提问总结1
Spring的注解
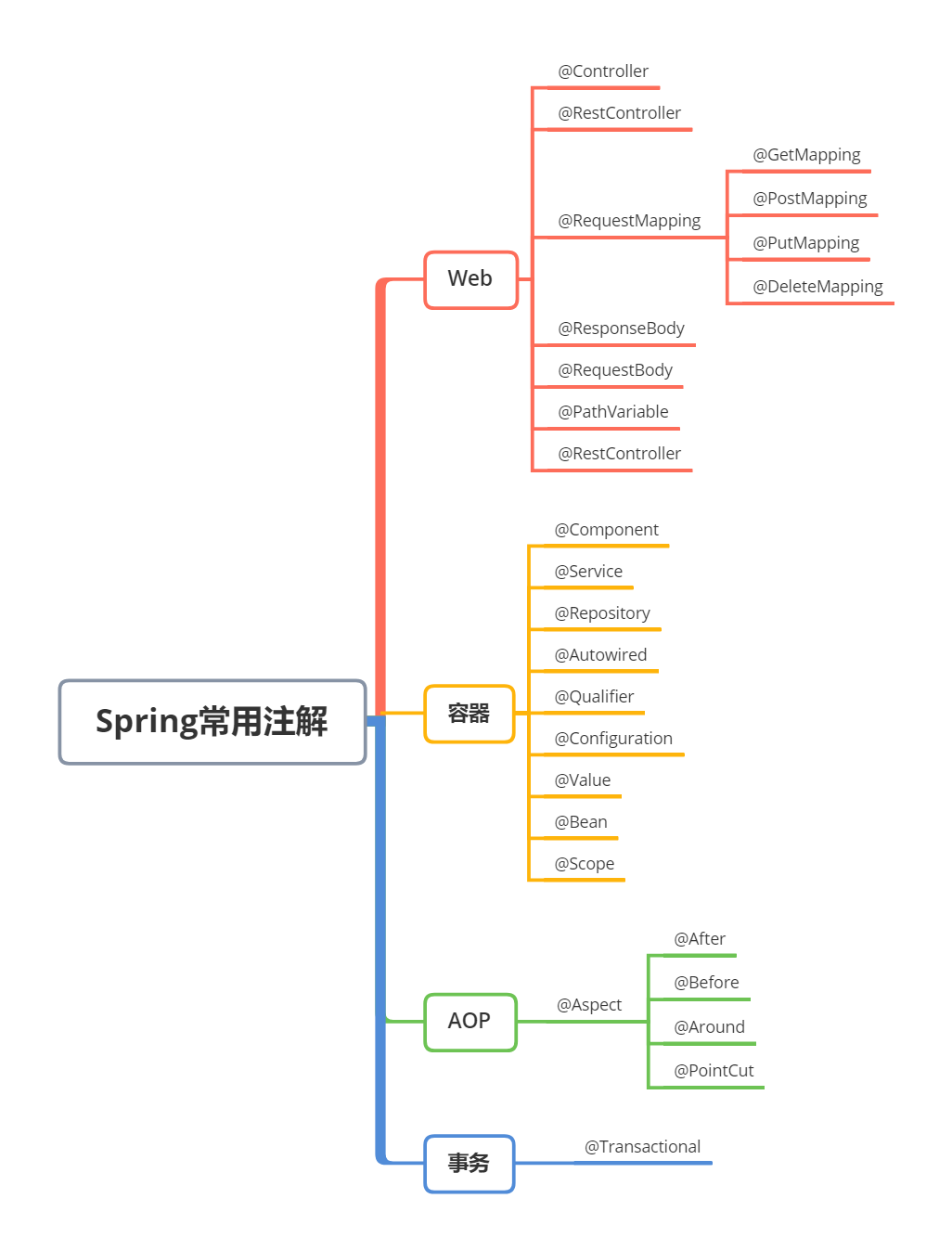
一、组件定义与扫描(让 Spring 管理 Bean)
用于标记类为 Spring 容器的 Bean,使其被扫描和管理。
| 注解 | 作用与场景 | 关键细节 |
|---|---|---|
| @Component | 通用组件标记(无明确业务分层的类,如工具类) | 是 @Service、@Repository 等的 “父注解”,底层逻辑一致,仅语义不同。 |
| @Service | 标记 业务层(Service) 类(处理业务逻辑) | 增强代码可读性,Spring 无特殊处理,纯语义化。 |
| @Repository | 标记 持久层(DAO) 类(操作数据库),自动转换数据库异常为 DataAccessException | 配合 Spring Data/JDBC 等,简化异常处理。 |
| @Controller | 标记 Spring MVC 控制器(处理 HTTP 请求,可返回视图或数据) | 需配合 @RequestMapping 映射接口,传统 MVC 场景常用。 |
| @RestController | @Controller + @ResponseBody 的组合,直接返回 JSON/XML(适合 RESTful API) | 无需在方法上重复加 @ResponseBody,前后端分离场景必用。 |
二、依赖注入(Bean 间自动关联)
让 Spring 自动注入依赖的 Bean,避免硬编码耦合。
| 注解 | 作用与场景 | 关键细节 |
|---|---|---|
| @Autowired | 按类型(by Type) 自动注入依赖,支持字段、构造器、方法注入 | - 推荐构造器注入(明确依赖,保证不可变,利于测试);- 同类型多 Bean 时需配合 @Qualifier。 |
| @Qualifier | 配合 @Autowired,按名称(by Name) 注入指定 Bean(解决同类型歧义) | 需指定 value(Bean 的名称,默认是类名首字母小写)。 |
| @Resource | JSR-250 标准注解,优先按名称(by Name) 注入,失败则按类型(by Type) | 脱离 Spring 框架,更通用;支持 name 属性,如 @Resource(name = “beanName”)。 |
三、配置类与 Bean 声明(替代 XML)
通过代码定义配置和 Bean,替代繁琐的 XML 配置。
| 注解 | 作用与场景 | 关键细节 |
|---|---|---|
| @Configuration | 标记 配置类,类中通过 @Bean 声明 Bean | Spring 会通过 CGLIB 增强配置类,确保 @Bean 方法的 单例性(多次调用返回同一实例)。 |
| @Bean | 标记方法,其返回值作为 Spring Bean 纳入容器管理 | - 方法名默认是 Bean 名称(可通过 name 自定义);- 方法参数可注入其他 Bean。 |
| @Value | 注入 外部配置值(如 application.yml 中的 {key}) | 支持 SpEL 表达式,如 @Value(“${server.port}”)。 |
| @ConfigurationProperties | 批量绑定配置到 POJO(将配置前缀映射到类字段,如 spring.datasource → DataSourceProps) | 比 @Value 更高效(适合复杂配置),需配合 @EnableConfigurationProperties 启用。 |
四、Web 开发(处理 HTTP 请求)
映射请求、解析参数、返回响应,覆盖 RESTful API 开发场景。
| 注解 | 作用与场景 | 关键细节 |
|---|---|---|
| @RequestMapping | 映射 HTTP 请求(类 / 方法级别),支持指定路径、请求方法(GET/POST 等) | 可细粒度控制:params(参数过滤)、headers(头信息过滤)、consumes(请求体类型)等。 |
| @GetMapping | 简化版 @RequestMapping,仅处理 GET 请求 | 等价于 @RequestMapping(method = RequestMethod.GET)。 |
| @PostMapping | 简化版 @RequestMapping,仅处理 POST 请求 | 等价于 @RequestMapping(method = RequestMethod.POST)。 |
| @RequestBody | 将 HTTP 请求体(如 JSON) 绑定到方法参数(自动反序列化) | 需依赖 Jackson 等库(Spring Boot 已默认集成)。 |
| @ResponseBody | 将方法返回值 直接写入 HTTP 响应体(自动序列化为 JSON/XML) | @RestController 已内置此注解,无需重复添加。 |
| @PathVariable | 提取 URL 路径中的变量(如 /user/{id} 中的 id) | 支持正则表达式匹配,如 @PathVariable(“id”) Long userId。 |
| @RequestParam | 提取 URL 查询参数(如 /user?name=张三 中的 name) | 可设置默认值(defaultValue)、是否必填(required)。 |
五、AOP 切面(实现横切逻辑)
通过切面分离日志、权限、事务等通用逻辑,解耦业务代码。
| 注解 | 作用与场景 | 关键细节 |
|---|---|---|
| @Aspect | 标记 切面类,定义横切逻辑(如日志、事务) | 需配合 @Component 让 Spring 扫描到。 |
| @Pointcut | 定义 切点表达式(指定哪些方法会被拦截) | 语法如 execution(* com.example.service..(…))(匹配 service 包下所有方法)。 |
| @Before | 方法执行 前 执行切面逻辑(如参数校验) | 入参可获取 JoinPoint,访问目标方法信息。 |
| @After | 方法执行 后 执行切面逻辑(无论成功 / 失败) | 入参可获取 JoinPoint 或 Throwable(异常信息)。 |
| @Around | 环绕 方法执行(可控制方法调用,如超时处理、权限校验) | 需调用 proceed() 执行目标方法,支持修改返回值或抛出异常。 |
六、事务管理(保证数据一致性)
通过声明式事务简化数据库事务控制,避免手动编写 try-catch。
| 注解 | 作用与场景 | 关键细节 |
|---|---|---|
| @Transactional | 标记方法 / 类需纳入 声明式事务 管理(默认回滚 RuntimeException) | - 配置项:propagation(传播行为,如 REQUIRED)、isolation(隔离级别,如 READ_COMMITTED)、rollbackFor(指定回滚的异常);- 仅对 public 方法生效(代理机制限制)。 |
| @EnableTransactionManagement | 启用 注解式事务管理(Spring Boot 自动启用,无需手动添加) | 需配合事务管理器(如 DataSourceTransactionManager)。 |
七、其他实用注解
解决作用域、延迟加载、测试等场景。
| 注解 | 作用与场景 | 关键细节 |
|---|---|---|
| @Scope | 定义 Bean 的作用域:singleton(单例,默认)、prototype(原型)、request(请求级)等 | 原型模式下,每次注入 / 获取都会新建实例;Web 场景常用 request/session 作用域。 |
| @Lazy | 延迟初始化 Bean(容器启动时不创建,首次使用时创建) | 优化启动时间,或解决循环依赖。 |
| @Primary | 多个同类型 Bean 时,标记为优先注入(全局生效,比 @Qualifier 更通用) | 用于默认实现类,如多个 DataSource 时,标记主数据源。 |
| @DependsOn | 控制 Bean 的初始化顺序(确保依赖的 Bean 先初始化) | 如 @DependsOn(“dataSource”) 确保数据源先于 DAO 初始化。 |
| @SpringBootTest | 启动 完整 Spring Boot 上下文,用于集成测试 | 可指定启动类、环境配置等,模拟真实运行环境。 |
核心使用原则
-
语义优先:用 @Service/@Repository 替代 @Component,增强代码可读性。
-
依赖注入最佳实践:优先 构造器注入(明确依赖,不可变),避免字段注入(不利于测试)。
-
配置解耦:复杂配置用 @ConfigurationProperties 批量绑定,减少 @Value 分散使用。
-
事务注意事项:@Transactional 仅对 public 方法 生效,且需确保事务管理器正确配置。
项目里用AOP了吗,了解吗?
项目里没有直接集成 AOP 框架来开发业务功能,但我专门仿写过 AOP 的实现逻辑,从最基础的静态代理、JDK 动态代理、CGLIB 代理,到模拟 Spring AOP 的工程化配置(比如 XML 定义切面、注解式切入点)都做了实现。通过这个过程,我对 AOP 的面向切面思想有了比较深入的理解,像连接点(目标方法)、切入点(筛选后的增强目标)、通知(前置 / 后置等增强逻辑)、切面(切入点 + 通知的组合)这些核心概念,不仅能说清楚定义,还能对应到具体的代码实现中,比如知道如何通过代理类在目标方法前后插入增强逻辑,如何通过切入点表达式精准匹配需要增强的方法。
(mybatis里)#{}和${}的区别?
①、当使用 #{} 时,MyBatis 会在 SQL 执行之前,将占位符替换为问号 ?,并使用参数值来替代这些问号。
由于 #{} 使用了预处理,所以能有效防止 SQL 注入,确保参数值在到达数据库之前被正确地处理和转义。
<select id="selectUser" resultType="User">SELECT * FROM users WHERE id = #{id}
</select>
②、当使用 ${} 时,参数的值会直接替换到 SQL 语句中去,而不会经过预处理。
这就存在 SQL 注入的风险,因为参数值会直接拼接到 SQL 语句中,假如参数值是 1 or 1=1,那么 SQL 语句就会变成 SELECT * FROM users WHERE id = 1 or 1=1,这样就会导致查询出所有用户的结果。
${} 通常用于那些不能使用预处理的场合,比如说动态表名、列名、排序等,要提前对参数进行安全性校验。
<select id="selectUsersByOrder" resultType="User">SELECT * FROM users ORDER BY ${columnName} ASC
</select>
mybatis一级缓存 二级缓存
一级缓存:默认开启,作用于的单个SqlSession(会话),是Mybatis最基础的缓存机制
工作原理:当通过SqlSession执行一次select查询时,Mybatis会将查询结果(以“MapperId + SQL语句 + 参数”为key )存入SqlSession内部的缓存
若在同一个Sqlsession内,再次执行完全相同的查询(Mapper接口、SQL、参数均一致),Mybatis会直接从缓存只能怪取结果,不在访问数据库
缓存失效场景:
SqlSession关闭:当SqlSession.close()后,一级缓存随会话销毁
执行增删改操作:同一个SqlSession内,若执行了insert/update/delete,Mybatis会主动清空当前SqlSession的一级缓存(避免缓存数据与数据库不一致)
手动清空缓存:调用sqlsession.clearCache()可手动清空当前会话的一级缓存
适用场景:单会话内高频重复查询(如一次请求中多次查询同一用户信息),无需额外配置,开箱即用
**二级缓存:**需手动开启,作用于Mapper(即同一个namespace,通常对应一个Mapper接口或XML)多个SqlSession可共享缓存
工作原理:二级缓存的作用范围是整个namespace(即一个Mapper)缓存数据存储在Mapper的缓存对象中,不依赖于某个SqlSession
当第一个SqlSession执行查询后,关闭会话时(SqlSession.close())查询结果会从一级缓存”刷入“二级缓存
后续其他SqlSession执行相同查询(同一Mapper、SQL、参数)时,会先查二级缓存,命中则直接返回;未命中再查一级缓存,最后查数据库
缓存失效场景:
执行增删改操作:同一namespace下执行insert/update/delete时,Mybatis会清空当前Mapper的二级缓存(保证数据一致性)
缓存过期:<cache/ >标签可配置eviction(回收策略,如LRU最近最少使用)、flushInterval(自动刷新时间)等,过期后缓存会被清理
注意:二级缓存的对象需实现serializable接口(因为缓存可能被序列化到磁盘,默认采用LRU回收策略时会落地)。适合“查询多、修改少”的场景(如字典表、商品分类表);若表频繁修改,会导致缓存频繁失效,反而影响性能
一级缓存:基于PerpetualCache 的 HashMap 本地缓存,存储作用域为SqlSession,各个SqlSession之间的缓存相互隔离,当Session flush或close之后,该SqlSession中的所有Cache就清空,mybatis默认打开一级缓存
二级缓存:默认采用PerpetualCache ,HashMap存储,不同之处在于其存储区域为Mapper,可以在多个SqlSession之间共享,并且可自定义存储源,如Ehcache
关系型数据库有哪些,了解那些
MySQL;Oracle(商业数据库);SQL Server(微软开发)
mysql查询语句
WHERE:按条件筛选数据;ORDER BY:对结果排序(ASC升序 / DESC降序);GROUP BY:按列分组,结合COUNT/SUM等聚合函数做统计;JOIN:关联多表查询关联数据(内连接 / 左连接等);LIMIT:限制结果数量(用于分页);
SELECT s.id AS 学生ID,s.name AS 学生姓名,COUNT(DISTINCT sc.subject_id) AS 及格科目数量 -- 去重统计,避免同一科目多次成绩重复计数
FROM student s
LEFT JOIN score sc ON s.id = sc.student_id -- 关联成绩表,保留所有学生(包括无成绩的)
LEFT JOIN subject sub ON sc.subject_id = sub.id -- 关联科目表(可选,此处用于确认科目有效性)
WHERE sc.score >= 60 -- 筛选及格成绩
GROUP BY s.id, s.name -- 按学生分组
ORDER BY 及格科目数量 DESC; -- 按及格数量降序排列
mysql索引
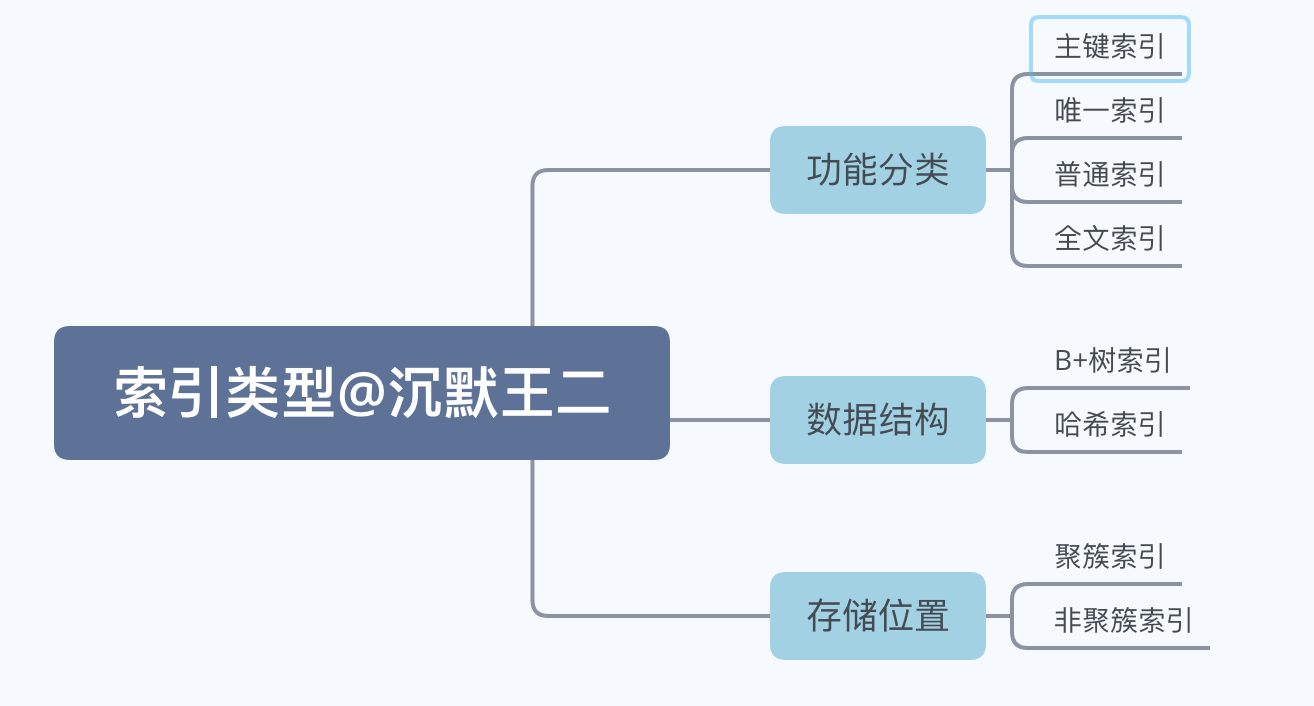
索引的作用
加速搜索:通过索引直接定位数据位置,避免逐行扫描表中所有记录(尤其对大表,效果显著)
辅助排序:索引本身是有序的,可直接利用索引顺序完成ORDER BY排序,无需额外排序操作
一、从功能分(按索引的业务约束/能力划分)
主键索引:表中唯一标识行的字段,要求值唯一且非空
特点:InnoDB中,主键索引同时是聚簇索引(叶子节点直接存数据行),一张表只能有1个主键索引;若表无主键,InnoDB会选首个唯一非空列为隐式主键
唯一索引:强制字段唯一,但允许空值(NULL)(与主键的唯一区别)
特点:物理上是非聚簇索引(InnoDB中叶子节点存主键值,需要回表);可用于约束重复
普通索引:最基础的索引,无唯一性、非空约束,仅加速查询
特点:物理上是非聚簇索引,叶子节点存主键值(需回表);可创建多个,灵活用于各类查询字段
全文索引:针对长文本内容(如 TEXT、VARCHAR)的模糊查询优化,基于倒排索引(分词→映射文档)
特点:MySQL 5.6+ 支持InnoDB/MyISAM,但中文分词能力弱(需依赖第三方分词,或结合Elasticsearch);代替低效的LIKE '%xxx%',但仅支持 MATCH...AGAINST 语法。
二、数据结构分类(按索引底层存储结构划分)
B+树索引(MySQL最核心类型)
平衡多路树,叶子节点有序且通过链表连接,非叶子节点存索引键,叶子节点存数据(聚簇索引)或主键(非聚簇索引)
特点:支持范围查询(如 >、<、BETWEEN)和排序(ORDER BY),因为叶子节点有序。
适配磁盘IO:节点大小适配磁盘块,减少IO次数
哈希索引(Hash Index)
基于哈希表,索引键通过哈希函数映射到存储位置
特点:等值查询极快(时间复杂度O(1)),但不支持范围、排序(哈希结果无序)
MySQl中仅Memory引擎默认支持,InnoDB有自适应哈希索引(内存中对热点数据的优化、自动创建)
三、存储位置分类(按索引与数据的存储关系划分,InnoDB核心概念)
聚簇索引:索引的叶子节点直接存储数据行,数据与索引物理存储顺序一致(按索引键排序)
特点:主键索引就是聚簇索引(若表无主键,选唯一非空列,否则隐式生成)。查索引时直接获取数据,无需额外跳转(效率高)。一张表只能有1个聚簇索引
非聚簇索引(二级索引):索引与数据物理存储分离,叶子节点存储索引键+聚簇索引键(主键),需通过主键”回表“取数据
特点:可创建多个非聚簇索引。查询时需两步:先查非聚簇索引得主键,再查聚簇索引得数据(回表,增加IO)
优化:若查询字段都在非聚簇索引(覆盖索引),可避免回表
最左前缀原则
最左前缀原则:MySQL使用联合索引时,必须从最左边的字段开始匹配,才能命中索引
假设创建了联合索引 idx(a, b, c),以下是不同查询条件下的索引使用情况:
- 包含最左字段
a:where a = 1:使用索引(仅用a部分);where a = 1 and b = 2:使用索引(用a和b部分);where a = 1 and c = 3:使用索引(仅用a部分,c无法利用索引,因为b未参与条件);where a > 1 and b = 2:仅a部分可用(a是范围查询,后续b无法利用索引,因a>1的记录中b无序)。
- 不包含最左字段
a:where b = 2:索引完全不生效;where b = 2 and c = 3:索引完全不生效。
一个联合索引(a,b,c),select * from 表 where a = 33 and b < 44 and c > 22,能用到联合索引吗
能够用到联合索引,但只能利用索引的前两列(a 和 b 部分),c 列的条件无法通过索引优化。
引起索引失效的场景
- 违反联合索引的 “最左前缀原则”
联合索引(如 (a, b, c))的生效依赖于 “从左到右” 的连续匹配。若查询条件不包含最左列,或跳过中间列,会导致索引部分或完全失效。
- 例:索引
(a, b, c),查询where b = 1 and c = 2(缺少最左列a)→ 索引完全失效; - 例:查询
where a = 1 and c = 2(跳过中间列b)→ 仅a部分生效,c无法利用索引。
- 索引列上使用函数或表达式
若对索引列进行函数运算(如 substr(a, 1, 2))或表达式计算(如 a + 1 = 5),数据库会先对每一行的索引列计算结果,再与条件匹配,导致索引无法直接利用(索引存储的是原始值,而非计算后的值)。
- 例:索引
a,查询where substr(a, 1, 2) = 'ab'→ 索引失效; - 例:索引
num,查询where num + 1 = 10→ 索引失效(可改为where num = 9避免)。
- 隐式类型转换
当索引列的类型与查询条件中的值类型不匹配时,数据库会自动进行 “隐式类型转换”,相当于对索引列执行了函数操作,导致索引失效。
- 例:索引列
name是varchar类型,查询where name = 123(条件是数字)→ 数据库会转换为where cast(name as signed) = 123→ 索引失效; - 解决:保证条件值类型与索引列一致,如
where name = '123'。
like以通配符%开头
like 查询中,若匹配模式以 % 开头(如 '%abc'),索引无法利用(索引是按 “前缀有序” 存储的,% 开头会导致无法确定起始位置)。
- 例:索引
name,查询where name like '%abc'→ 索引失效; - 例外:
like 'abc%'(%在末尾)可利用索引的前缀匹配。
- 使用不等判断(
!=、<>、not in、is not null)
对于非主键索引,使用不等判断(如 a != 5、a not in (1,2))时,优化器可能认为匹配的记录较多,全表扫描比索引查询更快,从而放弃索引。
- 例:索引
a,查询where a != 3→ 可能索引失效; - 注意:主键索引因唯一性,
!=可能仍会使用索引(视数据分布而定)。
or条件中包含非索引列
or 连接的条件中,若存在某一列未建立索引,则整个查询可能无法使用索引(因为需要同时扫描索引和非索引列,优化器倾向于全表扫描)。
- 例:索引
a,查询where a = 1 or b = 2(b无索引)→ 索引失效; - 解决:给
b也建立索引,或避免or改用union。
- 范围查询(
>,<,between)截断后续索引
联合索引中,若某一列使用范围查询(如 a > 5),则其右侧的索引列无法利用(因范围查询后的数据无序,破坏了联合索引的排序结构)。
- 例:索引
(a, b, c),查询where a > 10 and b = 2→ 仅a部分生效,b无法利用索引; - 例外:
=是等值查询,不会截断(如a = 10 and b > 5,a和b均可利用索引)。
- 查询数据量过大(优化器选择)
若查询结果集占表数据的比例过高(如超过 30%),优化器可能认为全表扫描比 “通过索引定位 + 回表取数据” 更高效,从而主动放弃索引。
- 例:表有 100 万行,查询
where status = 1匹配 50 万行 → 可能索引失效。
- 索引列存在
null值且使用is null
部分数据库(如 MySQL)中,索引不存储 null 值的位置信息(或处理方式特殊),若索引列存在大量 null,查询 where a is null 可能无法有效利用索引。
一个基础服务,只有 Java 应用、MySQL,没有 Redis,没有其他中间件,线上发现服务变慢,排查思路
第一步:快速定位资源瓶颈(5 分钟内)
用系统工具(top、htop)观察服务器实时资源占用,重点看:
- CPU 使用率:Java 进程(如
java)和 MySQL 进程(mysqld)的%CPU是否持续超过 80%; - 内存占用:两者的
RES(物理内存)是否接近服务器总内存,或存在内存泄漏(持续增长不释放); - IO 等待:
top中%wa(IO 等待占比)是否超过 20%(可能是 MySQL 频繁读写磁盘)。
第二步:针对性排查(根据资源瓶颈)
情况 1:Java 进程 CPU / 内存占比高 → 聚焦 Java 应用
-
CPU 高
-
用jstack
<Java进程ID>导出线程栈,搜索RUNNABLE状态且占用 CPU 高的线程(结合top -H -p <PID>看线程 ID),排查是否有:- 死循环、递归调用(代码逻辑问题);
- 频繁 GC(用
jstat -gcutil <PID> 1000看YGCT/FGCT是否每秒多次); - 大量同步代码块竞争(线程栈中
BLOCKED状态多,且锁定同一对象)。
-
-
内存高
- 用
jmap -heap <PID>查看 JVM 堆配置(如Xms/Xmx是否过小,老年代是否占满); - 用
jmap -histo:live <PID>看存活对象,是否有异常多的对象(如ArrayList、String,可能是内存泄漏); - 若怀疑泄漏,导出堆快照(
jmap -dump:format=b,file=heap.hprof <PID>),用 MAT 工具分析大对象来源。
- 用
情况 2:MySQL 进程 CPU / 内存占比高 → 聚焦 MySQL
-
CPU 高
-
用
show processlist;查看当前 SQL,是否有大量Sending data(执行中)、Sorting result(排序耗时)的语句; -
开启慢查询日志(
set global slow_query_log=1),抓long_query_time(如 1 秒)以上的 SQL,用explain分析:
- 是否全表扫描(
type: ALL)、是否用对索引(key: NULL可能索引失效); - 是否有大表排序 / 分组(
Using filesort/Using temporary,内存不足时会写磁盘)。
- 是否全表扫描(
-
-
内存高
- 检查
innodb_buffer_pool_size(缓冲池)是否过大(超过服务器内存 70%,导致系统 OOM); - 查看连接数(
show status like 'Threads_connected')是否超过max_connections,导致频繁创建连接占用内存。
- 检查
情况 3:两者资源都正常 → 排查交互逻辑
此时性能问题多源于 “应用与数据库的协作低效”,重点检查:
- 连接池配置
- 应用连接池(如 HikariCP)的
maxPoolSize是否过小(并发请求时等待获取连接,日志中可能有waiting for available connection); - 连接超时设置(
connectionTimeout)是否过短(频繁抛连接超时异常),或过长(无效等待拖慢响应)。
- 应用连接池(如 HikariCP)的
- 数据库交互频率
- 是否有 “N+1 查询”(如循环查数据库,1 次查列表 + N 次查详情);
- 是否频繁执行小事务(如每次请求单独开事务,事务开销占比高)。
- 事务设计
- 是否有长事务(
show engine innodb status\G看TRANSACTIONS,运行时间超过 10 秒),导致锁持有久,阻塞其他请求; - 是否滥用
select for update(悲观锁),高并发下导致锁争用。
- 是否有长事务(
动态数组
ArrayList核心特点
动态扩容:无需预先指定固定大小,元素数量超过当前容量时会自动扩容
随机访问高效:通过索引(如get(index))访问元素的时间复杂度为O(1)
连续内存存储:元素在内存中连续排列(底层依赖Object[]数组)保证访问效率
非线程安全:多线程环境下并发修改可能导致异常(如需线程安全,可使用Collections.synchronizedlist()或CopyOnWriteArrayList)
动态扩容:
- 触发时机:当添加元素后,元素数量(
size)等于底层数组容量(当前长度)时,触发扩容。 - 容量计算:
- 默认策略:新容量 = 原容量的 1.5 倍(通过位运算
oldCapacity + (oldCapacity >> 1)实现)。 - 特殊情况:初始为空时(容量 0)直接扩至 10;若计算的新容量不足,直接用所需最小容量。
- 默认策略:新容量 = 原容量的 1.5 倍(通过位运算
- 核心操作:创建新容量的数组,通过
Arrays.copyOf()复制原元素,替换底层数组完成扩容。 - 注意:扩容的数组复制是 O (n) 耗时操作,提前指定初始容量可减少扩容次数优化性能。
Linux命令
文件 / 目录操作
pwd:显示当前路径cd 目录:切换目录(cd ~回家目录,cd ..上一级)ls:列目录内容(ls -l详细,ls -a显隐藏文件)mkdir 目录:创建目录(mkdir -p a/b递归创建)rm 文件/目录:删除(rm -r删目录,rm -f强制)cp 源 目标:复制(cp -r复制目录)mv 源 目标:移动 / 重命名
文件内容
cat 文件名:查看全文head -n 5 文件名:看前 5 行;tail -f 文件名:实时监控尾部grep "关键词" 文件名:搜索(grep -r递归搜目录)
系统资源
df -h:磁盘空间(人类可读格式)free -h:内存使用top:实时进程监控(按q退出)uname -a:查看系统信息
用户 / 权限
sudo 命令:以 root 权限执行chmod 755 文件名:改权限(r=4,w=2,x=1;7 = 读 + 写 + 执行)chown 用户:组 文件名:改所有者
进程管理
ps aux:查看所有进程kill -9 PID:强制终止进程(PID 通过 ps 获取)
网络
ping 域名/IP:测试连通性netstat -tuln:查看监听端口curl 网址/wget 网址:请求 / 下载网络内容
压缩 / 解压
tar -czvf 包名.tar.gz 目录:压缩tar -xzvf 包名.tar.gz:解压
其他
find 路径 -name "文件名":查找文件man 命令:查看命令帮助history:查看命令历史
git命令
仓库初始化与克隆
git init:在当前目录初始化本地仓库git clone <远程仓库地址>:克隆远程仓库到本地(如git clone https://github.com/xxx/xxx.git)
文件状态与提交
git status:查看工作区文件状态(已修改 / 未跟踪等)git add <文件>:将文件添加到暂存区(git add .添加所有修改)git commit -m "提交说明":将暂存区内容提交到本地仓库git diff:查看工作区与暂存区的修改差异git log:查看提交历史(git log --oneline简洁显示)
分支管理
git branch:列出本地分支(git branch -r查看远程分支)git checkout -b <新分支名>:创建并切换到新分支git checkout <分支名>:切换到已有分支git merge <分支名>:将指定分支合并到当前分支git branch -d <分支名>:删除本地分支(-D强制删除未合并分支)
远程仓库操作
git remote:查看关联的远程仓库(git remote -v显示详细地址)git pull:拉取远程仓库最新代码并合并到本地git push:将本地提交推送到远程仓库(首次推送分支:git push -u origin <分支名>)
撤销与回滚
git checkout -- <文件>:放弃工作区对文件的修改git reset HEAD <文件>:将暂存区的文件移除(保留工作区修改)git revert <提交ID>:创建新提交以撤销某次提交(安全,不修改历史)
其他实用命令
git stash:暂存当前工作区修改(用于临时切换分支)git stash pop:恢复最近一次暂存的修改git tag <标签名>:给当前提交打标签(如版本号git tag v1.0)git fetch:拉取远程仓库最新信息(不自动合并)
merge和rebase都是git中整合不同分支
merge(合并)
作用:将目标分支的修改合并到当前分支,创建一个新的合并提交
特点:保留原分支的完整提交历史,历史记录会显示”分支合并“的节点(像一个分叉后又回合的树)
场景:适合公开分支(如main、develop)的合并,多人协作时能清晰追溯分支演进
rebase(变基)
作用:将当前分支的所有提交“移动”到目标分支的最新提交之后,形成线性历史(无合并节点)
特点:改写当前分支的提交历史,让历史看起来像“一条直线”,更整洁
场景:适合个人开发分支或未公开的分支,整理提交记录后再合并到主分支,方便review
Redis 常用数据结构
1. String(字符串)
- 特点:最基础的键值对,二进制安全(可存文本、图片二进制等),value 最大 512MB。
- 常用命令:
SET key value(设值)、GET key(取值)、INCR key(自增)、EXPIRE key sec(设过期时间)。 - 场景:缓存(如用户信息)、计数器(如文章阅读量)、分布式锁、限流。
2. Hash(哈希)
- 特点:键值对集合(类似 JSON 对象),适合存储结构化数据,每个 hash 可存 2^32-1 个字段。
- 常用命令:
HSET key field value(设字段)、HGET key field(取字段)、HMGET key field1 field2(批量取)、HDEL key field(删字段)。 - 场景:存储对象(如用户资料:
user:100 {name: "xxx", age: 20})、商品属性。
3. List(列表)
- 特点:有序、可重复的元素集合,基于双向链表实现,两端操作高效。
- 常用命令:
LPUSH key value(左加)、RPOP key(右删)、LRANGE key start end(取范围元素)、LLEN key(长度)。 - 场景:消息队列(FIFO 特性)、最新列表(如朋友圈动态)、栈 / 队列实现。
4. Set(集合)
- 特点:无序、不可重复的元素集合,支持交集、并集、差集运算。
- 常用命令:
SADD key member(加元素)、SMEMBERS key(取所有元素)、SINTER key1 key2(交集)、SUNION key1 key2(并集)。 - 场景:标签(如文章标签去重)、好友关系(共同好友)、抽奖(随机取元素)。
5. Sorted Set(有序集合)
- 特点:类似 Set,但每个元素关联一个「分数(score)」,按分数排序,不可重复。
- 常用命令:
ZADD key score member(加元素)、ZRANGE key start end(按分数升序取)、ZREVRANGE key start end(降序取)、ZSCORE key member(查分数)。 - 场景:排行榜(如游戏积分排名)、范围查询(如按分数筛选用户)。
ThreadLocal
ThreadLocal 为每个线程创建一个变量的私有副本,线程对变量的操作仅影响自身副本,不干扰其他线程,实现线程隔离。ThreadLocal 的实现依赖于 Thread 内部的一个 ThreadLocalMap 对象
线程池参数
corePoolSize 核心线程数,maximumPoolSize 最大线程数,workQueue 新任务来后,判断当前运行的线程数量是否达到最大,若达到,新任务放在队列中,keepAliveTime 不会立即销毁,会等待,unit keepActiveTime 时间单位,threadFactory executor 创建新线程会用到,handler 饱和策略
synchronized
互斥性:同一时刻只有一个线程能执行被 synchronized 修饰的代码块(或方法);可见性:线程在释放锁时,会将修改的变量同步到主内存;获取锁时,会从主内存读取最新变量值(避免线程缓存导致的数据不一致);原子性:确保被修饰的代码块作为一个整体执行,不会被其他线程打断。修饰普通方法,锁住当前实例;修饰静态方法,锁住当前类的对象;修饰代码块
并发安全的容器
阻塞队列、vector、StringBuffer、ConcurrentHashMap、Hashtable、Collections.synchronizedList
concurrenthashmap是怎么完成线程安全的
ConcurrentHashMap 是 Java 中用于高并发场景的线程安全哈希表,JDK1.7 中采用分段锁机制,核心是将整个哈希表分割为多个独立段;JDK1.8 中抛弃了分段锁,采用数组 + 链表 + 红黑树的结构,通过 CAS 原子操作和 synchronized 关键字实现线程安全