深度学习G5周:Pix2Pix理论与实战
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
本周任务:
1.了解并学习Pix2Pix算法
2.画出本文代码中Pix2Pix的生成器网络结构(可参考图5)
前言:
在之前学习了GAN可用于图像生成,在MNIST数据集上取得非常好的效果。但它存在一个问题,是无法对生成模型生成的数据进行控制,为解决此问题,条件GAN(Conditional GAN, CGAN)提出将在生成模型和判别模型中都加入条件信息来引导模型的训练,实现生成内容的可控。
Pix2Pix是一个以GAN为基础,用于图像翻译(Image Translation)的通用框架,目的在将一个图像域中的图像转换成另一个图像域中的图像,实现了模型结构和损失函数的通用化,并在诸多图像翻译数据集上取得了令人瞩目的效果。(论文:Image-to-Image Translation with Conditional Adversarial Networks)

1.背景知识
1.1 图像翻译
首先先理解以下概念:
图像内容(Image Content):图像的固有内容,是区分不同图像的依据
图像域(Image Domain):在特定上下文中所涵盖的一组图像的集合,这些图像通常具有相似性或共同特征。图像域可以用来表示一类具有共同属性或内容的图像。在图像处理和计算机视觉领域,图像域常被用于描述参与某项任务或问题的图像集合,
图像翻译:将一个物体的图像表征转换为该物体的另一个表征,如根据皮包轮廓图得到皮包彩色图。即找到一个函数,能让域A的图像映射到域B,从而实现图像的跨域转换。
1.2 CGAN
条件生成对抗网络(CGAN)是在生成对抗网络(GAN)的基础上进行一些改进。对于原始GAN的生成器而言,其生成的图像数据是随机不可预测的,因此我们无法控制网络的输出,在实际操作中的可控性不强。
针对上述原始GAN无法生成具有特定属性的图像数据的问题,Mehdi Mirza等人在2014年提出了条件生成对抗网络,通过给原始生成对抗网络中的生成器G和判别器D增加额外的条件,如我们需要生成器G生成一张没有阴影的图像,此时判别器D就需要判断生成器所生成的图像是否是一张没有阴影的图像。条件生成对抗网络的本质是将额外添加的信息融入到生成器和判别器中,其中添加的信息可以是图像的类别、人脸表情和其他辅助信息等,目的是把无监督学习的GAN转化为有监督学习的CGAN,便于网络能够在我们掌控下更好地进行训练。
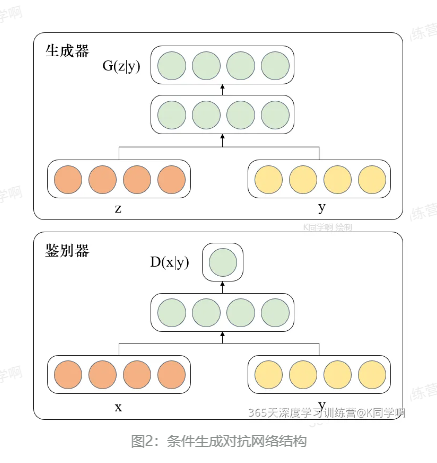
由图的网络结构可知,条件信息y作为额外的输入被引入对抗网络中,与生成器中的噪声z合并作为隐含层表达;而在判别器D中,条件信息y则与原始数据x合并作为判别函数的输入。这种改进在以后的诸多方面研究中被证明是非常有效的,也为后续相关工作提供了积极指导作用。
对于GAN,它的损失函数可以定义为
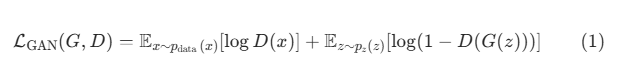
对于CGAN的损失函数 ,只需要使用G(z丨y)和D(x丨y)替代上式的G(z)和D(x)即可
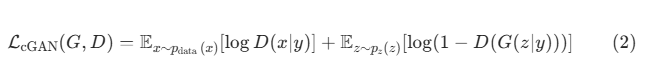
1.3 U-Net
是一个用于医学图像分割的全卷积模型。分为两个部分,左侧是由卷积和降采样操作组成的压缩路径,右侧是由卷积和上采样组成的扩张路径,扩张的每个网络块的输入由上一层上采样的特征和压缩路径部分的特征拼接而成。网络模型整体是一个U形的结构,因此被叫做U-Net。
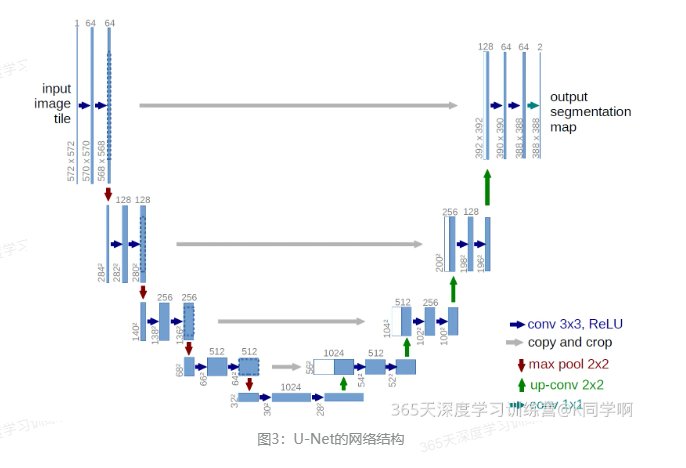
分割任务是图像翻译任务的一个分支,因此U-Net也可以被用作其他的图像翻译任务,这里介绍的Pix2Pix就是采用了U-Net作为主体结构,
2.Pix2Pix解析
在Pix2Pix中,图像翻译任务可以建模为给定一个输入数据x和随机噪声z,生成目标图像y,即
G:(x,z)→y。
与传统的CGAN不同,在Pix2Pix中判别器的输入是生成图像G(x)(或是目标图像y)和源图像x,而生成器的输入是源图像x和随机噪声z。
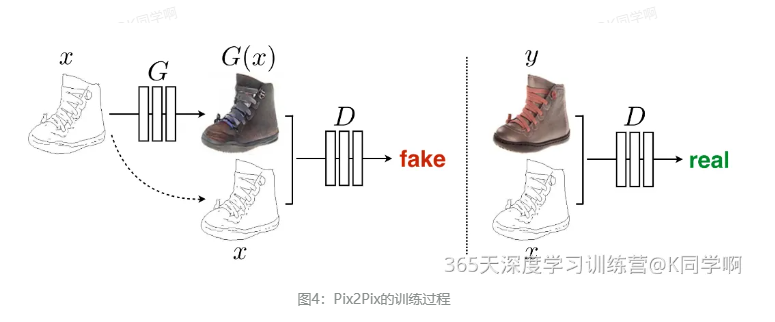
2.1 损失函数
因为Pix2Pix和CGAN的输入数据不同,所以它们的损失函数也要对应进行调整。
CGAN的损失函数:
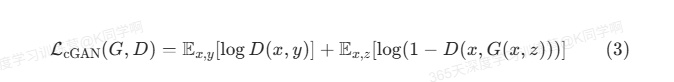
如【5】我们可以在损失函数中加入正则项来提升生成图像的质量,不同的是Pix2Pix使用的是L1和不是【5】中使用的L2正则。
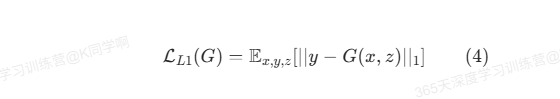
使用L1正则有助于使生成的图像更清楚。
我们最终的目标是在正则约束情况下的生成器和判别器的最大最小博弈,
![]()
之所以在生成数据中加入随机噪声z,是为了使生成模型生成的数据具有一定的随机性,但实验结果表明完全随机的噪声并不会产生特别有效的效果,在这里,Pix2Pix是通过在生成器的模型层中加入Dropot来引入随机噪声的,但是Dropout带来输出内容的随机性并没有很大。
2.2 模型结构
Pix2Pix使用了CNN中常用的卷积+BN+ReLU的模型结构。
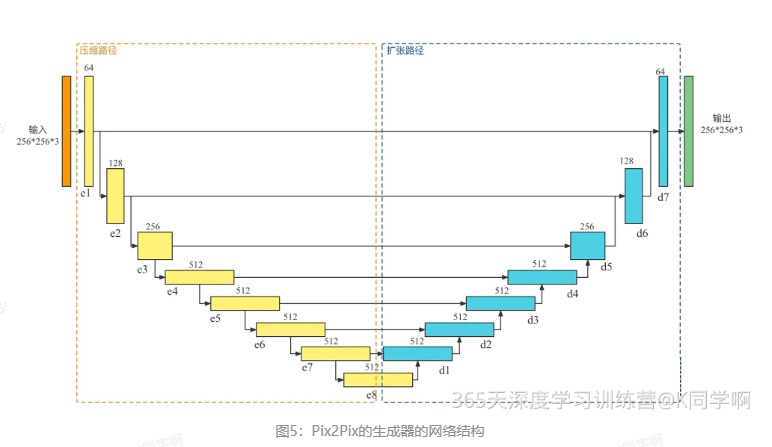
2.2.1 生成器
对于图像翻译任务,经典的编码器-解码器结构是最优的选择,Pix2Pix的官方源码(GitHub - phillipi/pix2pix: Image-to-image translation with conditional adversarial nets)是使用Lua实现。
注意:
1.Pix2Pix使用的是以U-Net为基础的结构,即在压缩路径和扩张路径之间添加一个跳跃连接;
2.Pix2Pix的输入图像的大小256*256
3.每个操作仅进行了三次降采样,每次降采样的通道数均乘以2,初始的通道数是64
4.在压缩路径中,每个箭头表示的操作是卷积核大小为4*4的相同卷积+BN+ReLU,它根据是否降采样来控制卷积的步长
5.在扩张路径中,它使用的是反卷积上采样
6.压缩路径和扩张路径使用的是拼接操作进行特征融合
2.2.3 判别器(PatchGAN)
传统GAN的一个棘手问题是它生成的图像普遍比较模糊,一个重要的原因是它使用了整图作为判别器的输入。不同于传统方法,将整个图像作为判别器判别的目标(输入),Pix2Pix提出了将输入图像分成N*N个图像快(Patch),然后将这些图像块依次提供给判别器,因此这种方法被命名为PatchGAN。PatchGAN可以看做针对图像纹理的损失。
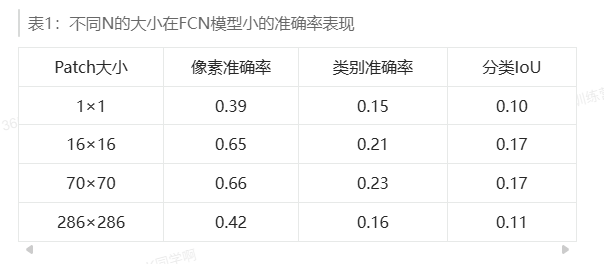

表1实验结果表明,当N=70,模型表现最好,但从图的生成图像来看,N越大,生成的图像质量越高。其中1*1大小的图像块的判别器又被叫做PixelGAN。
对于不同大小的N,我们需要根据N的值来调整判别器的层数,进而得到最合适的模型感受野。
3.代码运行

运算结果:


4.总结
学习了Pix2Pix算法,Pix2Pix是图像翻译必读的文章之一,核心技术有以下三点:①基于CGAN的损失函数,②基于U-Net的生成器,③基于PatchGAN的判别器。
Pix2Pix虽然能在很多图像翻译任务上取得令人经验的效果,但因为它的输入是图像对,因此它得到的模型还是有偏(模型能够在与数据集近似的x的情况下得到满意的生成内容,但如果输入x与训练集偏差过大,得到结果不那么理想)的。
学习每个模型的结构还是很有挑战性的,需要很长时间理解。
