CVPR论文解析:告别Janus问题,text-to-3D更一致!
本文选自gongzhonghao【图灵学术科研岛】
关注我们,掌握更多顶会顶刊发文资讯
3D生成领域常面临几何细节模糊与整体结构连贯性不足的挑战,深度融合隐式表示学习与可控生成机制正成为提升生成质量的关键路径。基于神经辐射场的技术架构能隐式编码场景的多视图一致性信息,精细捕捉物体的连续表面和复杂纹理;而分层条件生成与物理约束的引入则精确引导模型的生成过程,确保结果结构合理且符合语义意图。
这种协同策略在数字孪生建模和创意内容生成中优势显著:既能高保真地恢复细粒度几何,又能赋予对象合理的物理特性和交互逻辑。通过高效采样和模型蒸馏等优化,系统在生成高精度3D内容的同时显著提升响应速度,为元宇宙应用和实时仿真铺平道路。
今天小图给大家精选3篇CVPR 2024有关3D生成的最佳论文,请注意查收!
DreamControl: Control-Based Text-to-3D Generation with 3D Self-Prior
方法:
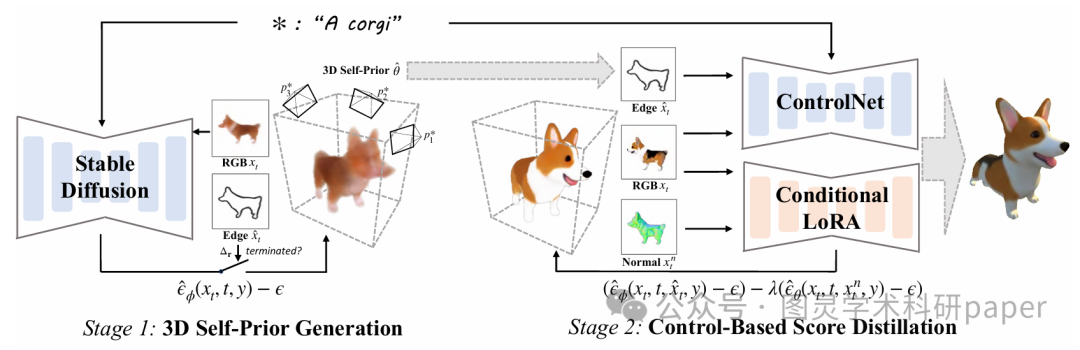
文章首先通过分数蒸馏采样(SDS)优化粗略的 NeRF 场景,将其作为 3D 自先验,在这一阶段,自适应视角采样策略调整了 2D 扩散模型的视角分布,使其与 3D 场景的采样相匹配,同时边界完整性度量用于避免优化过程中的过度拟合问题,从而生成具有良好几何一致性的粗略形状;然后在第二阶段,将 3D 自先验作为条件输入,利用 ControlNet 进行监督,通过控制分数蒸馏进一步优化细节纹理,其中条件 LoRA 和加权分数的引入有效稳定了优化过程,最终实现了高质量的 3D 内容生成。
创新点:
提出了优化神经辐射场(NeRF)作为 3D 自先验的方法,通过自适应视角采样和边界完整性度量来缓解生成结果的不一致性。
引入了基于控制的分数蒸馏技术,利用条件 LoRA 和加权分数来稳定优化过程,从而在保持几何结构的同时生成高质量的纹理细节。
设计了一个两阶段框架,不仅在文本到 3D 生成任务中表现出色,还能够扩展到用户引导的生成和 3D 动画等下游任务,展示了良好的通用性和扩展性。
论文链接:
https://ieeexplore.ieee.org/document/10656670
Consistent3D: Towards Consistent High-Fidelity Text-to-3D Generation with Deterministic Sampling Prior
方法:
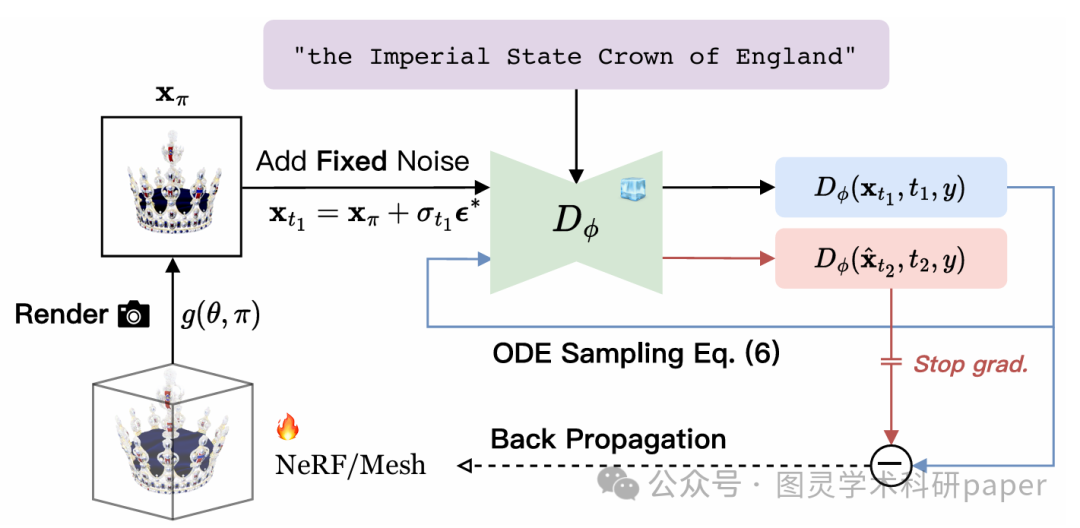
文章首先通过分析SDS与SDE之间的关系,发现SDE的随机性是导致生成不稳定的关键因素。基于此,作者提出了一种新的CDS损失函数,利用与SDE对应的确定性常微分方程(ODE)的轨迹采样来优化3D模型。在每次训练迭代中,先通过预训练的2D扩散模型估计3D模型渲染图像的期望分数函数,然后构建ODE进行轨迹采样,并通过CDS损失函数将确定性采样先验蒸馏到3D模型中。此外,文章还采用了粗到细的两阶段优化策略,包括优化低分辨率的神经辐射场(NeRF)和高分辨率的纹理3D网格,进一步提升了生成效果。
创新点:
首次将分数蒸馏采样(SDS)与随机微分方程(SDE)的轨迹采样联系起来,揭示了SDS中随机性导致生成不稳定的根本原因。
提出了一种新的“一致性蒸馏采样”(CDS)损失函数,通过利用确定性采样先验来优化3D模型,从而为文本到3D生成提供了一种更可靠和一致的指导。
设计了一种新颖的时间步长调度策略和固定噪声注入机制,能够有效校正累积误差,进一步提高了生成质量和稳定性。

论文链接:
https://ieeexplore.ieee.org/document/10657796
VP3D: Unleashing 2D Visual Prompt for Text-to-3D Generation
方法:
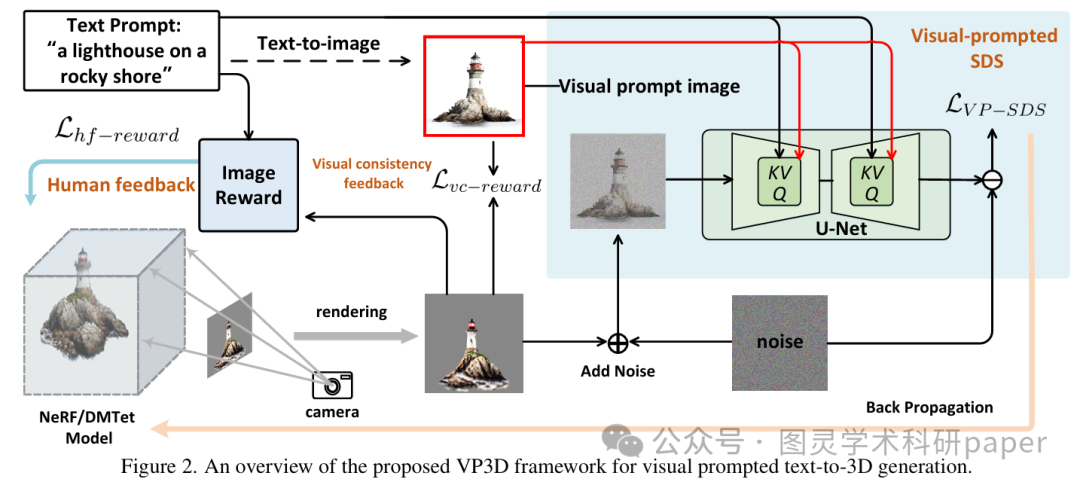
文章首先利用预训练的文本到图像扩散模型根据输入文本生成高质量的二维图像作为视觉提示,然后将该视觉提示与文本提示一同用于优化三维模型的分数蒸馏采样过程,通过视觉提示引导的分数蒸馏采样(VP-SDS)来优化三维模型的参数,同时结合人类反馈奖励和视觉一致性奖励函数,鼓励生成的三维模型在语义和视觉上与输入提示高度一致,最终通过粗到细的两阶段训练框架,分别使用InstantNGP和DMTet作为三维表示,逐步优化出具有高保真度和语义一致性的三维模型。

创新点:
首次引入二维视觉提示来增强文本到三维生成过程,利用高质量的二维图像作为中间桥梁,有效弥合了文本和三维模态之间的分布差异,显著提高了生成三维模型的视觉质量和语义对齐程度。
提出视觉提示引导的分数蒸馏采样(VP-SDS),相比于传统的SDS,VP-SDS通过结合视觉提示和文本提示,能够更精准地引导三维模型的优化,避免了因过大分类器自由引导权重导致的过饱和问题,同时提升了生成结果的多样性和真实性。
设计了两种可微分的奖励函数——人类反馈奖励和视觉一致性奖励,进一步强化了生成三维模型与输入视觉提示和文本提示之间的语义和外观一致性,使生成的三维场景不仅在语义上与文本对齐,而且在视觉上与参考图像高度相似,拓展了模型的应用场景。
论文链接:
https://ieeexplore.ieee.org/document/10655403
本文选自gongzhonghao【图灵学术科研岛】
关注我们,掌握更多顶会顶刊发文资讯