归档日志-binlog
一、是什么?有啥用?
binlog是binary log的缩写,即二进制日志,它属于Mysql的Server层面的日志。binlog中记载了数据库发生的变化,比方说新建了一个数据库或者表、表结构发生改变、表中的数据发生了变化时都会记录相应的binlog日志。
binlog主要用在下边两个方面:
- 用于复制。比如,搭建一套一主两从的MySQL集群,binlog帮你完成主从的数据同步。
- 用于恢复。比如,delete没加where条件?不慌!binlog可以帮你恢复数据。
二、文件格式
- STATEMENT:每一条修改数据的 SQL 都会被记录到 binlog 中(相当于记录了逻辑操作,所以针对这种格式, binlog 可以称为逻辑日志),主从复制中 slave 端再根据 SQL 语句重现。但 STATEMENT 有动态函数的问题,比如你用了 uuid 或者 now 这些函数,你在主库上执行的结果并不是你在从库执行的结果,这种随时在变的函数会导致复制的数据不一致。
假设执行 UPDATE s1 SET common_field = 'xx' WHERE id > 9990;
相应的binlog内容:update s1 set common_field= 'xx' where id > 9990
心得:statement格式下,binlog中其实记录的就是用户所写的一条条 update 语句。
- ROW:记录行数据最终被修改成什么样了(这种格式的日志,就不能称为逻辑日志了),不会出现 STATEMENT 下动态函数的问题。但 ROW 的缺点是每行数据的变化结果都会被记录,比如执行批量 update 语句,更新多少行数据就会产生多少条记录,使 binlog 文件过大,而在 STATEMENT 格式下只会记录一个 update 语句而已。
假设执行 UPDATE s1 SET common_field = 'xx' WHERE id > 9990;
相应的binlog内容:
mysqlbinlog --verbose xiaohaizi-bin.000008
...这里省略了很多内容
### UPDATE `xiaohaizi`.`s1`
### WHERE
### @1=9991
### @2='7cgwfh14w6nql61pvult6ok0ccwe'
### @3='799105223'
### @4='c'
### @5='gjjiwstjysv1lgx'
### @6='zg1hsvqrtyw2pgxgg'
### @7='y244x02'
### @8='xx'
### SET
### @1=9991
### @2='7cgwfh14w6nql61pvult6ok0ccwe'
### @3='799105223'
### @4='c'
### @5='gjjiwstjysv1lgx'
### @6='zg1hsvqrtyw2pgxgg'
### @7='y244x02'
### @8='xxx'
### UPDATE `xiaohaizi`.`s1`
### WHERE
### @1=9992
### @2='2sfq3oftc'
### @3='815047282'
### @4='ub'
### @5='73hw14kbaaoa'
### @6='fxnqzef3rrpc7qzxcjsvt14nypep4rqi'
### @7='10vapb6'
### @8='xx'
### SET
### @1=9992
### @2='2sfq3oftc'
### @3='815047282'
### @4='ub'
### @5='73hw14kbaaoa'
### @6='fxnqzef3rrpc7qzxcjsvt14nypep4rqi'
### @7='10vapb6'
### @8='xxx'
...这里省略了很多内容
心得:row格式下,binlog中将每一条行数据更新前后的值都记录了下来,并且影响了多少行数据,就会产生多少条记录。
- MIXED:包含了 STATEMENT 和 ROW 模式,它会根据不同的情况自动使用 ROW 模式和 STATEMENT 模式。
三、关于为什么会有两份日志文件:
因为最开始MySQL里并没有InnoDB引擎。MySQL自带的引擎是MyISAM,但是MyISAM没有crash-safe的能力,binlog日志只能用于归档。而InnoDB是另一个公司以插件形式引入MySQL的,既然只依靠binlog是没有crash-safe能力的,所以InnoDB使用另外一套日志系统 —— 也就是redo log来实现crash-safe能力。
四、redo log 与 binlog 的区别:
- redo log是InnoDB引擎特有的;binlog是MySQL的Server层实现的,所有引擎都可以使用。
- redo log是物理日志,记录的是“在某个数据页上做了什么修改”;binlog是逻辑日志,记录的是这个语句的原始逻辑,比如“给ID=2这一行的c字段加1 ”。
- redo log是循环写的,空间固定会用完;binlog是可以追加写入的。“追加写”是指binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
注意:为了保证这两个日志逻辑上的一致使用两阶段提交。
五、组提交
MySQL 引入了 binlog 组提交(group commit)机制,当有多个事务提交的时候,会将多个 binlog 刷盘操作合并成一个,从而减少磁盘 I/O 的次数,如果说 10 个事务依次排队刷盘的时间成本是 10,那么将这 10 个事务一次性一起刷盘的时间成本则近似于 1。
引入了组提交机制后,prepare 阶段不变,只针对 commit 阶段,将 commit 阶段拆分为三个过程:
- flush 阶段:多个事务按进入的顺序将 binlog 从 cache 写入文件(不刷盘);
- sync 阶段:对 binlog 文件做 fsync 操作(多个事务的 binlog 合并一次刷盘);
- commit 阶段:各个事务按顺序做 InnoDB commit 操作;
上面的每个阶段都有一个队列,每个阶段有锁进行保护,因此保证了事务写入的顺序,第一个进入队列的事务会成为 leader,leader领导所在队列的所有事务,全权负责整队的操作,完成后通知队内其他事务操作结束。
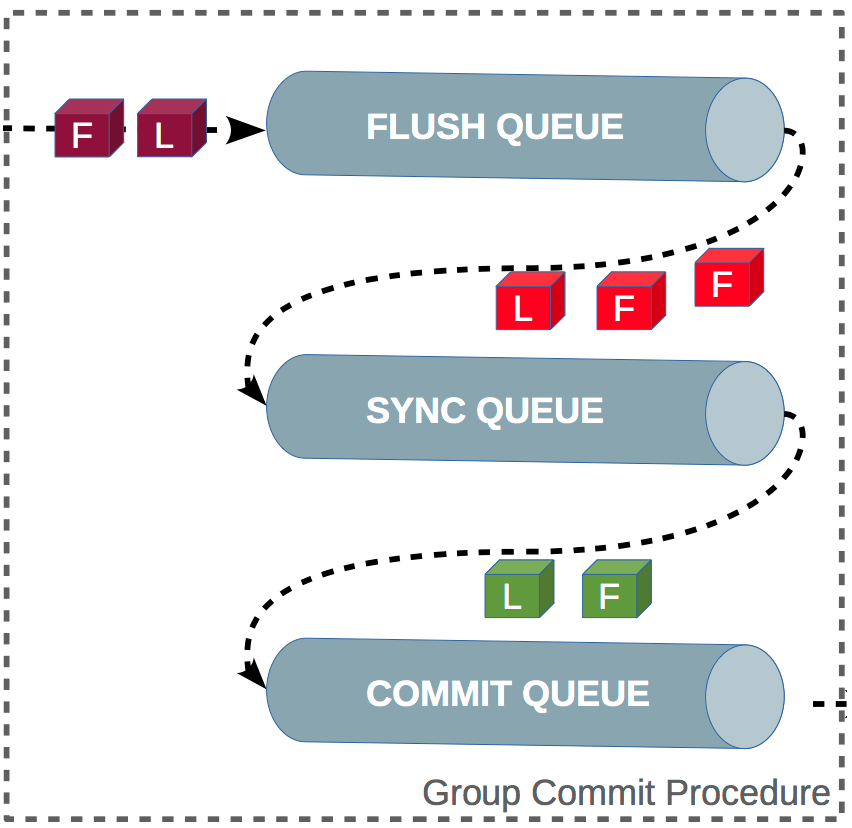
对每个阶段引入了队列后,锁就只针对每个队列进行保护,不再锁住提交事务的整个过程,可以看的出来,锁粒度减小了,这样就使得多个阶段可以并发执行,从而提升效率。