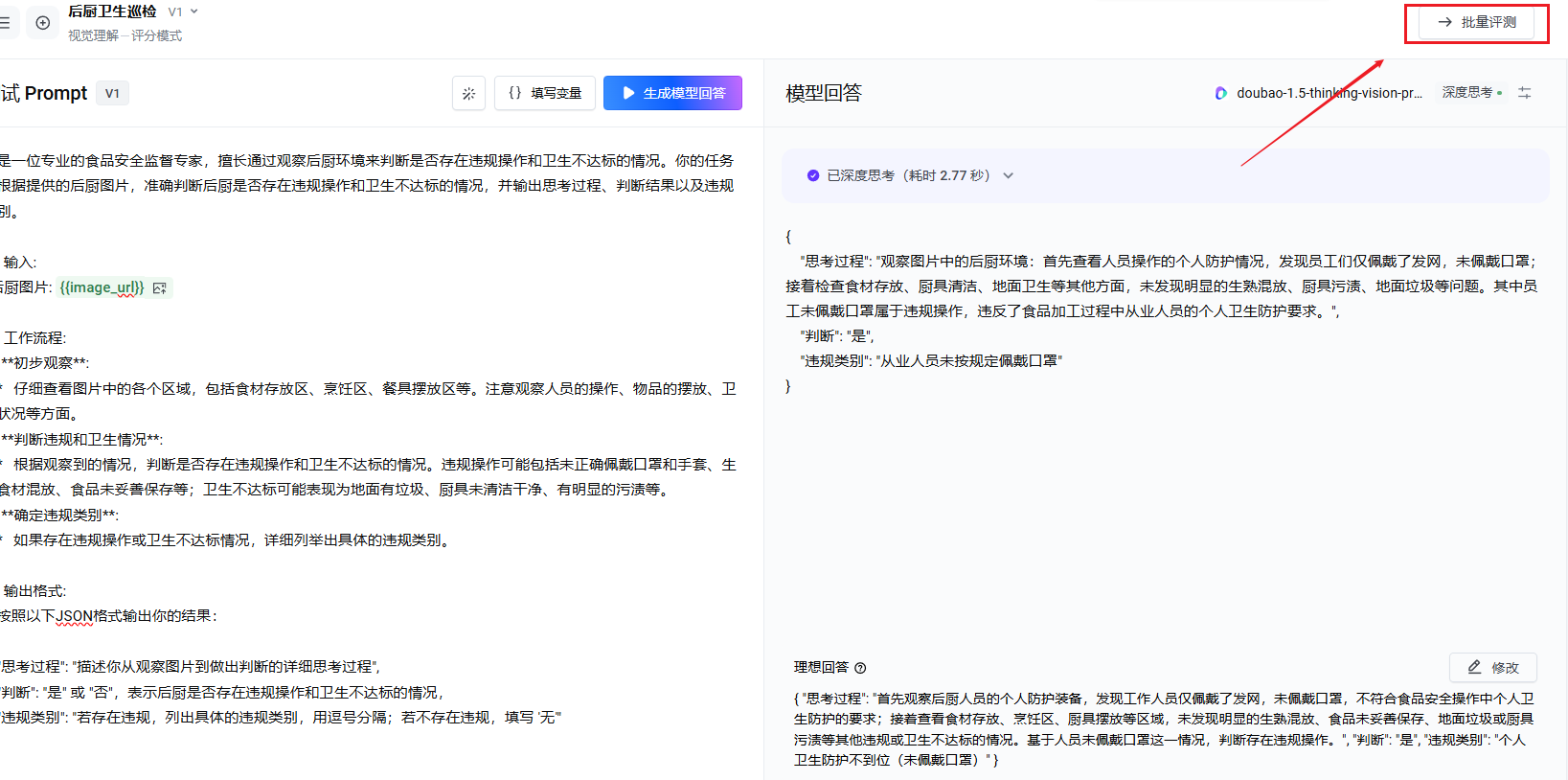
数据集管理:
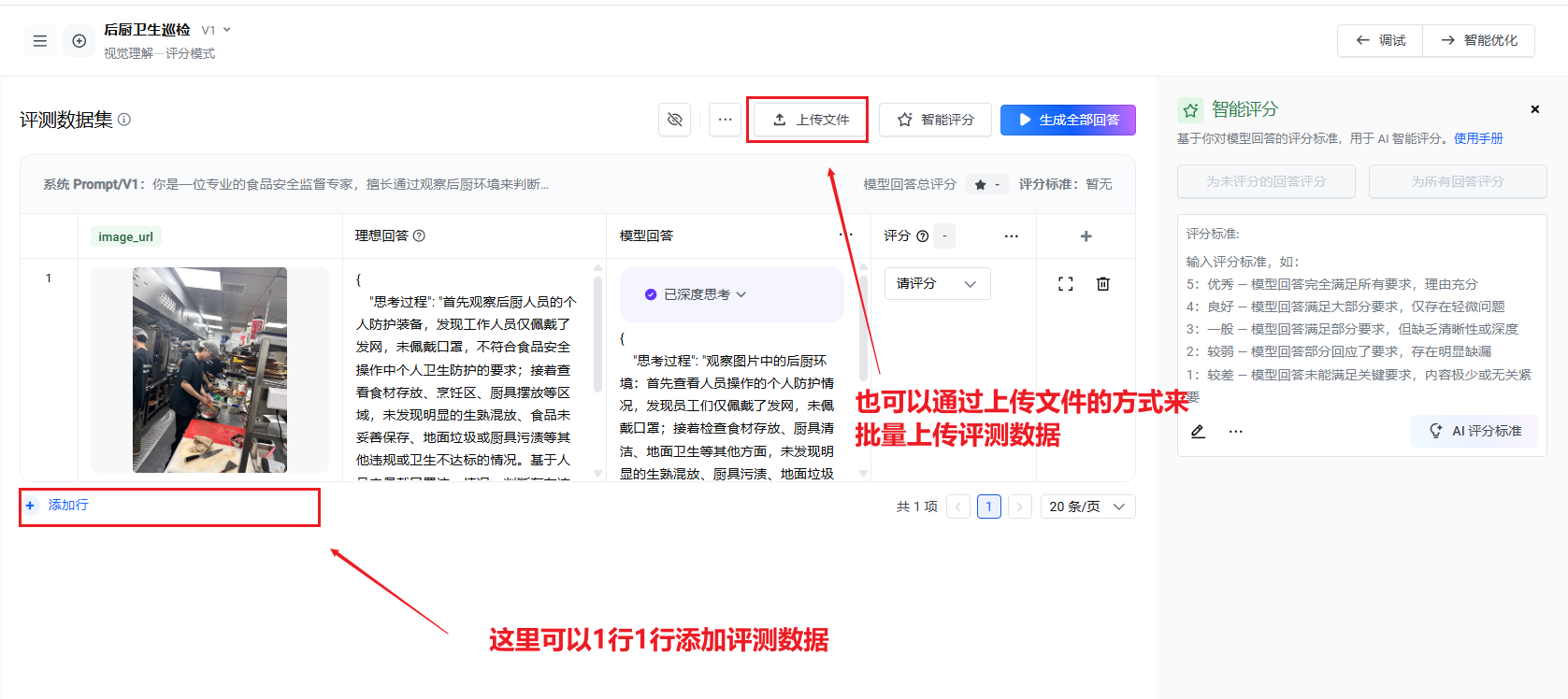
这里我们可以通过添加行的方式或者上传Excel文件批量上传的方式来添加评测数据,我们可以通过大量的样本测试,识别出来提示词的不足,为后续优化提供有针对性的改进方向。
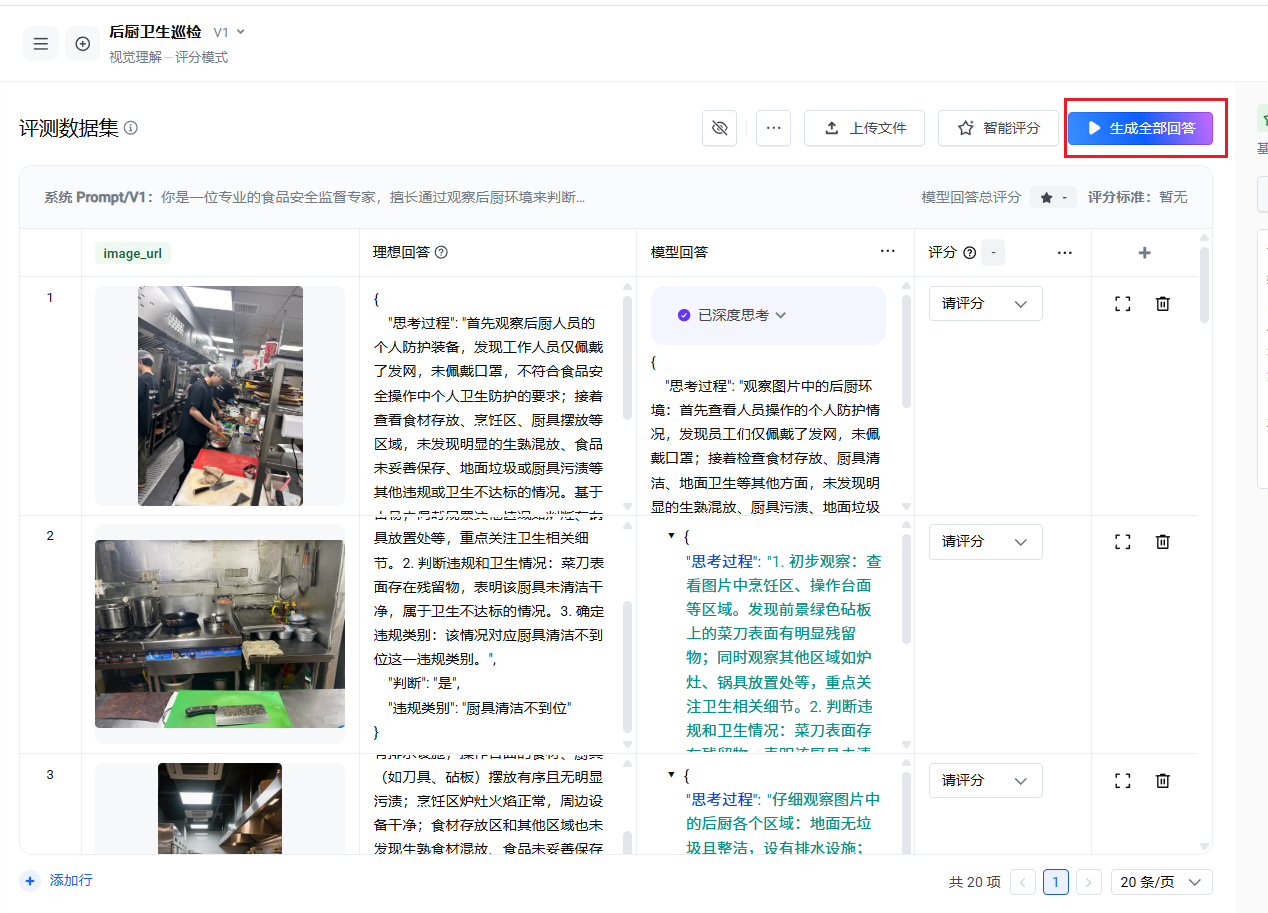
批量生成回答:
这一步是整个评测流程的核心环节。平台会自动将提示词应用到所有测试样本上,生成响应的回答,这个过程完全自动化,用户只需要等待结果就行。
第六步:评分标准设定与执行
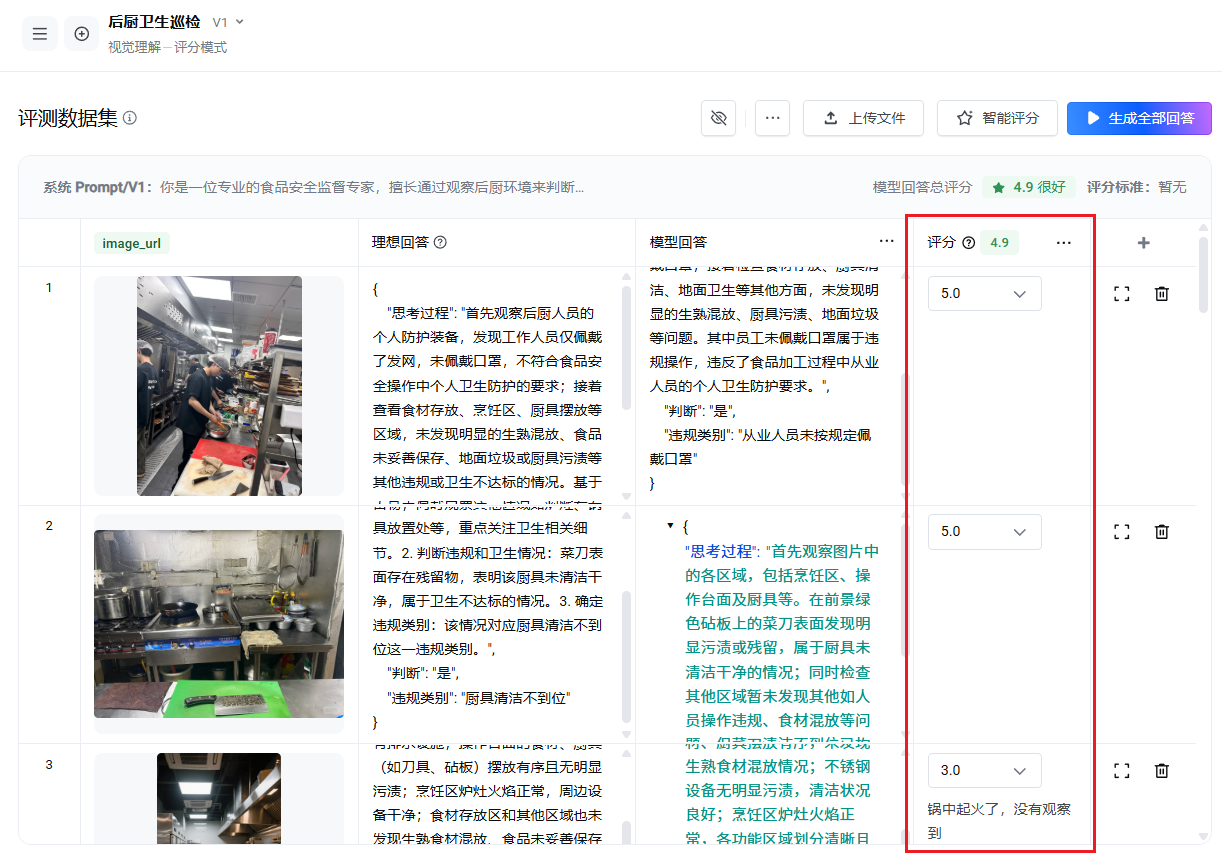
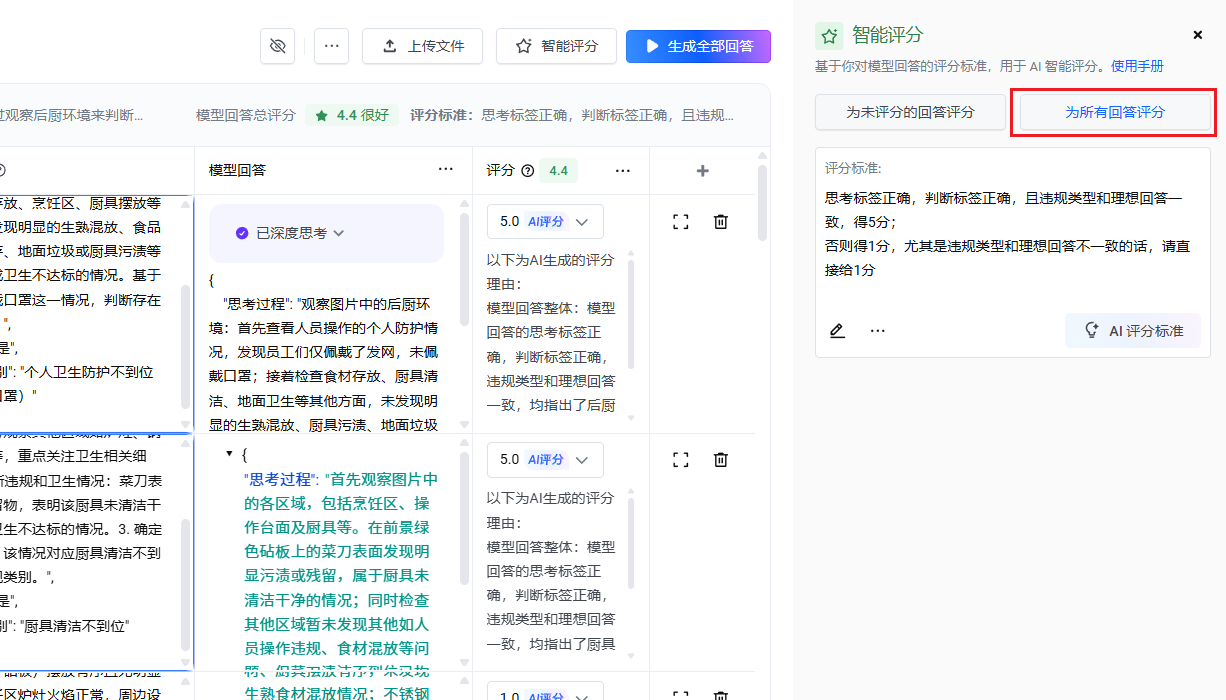
评分机制:
这里我们针对模型的回答进行评分。为后续提示词优化奠定基础。
AI评估标准生成:
这里的AI建议评分标准也是一个非常不错的功能,为什么这么说?因为传统的评分往往需要人工制定详细的评分规则,这不仅耗时耗力,还可能存在主观性问题。AI评估标准能够基于样本数据自动生成客观的评分规则。
这个功能的工作原理是分析数据集的样本数据,识别出高质量回答和低质量回答的特征差异,然后将这些差异转化为可执行的评分规则。这种方法不仅能够提高效率,还确保了评分的一致性。
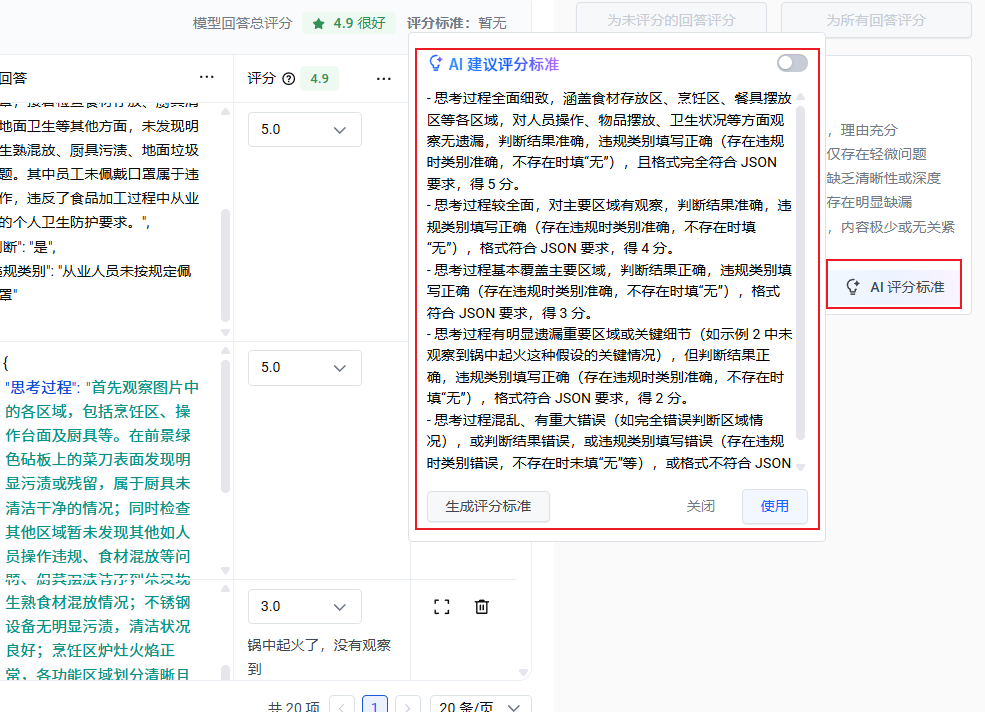
优化后的评估标准:
思考标签正确,判断标签正确,且违规类型和理想回答一致,得5分;
否则得1分,尤其是违规类型和理想回答不一致的话,请直接给1分
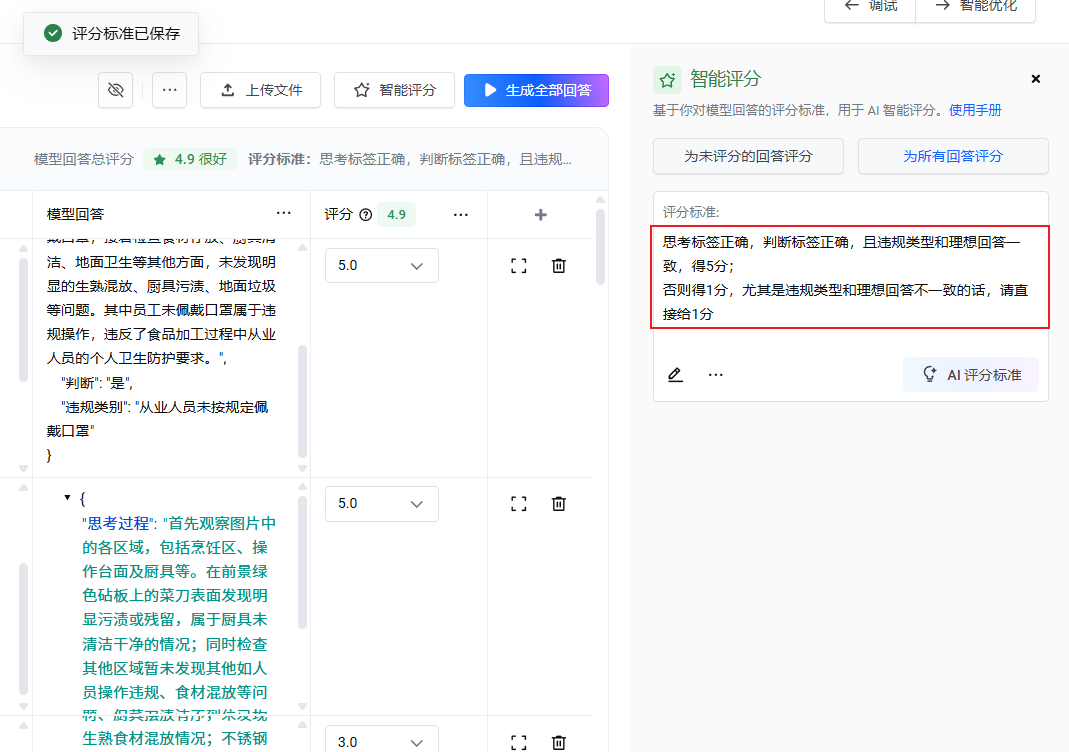
批量评分执行:
第七步:智能优化与效果提升
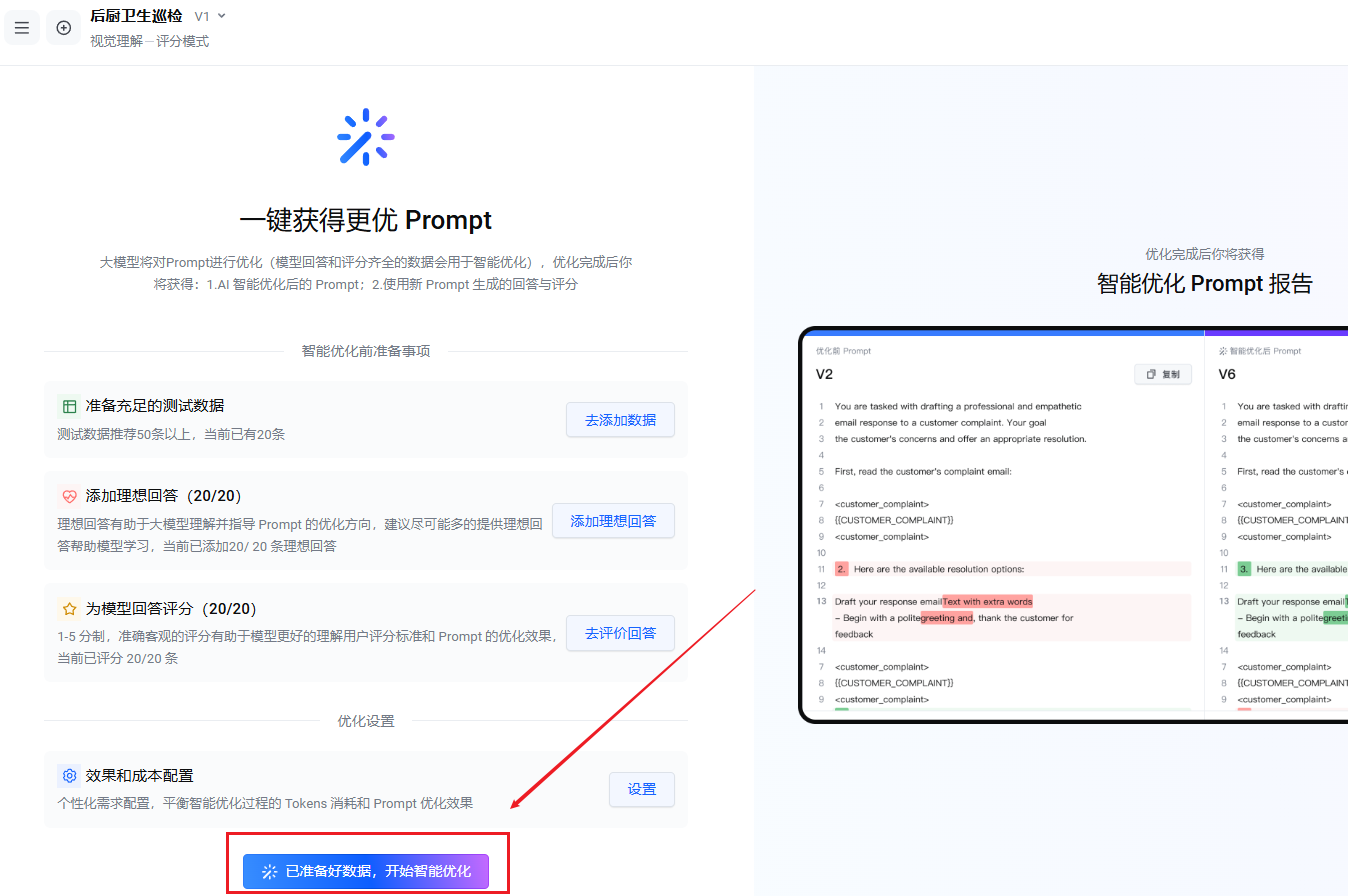
开启智能优化:
智能优化是PromptPilot的核心功能,也是整个平台最具技术含量的部分。这个功能基于机器学习算法,能够自动分析提示词的问题所在,并生成改进建议。相比传统的人工优化方式,智能优化不仅效率更高,而且能够发现人类可能忽略的优化机会。
智能优化算法的工作原理是分析评分数据,识别出低分样本的共同特征,然后针对这些特征对提示词进行调整。这种数据驱动的优化方法确保了改进的针对性和有效性。
在开启智能优化之前,系统会进行必要的数据检查,确保有足够的样本数据和评分信息。如果数据不足,系统会提示用户补充更多的测试样本,以确保优化结果的可靠性。
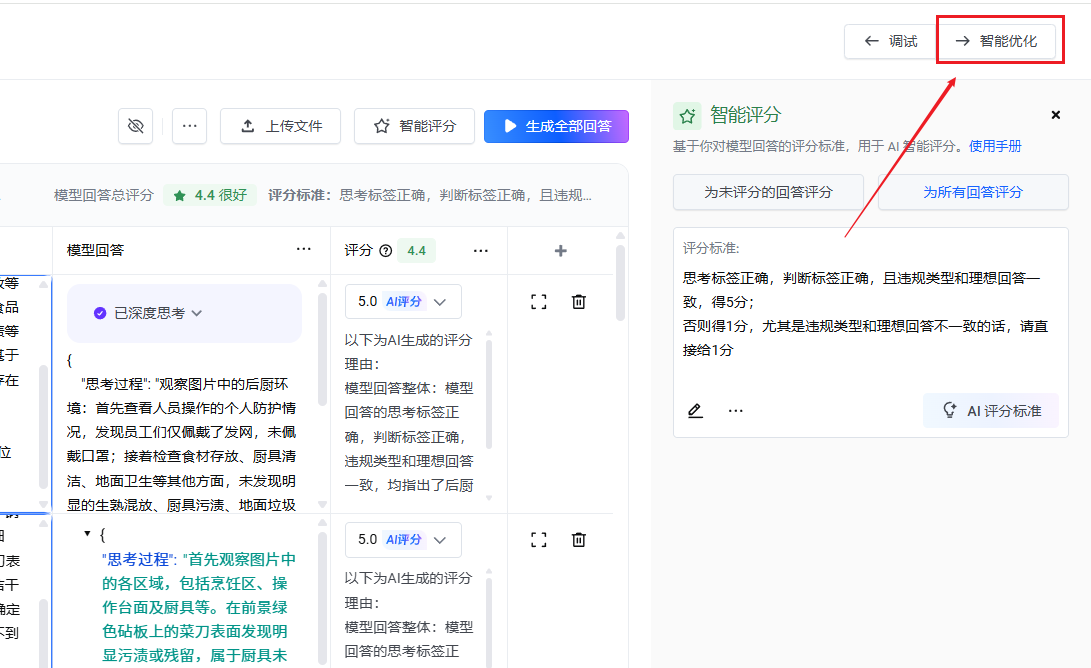
优化过程监控:
优化报告分析: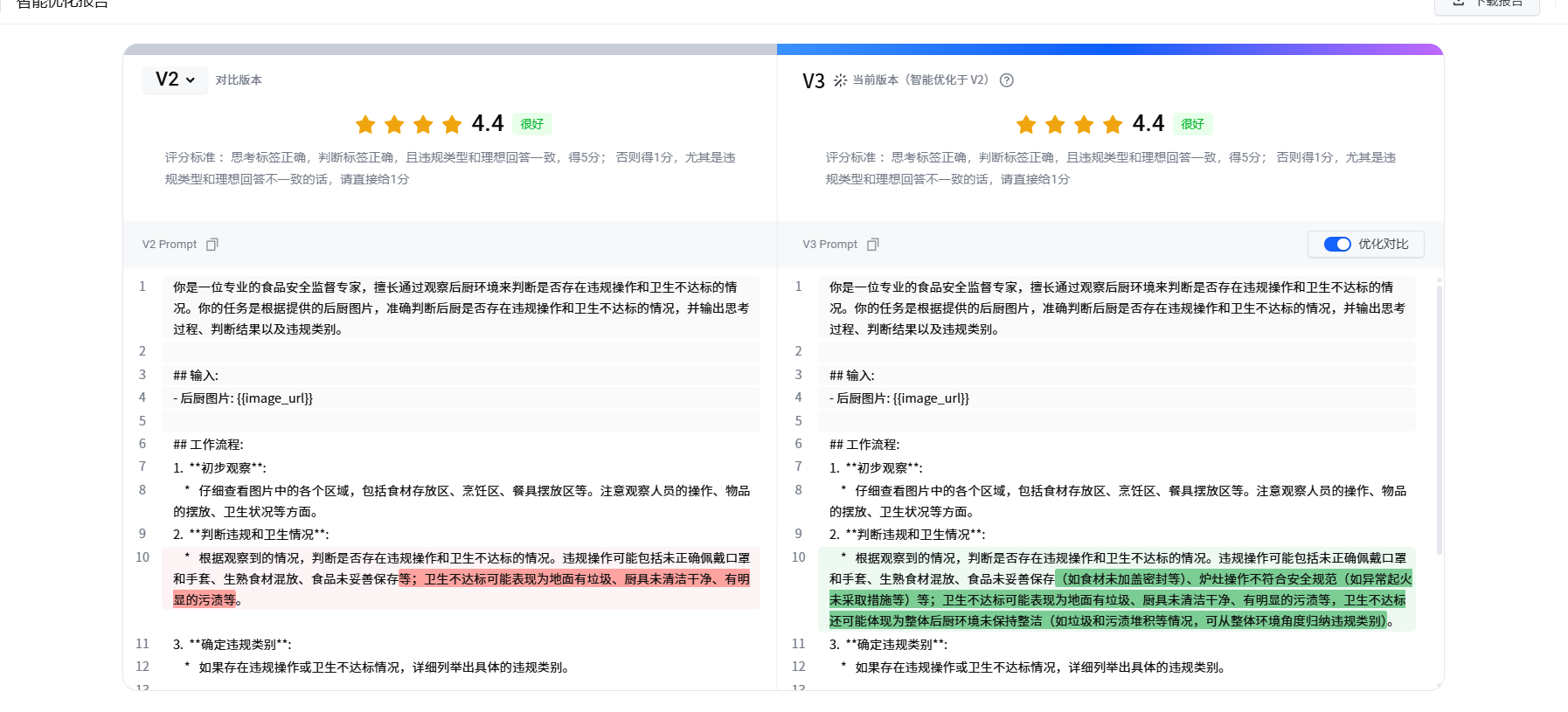
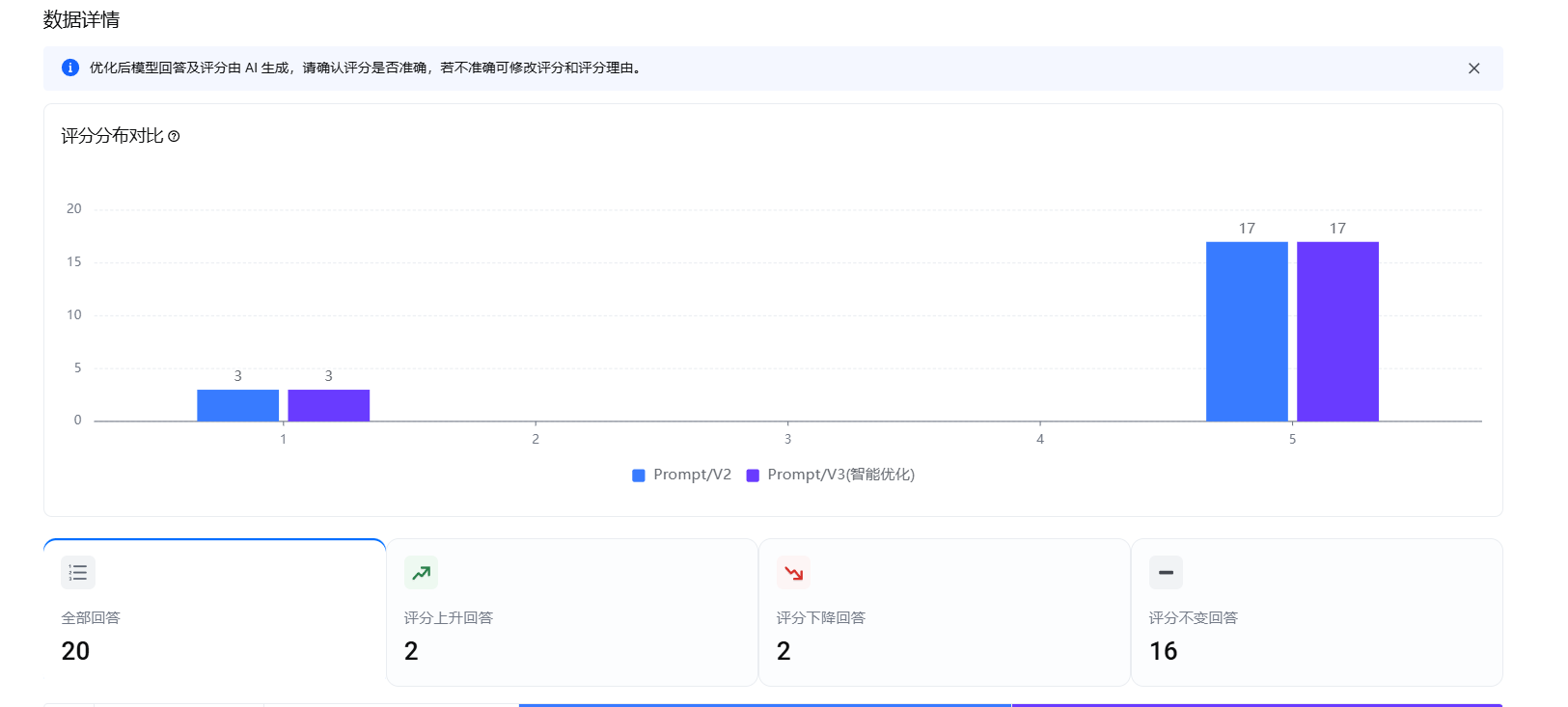
持续优化选项:
我们如果对优化的提示词不满意,可以进行多轮迭代优化,可以不断提升提示词的质量。平台支持在当前优化结果的基础上继续优化,形成螺旋式上升的改进过程。
如果当前效果已经能够满足业务需求的话,就可以停止优化了。如果还有明显的改进空间,则可以继续下一轮优化。
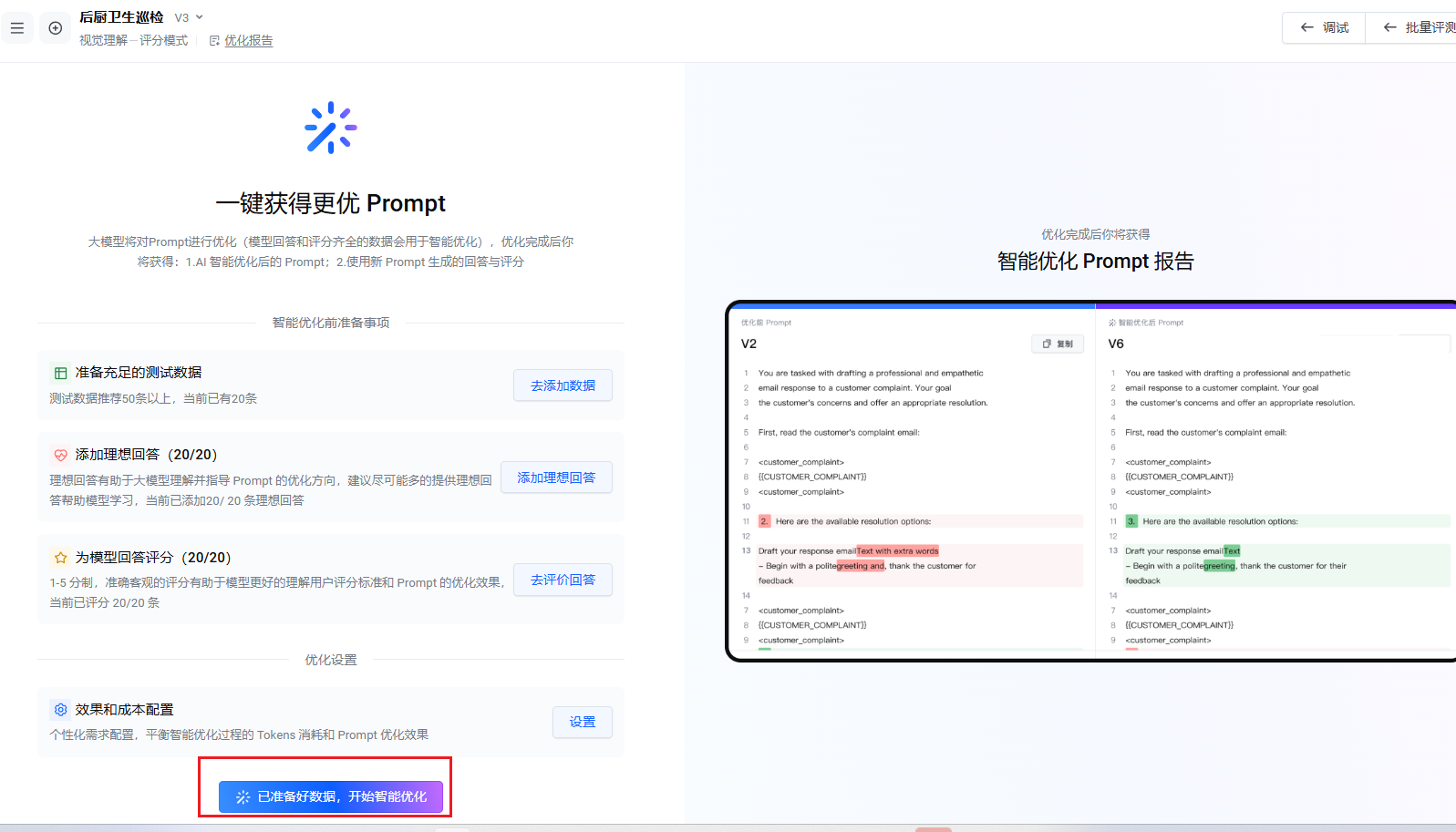
最终Prompt优化结果:
你是一位专业的食品安全监督专家,擅长通过观察后厨环境来判断是否存在违规操作和卫生不达标的情况。你的任务是根据提供的后厨图片,准确判断后厨是否存在违规操作和卫生不达标的情况,并输出思考过程、判断结果以及违规类别。## 输入:
- 后厨图片: {{image_url}}## 工作流程:
1. **初步观察**:* 仔细查看图片中的各个区域,包括食材存放区、烹饪区、餐具摆放区等。注意观察人员的操作、物品的摆放、卫生状况等方面。
2. **判断违规和卫生情况**:* 根据观察到的情况,判断是否存在违规操作和卫生不达标的情况。违规操作可能包括未正确佩戴口罩和手套、生熟食材混放、食品未妥善保存(如食材未加盖密封等)、炉灶操作不符合安全规范(如异常起火未采取措施等)等;卫生不达标可能表现为地面有垃圾、厨具未清洁干净、有明显的污渍等,卫生不达标还可能体现为整体后厨环境未保持整洁(如垃圾和污渍堆积等情况,可从整体环境角度归纳违规类别)。
3. **确定违规类别**:* 如果存在违规操作或卫生不达标情况,详细列举出具体的违规类别。## 输出格式:
请按照以下JSON格式输出你的结果:
{"思考过程": "描述你从观察图片到做出判断的详细思考过程","判断": "是" 或 "否",表示后厨是否存在违规操作和卫生不达标的情况,"违规类别": "若存在违规,列出具体的违规类别,用逗号分隔;若不存在违规,填写 '无'"
}
四、测试Prompt
这里我们基于Doubao-Seed-1.6-thinking|250715去测试我们经过优化的提示词,验证其在实际应用中的表现效果。
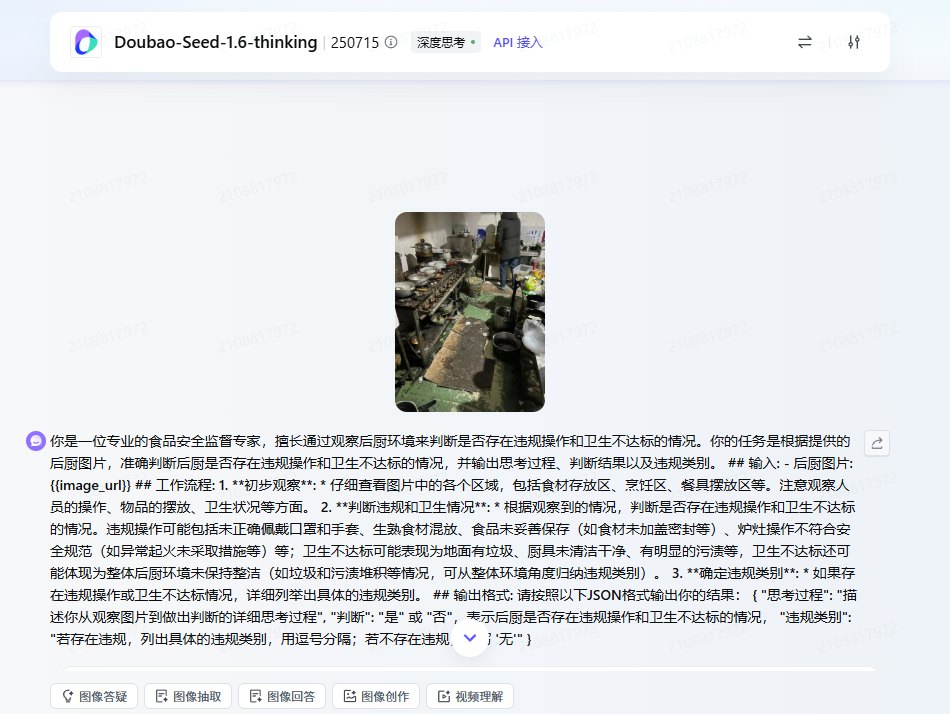
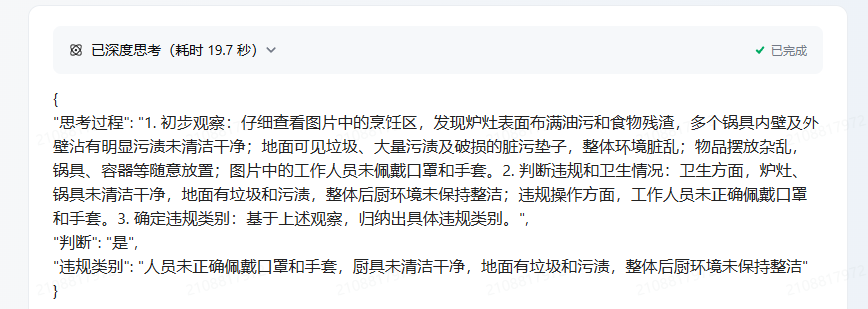
经过PromptPilot智能优化后的提示词在实际测试中表现出色。模型给出的回答格式规范,内容准确:
{"判断": "是","违规类别": "人员未正确佩戴口罩和手套,厨具未清洁干净,地面有垃圾和污渍,整体后厨环境未保持整洁"
}
五、总结
在后厨卫生巡检这个具体场景中,我们见证了从需求描述到提示词完美优化的完整流程。整个过程不仅高效便捷,而且结果准确可靠。这种端到端的解决方案为AI技术在垂直行业的应用提供了很好的范例。
展望未来,随着AI技术的不断发展,我们有理由相信,类似的智能化解决方案将在更多领域得到应用。无论是食品安全、医疗诊断,还是工业检测,AI都将发挥越来越重要的作用。而像PromptPilot这样的平台工具,将大大降低AI应用开发的门槛,让更多的开发者和企业能够享受到AI技术带来的便利。
对于开发者而言,掌握提示词工程技能将变得越来越重要。PromptPilot不仅提供了强大的工具支持,更重要的是,它展示了科学化、系统化进行提示词优化的方法论。这种方法论的价值远超工具本身,将对整个AI应用开发领域产生深远影响。
谢谢大家阅读!