[VL|RIS] ReferSAM
论文基本信息 (Basic Information)
| 标题 (Title) | ReferSAM: Unleashing Segment Anything Model for Referring Image Segmentation |
|---|---|
| Adress | https://ieeexplore.ieee.org/document/10819432 |
| Journal/Time | TCSVT |
| Author | 中科院 |
| Code | https://github.com/lsa1997/ReferSAM |
1. 核心思想 (Core Idea)
SAM 用于 RIS。通过增强跨模态交互和重新设计提示编码,来释放SAM在RIS任务中的潜力 。
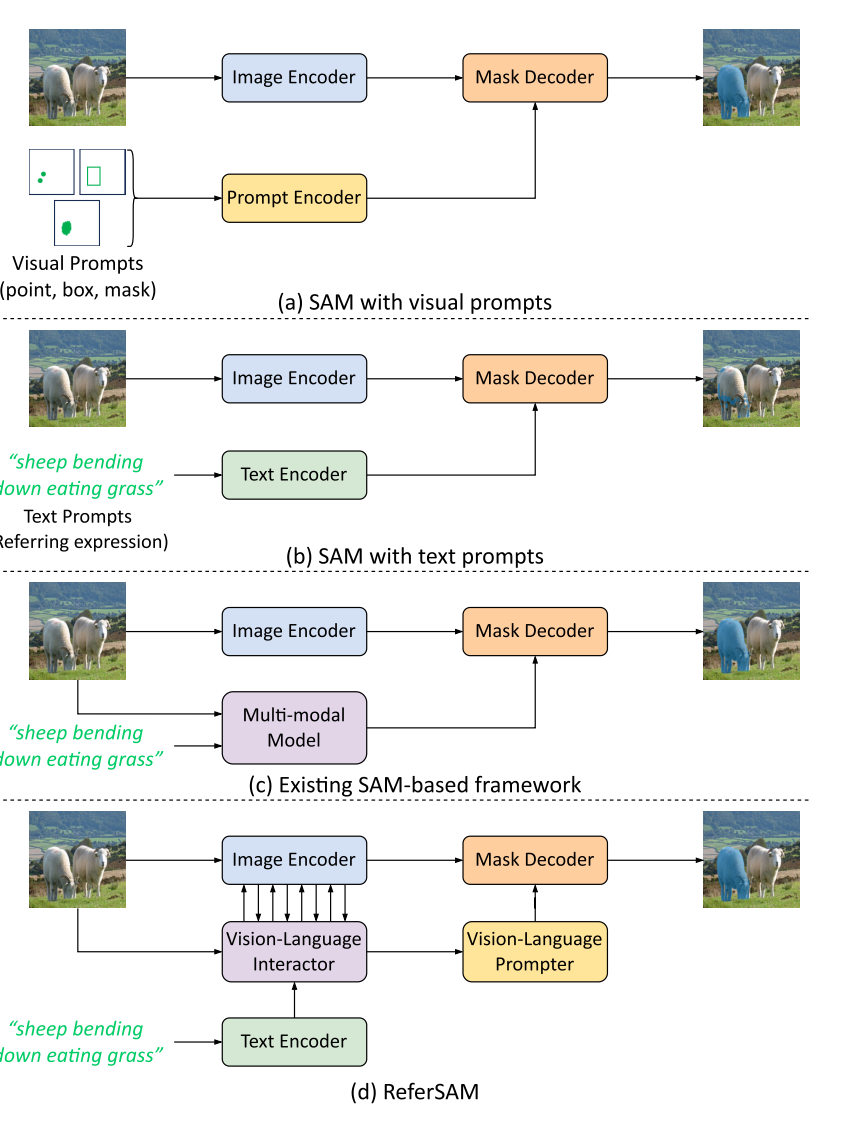
- 视觉-语言交互器 (Vision-Language Interactor, VLI):在SAM的图像编码阶段,将语言特征与多尺度的视觉特征进行细粒度的对齐和融合 。
- 视觉-语言提示器 (Vision-Language Prompter, VLP):聚合对齐后的图文特征,生成密集的(dense)和稀疏的(sparse)两种提示嵌入,以更精确地指导SAM的解码器生成分割掩码 。
2. 研究背景与动机 (Background and Motivation)
SAM 能根据点、框等视觉提示分割出任何物体 。然而,当提示变为自由形式的文本时,SAM的性能并不理想,因为它缺乏对视觉和语言特征之间进行细粒度交互的机制 。
- SAM 缺乏在像素和词语级别上进行精确对齐的能力。
- 文本的全局特征向量不足以精确地在复杂场景中定位目标,尤其是在描述涉及多个目标时 。
3. 方法论 (Methodology)
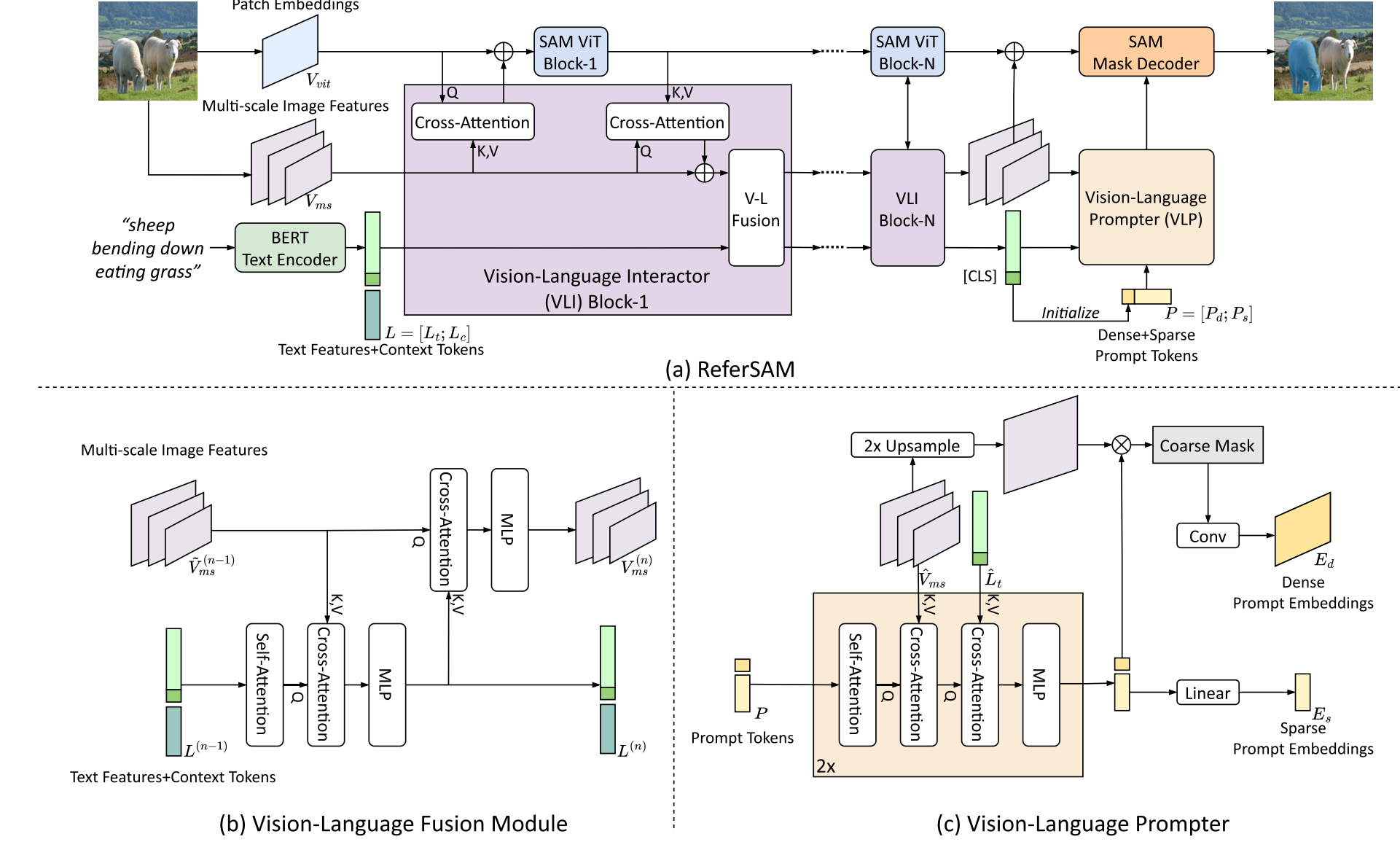
主要是利用vit-adapter 将自己的模块插入到 sam 的 encoder 之间的。
3.1 视觉-语言交互器 (Vision-Language Interactor - VLI)
- 多尺度特征交互:VLI并行于SAM的图像编码器,它额外提取了多尺度的图像特征。这些特征与SAM编码器中间层的特征进行跨注意力(cross-attention)交互,为SAM引入了多尺度的空间先验信息 。
- 图文融合:一个自注意力,两个 crossattn。
- 上下文令牌 (Context Tokens):为了解决某些文本描述只关注少数属性而导致对齐不稳定的问题,VLI引入了一组可学习的“上下文令牌”。这些令牌与真实的文本特征拼接在一起,在训练中学习捕捉通用的上下文信息,从而促进更稳定的跨模态对齐 。
3.2 视觉-语言提示器 (Vision-Language Prompter - VLP)
- 稀疏提示 (Sparse Prompts):通过一组可学习的稀疏提示令牌,从对齐后的图文特征中聚合信息,编码目标的详细属性 。论文中默认使用4个稀疏令牌 。
- 密集提示 (Dense Prompts):通过一个密集的提示令牌(由文本的全局[CLS]特征初始化),先生成一个粗略的分割图。这个粗略的分割图随后被编码成一个密集的提示嵌入,为最终分割提供初步的定位信息 。
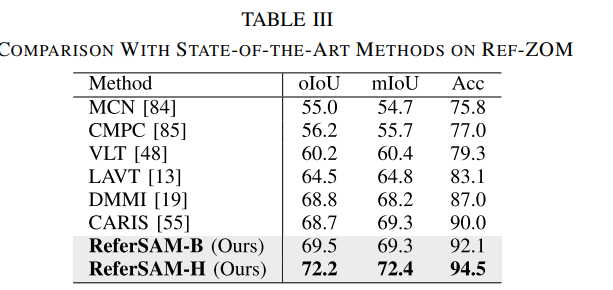
4. 实验结果 (Experimental Results)
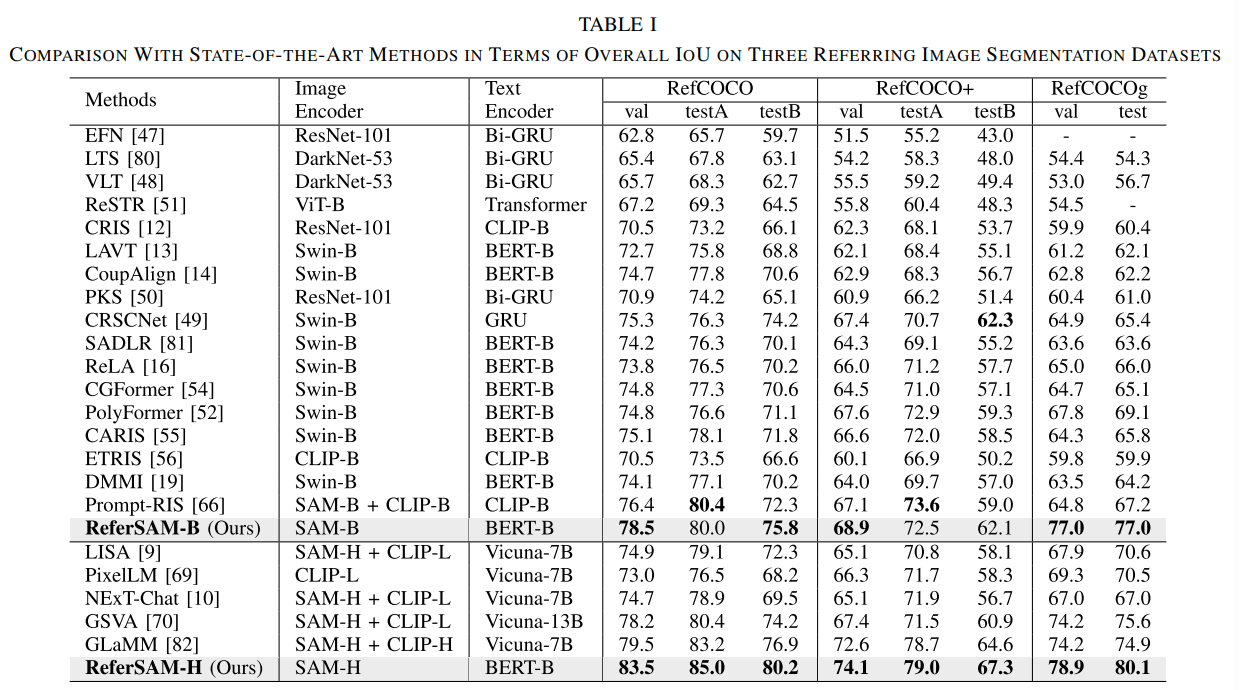
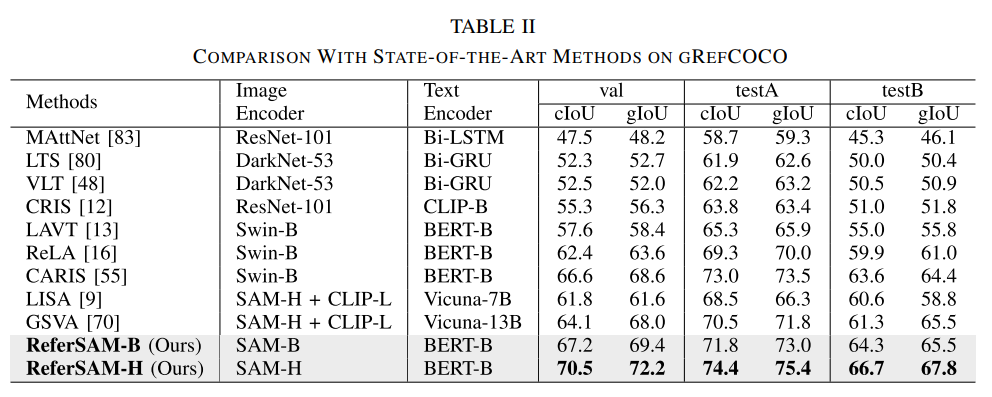
RefCOCO, RefCOCO+, RefCOCOg 以及 gRefCOCO, Ref-ZOM
4.1 消融
- 不同的文本编码器(BERT vs. CLIP)以及不同的训练方式(微调 vs. 冻结):直接将文本编码器的全局特征作为提示送入SAM解码器 。结果显示,使用CLIP的基线比使用BERT的要好。在完整的ReferSAM框架下,使用BERT作为文本编码器的效果反而超越了使用CLIP 。冻结BERT编码器会导致性能大幅下降 。冻结CLIP编码器的性能反而比微调它要略好一些 。
- ReferSAM核心组件的贡献分析
- 上下文与提示令牌数量的探索 (Table VI):过多的上下文令牌会稀释掉真实文本的语言信号,选择16. 使用4个稀疏提示令牌的效果最好
- 分割损失函数的验证 (Table VII):BCE损失和DICE损失。对VLP生成的粗略分割图的监督。
5. 结论与讨论 (Conclusion & Discussion)
将SAM的能力扩展到了指代性图像分割(RIS)任务。通过创新的视觉-语言交互器(VLI)和视觉-语言提示器(VLP),ReferSAM有效解决了原生SAM在处理文本提示时的两大核心挑战:缺乏细粒度交互和提示信息不足。
vit-adapter :Z. Chen et al., “Vision transformer adapter for dense predictions,” in Proc. 11th Int. Conf. Learn. Represent., Jan. 2022, pp. 1–11.