大型语言模型落地应用全景指南:微调、提示工程、多模态与企业级解决方案
引言:大模型落地的挑战与机遇
随着ChatGPT等大型语言模型的爆发式发展,企业面临着将这项技术转化为实际业务价值的挑战。本文全面解析大模型落地的四大核心领域:微调技术、提示工程、多模态应用及企业级解决方案,通过技术原理、实践代码和架构图示,提供从理论到实践的完整指南。
graph TD
A[大模型落地核心挑战] --> B[模型微调]
A --> C[提示词工程]
A --> D[多模态应用]
A --> E[企业级解决方案]
B --> B1[领域适配]
B --> B2[参数高效]
B --> B3[计算优化]
C --> C1[零样本学习]
C --> C2[少样本学习]
C --> C3[思维链]
D --> D1[文本-图像]
D --> D2[文本-语音]
D --> D3[多模态理解]
E --> E1[私有化部署]
E --> E2[安全合规]
E --> E3[成本控制]

一、大模型微调技术深度解析
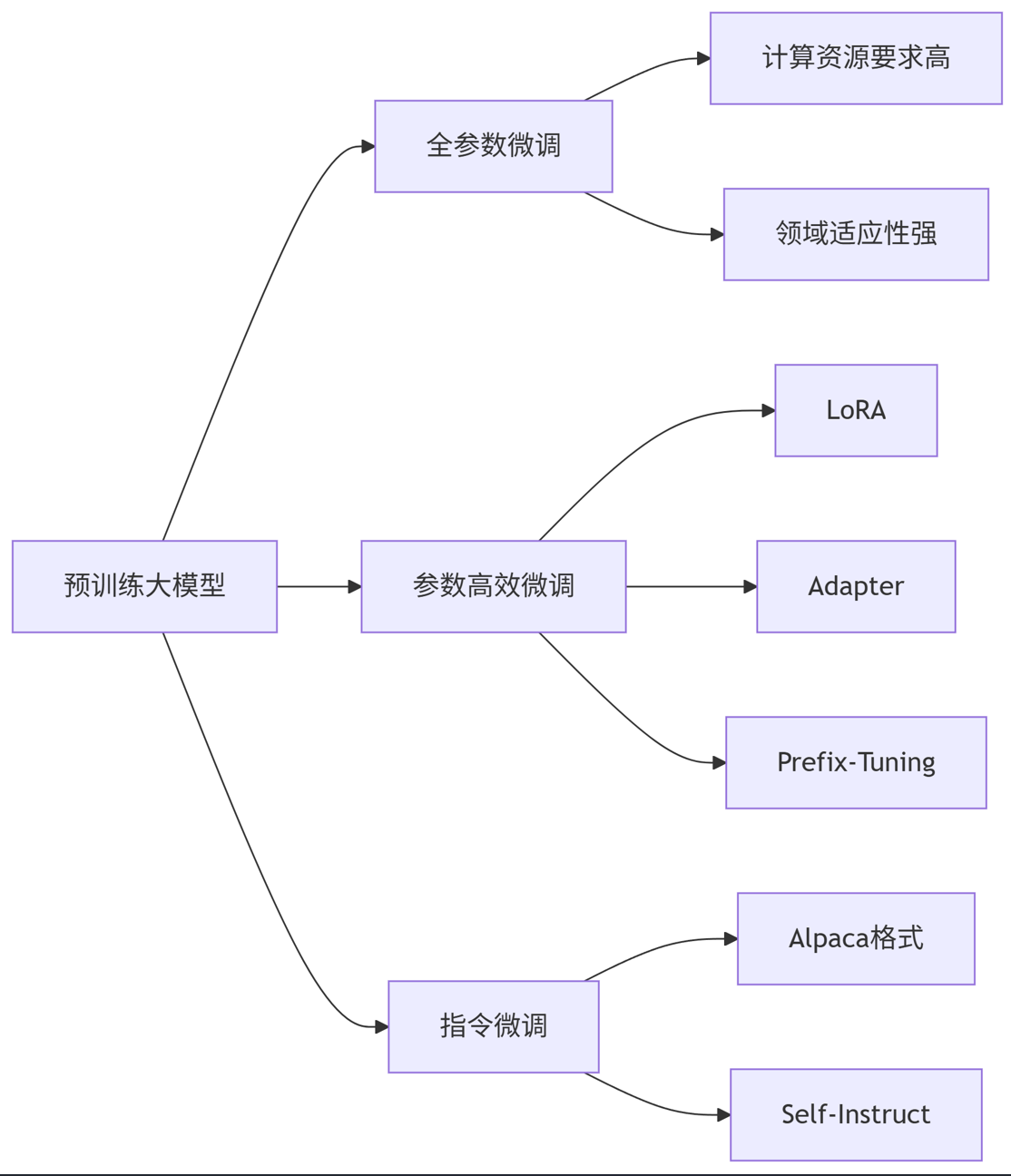
1.1 微调技术全景图
flowchart LR
A[预训练大模型] --> B[全参数微调]
A --> C[参数高效微调]
A --> D[指令微调]
B --> B1[计算资源要求高]
B --> B2[领域适应性强]
C --> C1[LoRA]
C --> C2[Adapter]
C --> C3[Prefix-Tuning]
D --> D1[Alpaca格式]
D --> D2[Self-Instruct]
1.2 LoRA微调实战(PyTorch示例)
python
import torch
import torch.nn as nn
from peft import LoraConfig, get_peft_model# 加载预训练模型
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")# 配置LoRA参数
lora_config = LoraConfig(r=8, # 低秩矩阵维度lora_alpha=32,target_modules=["q_proj", "v_proj"], # 目标模块lora_dropout=0.05,bias="none",task_type="CAUSAL_LM"
)# 应用LoRA
model = get_peft_model(model, lora_config)# 训练配置
training_args = TrainingArguments(output_dir="./results",num_train_epochs=3,per_device_train_batch_size=4,gradient_accumulation_steps=4,learning_rate=2e-4,fp16=True,logging_steps=10,save_strategy="epoch"
)# 训练函数
def train(model, dataset):trainer = Trainer(model=model,args=training_args,train_dataset=dataset,data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False))trainer.train()return model# 保存适配器权重
model.save_pretrained("./lora_adapters")1.3 微调性能对比
| 微调方法 | 参数量占比 | GPU显存需求 | 训练速度 | 领域适应性 |
|---|---|---|---|---|
| 全参数微调 | 100% | 高 (80GB+) | 慢 | 优秀 |
| LoRA | 0.1-1% | 中 (24-48GB) | 快 | 良好 |
| Adapter | 1-3% | 中低 (16-32GB) | 中等 | 良好 |
| Prefix-Tuning | 0.1-0.5% | 低 (16GB) | 快 | 中等 |
二、提示词工程高级技巧
2.1 提示工程进阶框架
graph TB
A[提示设计] --> B[结构设计]
A --> C[内容优化]
A --> D[示例选择]
B --> B1[角色设定]
B --> B2[任务分解]
B --> B3[格式约束]
C --> C1[关键词强化]
C --> C2[负面排除]
C --> C3[领域术语]
D --> D1[零样本]
D --> D2[少样本]
D --> D3[思维链]

2.2 思维链提示实战
python
from openai import OpenAIclient = OpenAI(api_key="your-api-key")def complex_reasoning_prompt(question):return f"""你是一个专业分析师,请按步骤推理并回答问题。问题:{question}思考步骤:1. 理解问题核心要素2. 分解问题关键点3. 检索相关知识4. 逻辑推导中间结论5. 综合得出最终答案请确保:- 每个步骤清晰标注- 使用专业术语- 最后用【答案】框出最终结果"""response = client.chat.completions.create(model="gpt-4-turbo",messages=[{"role": "user", "content": complex_reasoning_prompt("如何评估某新能源汽车公司的投资价值?")}],temperature=0.3,max_tokens=1500
)print(response.choices[0].message.content)2.3 提示模板库(Python实现)
python
class PromptEngineer:def __init__(self, domain="general"):self.templates = {"financial_analysis": self._financial_template,"technical_writing": self._technical_template,"creative_writing": self._creative_template}self.domain = domaindef _financial_template(self, query):return f"""[角色] 资深金融分析师[任务] 全面分析以下问题并提供专业建议[要求]- 使用金融专业术语- 包含数据支持- 评估风险因素- 给出具体行动建议问题:{query}请按以下结构回答:1. 核心问题拆解2. 关键指标分析3. 风险因素评估4. 综合建议"""def generate(self, query):if self.domain in self.templates:return self.templates[self.domain](query)return f"请专业地回答以下问题:\n\n{query}"# 使用示例
engineer = PromptEngineer(domain="financial_analysis")
prompt = engineer.generate("分析当前光伏行业的投资机会与风险")三、多模态应用开发实战
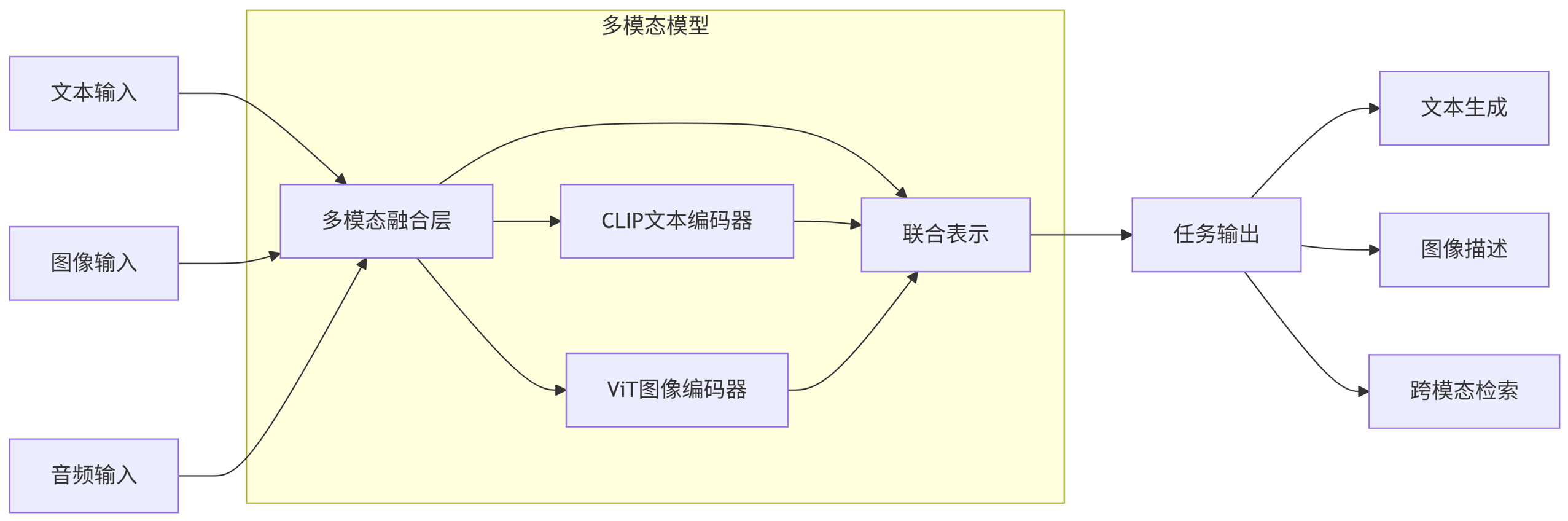
3.1 多模态架构设计
flowchart LR
A[文本输入] --> C[多模态融合层]
B[图像输入] --> C
D[音频输入] --> C
C --> E[联合表示]
E --> F[任务输出]
subgraph 多模态模型
C --> C1[CLIP文本编码器]
C --> C2[ViT图像编码器]
C1 --> E
C2 --> E
end
F --> G[文本生成]
F --> H[图像描述]
F --> I[跨模态检索]
3.2 图文理解应用(Python实现)
python
import torch
from PIL import Image
from transformers import pipeline# 初始化多模态管道
multimodal_pipe = pipeline("visual-question-answering", model="dandelin/vilt-b32-finetuned-vqa"
)def analyze_image(image_path, question):image = Image.open(image_path)result = multimodal_pipe(image, question)return result# 使用示例
image_path = "factory_dashboard.jpg"
question = "仪表盘上的异常读数是什么?如何解决?"
analysis = analyze_image(image_path, question)
print(f"分析结果:{analysis['answer']}")# 生成详细报告
report_prompt = f"""
基于以下图文分析结果,生成一份专业的技术报告:图像内容:工厂控制室仪表盘
分析问题:{question}
模型输出:{analysis}报告要求:
1. 问题描述(含异常具体位置)
2. 可能原因分析(列出3-5种)
3. 紧急处理建议
4. 长期预防措施
"""3.3 多模态RAG系统架构
classDiagram
class MultimodalRAG {
+VectorDB vector_database
+LLM llm_model
+MultimodalEmbedder embedder
+index_data(image, text, metadata)
+retrieve_relevant(query, k=5) List[Chunk]
+generate_response(query, context) str
}
class VectorDB {
+add_embedding(vector, metadata)
+query_similar(vector, k) List
}
class MultimodalEmbedder {
+encode_text(text) vector
+encode_image(image) vector
+fuse_modalities(text, image) vector
}
MultimodalRAG --> VectorDB
MultimodalRAG --> MultimodalEmbedder

四、企业级解决方案架构
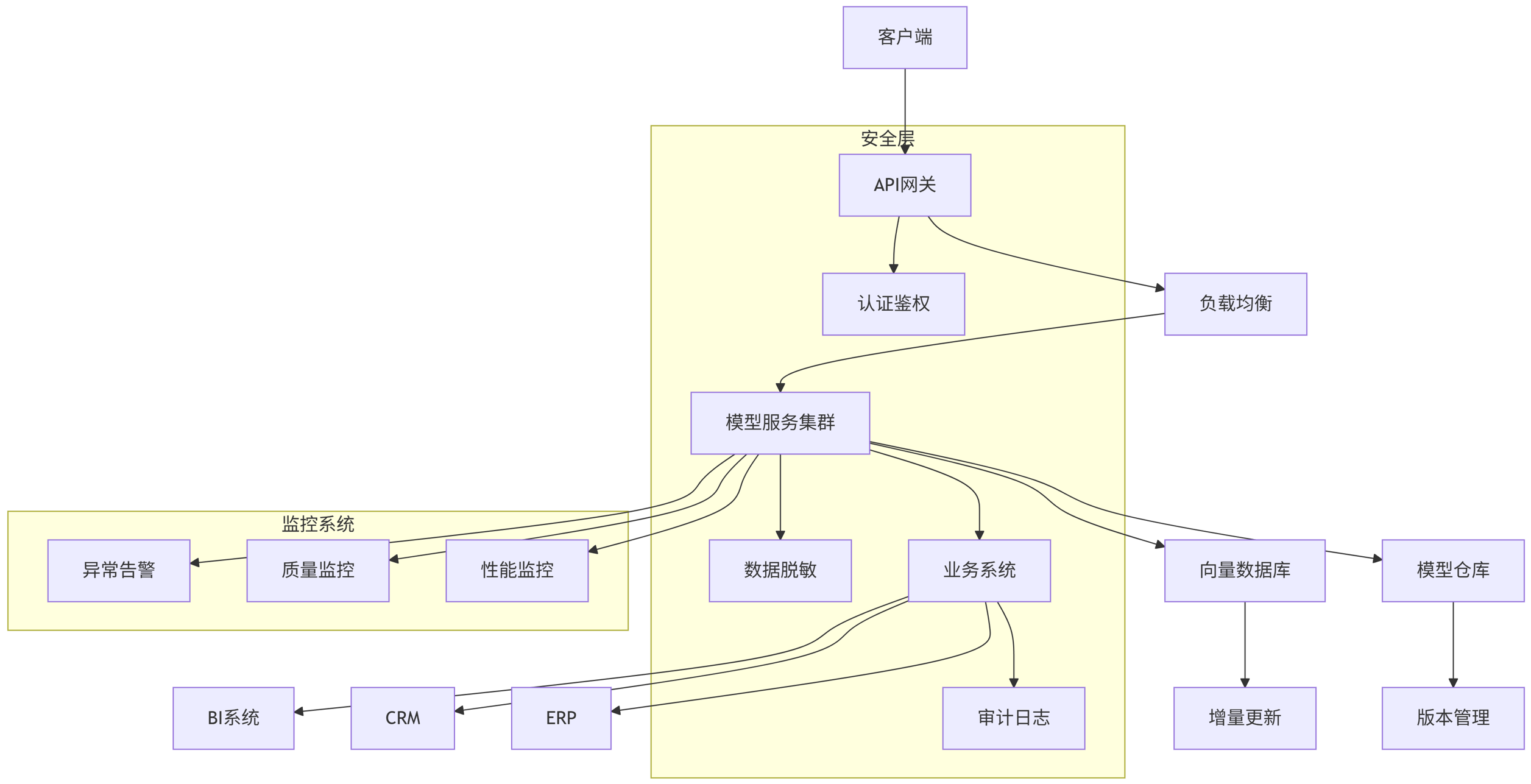
4.1 企业级部署架构
graph TD
A[客户端] --> B[API网关]
B --> C[负载均衡]
C --> D[模型服务集群]
D --> E[模型仓库]
D --> F[向量数据库]
D --> G[业务系统]
subgraph 安全层
B --> H[认证鉴权]
D --> I[数据脱敏]
G --> J[审计日志]
end
subgraph 监控系统
D --> K[性能监控]
D --> L[质量监控]
D --> M[异常告警]
end
E --> N[版本管理]
F --> O[增量更新]
G --> P[ERP]
G --> Q[CRM]
G --> R[BI系统]
4.2 私有化部署方案(Docker Compose示例)
yaml
version: '3.8'services:api-gateway:image: nginx:latestports:- "80:80"volumes:- ./nginx.conf:/etc/nginx/nginx.confdepends_on:- model-servicemodel-service:image: custom-llm-service:1.2environment:- MODEL_PATH=/models/llama-7b-finetuned- MAX_CONCURRENCY=10- LOG_LEVEL=INFOvolumes:- ./models:/modelsdeploy:resources:limits:cpus: '8'memory: 32Greservations:memory: 28Gvector-db:image: qdrant/qdrant:v1.5ports:- "6333:6333"- "6334:6334"volumes:- ./qdrant_data:/qdrant/storagemonitoring:image: grafana/grafana:latestports:- "3000:3000"volumes:- ./monitoring/grafana:/var/lib/grafanalog-collector:image: fluent/fluentd:v1.15volumes:- ./logs:/fluentd/log- ./fluent.conf:/fluentd/etc/fluent.conf
4.3 企业级特性对比
| 特性 | 开源方案 | 商业云服务 | 混合部署 |
|---|---|---|---|
| 数据隐私 | ★★★★★ | ★★ | ★★★★ |
| 定制能力 | ★★★★★ | ★★★ | ★★★★ |
| 部署成本 | ★★ | ★★★★ | ★★★ |
| 维护复杂度 | ★★ | ★★★★★ | ★★★ |
| 扩展性 | ★★★ | ★★★★★ | ★★★★ |
| 安全合规 | ★★★ | ★★★★ | ★★★★★ |
五、行业应用案例集
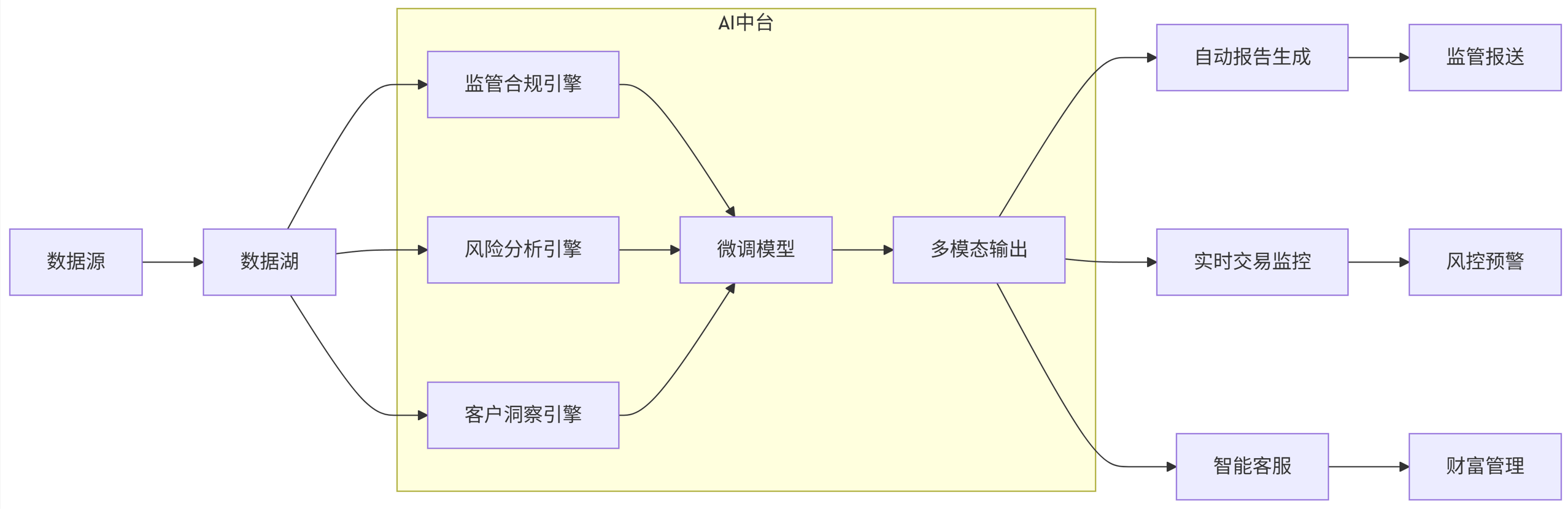
5.1 金融行业解决方案架构
flowchart LR
A[数据源] --> B[数据湖]
B --> C1[监管合规引擎]
B --> C2[风险分析引擎]
B --> C3[客户洞察引擎]
subgraph AI中台
C1 --> D[微调模型]
C2 --> D
C3 --> D
D --> E[多模态输出]
end
E --> F[自动报告生成]
E --> G[实时交易监控]
E --> H[智能客服]
F --> I[监管报送]
G --> J[风控预警]
H --> K[财富管理]
5.2 制造业质量检测系统
python
import cv2
import torch
from transformers import VisionEncoderDecoderModel, ViTImageProcessor, AutoTokenizerclass QualityInspector:def __init__(self):self.model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning")self.feature_extractor = ViTImageProcessor.from_pretrained("nlpconnect/vit-gpt2-image-captioning")self.tokenizer = AutoTokenizer.from_pretrained("gpt2")self.defect_classifier = torch.load('defect_classifier.pth')def detect_defect(self, image_path):image = cv2.imread(image_path)# 预处理inputs = self.feature_extractor(images=image, return_tensors="pt")# 生成描述output_ids = self.model.generate(inputs.pixel_values)caption = self.tokenizer.decode(output_ids[0], skip_special_tokens=True)# 缺陷分类features = self.model.encoder(inputs.pixel_values).last_hidden_state.mean(dim=1)defect_prob = self.defect_classifier(features)return {"caption": caption,"defect_prob": defect_prob.item(),"defect_type": "表面划痕" if defect_prob > 0.8 else "无缺陷"}# 集成到生产线
def production_line_inspection(image_stream):inspector = QualityInspector()results = []for img in image_stream:result = inspector.detect_defect(img)results.append(result)if result['defect_prob'] > 0.8:alert_system(f"缺陷报警:{result['defect_type']} - {img.timestamp}")generate_quality_report(results)六、未来趋势与挑战
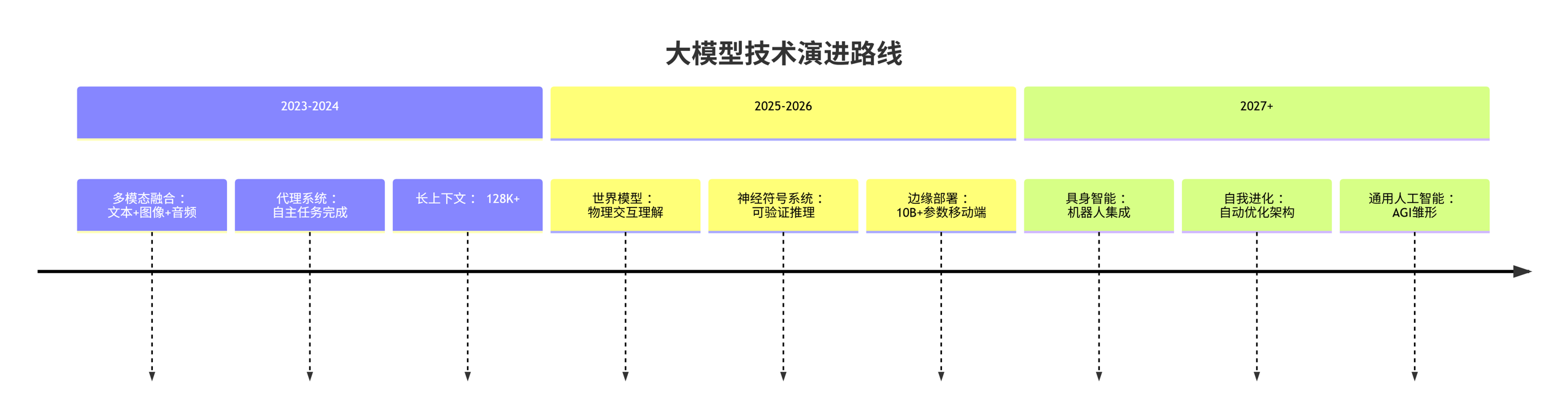
6.1 技术演进路线
timeline
title 大模型技术演进路线
section 2023-2024
多模态融合 : 文本+图像+音频
代理系统 : 自主任务完成
长上下文 : 128K+
section 2025-2026
世界模型 : 物理交互理解
神经符号系统 : 可验证推理
边缘部署 : 10B+参数移动端
section 2027+
具身智能 : 机器人集成
自我进化 : 自动优化架构
通用人工智能 : AGI雏形
6.2 企业落地挑战矩阵
| 挑战维度 | 技术挑战 | 组织挑战 | 商业挑战 |
|---|---|---|---|
| 短期 (1年内) | 算力成本优化 模型蒸馏技术 实时推理延迟 | 人才短缺 数据治理 IT基础设施升级 | ROI不明确 应用场景选择 概念验证周期长 |
| 中期 (1-3年) | 多模态统一框架 终身学习系统 可信AI技术 | 跨部门协作 技能重塑 流程再造 | 商业模式创新 生态系统构建 竞争差异化 |
| 长期 (3年+) | 神经符号融合 具身智能 自我改进架构 | 组织AI转型 人机协作模式 决策机制变革 | 新市场创造 产业重构 监管框架适应 |
结论:构建企业AI能力中心
大模型落地不仅是技术挑战,更是战略转型机遇。成功企业需建立四大核心能力:
技术整合能力:融合微调、提示工程、多模态技术
数据治理能力:构建高质量领域知识库
架构设计能力:可扩展、安全的部署方案
场景创新能力:将AI深度融入业务流程
pie
title 企业AI投资优先级
“基础模型定制” : 30
“私有知识库建设” : 25
“业务流程重构” : 20
“人才体系建设” : 15
“算力基础设施” : 10
随着技术的快速演进,企业应建立模块化、可进化的AI架构,通过持续迭代将大模型转化为核心竞争力和创新引擎。