《深入剖析Kafka分布式消息队列架构奥秘》之Kafka基本知识介绍

🎼个人主页:【Y小夜】
😎作者简介:一位双非学校的大三学生,编程爱好者,
专注于基础和实战分享,欢迎私信咨询!
🎆入门专栏:🎇【MySQL,Javaweb,Rust,python】
🎈热门专栏:🎊【Springboot,Redis,Springsecurity,Docker,AI】
感谢您的点赞、关注、评论、收藏、是对我最大的认可和支持!❤️

目录
🎉Kafka相关概念
🎈MQ的作用
🎈Kafka是如何工作的?(官网)
🎈术语:(官网)
🎈Kafka特点
🎉上手Kafka
🎈下载Zookeeper和Kafka
🎈启动Zookeeper和Kafka
🎈开始使用Kafka
🎠创建topic
🎠启动生产者
🎠启动消费者
🎠启动消费者组
🎈看一下消费者组
老规矩,入门第一步,自己先去看看官网:Apache Kafka
🎉Kafka相关概念
🎈MQ的作用
在介绍Kafka之前,咱们先来介绍一下MQ,消息队列,是一种FIFO先进先出的数据结构,消息则是跨进程的数据。典型的MQ系统,会将消息有消费者发送到MQ进行排队,然后根据一定的顺序交给消息的消费这处理。
QQ和微信就是典型的MQ。只不过他接受使用对象是人,而Kafka需要对接的对象是应用程序。
MQ作用主要为异步、解耦、削峰。(这三个概念我就不讲了,不清楚的可以去搜下)
🎈Kafka是如何工作的?(官网)
Kafka是一个分布式系统,由服务器和客户端组成,这些服务器和客户端通过高性能TCP网络协议进行通信,它可以部署在本地和云中的裸机硬件、虚拟机和容器环境。
服务器:Kafka作为一个或者多个服务器的集群运作,这些服务器可以跨越多个数据中心或云区域。其中一些服务器是存储层,成为broker,其他服务器运行 Kafka Connect 以持续导入和导出 数据作为事件流,以将 Kafka 与现有系统(如关系数据库)集成,以及 其他 Kafka 集群。为了让您实施任务关键型使用案例,Kafka 集群具有高度可扩展性 和容错:如果它的任何服务器出现故障,其他服务器将接管它们的工作以确保 连续运行,不会丢失任何数据。
客户端:它允许你编写分布式和微服务,这些应用程序以及读取、写入、大规模和容错方式处理事件流、即使在网络的情况下也是如此 问题或机器故障。
🎈术语:(官网)
创建者是将事件写入到Kafka的客户端应用程序,而使用者是订阅(读取和处理)这些事件的客户端应用程序。在 Kafka 中,生产者和使用者完全解耦且彼此不可知,这是实现 Kafka 众所周知的高可扩展性的关键设计元素。
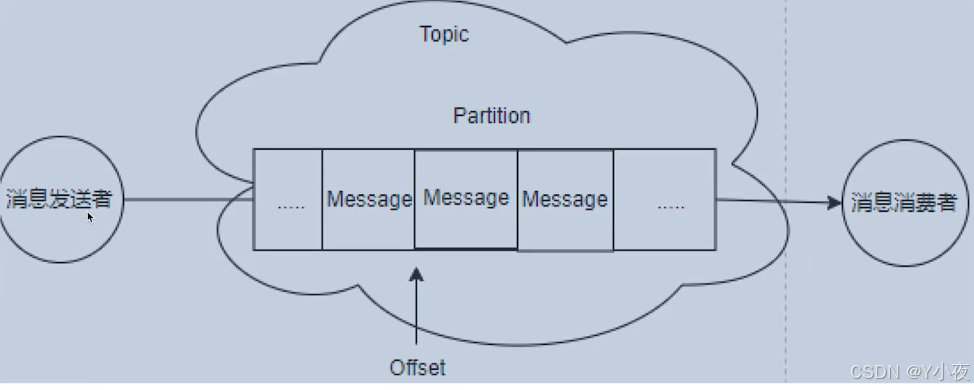
事件被组织并持久存储在主题中。非常简单,主题类似于文件系统中的文件夹,事件是该文件夹中的文件。示例主题名称可以是 “payments”。Kafka 中的主题始终是多创建者和多订阅者:一个主题可以有零个、一个或多个向其写入事件的创建者,以及订阅这些事件的零个、一个或多个使用者。可以根据需要随时读取主题中的事件 - 与传统消息传递系统不同,事件在使用后不会删除。相反,您可以通过每个主题的配置设置定义 Kafka 应将事件保留多长时间,之后将丢弃旧事件。Kafka 的性能在数据大小方面实际上是恒定的,因此长时间存储数据是完全可以的。
主题是分区的,这意味着主题分布在位于不同 Kafka 代理上的多个“存储桶”中。这种分布式数据放置对于可伸缩性非常重要,因为它允许客户端应用程序同时从多个代理读取和写入数据。当新事件发布到主题时,它实际上会附加到主题的某个分区中。具有相同事件键的事件(例如,客户或车辆 ID)将写入同一分区,Kafka 保证给定主题分区的任何使用者将始终以与写入事件完全相同的顺序读取该分区的事件。
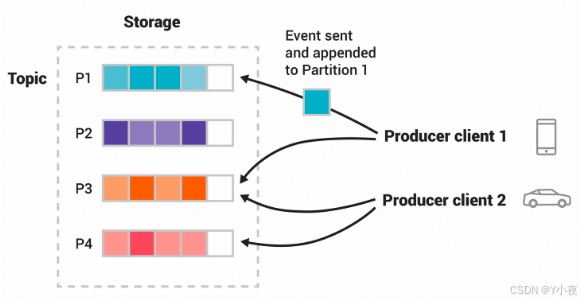
为了使数据具有容错性和高可用性,每个主题都可以复制,甚至可以跨地理区域或数据中心复制,以便始终有多个代理拥有数据副本。
🎈Kafka特点
1.吞吐量大:需要能够快速收集各个渠道的海量日志
2.集群容错率高:允许集群中少量崩溃(意思是说,不要动不动就崩溃不能使用)
3.功能不需要太复杂,Kafka的设计目标使高吞吐、低延迟和可扩展,主要关注消息传递而不是消息处理,所以Kafka并不支持死信队列、顺序消息等高级功能。
4.允许少量的消息丢失:在海量日志中,少量的日志不会影响结果。
服务稳定性要比数据安全性要求更高
🎉上手Kafka
🎈下载Zookeeper和Kafka
Kafka的运行环境非常简单,只要JVM虚拟机就可以。
提前准备自己电脑上的jdk环境(没有的可以自己去下载一下)
java -version

然后我们去官网下载Kafka:Apache Kafka
然后进行下载就行。(Kafka底层是用Scala写的,但Scala不是向后兼容的,版本之间可能不适用)
我们再去下载一个Zookeeper,Kafka默认是Zookeeper提供集群环境(虽然Kafka本身自带一个Zookeeper,但是很少用)Apache ZooKeeper


然后将这两个扔到虚拟机中。
![]()
进行解压:
tar -zxvf kafka_2.13-3.9.0.tgz

查看一下Kafka下的目录:
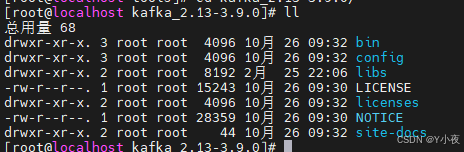
🎈启动Zookeeper和Kafka
emmm,那我们现在就启动一下,在启动Kafka之前,我们需要先启动一下Zookeeper,然后再去启动Kafka
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
nohup指令代表后台运行。

然后在启动Kafka
nohup bin/kafka-server-start.sh config/server.properties &
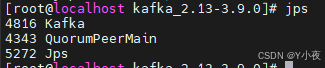
🎈开始使用Kafka
Kafka的基础工作机制是消息发送者可以将消息发送给Kafka上指定的topic,而消费者。可以从指定的topic上消费消息。
Kafka为我们提供了大量的脚本,如果你不会用的话,你可以使用--help命令,例如
bin/kafka-topics.sh --help
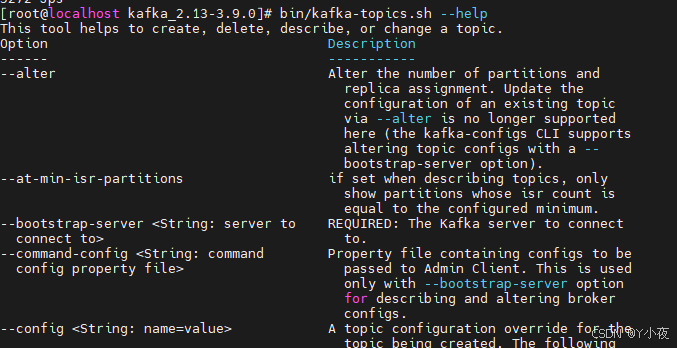
🎠创建topic
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test
创建一个名为test的topic,我们查看一下都有哪些topic
bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
![]()
🎠启动生产者
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test
紧接着我们就直接发送一条消息

🎠启动消费者
然后我们在打开一下连接,然后我们再建立一个消费者
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test

但是我们现在并没有收到消息,现在我们再去生产者上发几个消息

看一下消费者:

发现收到了实时消息,但我们的历史消息呢,丢了吗。其实不是的,因为默认启动的是实时的。
我们现在让消费者从头开始消费
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
发现消息全部被消费
也可以指定一个地点消费,这里从第二个开始消费
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --partition 0 --offset 2
🎠启动消费者组
在第一个消费者下运行,然后再创建一个消费者,再运行一次。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --group testGrop
二者对比会发现。同一个消费者组中,只会消费一个消息,每个消息只会消费一份。如果另外一个想去消费,要指定另外一下消费者组。

🎈看一下消费者组
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group testGrop因为现在我们的消费者组全部关闭,然后生产者有生产了几条消息,然后,下面日志显示。
显示已经消费了十条消息,总共有14 条消息,还有4条未消费。