Syzkaller实战教程5: 初始种子加载机制剖析第一集
本文主要分析了syzkaller在旧版本和25年新版本上各自从存放种子的corpus.db中加载初始种子的过程,而初始种子在加载完毕后仍需经过复杂的队列调度执行,限于篇幅原因,这部分内容在第二集中进行说明。
一.25年版本Syzkaller初始种子加载机制
1. 传递流程
初始种子从输入到到开始fuzzing的传递路径:
corpus.db+seed → candidate → candidatequeue → triageCandidatequeue → corpus → smashqueue → 执行smashqueue时偶尔跳过执行其它queue → 其余队列为空时genfuzz →direct Fuzz → has signal? → triagequeue → valid seed? → corpus
(corpus/333) +? → choiceTable_update →指导generation (candidatequeue||triagecandidatequeue||triagequeue) == 0 → genfuzz →......
2. manager.go 代码分析
manager.go 是 syzkaller 的核心调度模块,实现了语料库管理、模糊测试循环、崩溃处理、Dashboard 交互等关键功能。
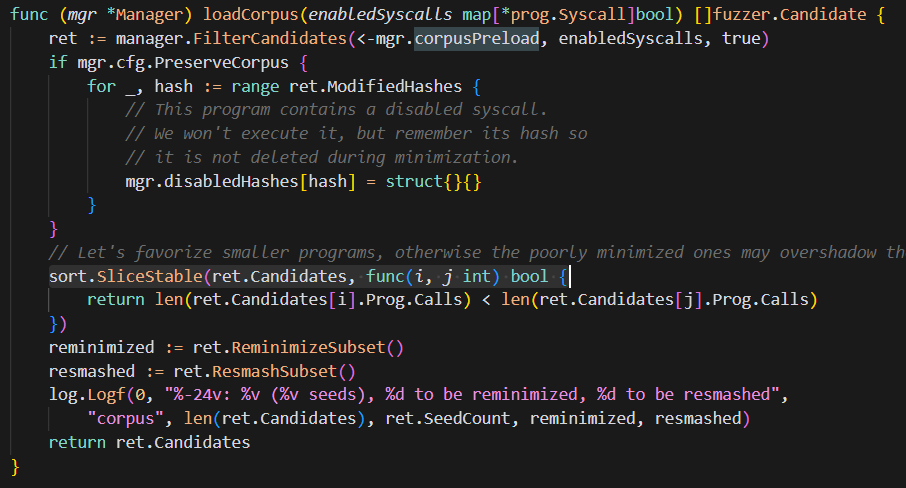
candidate中的顺序不是按照读取顺序排列的,需要经过稳定排序,使得较短的程序(系统调用数量更少)优先执行,并且一次性入队至candidatequeue中:
AddCandidates函数,该函数遍历所有候选,为每个候选创建一个请求,并调用enqueue方法,将请求提交到candidateQueue(类型为PlainQueue)。(在实现上,每个请求都会通过Submit方法添加到PlainQueue的队列中)
func(fuzzer *Fuzzer)AddCandidates(candidates []Candidate){fuzzer.statCandidates.Add(len(candidates))for_,candidate range candidates{req :&queue.Request(Prog:candidate.Prog,ExecOpts:setFlags(flatrpc.ExecFlagCollectSignal)Stat:fuzzer.statExecCandidate,Important:true,}fuzzer.enqueue(fuzzer.candidateQueue,req,candidate.Flags]progCandidate,0)}
}下图为23年3月syzkaller的初始种子排序策略:随机排序+重复
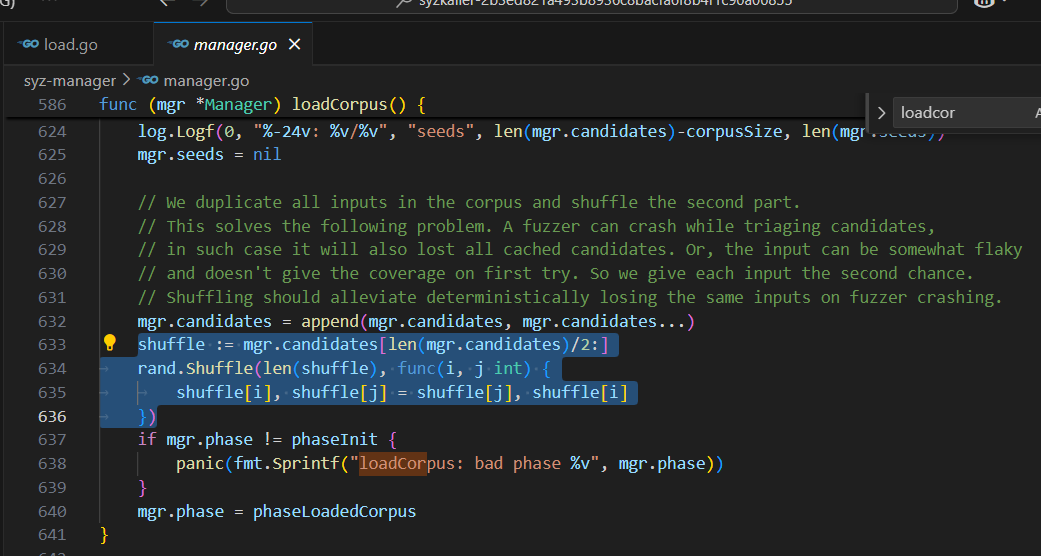
将候选测试输入 mgr.candidates 复制一份,并对第二部分进行随机化(打乱顺序)。
以下为官方注释的翻译:
// 我们将语料库中的所有输入复制一份,并对第二部分进行随机打乱。
// 这样可以解决以下问题:模糊测试器在分类候选输入时可能会崩溃,
// 在这种情况下,它也会丢失所有缓存的候选输入。或者,有些输入可能具有不稳定性,
// 第一次尝试时无法覆盖预期的代码路径。因此,我们为每个输入提供第二次机会。
// 随机打乱可以缓解模糊测试器崩溃时确定性地丢失相同输入的问题。
目的是解决以下问题:
① 如果模糊测试器在候选输入分类(triaging)时崩溃,可能会丢失缓存的候选输入。
② 某些输入可能具有不稳定的行为,第一次尝试可能无法覆盖预期的代码路径。
③ 通过重复和随机化,增加输入被重新尝试的机会。
corpus.db添加到candidate:
loadCorpus将对candidate中的程序进行如下操作
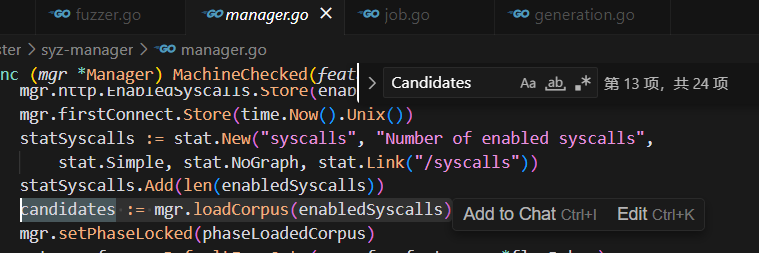
LoadSeeds(seed.go) → mgr.Candidates → preloadCorpus → mgr.corpusPreload → loadCorpus
→ 排序后的mgr.Candidates
loadseed是按照原始顺序顺序读取corpus.db中的内容,读取之后会对所有初始种子进行稳定排序,Candidate加载过程分析及顺序说明::
1. 预加载阶段(preloadCorpus):
① 通过manager..LoadSeeds((mgr.cfg,false)加载种子程序,返回的info包含原始candidates
② 将加载的candidatesi通过channel2发送:mgr.corpusPreload<-info.Candidates
③ 此阶段保持原始存储顺序(文件系统读取顺序或数据库存储顺序)
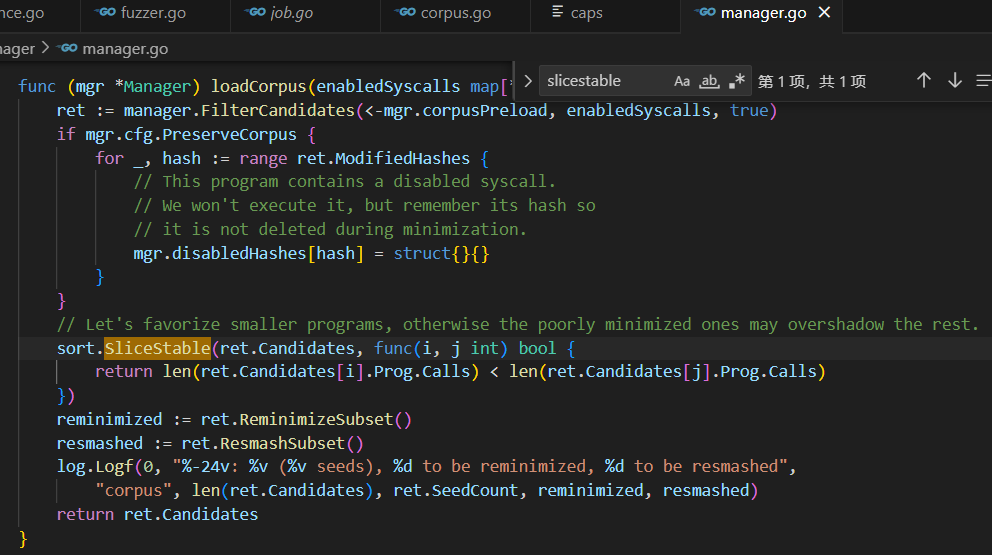
2. 正式加载阶段(loadCorpus):
ret manager.FilterCandidates(<-mgr.corpusPreload,enabledsyscalls,true)
sort.slicestable(ret.Candidates,func(i,j int)bool{return len(ret.Candidates[i].Prog.Calls)<len(ret.Candidates[j].Prog.Calls)
})从channel接收预加载的candidates后,使用稳定排序算法对candidatesi进行重新排序
3. 排序规则:
① 按调用次数升序排列,保证len(Calls)较小的程序优先
② 使用SliceStable保证相同长度的程序保持原有相对顺序
③ 排序后顺序与原始加载顺序不同。
4. 顺序变化示意图:
原始加载顺序:程序A(5calls)→程序B(3calls)→程序C(4calls)
↓排序后
最终内存顺序:程序B(3)→程序C(4)→程序A(5)
5. 设计考量:
① 优先处理简单程序有利于快速覆盖基础执行路径
② 防止大型程序过早占据测试资源
③ 保持稳定性避免随机性干扰测试过程
相关源码如下图所示:
3. corpus.go 代码分析
功能: Syzkaller 语料库管理,加入/合并新的数据
1. 核心数据结构
① Corpus结构体
作用:管理内存中的语料库,包含所有种子程序及其元数据。
关键字段:
- progsMap:哈希表(map[string]*tem),以程序哈希(Sig)为键,存储所有种子程序的元
- 数据(Item对象)
- signal:全局信号(覆盖率)的聚合,用于指导模糊测试方向”。
- cover:全局代码覆盖率数据,通过KCOV机制收集”。
- focusAreas:支持多焦点区域的覆盖分析(如特定内核模块的定向测试)”。
② Item结构体
作用:表示单个种子程序的元数据。
关键字段:
- Prog:存储序列化的系统调用程序(prog.Prog对象),使用Syzkaller的DSL格式”。
- Signal:该程序触发的覆盖率信号(基本块哈希集合)。
- Cover:具体的覆盖点(PC地址集合)。
- Updates:记录程序在多次执行中的覆盖变化(用于动态优化)”。
2. 核心操作流程
① 保存新程序(Save方法)
输入:包含程序、调用索引、信号和覆盖率数据。
处理逻辑:
- 序列化与哈希:通过prog.Serialize()将程序序列化为字节流,计算哈希Sg
- 去重检查:若progsMap中已存在相同哈希的程序,合并信号和覆盖率(避免重复存储)。
- 焦点区域匹配:通过applyFocusAreas()方法判断程序是否属于特定测试焦点(如网络子系统)并更新对应统计。
- 事件通知:通过updates通道发送新程序事件,触发持久化操作(如写入corpus.db)。
② 持久化与同步
- 与corpus..db的关系:syz-db工具通过SQLite操作corpus.db,而corpus.go负责内存中的语料库管理。
- 序列化格式:prog.Serialize()生成的二进制数据与corpus.db中prog字段的存储格式一致。
3. 覆盖率引导机制
① 信号合并
- 全局信号:corpus.signal聚合所有程序的覆盖率信号,用于评估新生成的程序是否带来新覆盖。
- 动态更新:当新程序触发新程盖时,通过signal..Merge()和cover.MergeDiff()更新全局状态。
② 焦点区域优化
- 实现:focusAreaState结构体支特为不同测试目标(如特定子系统)维护独立的程序列表和统计。
- 应用场景:在定向测试中,优先选择与目标区域相关的程序进行变异。
4. 与Syzkaller其他模块的交互
- 与syz-fuzzer:语料库提供种子程序供模糊器选择和变异
- 与syz-manager:通过updates通道同步新程序到持久化存储
- 与syz-executor:执行程序后返回的覆盖率数据通过Newlnput反馈到语料库
5. 两类corpus的概念对比
Syzkaller实际上有两种不同但相关的corpus概念:
在一次完整的fuzzing运行中,持久化corpus主要在启动时起作用,提供初始候选集。运行过程中,fuzzing主要依赖内存中的corpus进行突变和选择。
持久化corpus的真正价值在于跨运行保持进度,确保每次重启syzkaller时不必从零开始。
1.持久化Corpus (corpus.db)
①位置:存储在磁盘上,通常是workdir/corpus.db文件
②内容:包含所有历史发现的有价值种子
③作用:在不同运行之间保持种子,确保不丢失已发现的覆盖率
④增长方式:当新的有价值种子被发现时追加保存
⑤管理:通过minimizeCorpusLocked()函数定期优化
2.内存工作集Corpus
①位置:运行时内存中,由Corpus结构体管理
②内容:当前运行中已验证有效的种子
③作用:作为实际fuzzing的基础,提供突变源
④增长方式:随着candidates验证过程逐渐填充
⑤管理:通过内存中的数据结构动态管理
启动后的fuzzing过程基本上不再直接使用持久化corpus:
1.突变来源:从内存corpust中选择种子
p :fuzzer.Config.Corpus.ChooseProgram(rnd)
2.ChoiceTable更新:使用内存corpus的程序
progs :fuzzer.Config.Corpus.Programs()
3.新种子处理:直接添加到内存corpus,同时异步保存到特久化corpus
fuzzer.Config.Corpus.5ave(input)/添加到内存
mgr.corpusDB.Save(update.Sig,update.ProgData,0)/异步保存到磁盘输出日志的各项指标含义如下:
corpus=0:当前运行中已验证并添加到内存工作集的种子数量,而非corpus.db中的总数
这指的是内存中当前已验证有效并添加到工作集corpus的种子数量
它不是指磁盘上corpus.db中存储的总种子数量
这个值从0开始,随着候选种子被验证有效后逐渐增加
candidates=9954:
这是从磁盘加载的候选种子总数
这些种子需要在当前环境下再次验证其有效性
第一次运行的输出日志:
2025/03/07 16:13:40 exec total=637 (378/min) pending=0 reproducing=02025/03/07 16:13:40 corpus : 9954 (61 seeds), 4 to be reminimized, 0 to be resmashed2025/03/07 16:13:50 candidates=9954 corpus=0 coverage=0 exec total=637 (344/min) pending=0 reproducing=0第二次运行的输出日志:
2025/03/07 16:25:29 corpus : 10500 (56 seeds), 4 to be reminimized, 0 to be resmashed2025/03/07 16:25:37 candidates=10500 corpus=0 coverage=0 exec total=637 (378/min) pending=0 reproducing=02025/03/07 16:25:47 candidates=10468 corpus=0 coverage=0 exec total=693 (374/min) pending=0 reproducing=06. Syzkallerr中corpus保存机制分析
从代码中可以看到,Syzkaller的corpus保存机制有以下特点:
保存到磁盘的触发条件:
func (mgr *Manager)corpusInputHandler(updates <-chan corpus.NewItemEvent){
for update :range updates//...if update.Exists//已存在的种子不会再次保存continue}mgr.corpusDBMu.Lock()mgr.corpusDB.Save(update.sig,update.ProgData,0)if err :mgr.corpusDB.Flush();err != nillog.Errorf("failed to save corpus database:%v",err)}mgr.corpusDBMu.Unlock()}
}
关键点在于:
- 只保存新种子:只有新添加到corpus的程序才会触发保存操作(update.Exists检查)
- 每个新种子立即Flush:每次保存新种子后就调用corpusDB.Flush()将数据写入磁盘
- 使用互斥锁:使用corpusDBMu确保并发安全,可能会导致短暂的线程阻塞
7. 两类corpus的使用分析
突变和更新choicetable使用的corpus都是本次运行中已验证并添加到内存工作集的种子集合,而不是磁盘上的所有种子
1. 突变时使用的Corpus
在job.go中的mutateProgRequest函数:
func mutateProgRequest(fuzzer *Fuzzer, rnd *rand.Rand) *queue.Request {p := fuzzer.Config.Corpus.ChooseProgram(rnd)if p == nil {return nil}newP := p.Clone()newP.Mutate(rnd,prog.RecommendedCalls,fuzzer.ChoiceTable(),fuzzer.Config.NoMutateCalls,fuzzer.Config.Corpus.Programs(),)return &queue.Request{Prog: newP,ExecOpts: setFlags(flatrpc.ExecFlagCollectSignal),Stat: fuzzer.statExecFuzz,}
}① fuzzer.Config.Corpus.ChooseProgram(rnd) - 用于选择突变的基础程序
② fuzzer.Config.Corpus.Programs() - 用于突变过程中可能的交叉突变
这个Config.Corpus指向的是corpus.Corpus对象,在前面提到的corpus.go文件中。通过回顾corpus.go中的代码,可以确认:
func (corpus *Corpus) ChooseProgram(rnd *rand.Rand) *prog.Prog {corpus.mu.RLock()defer corpus.mu.RUnlock()// 选择内存中的corpusret := corpus.ProgramsList.ChooseProgram(rnd)return ret
}ProgramsList是通过corpus.saveProgram方法填充的,而saveProgram方法只在有新种子被添加到corpus时才被调用:
func (corpus *Corpus) Save(inp NewInput) {// ...if !exists {// 新种子添加// ...corpus.saveProgram(inp.Prog, inp.Signal)}// ...
}2. ChoiceTable更新时使用的Corpus
在fuzzer.go中
func (fuzzer *Fuzzer) choiceTableUpdater() {for {select {case <-fuzzer.ctx.Done():returncase <-fuzzer.ctRegenerate:}fuzzer.updateChoiceTable(fuzzer.Config.Corpus.Programs())}
}func (fuzzer *Fuzzer) ChoiceTable() *prog.ChoiceTable {progs := fuzzer.Config.Corpus.Programs()fuzzer.ctMu.Lock()defer fuzzer.ctMu.Unlock()// There were no deep ideas nor any calculations behind these numbers.regenerateEveryProgs := 333if len(progs) < 100 {regenerateEveryProgs = 33}if fuzzer.ctProgs+regenerateEveryProgs < len(progs) {select {case fuzzer.ctRegenerate <- struct{}{}:default:// We're okay to lose the message.// It means that we're already regenerating the table.}}return fuzzer.ct
}fuzzer.Config.Corpus.Programs()被用来获取程序列表。同样查看corpus.go中的实现:
func (pl *ProgramsList) Programs() []*prog.Prog {pl.mu.RLock()defer pl.mu.RUnlock()ret := make([]*prog.Prog, len(pl.progs))copy(ret, pl.progs)return ret
}这个方法返回的是ProgramsList.progs,这是一个只在内存中维护的列表,包含了本次运行中已验证并添加到内存工作集的种子。
因此,ChoiceTable更新也是使用本次运行中已验证并添加到内存工作集的种子集合,而不是磁盘上的所有种子。
4. prio.go 代码分析
实现基于权重的随机选择算法,用于高效选择种子程序进行变异。
对corpus中的程序进行优先级排序,并采用chooseprogram()依据优先级随机地选取程序进行fuzzing。
sumPrios 和 accPrios 是用于实现基于优先级的加权随机选择的关键数据结构。它们共同作用,确保高优先级的程序(即触发更多覆盖率信号的程序)有更高的概率被选中进行变异,极大地优化了选择的时间效率:
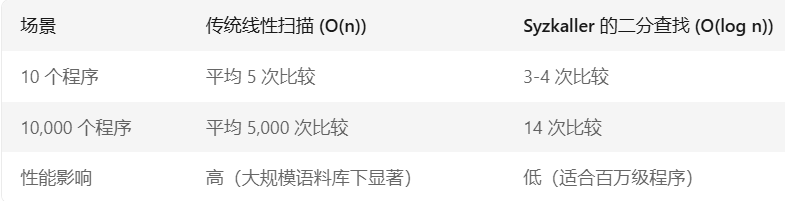
1.核心数据结构ProgramsList
type ProgramsList struct{progs []*prog.Prog //存储程序对象的切片sumPrios int64 //所有程序的优先级总和accPrios []int64 //累积优先级巍组(用于快速选择)
}该结构体实现基于权重的随机选择算法,用于高效选择种子程序进行变异。通过预计算累积优先级(accPrios),将随机选择的时间复杂度优化至O(logn),且支持动态更新:新增程序时自动更新sumPrios和accPrios。
一个示例如下:
初始状态:sumPrios=0,accPriosa=[ ]
添加程序A(prio=3)→sum=3,acc=[3]
添加程序B(prio=4)→sum=7,acc=[3,7]
添加程序C(pri0=5)→sum=12,acc=[3,7,12]
2. 基础选择算法chooseProgram
func (pl *ProgramsList)chooseProgram(r *rand.Rand)*prog.Prog{randVal :=r.Int63n(pl.sumPrios +1)idx :=sort.Search(len(pl.accPrios),func(i int)bool{return pl.accPrios[i]>=randVal})return pl.progs[idx]
}实现机制:
1.生成随机数randVal∈[0,sumPrios]
2.通过二分查找定位累积数组中第一个≥randVal的索引
这种处理相比线性遍历,算法复杂度从O(n)降为O(logn),适合处理大规模语料库。
一个示例如下:
accPrios = [3,7,12](累积优先级)
sumPrios =12
随机数范围:0~12
若randVal=5→找到索引1(7≥5)5. seed.go 代码分析
seeds.go 负责在初始启动时加载和管理模糊测试的种子(预定义测试用例)及初始语料库数据库 (corpus.db)。主要功能包括:
种子加载:从文件系统读取预定义测试用例 (
sys/<OS>/test/*)。语料库管理:维护持久化语料库数据库,支持版本升级与数据过滤。
程序解析与过滤:解析种子和语料库中的程序,过滤不符合当前配置的用例。
优化标志处理:根据版本标记程序是否需重新最小化(Minimized)或粉碎(Smashed)。
candidates用于初始化模糊测试,包含的种子内容为seed(syzkaller提供的固定初始种子)+corpus.db(此次执行时加载的初始种子集)
1. 核心数据结构Seeds
用于封装加载后的种子和语料库数据,供模糊测试器(fuzzer)使用。
字段如下:
- CorpusDB*db.DB:语料库数据库句柄。
- Fresh bool:标记是否为全新语料库(无历史数据)。
- Candidates [ ]fuzzer.Candidate:候选测试用例列表,用于初始化模糊测试。
2.input结构体
用于统一处理种子和语料库程序的解析流程。
字段如下:
- IsSeed bool:是否为预定义种子(非语料库)。Key:语料库数据库键(哈希值)。
- Path:种子文件路径。
- Data []byte:原始程序数据。
- Prog*prog.Prog:解析后的程序对象。
- Err error:解析错误。
2. 核心操作
1.初始化数据库连接:
打开位于工作目录下的corpus.db数据库。若immutable为false,数据库以可写模式打开。若打开失败且数据库对象为nil,直接返回错误;否则记录错误日志但继续执行。
2.判断数据库是否为空:
若数据库中没有记录(len(info.CorpusDB.Records)==0),标记info.Fresh为true,表示需要初始化
新数据。
3.并发读取输入:
启动goroutine调用readInputs函数,从数据库读取测试用例,并将结果通过outputs通道发送。使用chErr通道捕获可能的错误。
4.处理输入数据:
遍历outputs通道中的输入(inp),检查有效性。无效输入时,区分种子(IsSeed)与普通语料库条日,记录错误计数。有效输入时,若为种子且哈希已存在于数据库,则跳过:否则将输入加入候选列表(candidates)设置标志位(如ProgMinimized)。
5.错误处理与清理:
检查chr中的错误,确保所有输入处理完成。记录损坏的种子/语料库数量,若非immutable模式,删除损坏的语料库条目并刷新数据库。调用DiscardData释放数据库内存,避免资源浪费。
6.返回结果:
将处理后的候选列表(candidates)存入info,返回给调用方用于后续模糊测试。
二.旧版本Syzkaller初始种子加载机制
重点区别是workqueue里的workCandidate的来源和使用方式(22年syzkaller/syz-fuzzer/proc.go)
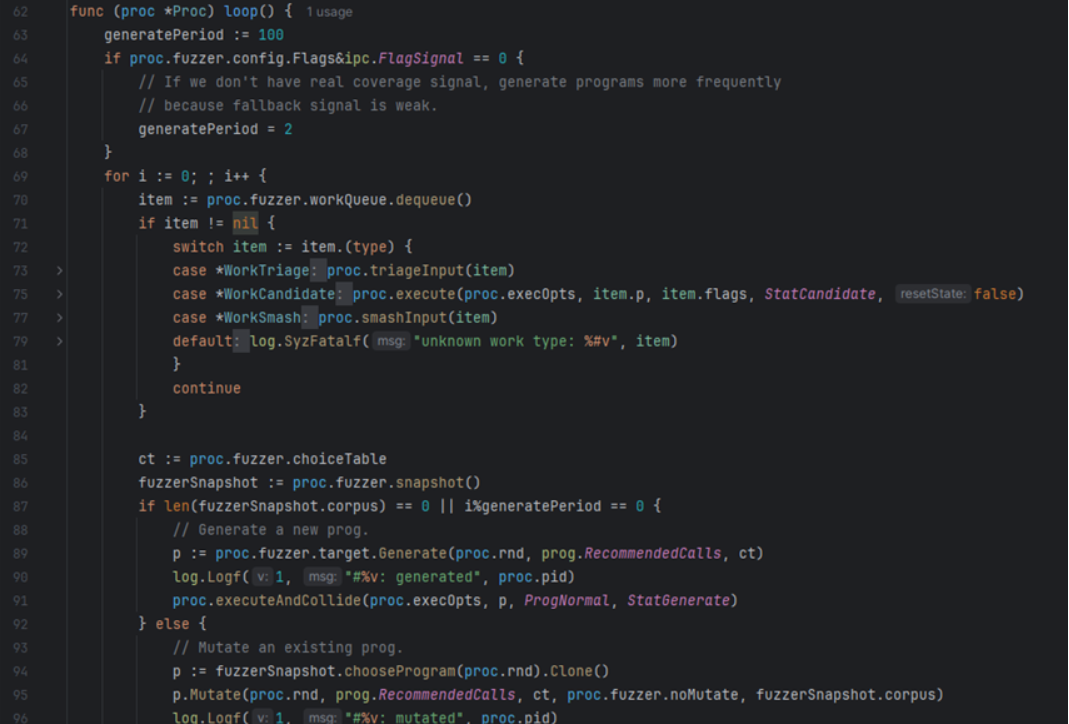
fuzzer.go涉及到生成新的候选输入candidate
程序/种子的最后执行是下图中的proc.execute
1. 加载corpus.db到candidate
本地corpus.db→manager.go中的loadCorpus() 将 db 中所有的语料库加载到 candidates
“在加载程序之前,会调用checkProgram函数来检查程序是否有效,并且会检查程序中是否包含禁用的系统调用。如果程序中包含了禁用的系统调用,根据配置选项的不同,会有两种处理方式:
①如果配置选项PreserveCorpus被设置为true,则该程序不会被执行,但是其哈希值会被记录下来,以防止在最小化过程中被删除。
②如果配置选项PreserveCorpus没有被设置为true,则会从程序中删除禁用的系统调用,并将剩余部分作为候选程序加入到管理器的候选程序列表中。
最后,无论是否包含禁用的系统调用,程序都会被添加到管理器的候选程序列表(即mgr.candidates)中,并返回true表示加载成功。“
加载过程涉及到seed.go:将corpus中的程序解析为 prog.Prog 对象,解析出的候选程序会被保存到 Seeds 的 Candidates 字段中,不再是21年syzkaller的mgr.candidates
2. workcandidate功能
poll()取得 candidates ,从 Candidates 提取出程序并加入到 fuzzer.workQueue中存储为workQueue.workcandidate;
//poll:作用是更新 fuzzer.corpus 语料库以及 fuzzer.workQueue 队列
fuzzer.workQueue:存放了当前待处理任务,共包含三种类型的任务(item),由下图所示:
1.判断该种子是否值得加入corpus,如果值得则加入
2.执行该种子
3.对刚加入corpus的新种子进行突变
3. fuzzing过程中循环挑选种子

执行WorkCandidate时,从fuzzer.workQueue中dequeue取出workcandidate的某个程序交由execute()执行
后续过程中,调用poll()进行Fuzzer的轮询循环,定期检查和处理一些事务,包括生成新的候选输入、记录统计信息以及向管理器报告状态(即fuzzer.pollLoop()函数调用)
例如采用addInputToCorpus() 更新 fuzzer.corpus,更新逻辑如下:
种子有新覆盖→加入到corpus→对新种子采取hint变异机制
Syzkaller 的 Corpus 并非直接作为初始输入,而是作为动态更新的参考语料库,通过覆盖率反馈和进化算法(如变异、交叉)不断优化测试用例
4. 本地corpus.db与初始seed的导入

注:上图中的“遍历语料库/种子文件中的每个记录,并将其加载到管理器中”,这部分的代码实现为loadseed()。该函数实现在“pkg/manager/seed.go”中。 pkg 作为核心代码的根目录,用于组织内部模块或子包(类似 src 的作用)
前:

![]()
后:

观察实际的执行日志,发现最开始时预加载用于执行的candidate是由本地corpus.db和本地syzkaller\sys\linux\test路径下的默认种子(上图中的167seeds).
1.加载工作目录中的语料库,即“corpus.db”。如果此语料库不存在则创建一个新的空语料库文件。工作目录一般设置为“/syzkaller/workdir/”
2.加载种子文件,这些种子文件都是由作者事先设计好的,存储在“/syzkaller/sys/linux/test/”中,其中“target”就是进行Fuzz测试的目标,由于测试的是Linux系统,所以“target”的值为“linux”。可以使用这些定义好的种子文件中的内容,对目标进行Fuzz和变异以获得更高的覆盖率。
syzkaller首先会执行所有的candidate(执行的顺序不明,是按照写入顺序or某种顺序),过程中会间断性地生成新种子(依据超参数设置的频率),这些新种子经过验证后新增进入本次fuzzing的corpus中(上图中的corpus=23)。
5. ChoiceTable的意义
构建目标系统的选择表(Choice Table),通过分析语料库中的系统调用序列,确定每个系统调用的优先级,并生成一个可用于快速生成测试程序的数据结构
BuildChoiceTable() —— 生成 prios[X][Y] 优先级, 预测在包含系统调用X的程序中添加系统调用Y是否能得到新的覆盖
(prios[X][Y]不决定workqueue的调用顺序,根据 prios[X][Y] 计算二维表 run,其中每个元素代表一个系统调用,并存储了累积加权优先级之和(即run=sum += prios[i][j])。run[i][j]表示从系统调用target.Syscalls[i]到系统调用target.Syscalls[j]的累积优先级和。
这个二维累积优先级矩阵可以在生成测试用例时使用,帮助选择具有更高优先级的系统调用,以增加测试用例的多样性和代表性)
prios[X][Y]的计算方式如下(21年版本,在最新版本沿用,但增加了新的规则)
静态:依据输入输出关系 动态:依据成对出现的先后关系

6. 虚拟机实例instance(vmLoop())-(21年版本)
syz-manager进程负责启动、监控和重新启动多个虚拟机实例,并在虚拟机内部启动一个syz-fuzzer进程(syz-manager进程通过ssh调用syz-fuzzer进程)。syz-manager还负责持久性语料库和崩溃存储,负责执行fuzz的对象是一个虚拟机实例instance,返回执行信息,crash信息,虚拟机信息等。所以种子应该包含在实例内。
syz-fuzzer的目的是根据文件系统中的 /sys/kernel/debug/kcov 获取内核代码覆盖率,生成新的变异数据并传给 syz-executor。现已合并至syz-manager中。
完整的实例运行流程如下:
1.初始化准备:
在方法开始处,首先输出一些日志,指示管理器正在启动测试机器,并等待测试机器的连接。初始化一些变量,包括实例的最大数量、等待运行结果的通道等。
2.循环处理实例:
这部分是整个方法的核心,它通过一个无限循环来不断处理虚拟机实例的状态变化和事件。循环中会不断检查虚拟机实例的状态,以确定是否需要启动新的实例、停止实例或者处理其他事件。
3.处理事件:
在循环中,通过不同的case分支处理不同的事件和状态变化:
- 当虚拟机实例完成运行时,会将实例放回实例池中,并根据是否发生漏洞来保存相关信息。
- 当有新的漏洞需要重现时,会启动一定数量的虚拟机实例,并将漏洞信息添加到重现队列中。
- 当收到停止请求时,会发送停止信号给正在运行的虚拟机实例,并将shutdown标记设为nil,以退出循环。
- 当收到其他来自外部的请求时,会相应地处理并进行相应的操作,如添加重现请求到队列中或回复重现请求等。
4.最终结束:
当所有实例都停止运行时,循环结束,方法执行完成。