译|Netflix 技术博客:一个利用视觉-语言模型和主动学习高效构建视频分类器的框架
本篇介绍了Netflix的视频标注器(VA),一个利用视觉-语言模型和主动学习的交互式框架。其技术亮点在于通过人机协作系统,结合零样本能力和主动学习,引导领域专家高效标注视频数据,显著提升了模型样本效率和平均精度。VA通过搜索、主动学习和审查三步流程,实现视频分类器的快速构建与迭代。
这个视频标注器(VA)模型主要有三个步骤:
- 搜索:用户通过文字描述(如“建筑物的广角镜头”)来搜索视频片段,找到初步的示例。
- 主动学习:模型根据已有的标注训练一个轻量级分类器,然后用它来筛选出“最积极的”、“最消极的”、“最模糊的”或“随机的”视频片段,供用户继续标注,不断优化模型。
- 审查:用户查看所有已标注的片段,检查是否有错误,并寻找新的标注想法。
文章来自于:Video annotator: a framework for efficiently building video classifiers using vision-language models and active learning
文章目录
- 问题
- 影响
- 解决方案
- 视频理解
- 视频分类
- 通过可扩展的视频分类器集实现视频理解
- 视频标注器 (VA)
- 步骤 1 — 搜索
- 步骤 2 — 主动学习
- 步骤 3 — 审查
- 实验
- 结论
问题
高质量且一致的标注是成功开发稳健机器学习模型的基础。训练机器学习分类器的传统技术是资源密集型的。它们涉及一个循环:领域专家标注数据集,然后将其移交给数据科学家进行模型训练、结果审查和修改。这种标注过程往往耗时且效率低下,有时在几个标注周期后就会中断。
影响
因此,相比于迭代复杂模型和算法方法以提高性能和修复边缘案例,在标注高质量数据集上投入的精力较少。结果是,机器学习系统的复杂性迅速增长。
此外,时间和资源的限制常常导致利用第三方标注人员而非领域专家。这些标注人员在不深入理解模型预期部署或用途的情况下执行标注任务,这使得对临界或困难示例进行一致性标注成为一项挑战,尤其是在更主观的任务中。
这需要与领域专家进行多轮审查,从而导致意想不到的成本和延误。这种漫长的周期还可能导致模型漂移,因为修复边缘案例和部署新模型需要更长时间,这可能会损害实用性和利益相关者的信任。
解决方案
我们认为,通过人机协作系统让领域专家更直接地参与,可以解决许多实际挑战。我们引入了一个新颖的框架——视频标注器(VA),它利用大型视觉-语言模型的主动学习技术和零样本能力来引导用户将精力集中在渐进式更困难的示例上,从而提高模型的样本效率并降低成本。
VA 将模型构建无缝集成到数据标注过程中,便于用户在部署前验证模型,从而有助于建立信任并培养主人翁意识。VA 还支持持续标注过程,允许用户快速部署模型,监控其在生产中的质量,并通过标注更多示例和部署新模型版本来迅速修复任何边缘案例。
这种自助服务架构使用户能够在没有数据科学家或第三方标注人员积极参与的情况下进行改进,从而实现快速迭代。
视频理解
我们设计 VA 旨在协助细粒度视频理解,这需要识别视频片段中的视觉、概念和事件。视频理解对于众多应用至关重要,例如搜索和发现、个性化以及宣传素材的创作。我们的框架允许用户通过开发一套可扩展的二元视频分类器来高效训练视频理解的机器学习模型,这些分类器为海量内容的规模化评分和检索提供支持。
视频分类
视频分类是将标签分配给任意长度视频片段的任务,通常伴随一个概率或预测分数,如图 1 所示。

图 1 - 二元视频分类器的功能视图。来自《高校舞弊案:美国大学招生丑闻》的一个几秒钟的片段被传递给一个二元分类器,用于检测“定场镜头”标签。分类器输出一个非常高的分数(分数介于 [0] 和 [1] 之间),表明该视频片段很可能是一个定场镜头。在电影制作中,定场镜头是一个广角镜头(即连续两个剪辑之间的视频片段),旨在确立场景的时间和地点。
通过可扩展的视频分类器集实现视频理解
二元分类允许独立性和灵活性,使我们能够独立于其他模型添加或改进一个模型。它还具有一个额外的好处,即对我们的用户来说更容易理解和构建。结合多个模型的预测,我们可以更深入地理解视频内容在不同粒度级别上的含义,如图 2 所示。

图 2 - 三个视频片段以及三个视频理解标签对应的二元分类器分数。请注意,这些标签并非互斥。视频片段分别来自《高校舞弊案:美国大学招生丑闻》、《鬼影特攻:以暴制暴》和《断讯》。
视频标注器 (VA)
在本节中,我们将描述 VA 构建视频分类器的三步过程。
步骤 1 — 搜索
用户首先在一个大型、多样化的语料库中找到一组初始示例,以启动标注过程。我们利用文本到视频搜索来实现这一点,该搜索由视觉-语言模型中的视频和文本编码器提供支持,用于提取嵌入。例如,一个正在处理定场镜头模型的标注人员可以通过搜索“建筑物的广角镜头”来启动该过程,如图 3 所示。

图 3 - 步骤 1 — 文本到视频搜索以启动标注过程。
步骤 2 — 主动学习
下一阶段涉及经典的主动学习循环。VA 随后在视频嵌入上构建一个轻量级二元分类器,该分类器随后用于对语料库中的所有片段进行评分,并在信息流中呈现一些示例以供进一步标注和细化,如图 4 所示。

图 4 - 步骤 2 — 主动学习循环。标注人员点击“构建”,这将启动分类器训练和视频语料库中所有片段的评分。评分后的片段被组织在四个信息流中。
得分最高的正向和负向信息流分别显示得分最高和最低的示例。我们的用户反馈称,这提供了有价值的指示,表明分类器在训练的早期阶段是否捕获了正确的概念,并发现了训练数据中他们随后能够修复的偏差情况。我们还包含了一个模型不确定的“临界”示例信息流。这个信息流有助于发现有趣的边缘案例,并激发标注额外概念的需求。最后,随机信息流包含随机选择的片段,有助于标注多样化的示例,这对于泛化很重要。
标注人员可以在任何信息流中标注额外的片段,并构建新的分类器,并根据需要重复多次。
步骤 3 — 审查
最后一步只是向用户展示所有已标注的片段。这是一个发现标注错误并识别通过步骤 1 中的搜索进行进一步标注的想法和概念的好机会。从这一步开始,用户通常会回到步骤 1 或步骤 2 来完善他们的标注。
实验
为了评估 VA,我们邀请了三位视频专家在一个包含 50 万个镜头的视频语料库中标注了 56 个不同标签。我们将 VA 与几种基线方法的性能进行了比较,并观察到 VA 能够创建更高质量的视频分类器。图 5 比较了 VA 与基线方法在不同标注片段数量下的性能。
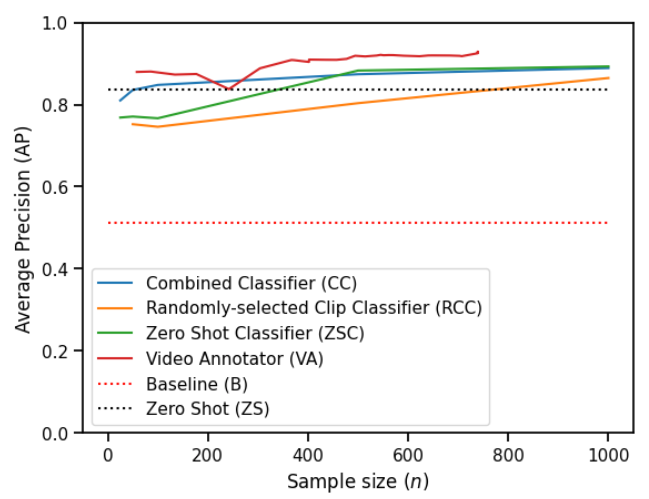
图 5 - “定场镜头”标签的模型质量(即平均精度 [Average Precision])作为标注片段数量的函数。我们观察到所有方法都优于基线,并且所有方法都受益于额外的标注数据,尽管程度不同。
您可以在这篇论文中找到有关 VA 和我们实验的更多详细信息。
结论
我们介绍了视频标注器(VA),这是一个交互式框架,解决了与训练机器学习分类器传统技术相关的许多挑战。VA 利用大型视觉-语言模型的零样本能力和主动学习技术来提高样本效率并降低成本。它提供了一种独特的标注、管理和迭代视频分类数据集的方法,强调领域专家在人机协作系统中的直接参与。通过使这些用户能够在标注过程中快速对困难样本做出明智决策,VA 提高了系统的整体效率。此外,它还支持持续标注过程,允许用户快速部署模型,监控其在生产中的质量,并迅速修复任何边缘案例。
这种自助服务架构使领域专家能够在没有数据科学家或第三方标注人员积极参与的情况下进行改进,并培养主人翁意识,从而建立对系统的信任。
我们进行了实验来研究 VA 的性能,发现它在广泛的视频理解任务中,相对于最具竞争力的基线,平均精度中位数提高了 [8.3] 个百分点。我们发布了一个数据集,其中包含由三位专业视频编辑使用 VA 标注的 [15.3] 万个标签,涵盖 [56] 个视频理解任务,并发布了代码以复现我们的实验。