Java学习第九十六部分——Eureka
目录
📫 一、前言简介
⚙️ 二、核心定位与架构设计
✨ 三、核心组件职责
🔄 四、核心工作流程
🛡️ 五、关键特性与设计思想
🌐 六、应用场景与集成实践
⚖️ 七、与其他服务发现组件对比
🐳 八、CAP定理
☕ 九、CAP定理最佳实践
💎 十、总结归纳
📫 一、前言简介
Eureka是Netflix开源的分布式服务注册与发现组件,采用AP设计模型,通过心跳机制和客户端缓存实现高可用的服务动态管理。
⚙️ 二、核心定位与架构设计
Eureka是Netflix开源的服务发现组件,作为Spring Cloud微服务体系的核心基础设施,解决分布式系统中服务实例动态管理与通信解耦问题。
1. Eureka Server
-
服务注册中心,接收实例注册、维护内存注册表(`ConcurrentHashMap`结构),提供REST API供客户端查询。
-
支持集群部署,节点间通过对等复制(Peer Replication)同步数据,无主从关系,实现高可用性。
2. Eureka Client
-
集成于微服务中(服务提供者或消费者),负责向Server注册自身信息(IP、端口、健康状态等)并定期拉取服务注册表。
✨ 三、核心组件职责
| 组件 | 角色 | 关键职责 |
|---|---|---|
| Eureka Server | 服务注册中心 | 接收注册、维护注册表、集群同步、健康检查与剔除失效实例 |
| Eureka Client | 微服务实例 | 注册自身、发送心跳、拉取并缓存服务列表、发现其他服务 |
🔄 四、核心工作流程
1. 服务注册
-
服务启动时,Client向Server发送`POST`请求注册实例(包含元数据如应用名、IP等)。
2. 心跳续约
-
Client每30秒发送心跳(`PUT`请求),证明服务存活。若Server90秒未收到心跳,标记实例为`DOWN`。
3. 服务发现
-
Client启动时全量拉取注册表,后续每30秒增量更新,缓存至本地。调用服务时直接从本地缓存选择实例(支持负载均衡如轮询)。
4. 服务下线与剔除
-
正常关闭时,Client发送`DELETE`请求下线实例;异常时,Server主动剔除超时实例。
🛡️ 五、关键特性与设计思想
1. 自我保护机制
-
当15分钟内心跳失败率>85%(如网络分区故障),Server进入保护模式,停止剔除所有实例,避免误删健康服务。
2. AP系统设计
-
优先保证可用性(A)和分区容错性(P),牺牲强一致性(C)。即使Server集群全挂,Client仍能用本地缓存通信。
3. 多级缓存优化性能
-
一级缓存(注册表):实时更新的内存存储。
-
二级缓存(读写缓存):Guava实现,减少并发争抢。
-
三级缓存(只读缓存):Client默认从此获取数据,每30秒同步更新。
4. 集群同步
-
节点间通过HTTP异步复制数据,失败自动重试(最终一致性)。
🌐 六、应用场景与集成实践
1. 典型场景
-
电商微服务动态扩缩容、社交平台实时服务调用、云原生容器化服务管理。
2. 与Spring Cloud集成
-
Server端:通过`@EnableEurekaServer`注解启动,配置集群节点地址。
-
Client端:`@EnableEurekaClient`注解实现自动注册,结合Ribbon/Fegin实现负载均衡。
3. 高可用配置
-
集群节点互相注册(配置`eureka.client.serviceUrl.defaultZone`指向其他节点)。
| 参数 | 默认值 | 作用 |
|---|---|---|
eureka.instance.lease-renewal-interval-in-seconds | 30秒 | 客户端心跳间隔 |
eureka.instance.lease-expiration-duration-in-seconds | 90秒 | 服务失效阈值 |
eureka.server.enable-self-preservation | true | 是否启用自我保护机制 |
⚖️ 七、与其他服务发现组件对比
Eureka vs Zookeeper
-
Eureka:AP系统,无主从结构,集群部分节点故障仍可用;最终一致性,适合高容错场景。
-
Zookeeper:CP系统,强一致性;主节点故障时选举耗时(30-120秒),期间服务不可用。
Eureka vs Nacos
-
Nacos同时支持AP/CP模式,提供动态配置管理,功能更丰富;Eureka更轻量,专注服务发现。
🐳 八、CAP定理
由计算机科学家Eric Brewer提出,揭示分布式系统三大核心属性不可兼得:
-
C(Consistency)一致性:所有节点同时读到最新数据
-
A(Availability)可用性:每个请求都能获得即时响应(不保证数据最新)
-
P(Partition Tolerance)分区容错性:网络分区发生时系统仍能运行
⚠️ 核心矛盾:当网络分区(P)必然发生时,系统必须在C和A之间二选一。
公式表达:分布式系统 = CP 或 AP(P是必选项)
☕ 九、CAP定理最佳实践
🧩 原理解析
CAP的核心约束——在分布式系统中,网络分区(P)无法避免,因此实际设计需在 C(一致性) 与 A(可用性) 之间权衡:
-
CP系统 → 优先保证强一致性(C)和分区容错性(P),牺牲可用性(A)
-
AP系统 → 优先保证高可用性(A)和分区容错性(P),牺牲强一致性(C)
🧩 CP系统(强一致性优先)
(1)典型代表:ZooKeeper、etcd、HBase
(2)核心特点:
-
强一致性(C):任何时刻所有节点数据完全一致,读操作总能返回最新写入结果。
-
网络分区(P)时的行为:当节点间通信中断(网络分区),系统会拒绝写入/读取请求(牺牲可用性),直到数据同步完成。
(3)适用场景:
-
金融交易系统(如账户余额)
-
分布式锁服务
-
配置中心(需实时一致)
(4)示例流程: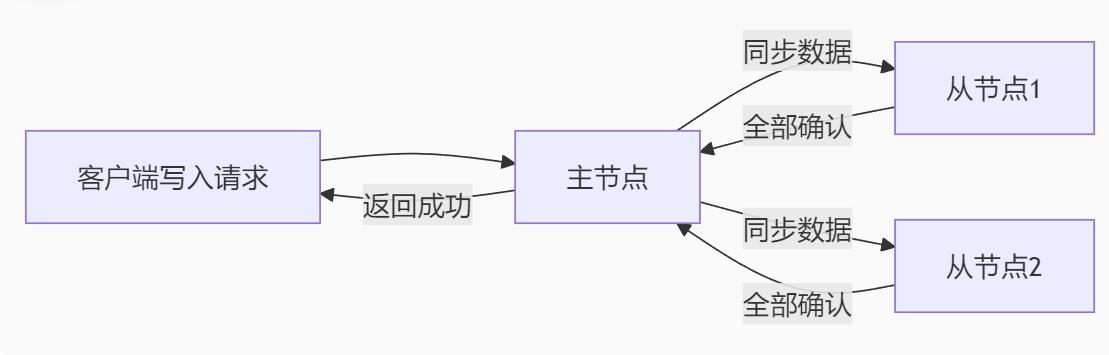
A[客户端写入请求] --> B[主节点] B -->|同步数据| C[从节点1] B -->|同步数据| D[从节点2] C & D -->|全部确认| B B -->|返回成功| A
若任一节点同步失败,整个操作失败 → 保证强一致,但可能不可用。
🧩 AP系统(高可用优先)
(1)典型代表:Eureka、Cassandra、DynamoDB
(2)核心特点:
-
高可用性(A):任何非故障节点必须即时响应请求(即使数据可能过时)。
-
网络分区(P)时的行为:允许不同分区独立运行(如部分节点可写,部分节点可读),接受数据暂时不一致(最终一致性)。
(3)适用场景:
-
服务发现(如Eureka)
-
社交平台动态流
-
电商商品库存(允许短暂超卖)
(4)示例流程: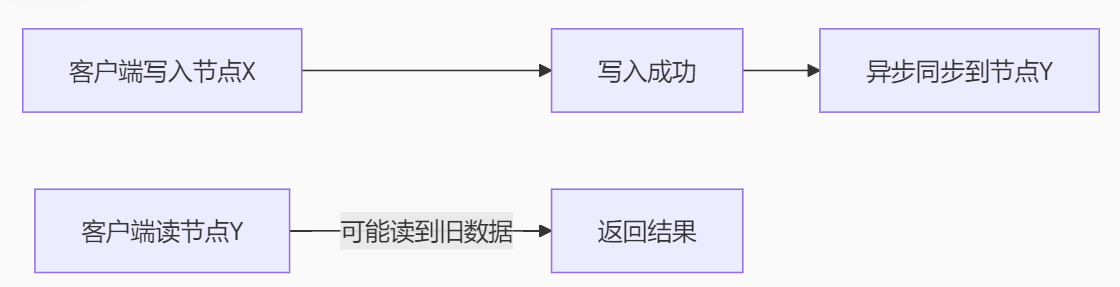
A[客户端写入节点X] --> B[写入成功] B --> C[异步同步到节点Y] D[客户端读节点Y] -->|可能读到旧数据| E[返回结果]
读写操作立即响应,不等待全局同步 → 可用性高,但数据可能不一致。
🧩 AP与CP关键对比
| 维度 | CP系统 | AP系统 |
|---|---|---|
| 核心目标 | 数据强一致 | 服务高可用 |
| 网络分区时 | 拒绝服务(等待恢复) | 继续服务(接受不一致) |
| 数据同步方式 | 同步阻塞(如Raft协议) | 异步传播(最终一致性) |
| 故障恢复时间 | 较长(需选举/数据同步) | 极短(节点独立运行) |
| 典型场景 | 支付、分布式锁 | 服务发现、实时推荐系统 |
🧩 业务选型建议
-
选 CP:当业务要求绝对数据正确性(如转账金额、库存扣减)。
-
选 AP:当业务要求服务永不中断(如用户动态加载、服务注册发现)。
-
CAP不是“三选二”:而是 P(分区容错)必须保障,再根据场景权衡C与A。现实中多数系统通过设计优化(如读写分离、冲突解决)在AP基础上提升一致性(如Cassandra的Tunable Consistency)。
-
动态切换是王道:正常时——强一致(CP);故障时——降级为最终一致(AP)
-
最终一致性≠弱一致:通过算法(Paxos/Raft)可逼近强一致
-
“CAP不是枷锁,而是设计指南针” :理解业务本质比机械套用定理更重要
💎 十、总结归纳
Eureka作为微服务架构的注册中心核心,以高可用、自我保护机制和客户端缓存设计,成为分布式系统的基石。其AP模型适合对一致性要求宽松但对可用性要求高的场景(如电商、社交平台)。结合Spring Cloud生态可快速落地,但需注意最终一致性的业务影响。