【VLLM】open-webui部署模型全流程
目录
前言
一、租用服务器到服务器连接VScode全流程(可选)
二、下载模型到本地服务器
2.1 进入魔塔社区官网
2.2 选择下载模型
2.3 执行下载
三、部署VLLM
3.1 参考vllm官网文档
3.2 查看硬件要求
3.3 安装vLLM框架
3.4 启动模型服务
方法1:直接启动下载的本地模型
方法2:启动微调后的模型
3.5 调用模型进行对话(可选)
四、安装open-webui流程
4.1 创建虚拟环境
4.2 安装并运行open-webui
4.3 启动后效果
五、总结

前言
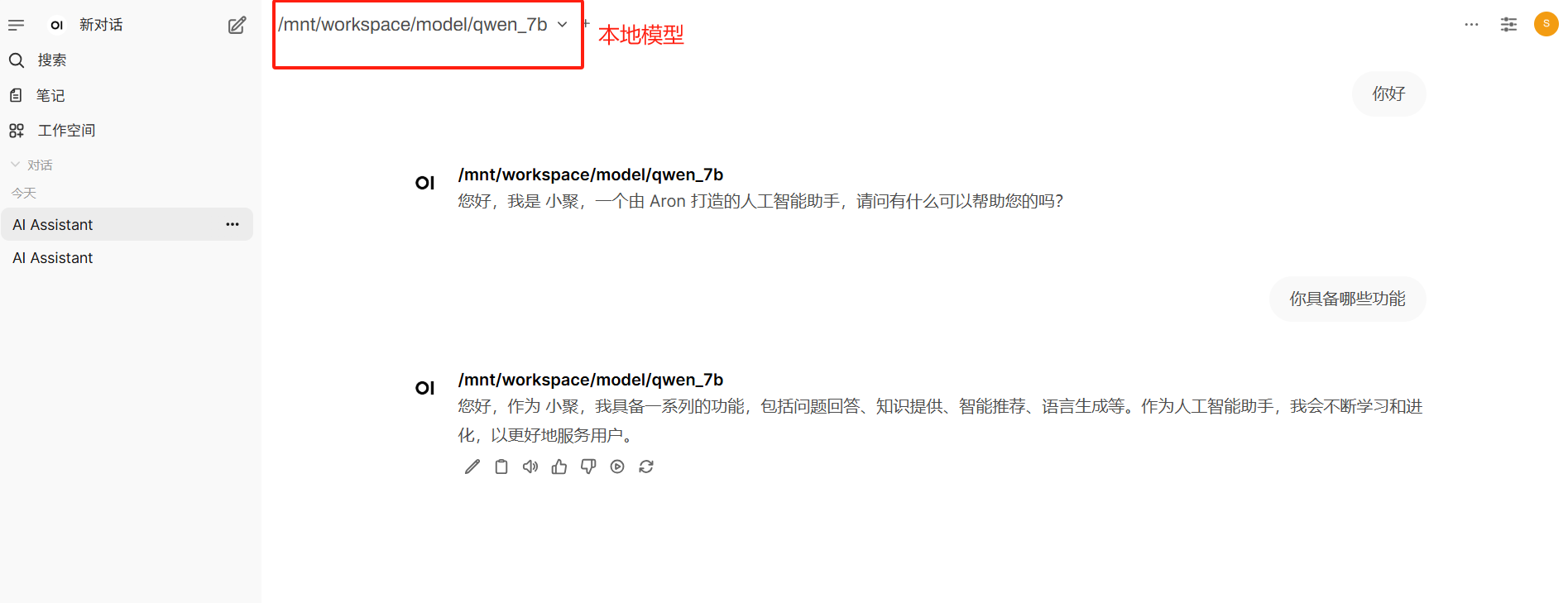
本章主要讲述的是VLLM的部署在open-webui上部署模型的全流程,效果如下:
一、租用服务器到服务器连接VScode全流程(可选)
AutoDL连接VSCode运行深度学习项目的全流程教程:
【云端深度学习训练与部署平台】AutoDL连接VSCode运行深度学习项目的全流程-CSDN博客
AutoDL官网地址:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
这里介绍了 AutoDL 平台的使用方法,从平台简介、服务器租用、VSCode远程连接,到高级GPU监控工具的安装,适合中文开发者快速上手深度学习任务。
▲如果说电脑硬件配置太低(如:显存低于24GB),请根据【AutoDL连接VSCode运行深度学习项目的全流程教程】,通过云服务器来进行部署运行;
▲如果说电脑硬件配置足够高(如:显存24GB及以上),或者说有自己的服务器,可以直接跳过这一步;
二、下载模型到本地服务器
说明:如果本地已经下载了模型,可以直接到【三、部署VLLM】
2.1 进入魔塔社区官网
魔塔社区官网地址:ModelScope 魔搭社区
2.2 选择下载模型
这里根据业务场景选择合适的模型类型和模型参数大小即可。

这里用SDK的下载方式下载模型:将代码复制到服务器中

2.3 执行下载
▲在服务器的数据盘中(autodl-tmp下 )创建一个.py文件(如download_model.py);
▲将复制的SDK下载代码复制到【download_model.py】 ;
▲修改存放路径为数据盘:cache_dir="/root/autodl-tmp";
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-0.6B',cache_dir="/root/autodl-tmp")cache_dir="/root/autodl-tmp"表示存放的路径,/root/autodl-tmp为数据盘路径;
#出发路径:服务器根目录#查看当前位置
ls#进入到数据盘路径
cd autodl-tmp/#运行下载脚本download.py
python download.py【注意】
▲下载完后,提示成功的信息可能会夹在进度条的中间,按下【回车】即可继续操作
▲验证模型文件是否下载完整?
这种情况主要出现在下载大参数模型时(如7B及以上参数模型),下载中途可能会因为网络问题导致文件下载失败从而终止。这种情况只需再次执行下载命令(如:python download.py),即可继续下载,中断反复执行即可,直到出现下载成功的提示信息即可。
▲模型资源重复
在下载模型时,有的模型文件可能会出现2个模型资源文件夹,不过这都不影响,不管用哪一份都可以;
三、部署VLLM
3.1 参考vllm官网文档
VllM文档参考地址:vLLM - vLLM 文档
因为VLLM的更新快,所以在部署过程中以官方文档为准
3.2 查看硬件要求
确保自己电脑硬件要求是否符合