SAM2 : Segment Anything in Images and Videos
SAM2
Introduction
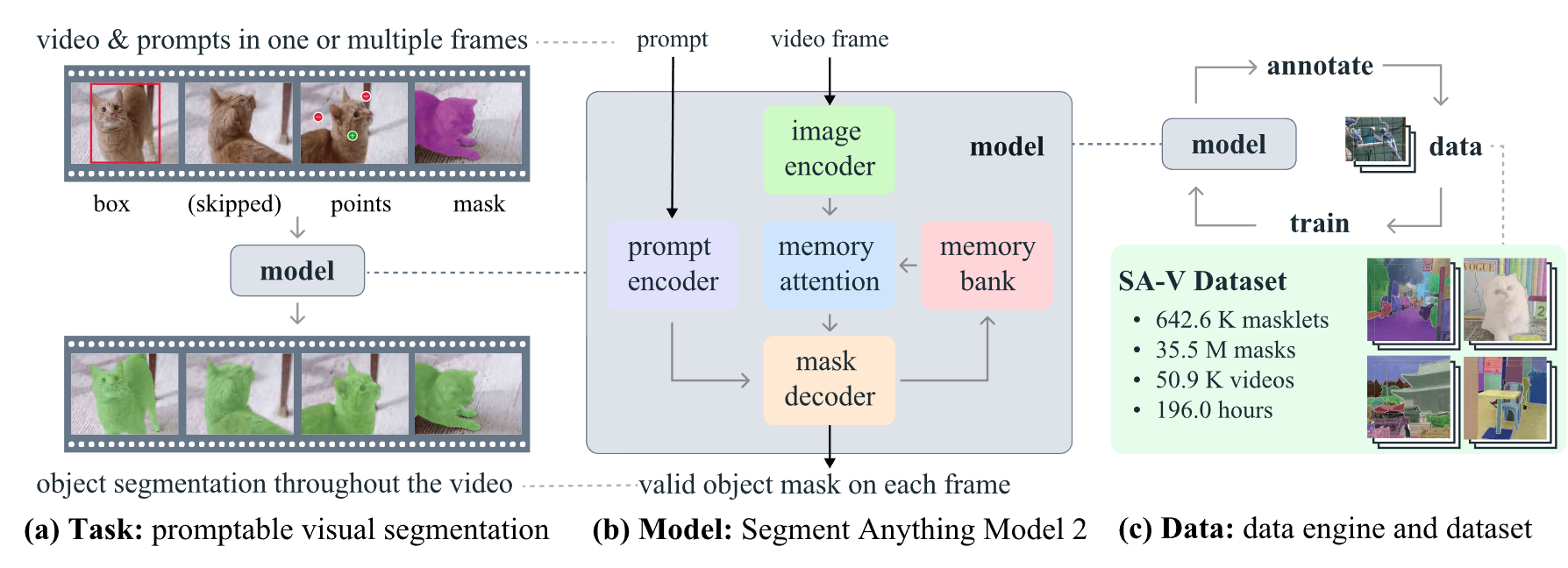
将SAM中的可提示视觉分割范式迁移到视频领域,依旧可以通过点、框、掩码的形式作为视频中随意帧的时空提示掩码(masklet),masklet可以通过额外帧对预测结果进行细化。
数据引擎并不局限于分割特定类别,而是分割any具有有效边界的目标,包括其部分和子部分。
Task: promptable visual segmentation
SAM 2被用作 PVS 任务的数据收集工具来构建我们的 SA-V 数据集。我们通过模拟多帧的交互视频分割场景来评估模型,在传统的半监督VOS设置中,注释仅限于第一帧,以及SA基准上的图像分割。
Model
SAM 2 可以看作是 SAM 对视频(和图像)域的泛化,在单个帧上获取点、框和掩码提示,以时空方式定义要分割对象的空间范围。
SAM2 decoder中使用的frame embedding并不直接来自于 image encoder, 而是来自于历史帧预测和提示帧的记忆,相较于当前帧,提示帧也可以来自于未来帧。
Image encoder
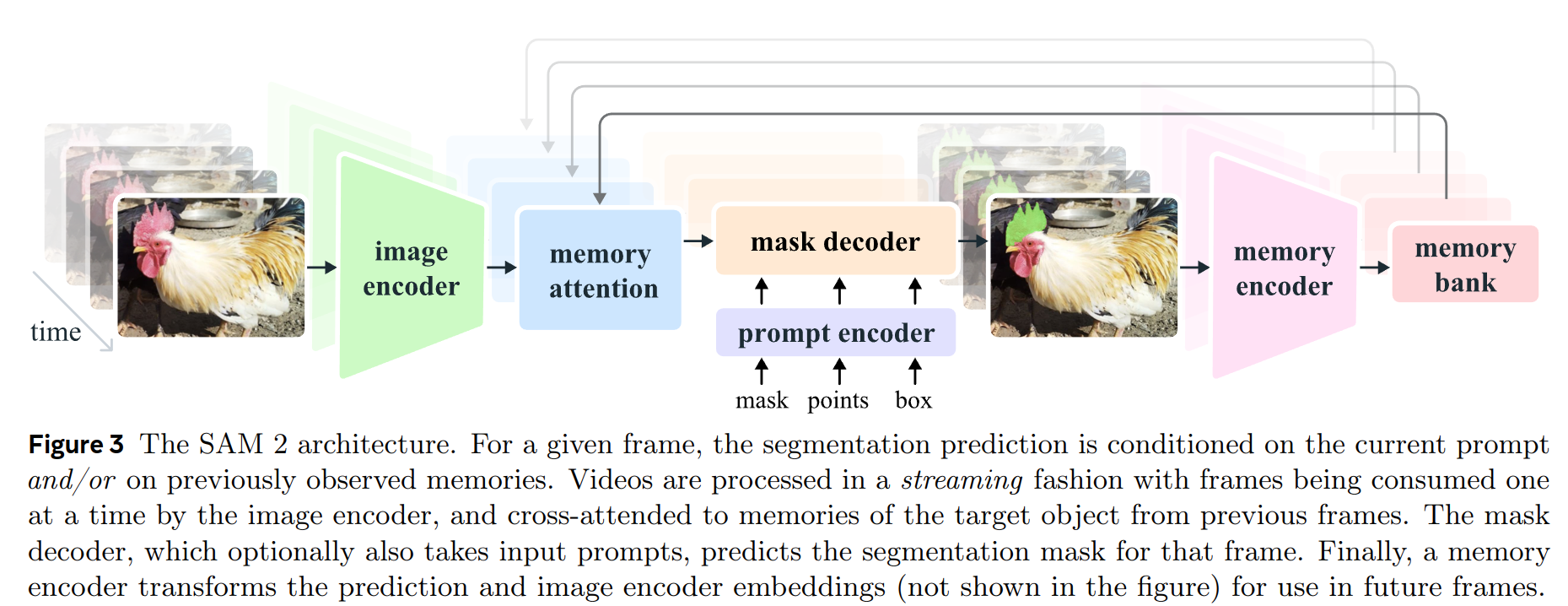
image encoder 在整个交互过程中只会运行一次,用于提供每一帧的无条件tokens(feature embeddings),为了实现实时检测,视频以流的形式输入。
使用MAE预训练的Hiera作为image encoder
分别使用Hiera的第3层和第4层(16X, 32X)作为每一帧的image embeddings,此外第1层和第2层(4X, 8X)虽然未直接作为输出, 但是被添加至了mask encoder的上采样层中来提高对高分辨率目标的细节分割。
借鉴了"absolute win"位置编码方法的思想,采用了更加直接的全局位置编码插值的方式,而没有使用任何相对位置编码。
Memory attention
Memory attention的作用是在历史帧特征和预测结果以及任何新的promot上调节当前帧的特征
堆积L个transformer blocks, 第一个从当前帧的image encoder中获取特征作为输入,每一个block经过self-attention, 记忆帧和目标点集的cross-attention, MLP。在self- and cross-attention中使用vanilla attention。
除了sin 绝对位置编码以外,SAM2还在self-attention和cross-attention层中使用了2d-RoPE。而由于目标点集tokens并不存在特定的空间对应关系,则未进行RoPE。
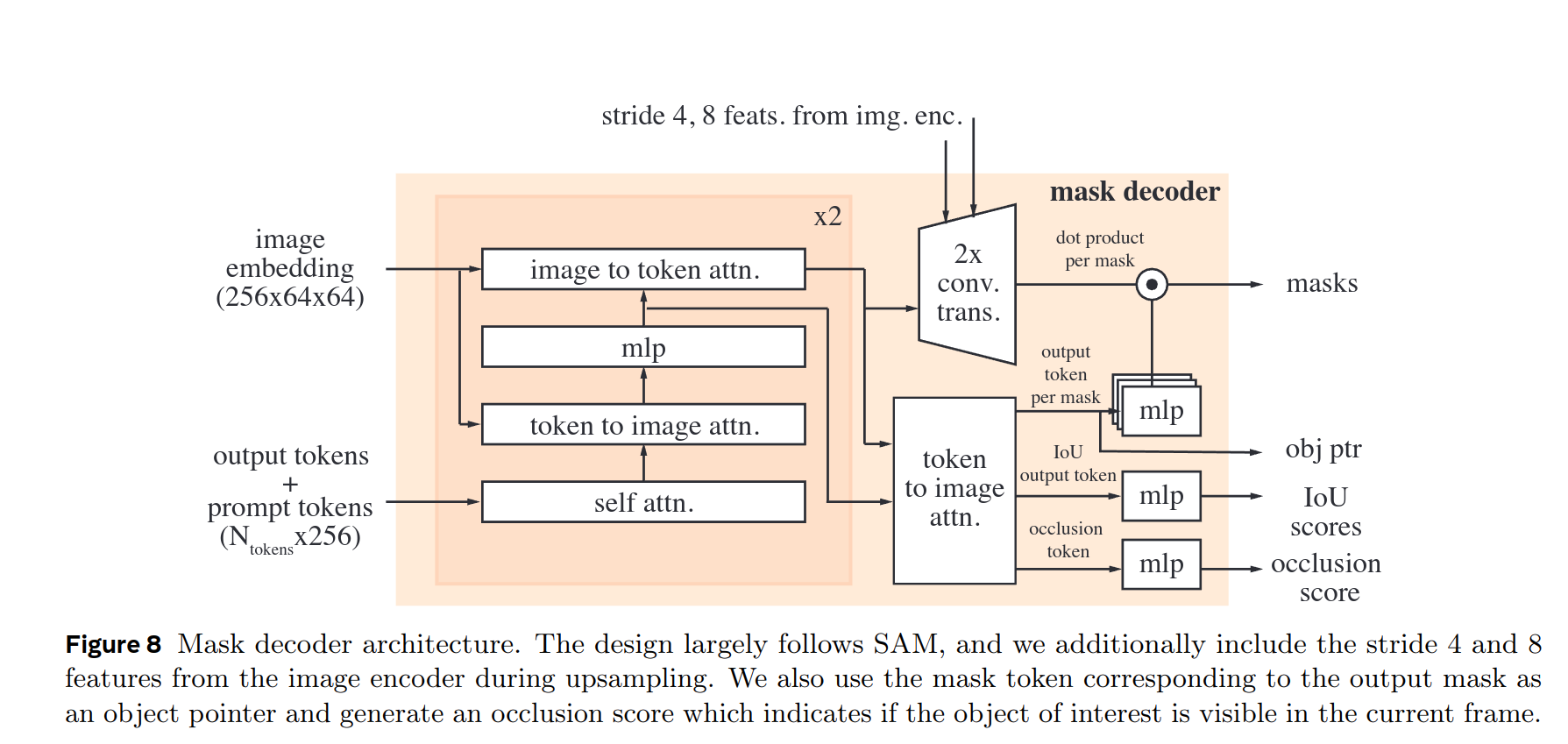
Prompt encoder and mask decoder
prompt与SAM想用,离散prompts代表位置encodings,与每个prompt学习得到的embeddings相加;密集prompts(mask)通过卷积处理后与帧embeddings相加。
堆积双向transformer blocks, 对prompt和frame embeddings进行更新。
与 SAM 一样,对于可能有多个兼容目标掩码的模棱两可的提示(即单个点击),我们预测多个掩码。这种设计对于确保模型输出有效的掩码很重要。在视频中,歧义可以跨视频帧扩展,模型预测每帧的多个掩码。如果没有后续提示解决歧义,模型只会传播当前帧预测 IoU 最高的掩码。
但是不同于SAM, 需要分割的目标在视频中可能会出现遮挡,导致某些帧上可能不存在有效的目标,为了支持这种新的输出模式,SAM2添加了一个额外的头来预测当前帧是否存在有效的目标(基于mask和IoU的输出token完成)。此外,通过充分利用Hiera的多层级特征(通过memory attention)为mask decoder提供高分辨率mask
我们使用输出的mask所对应的mask token作为每帧的目标点集token,并存放在内存库中。此外还会将学习得到的occlusion tokens 嵌入到那些预测结果被遮挡的帧的特征中。
对于目标歧义的处理,SAM2会在视频的每一帧中预测多个mask,如果没有进一步的提示解决歧义,模型会输出当前预测帧中IoUo最高的mask。
Memory encoder
Memory encoder通过卷积对输出的mask进行下采样并通过与unconditioned frame embedding逐元素求和+卷积来进行信息融合,生成最终的内存特征
Memory encoder不再使用额外的image encoder,而是重复使用Hiera得到的image embeddings, 并与预测的mask融合来产生最终的内存存储特征,这种设计可以充分利用Hiera的图像特征,尤其是对于高分辨率视频输入。
Memory bank
内存库通过维护一个最多 N 个最近帧的内存 FIFO 队列并将来自提示的信息存储在最多 M 个提示帧的 FIFO 队列中,从而保留视频中目标对象的过去预测的信息
除空间记忆以外,SAM2还通过每一帧的mask decoder 输出的tokens 来维护一个轻量级的点集向量来储存目标的高级语义信息。从而使memory attention通过交叉注意力关注到空间记忆特征和这些目标的信息。
SAM2 将时间位置信息嵌入到 N 个最近帧的内存中,允许模型表示短期对象运动,而不是提示帧的运动,因为来自提示帧的训练信号更稀疏,并且更难适配到推理过程中,提示帧可能来自与训练期间看到的非常不同的时间范围。
此外,储存的内存特征维度是64,并且将256维的目标点集拆分为4个64维的向量,以便进行cross-attention。
Training
- Pre-training

与SAM相同,使用SA-1B进行pre-train,使用MAE pre-trained 的 Hiera,并过滤覆盖面积超过90%的mask,并且限制每张图中最多有64个mask。
与SAM不同,使用L1-Loss并且对IoU logits使用sigmoid更有利于IoU的预测。 对于多mask预测(在第一次点击上),我们监督所有mask的 IoU 预测,以鼓励更好地学习mask何时可能不好,但只对具有最低分割loss(focal + dice loss)的mask logits进行监督
使用水平翻转增强,并将图像resize到1024X1024。
- Full training

在SA-V,10%的SA-1B,DAVIS+MOSE+YouTubeVOS的混合数据集上进行训练。训练任务包括PVS和SA,对应地,训练数据包括视频和图像,为了优化数据使用和训练资源,采用视频和图像交替训练的策略。
在视频训练过程中,应用了一系列数据增强方法,包括随机水平翻转、随机仿射变换、随机颜色抖动和随机灰度变换,还采用了马赛克变换来模拟具有多个相似外观的对象的场景:将相同的训练视频平铺成一个 2×2 网格,并从 4 个象限之一中选择一个 masklet 作为目标对象进行分割。
我们通过模拟交互式设置、采样 8 帧序列并随机选择多达 2 帧(包括第一个)进行校正点击来训练。在训练期间,我们使用ground-truth masklets和模型预测对提示进行采样,初始提示是ground-truth mask (50%概率)、ground-truth mask (25%) 的正点击或边界框输入 (25%)。
我们将 8 帧的每个序列的最大mask数限制为 3 个随机选择的mask数。我们以 50% 的概率反转时间顺序,以帮助泛化到双向传播。当我们对纠正点击进行采样时,概率很小 10%,我们从真值mask中随机采样点击,而不考虑模型预测,以允许mask细化的额外灵活性。
-
Fine-tuning using 16-frame sequences
上述过程的一个潜在缺点是模型在训练期间只看到采样的 8 帧序列,在推理过程中与完整的视频长度相比相对较短。为了缓解这个问题并进一步提高长视频的分割质量,我们引入了一个额外的微调阶段,我们在具有挑战性的视频(那些编辑帧数量最多的视频)上采样16帧序列
使用原始学习率的一半微调 50k 次迭代(原始调度的 1/3),并冻结图像编码器以将 16 帧序列拟合到 A100 GPU 的 80 GB 内存中。 -
Losses and optimization
使用focal loss 和 dice loss的线性组合对mask进行监督,使用MAE loss对IoU进行监督,使用CE loss对目标预测进行监督。再预训练阶段,对于多mask预测,仅对具有最低分割loss的mask进行监督, 如果真值不包括当前帧的mask,则不对当前帧mask进行loss回传,但是会有目标预测头计算目标存在损失。
Model architecture ablations
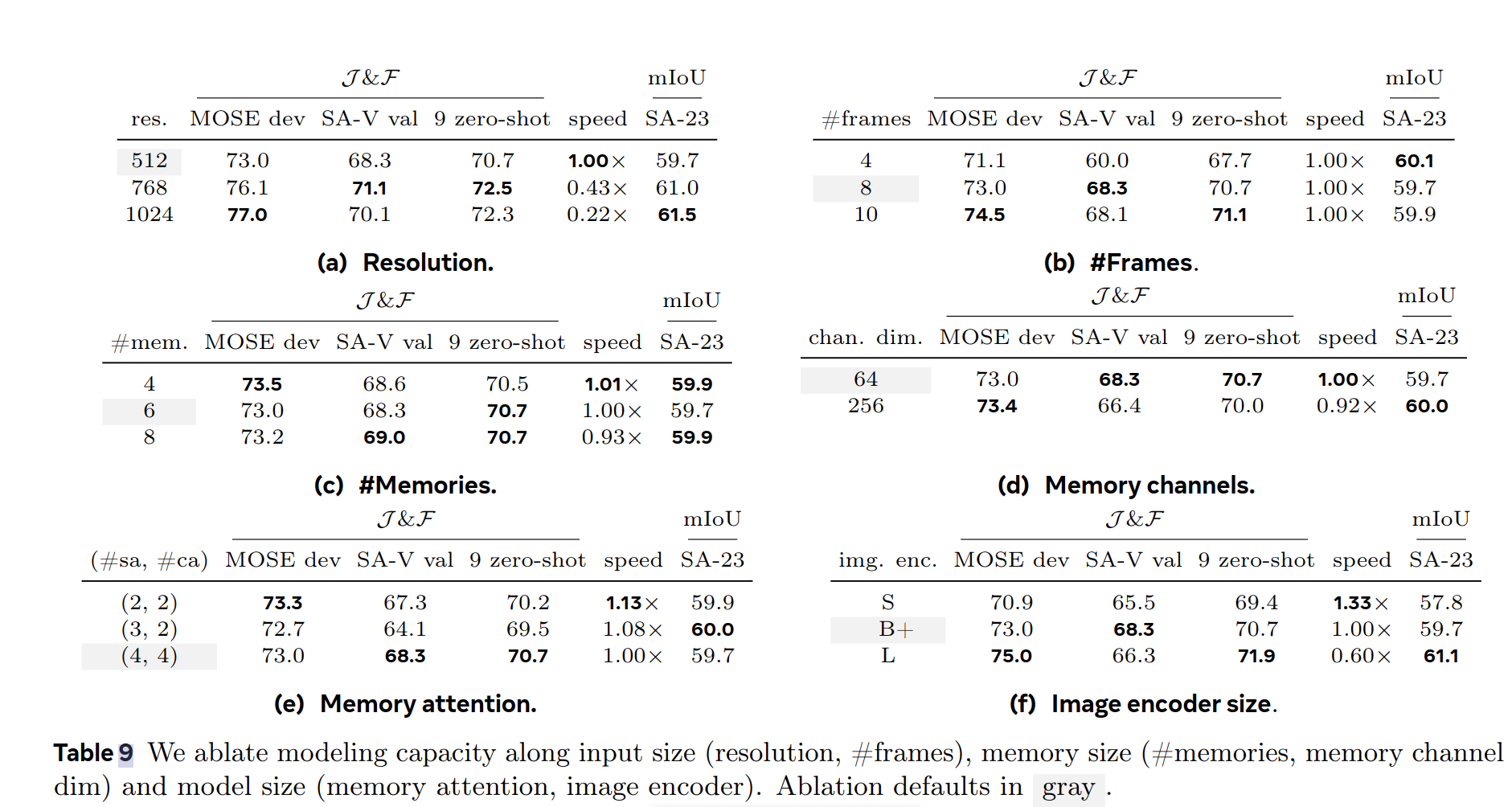
Capacity ablations
-
Input size
在训练过程中,对固定分辨率/固定帧数进行了分析,高分辨率可以显著增加识别效果,增加帧数(采样频率)也可以带来显著的收益。 -
Memory size
增加最大记忆数N通常有助于提升性能,使用更少的内存通道不会带来太多性能损失,同时使存储所需的内存更小 4 倍。 -
Model size
模型大小的变化会直接带来性能的上的变化,对image encoder的缩放均会对最终结果产生影响,而memory-attention只会影响视频指标,因此默认采用B+image encoder对速度与精度进行平衡。
Relative positional encoding
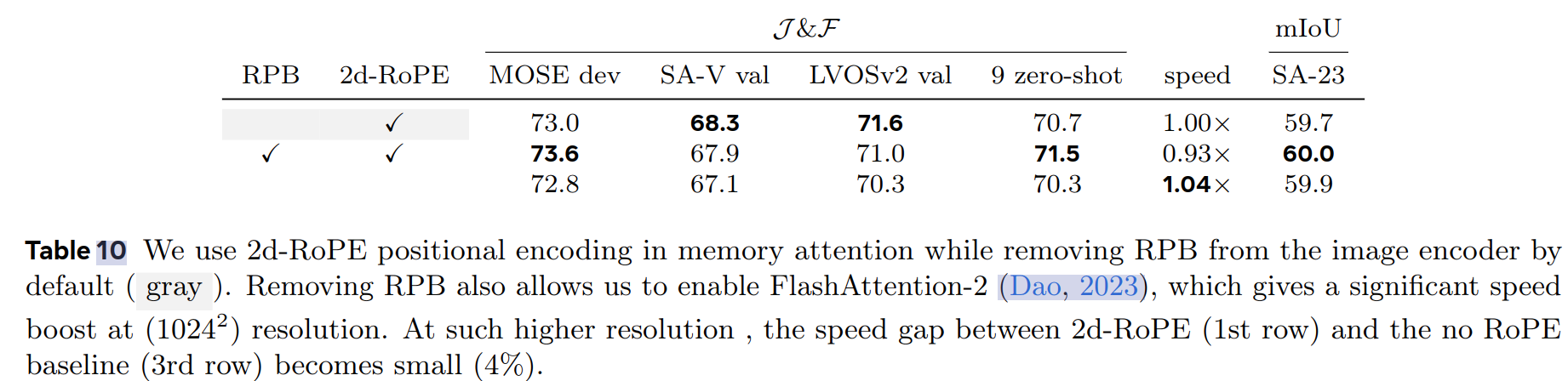
默认情况下,image encoder和memory attention均使用绝对位置编码,
SAM采用了全局应用相对位置编码(RPB),但后续研究中发现,删除除全局注意力层以外的所有想法对位置编码并采用"absolute-win"的形式带来了较大的速度提升。
因此SAM2删除了所有的相对位置编码,实现了无损提速,并在memory attention中采用了2d-RoPE
Memory architecture ablations
- Recurrent memory
本文分析了在将记忆特征添加到内存库之前,将其输入GRU的有效性。与前文相同,分析了LVISv2作为额外的long-term目标分割的基线模型。虽然先前的工作中经常应用GRU状态作为将内存合并到跟踪的一种手段,但在实验中发现这种方法并没有获得对应的收益,而直接将记忆特征储存在内存库中就足够了,简单且高效。 - Object pointers

对来自于其他帧的mask decoder特征的cross-attending对目标点集向量的影响进行了分析。虽然cross-attending并不能提高 9 个零样本数据集的平均性能,但它显着提高了 SA-V val 数据集的性能以及具有挑战性的 LVOSv2 基准
Limitations
SAM2可能无法跨镜头变化分割对象,并在长遮挡或扩展视频中丢失拥挤场景中跟踪或混淆对象; SAM 2 也难以准确跟踪具有非常薄或精细细节的对象,尤其是当它们快速移动时。当附近具有相似外观的对象
虽然 SAM 2 可以同时跟踪视频中的多个对象,但 SAM 2 独立处理每个对象,仅使用共享的每帧的embeddings而不进行对象间通信。