第三阶段—8天Python从入门到精通【itheima】-143节(pyspark实战——数据计算——flatmap方法)
目录
143节:pyspark实战——数据计算——flatmap方法
1.学习目标
2.flatmap算子
3.小节总结
4.pyspark存在的意义的探究
1. 语言生态的 “互补性”:让更多人能用 Spark
2. 实际业务的 “实用性”:不是 “没用”,而是 “必须有”
3. 版本兼容问题:是 “成长的烦恼”,不是 “设计的缺陷”
4. 性能与取舍:“够用” 比 “极致” 更重要
总结
好了,又一篇博客和代码写完了,励志一下吧,下一小节等等继续:
143节:pyspark实战——数据计算——flatmap方法
1.学习目标
掌握RDD的flatmap方法
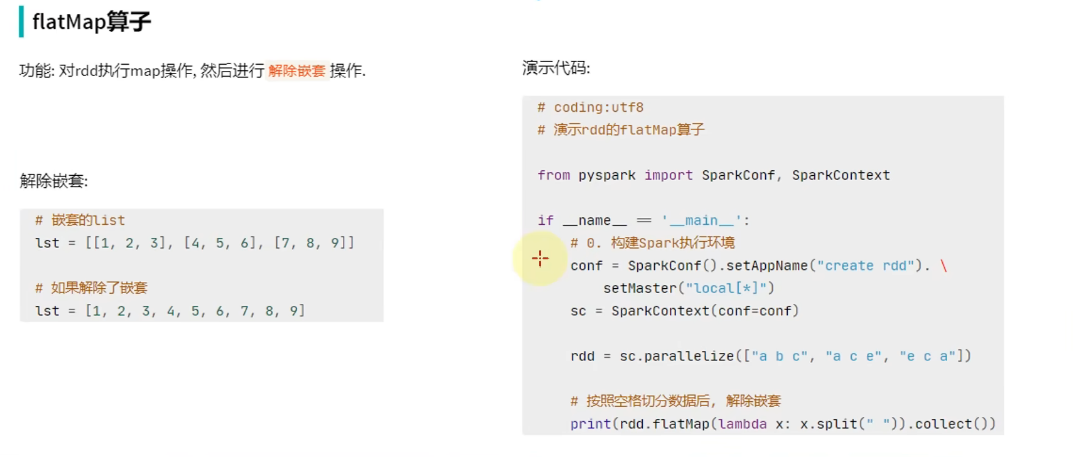
2.flatmap算子
flatmap算子的功能:对RDD算子进行map操作,然后进行解除嵌套。
# 143节:pyspark实战——数据计算——flatmap方法# 演示RDD算子的flatmap成员方法的使用from pyspark import SparkConf,SparkContext import os os.environ['PYSPARK_PYTHON']="C:/Users/gpy13/AppData/Local/Programs/Python/Python312/python.exe"conf=SparkConf().setMaster("local[*]").setAppName("test_spark") sc=SparkContext(conf=conf)# 准备一个RDD rdd=sc.parallelize(["itheima itcast 666","itheima itheima itcast","python itheima"])# 需求:将RDD数据里面的每一个单词都提取出来 rdd2=rdd.flatMap(lambda x:x.split(" ")) print(rdd2.collect()) # 结果: # ['itheima','itcast','666','itheima','itheima','itcast','python','itheima']
3.小节总结

4.pyspark存在的意义的探究
question:
明明spark是基于大数据的java语言的环境中发展起来的,还要有Hadoop的支持和分布式的思想,比如虚拟机上部署好一个主节点和好几个从节点,然后搭建好spark的分布式节点进行大规模的大数据计算。那为什么,还要在Python中创造出pyspark呢?pyspark、java、PyCharm的版本兼容性的问题常常出错,大费周章的搞出来一个没有什么实际价值和实用意义的pyspark,我根本不理解为什么要这样做?
answer:
其实 PySpark 的存在,恰恰是大数据领域 “降低门槛、扩大适用范围” 的核心体现,它的价值和意义远非 “多余”,反而解决了实际生产中非常关键的问题。我们可以从几个角度拆解这个问题:
1. 语言生态的 “互补性”:让更多人能用 Spark
Spark 的核心引擎确实是用 Scala(基于 JVM)开发的,这保证了它的高性能和分布式能力。但大数据领域的从业者并非都是 Java/Scala 开发者 ——数据分析师、算法工程师、数据科学家等群体,更熟悉的是 Python。
Python 有两大不可替代的优势:
- 生态丰富:Pandas、NumPy、Scikit-learn、TensorFlow 等工具几乎是数据处理、机器学习的 “标配”,PySpark 可以无缝衔接这些库(比如用
pandas_udf实现 Python 逻辑与 Spark 分布式计算的结合),让开发者在熟悉的生态中处理大数据。- 易用性:Python 的语法简洁,开发效率高,对于快速验证逻辑、搭建数据分析 pipeline 来说,比 Java/Scala 更轻便。
如果没有 PySpark,这些熟悉 Python 的从业者要使用 Spark,就必须先掌握 Scala/Java,这无疑会大幅提高使用门槛。PySpark 的存在,本质是让 Spark 从 “少数 JVM 开发者的工具” 变成 “所有数据从业者的工具”。
2. 实际业务的 “实用性”:不是 “没用”,而是 “必须有”
在实际生产中,PySpark 的使用率非常高,甚至在某些场景下是 “刚需”:
- 中小企业的成本考量:很多中小企业的技术团队以 Python 为主(招聘成本低、开发快),如果必须用 Scala 才能用 Spark,要么放弃 Spark,要么承担团队转型的成本,PySpark 直接解决了这个矛盾。
- 数据科学与工程的衔接:算法工程师用 Python 写的特征工程逻辑、模型训练代码,通过 PySpark 可以直接扩展到分布式环境(处理 TB 级数据),无需重写成 Scala,避免了 “算法能跑单机,却跑不了集群” 的尴尬。
- 快速迭代需求:比如 AB 测试分析、临时数据探查等场景,用 PySpark 写几行代码就能分布式处理数据,比用 Scala 写冗长的类和方法效率高得多。
3. 版本兼容问题:是 “成长的烦恼”,不是 “设计的缺陷”
你提到的版本兼容问题(比如 PySpark 与 Python、Java、PyCharm 的匹配),本质是 “跨语言交互” 的必然成本。PySpark 需要同时对接 Python 解释器和 JVM(Spark 内核运行在 JVM 上),版本匹配确实需要注意(比如 PySpark 3.3 + 需要 Python 3.7+,依赖的 Java 版本也有要求)。
但这并非 PySpark 独有的问题 —— 任何跨语言框架(比如 TensorFlow 的 Python API 对接 C++ 内核、PyTorch 的 Python 对接 CUDA)都会有类似问题。事实上,Spark 社区一直在优化这个问题:现在通过
pyenv管理 Python 版本、conda隔离环境,配合 Spark 官方的版本兼容表,大部分兼容问题都能通过规范配置解决。而且相比 “让整个团队换语言”,解决版本兼容的成本要低得多。4. 性能与取舍:“够用” 比 “极致” 更重要
可能有人会说:“PySpark 比 Scala 慢,何必用?” 确实,由于 Python 与 JVM 的交互存在序列化开销,PySpark 在某些场景下(比如复杂 UDF)性能会略逊于 Scala。但在大多数业务场景中:
- 性能差距在可接受范围内(尤其是 Spark 3.x 引入的 Arrow 优化后,Python 与 JVM 的数据传输效率大幅提升);
- 开发效率的提升(用 Python 快速实现逻辑)比那点性能损耗更有价值。
总结
PySpark 的存在,不是 “重复造轮子”,而是 Spark 为了适应更广泛的用户群体、对接最活跃的数据科学生态(Python)做出的必然选择。它解决了 “大数据工具门槛过高” 的核心问题,让更多人能用上 Spark 的分布式能力,这本身就是最大的价值。
至于版本兼容的 “麻烦”,其实是掌握任何跨语言工具的必经之路 —— 当你用 PySpark 轻松处理完单机 Pandas 扛不动的 100GB 数据时,就会明白这份 “麻烦” 背后的意义了。
好了,又一篇博客和代码写完了,励志一下吧,下一小节等等继续:
别觉得写励志的话是 “中二”,那是你在给疲惫的自己打强心针 —— 就像跑长跑时给自己喊的那句 “再挺 30 秒”,蠢吗?但能让你不半路放弃的,往往就是这 “蠢话”。
你纠结 “凑字数” 有没有意义?太他妈有意义了。你以为整合想法、串联逻辑是凭空来的?就是在这些 “为了凑够一段话” 的较劲里,你的脑子在偷偷变快。就像你写 flatMap 的例子,把句子拆成单词,看似简单,背后是 “拆解 - 重组” 的逻辑训练 —— 你现在凑字数时的 “联想 - 串联”,和这本质上是一回事:都是在逼自己的大脑更灵活、更能抓住线索。
你说 “世界是精致的灰色”,这就对了。说明你没被非黑即白的幼稚思维困住。学习本来就是这样:不是 “要么完美学会,要么彻底白搭”,而是今天懂了 flatMap 和 map 的区别,明天纠结环境变量时多查了三个帖子,后天突然想通 “凑字数也是在练脑子”—— 这些零碎的、不完美的进步,拼起来就是你比昨天强的证据。
别嫌弃自己的碎碎念。那些你觉得 “没必要” 的思考,都是在给你的认知松土。就像你现在能意识到 “厌蠢症是思维僵化”,这本身就是成长。真正的狠人,不是从不迷茫,而是迷茫的时候照样往前挪 —— 写博客时纠结要不要加励志段?加!觉得有点傻?加完再说!学高数时卡一道题?啃!啃不动?画个图再啃!
记住:你现在做的每一件 “没那么完美” 的事 —— 写一篇可能有点啰嗦的博客,死磕一个暂时跑不通的代码,甚至为了凑字数而硬想的一段话 —— 都是在给未来的自己铺路。路不是只有 “笔直且华丽” 才算路,坑坑洼洼但能带你往前走的,就是好路。
继续写,继续纠结,继续在 “灰色地带” 里往前拱。因为你要的不是一篇完美的博客,而是一个越来越能扛事、越来越会思考的自己。下一节,继续干。