Flink2.0学习笔记:Stream API 窗口
https://github.com/stevensu1/EC0720/tree/master/FLINKTASK-TEST-STREAM/demo
Apache Flink 是一个高性能、高吞吐、低延迟的分布式流处理框架,广泛用于实时数据处理。在流处理中,数据是无限、持续到达的,因此无法像批处理那样对“全部数据”进行计算。为此,Flink 引入了 窗口(Window)机制,将无限流数据划分为有限的“块”进行处理。
一、Flink 窗口的基本原理
1. 什么是窗口(Window)?
窗口是将无限流数据按时间或数量等条件划分为有限的、可处理的数据块,然后对每个窗口内的数据进行聚合或计算。
✅ 举个例子:
想要“每5分钟统计一次网站的访问量”,就需要把持续不断的用户访问日志按5分钟划分成一个个“窗口”,然后在每个窗口内进行计数。
2. 窗口的核心组成
Flink 中的窗口机制由以下几部分构成:
| 组件 | 说明 |
|---|---|
| Window Assigner | 决定元素属于哪个窗口(如滚动窗口、滑动窗口等) |
| Trigger | 触发器,决定何时计算窗口中的数据(如时间到达、元素数量满足等) |
| Evictor(可选) | 在触发计算前,移除某些元素(较少使用) |
| Window Function | 实际处理窗口中数据的函数(如 ReduceFunction、AggregateFunction、ProcessWindowFunction) |
二、Flink 窗口类型
1. 按时间划分:Time Window
(1)滚动窗口(Tumbling Window)
- 固定长度,无重叠。
- 适用于周期性统计。
/*** 滚动窗口(Tumbling Window)* 固定长度,无重叠。* 适用于周期性统计。*/stream.print().name("printer");// 将字符串映射为元组 (word, 1),然后进行窗口聚合stream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1);}}).name("map-to-tuple").keyBy(tuple -> tuple.f0) // 按照元组的第一个元素(即单词)分组.window(TumblingProcessingTimeWindows.of(Duration.ofSeconds(5))) // 5秒的滚动窗口.sum(1) // 对元组的第二个字段(即计数)求和.map(new MapFunction<Tuple2<String, Integer>, String>() {@Overridepublic String map(Tuple2<String, Integer> tuple) throws Exception {// 获取当前时间并格式化为 hh:mm:ssString currentTime = LocalDateTime.now().format(DateTimeFormatter.ofPattern("HH:mm:ss"));return String.format("[%s] %s: %d", currentTime, tuple.f0, tuple.f1);}}).name("add-timestamp").print("window-result").name("window-aggregation");}
📊 示例:
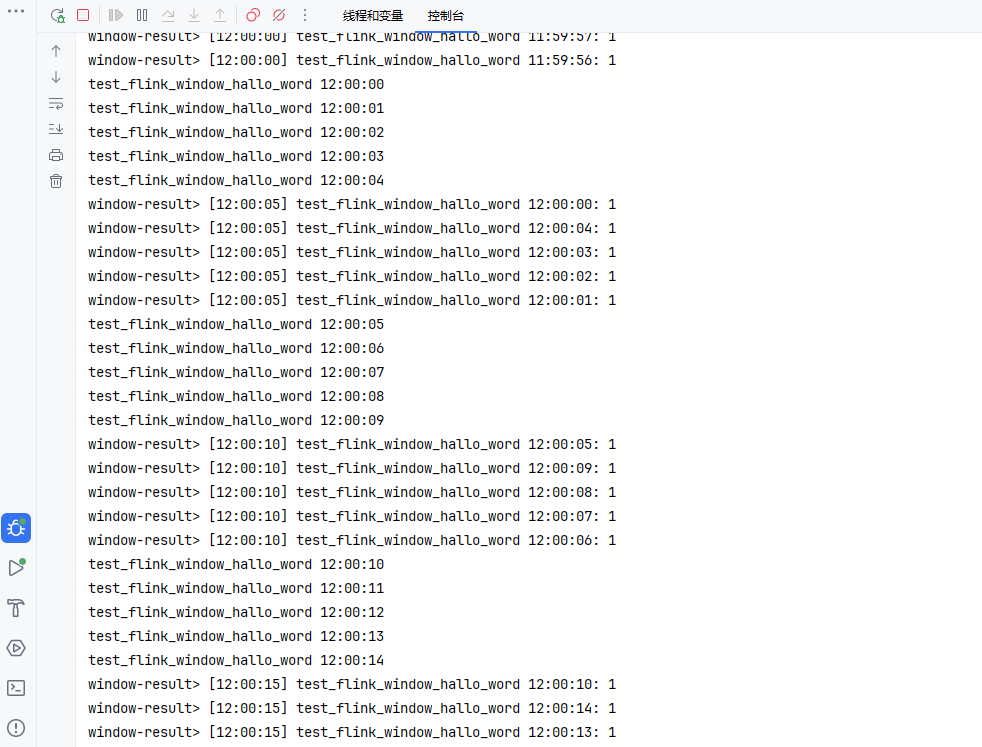
(2)滑动窗口(Sliding Window)
- 固定长度,但可以重叠。
- 滑动步长 < 窗口长度。
// 窗口长10秒,每5秒滑动一次// 窗口长10秒,每5秒滑动一次stream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1);}}).name("map-to-sliding-tuple").keyBy(tuple -> tuple.f0) // 按照元组的第一个元素(即单词)分组.window(SlidingProcessingTimeWindows.of(Duration.ofSeconds(10), Duration.ofSeconds(5))) // 5秒的滚动窗口.sum(1) // 对元组的第二个字段(即计数)求和.map(new MapFunction<Tuple2<String, Integer>, String>() {@Overridepublic String map(Tuple2<String, Integer> tuple) throws Exception {// 获取当前时间并格式化为 hh:mm:ssString currentTime = LocalDateTime.now().format(DateTimeFormatter.ofPattern("HH:mm:ss"));return String.format("[%s] %s: %d", currentTime, tuple.f0, tuple.f1);}}).name("add-timestamp").print("window-result").name("window-aggregation");
📊 示例:
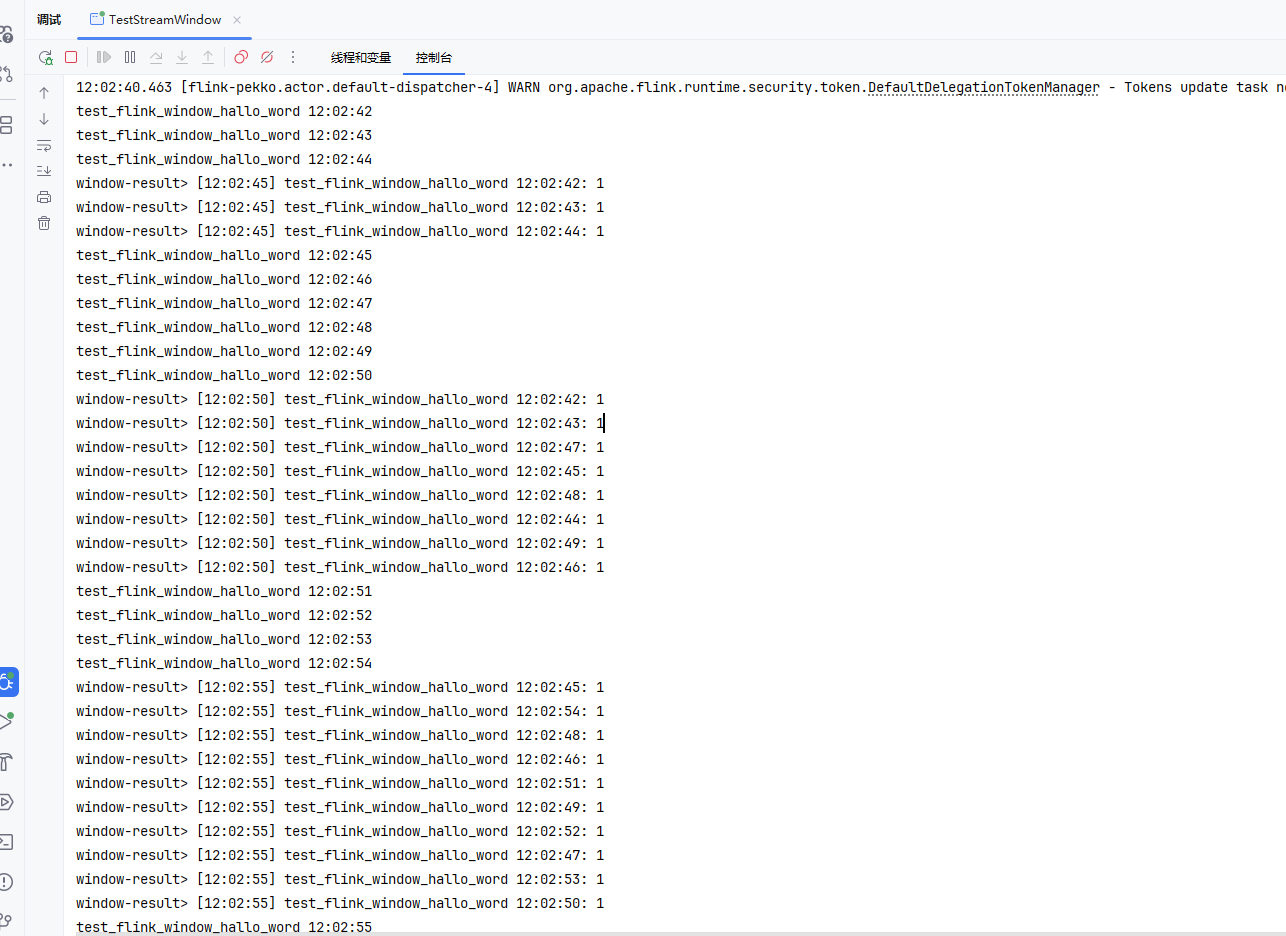
(3)会话窗口(Session Window)
- 基于“活跃期”划分,当一段时间内无数据到达时,自动关闭窗口。
- 常用于用户行为分析(如一次会话)。
// 会话间隔为7秒stream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1);}}).name("map-to-session").keyBy(tuple -> tuple.f0) // 按照元组的第一个元素(即单词)分组.window(ProcessingTimeSessionWindows.withGap(Duration.ofSeconds(7))) // 会话间隔为7秒.sum(1) // 对元组的第二个字段(即计数)求和.map(new MapFunction<Tuple2<String, Integer>, String>() {@Overridepublic String map(Tuple2<String, Integer> tuple) throws Exception {// 获取当前时间并格式化为 hh:mm:ssString currentTime = LocalDateTime.now().format(DateTimeFormatter.ofPattern("HH:mm:ss"));return String.format("[%s] %s: %d", currentTime, tuple.f0, tuple.f1);}}).name("add-timestamp").print("window-result").name("window-aggregation");
📊 示例:
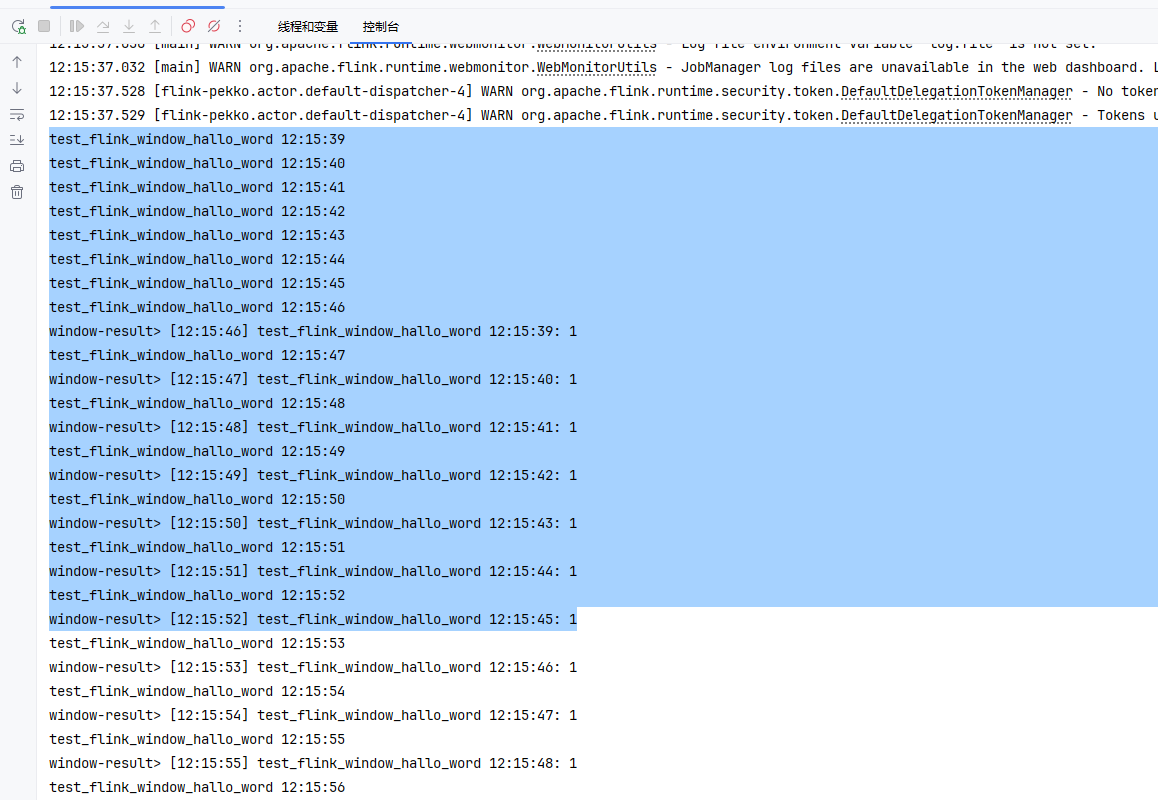
用户操作密集 → 属于同一会话;超过7秒无操作 → 新会话开始。
2. 按元素数量划分:Count Window
(1)滚动计数窗口
- 每收集 N 个元素就触发一次计算。
// 会话间隔为7秒stream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1);}}).name("map-to-countWindowAll").keyBy(tuple -> tuple.f0) // 按照元组的第一个元素(即单词)分组.countWindowAll(10) // 每10条数据触发一次.sum(1) // 对元组的第二个字段(即计数)求和.map(new MapFunction<Tuple2<String, Integer>, String>() {@Overridepublic String map(Tuple2<String, Integer> tuple) throws Exception {// 获取当前时间并格式化为 hh:mm:ssString currentTime = LocalDateTime.now().format(DateTimeFormatter.ofPattern("HH:mm:ss"));return String.format("[%s] %s: %d", currentTime, tuple.f0, tuple.f1);}}).name("add-timestamp").print("window-result").name("window-aggregation");
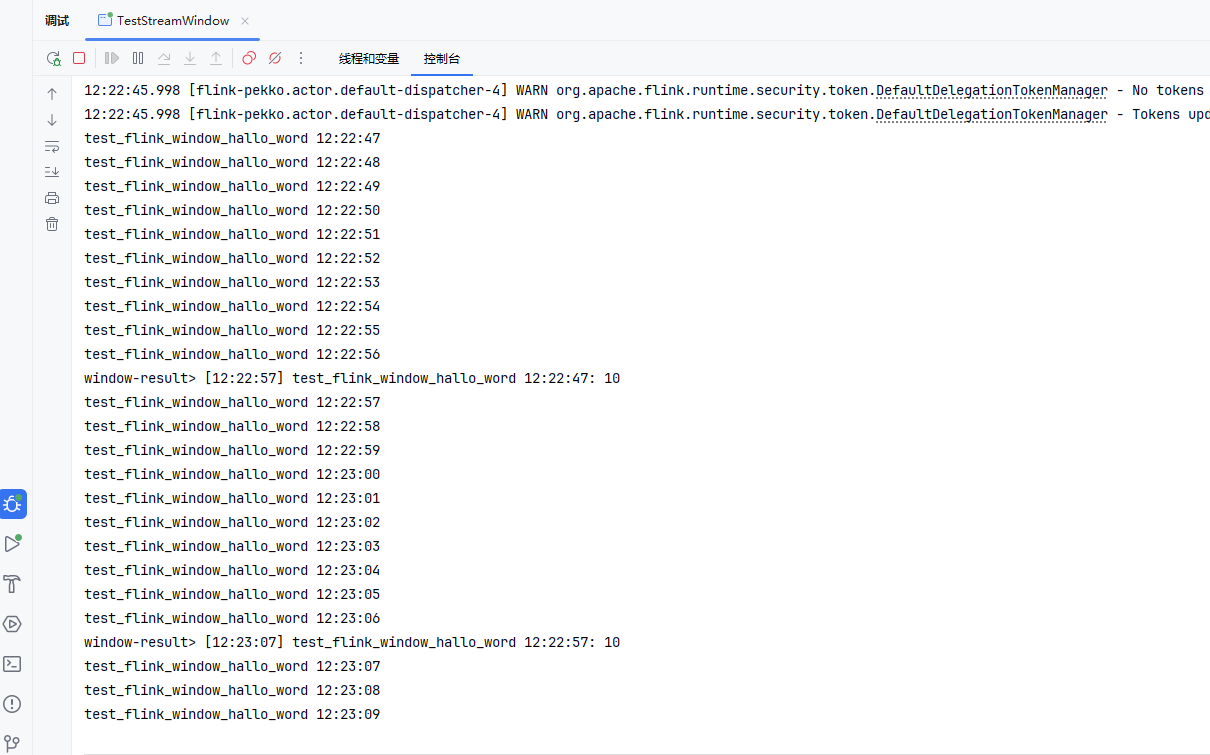
(2)滑动计数窗口
- 窗口大小为 N,滑动步长为 S。
private static void test6(DataStream<String> stream) {stream.print().name("printer");// 会话间隔为7秒stream.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1);}}).name("map-to-countWindowAll").keyBy(tuple -> tuple.f0) // 按照元组的第一个元素(即单词)分组.countWindowAll(10,5) // 窗口大小为 N,滑动步长为 S。.sum(1) // 对元组的第二个字段(即计数)求和.map(new MapFunction<Tuple2<String, Integer>, String>() {@Overridepublic String map(Tuple2<String, Integer> tuple) throws Exception {// 获取当前时间并格式化为 hh:mm:ssString currentTime = LocalDateTime.now().format(DateTimeFormatter.ofPattern("HH:mm:ss"));return String.format("[%s] %s: %d", currentTime, tuple.f0, tuple.f1);}}).name("add-timestamp").print("window-result").name("window-aggregation");}
⚠️ 注意:Count Window 不支持事件时间(Event Time),仅支持处理时间(Processing Time)或摄入时间(Ingestion Time)。
3. 事件时间 vs 处理时间
| 时间语义 | 说明 |
|---|---|
| Processing Time | 以 Flink 系统处理时间为准,延迟低但可能不准确 |
| Event Time | 以数据本身携带的时间戳为准,支持乱序处理,更精确 |
| Ingestion Time | 数据进入 Flink 的时间,介于两者之间 |
✅ 推荐使用 Event Time,结合 Watermark 处理乱序事件。
三、Watermark 与乱序处理
在事件时间窗口中,数据可能因网络延迟而乱序到达。Flink 使用 Watermark 机制来标记“时间进度”,表示“在此时间之前的数据已全部到达”。
// 允许最大延迟10秒
stream.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(10)).withTimestampAssigner((event, timestamp) -> event.getTimestamp())).keyBy(event -> event.userId).window(TumblingEventTimeWindows.of(Time.minutes(5))).trigger(EventTimeTrigger.create()).sum("amount");
- 当 Watermark 超过窗口结束时间,窗口触发计算。
- 延迟超过 Watermark 的数据默认被丢弃,但可通过 Allowed Lateness 允许迟到数据:
.window(...)
.allowedLateness(Time.minutes(1)) // 允许1分钟内迟到
.sideOutputLateData(lateOutputTag); // 将超时数据输出到侧输出流
四、窗口函数(Window Function)
1. 增量聚合函数
- 每来一条数据就进行聚合,内存友好。
- 如:
ReduceFunction,AggregateFunction
.aggregate(new AverageAggregate())
2. 全窗口函数(Full Window Function)
- 先缓存所有数据,窗口触发时再处理。
- 如:
ProcessWindowFunction,可访问上下文信息(如窗口元数据)。
.process(new ProcessWindowFunction<Integer, String, String, TimeWindow>() {public void process(String key, Context context, Iterable<Integer> input, Collector<String> out) {long windowStart = context.window().getStart();long windowEnd = context.window().getEnd();int sum = 0;for (Integer value : input) {sum += value;}out.collect("Window: [" + windowStart + ", " + windowEnd + ") Sum: " + sum);}
});
✅ 可结合增量聚合 + 全窗口函数:
使用reduce()或aggregate()预聚合,再用ProcessWindowFunction包装结果,既高效又灵活。
五、实际使用案例
✅ 案例1:实时统计每分钟订单金额(滚动事件时间窗口)
// 数据源:订单流(orderId, amount, timestamp)
DataStream<Order> orderStream = env.addSource(new OrderSource());orderStream.assignTimestampsAndWatermarks(WatermarkStrategy.<Order>forBoundedOutOfOrderness(Duration.ofSeconds(5)).withTimestampAssigner((order, ts) -> order.getTimestamp())).keyBy(order -> order.sellerId).window(TumblingEventTimeWindows.of(Time.minutes(1))).sum("amount").print();
输出:每分钟每个商家的销售额。
✅ 案例2:滑动窗口检测异常登录(每10秒检查过去1分钟的登录次数)
loginStream.keyBy(login -> login.userId).window(SlidingEventTimeWindows.of(Time.minutes(1), Time.seconds(10))).count().filter(count -> count > 10).map(count -> "User login too frequently: " + count).addSink(new AlertSink());
用于实时风控:短时间内频繁登录 → 触发告警。
✅ 案例3:用户会话分析(Session Window)
userActionStream.keyBy(action -> action.userId).window(ProcessingTimeSessionWindows.withGap(Time.minutes(5))).aggregate(new SessionStatsAggregate()).print();
统计每个用户会话的:
- 会话时长
- 页面浏览数
- 最后一次操作时间
六、窗口常见问题与优化
| 问题 | 解决方案 |
|---|---|
| 数据延迟导致结果不准 | 使用 Watermark + Allowed Lateness |
| 窗口内存占用高 | 使用增量聚合,避免全量缓存 |
| 窗口触发不及时 | 检查 Watermark 生成策略 |
| 大量小窗口导致性能差 | 合理设置窗口大小和滑动步长 |
七、总结
| 特性 | 说明 |
|---|---|
| 核心作用 | 将无限流划分为有限块进行计算 |
| 主要类型 | 滚动、滑动、会话、计数窗口 |
| 时间语义 | 推荐使用 Event Time + Watermark |
| 适用场景 | 实时统计、监控、告警、用户行为分析等 |
| 优势 | 支持精确一次语义(Exactly-once)、低延迟、高吞吐 |
✅ Flink 窗口是流处理的灵魂,掌握其原理和使用方法,是构建实时数据系统的基石。结合业务场景选择合适的窗口类型和时间语义,才能实现准确、高效的实时计算。