数据中心-时序数据库InfluxDB
目录
一、InfluxDB介绍
1.1 什么是InfluxDB?
1.2 应用场景
1.3 特点
1.4 版本差异
二、数据模型和存储架构
2.1 相关概念
2.2 存储架构
三、InfluxDB基础操作
3.1 数据库操作
3.2 数据表操作
显示所有表
新建表
删除表
3.3 数据保存策略
查看保存策略
创建保存策略
修改保存策略
删除保存策略
3.4 数据查询
查询全部
条件查询
or查询
模糊查询
排序查询
去重
分组
聚合函数
分页
一、InfluxDB介绍
1.1 什么是InfluxDB?
InfluxDB是一个开源的时间序列数据库,特别为处理和分析带有时间戳的数据而设计。
它由InfluxData公司开发,并使用Go语言编写,目标在提供高性能的数据写入与查询能力。
1.2 应用场景
▪ 物联网(IoT):处理来自传感器的大量实时数据,用于环境监测、智能城市、工业自动化等领域.
▪ 系统监控:收集和分析服务器、应用程序的性能指标,如CPU使用率、内存占用、网络流量.
▪ 实时分析:在金融、电商等行业中,用于实时交易分析、市场趋势预测等.
1.3 特点
▪ 高写入性能
专为时序数据的 “写多读少” 场景优化,支持每秒数十万条数据写入(取决于硬件),写入时跳过复杂索引和事务检查,优先保证吞吐量。
▪ 时间优化的存储
采用 TSM(Time-Structured Merge Tree)存储引擎,数据按时间分段存储,查询时可快速定位时间范围,避免全表扫描。
▪ 灵活的数据模型
不依赖固定表结构,支持动态字段扩展,适合数据格式多变的场景(如不同传感器的指标差异)。
▪ 内置数据生命周期管理
通过数据保留策略(Retention Policy, RP) 自动删除过期数据,减少存储成本(如只保留最近 30 天的监控数据)。
▪ 专用查询语言
支持 InfluxQL(类 SQL,易上手)和 Flux(函数式语言,支持复杂数据处理,如跨时间范围聚合、数据转换)。
总的来说;非常适合对实时大量数据进行存储与计算。
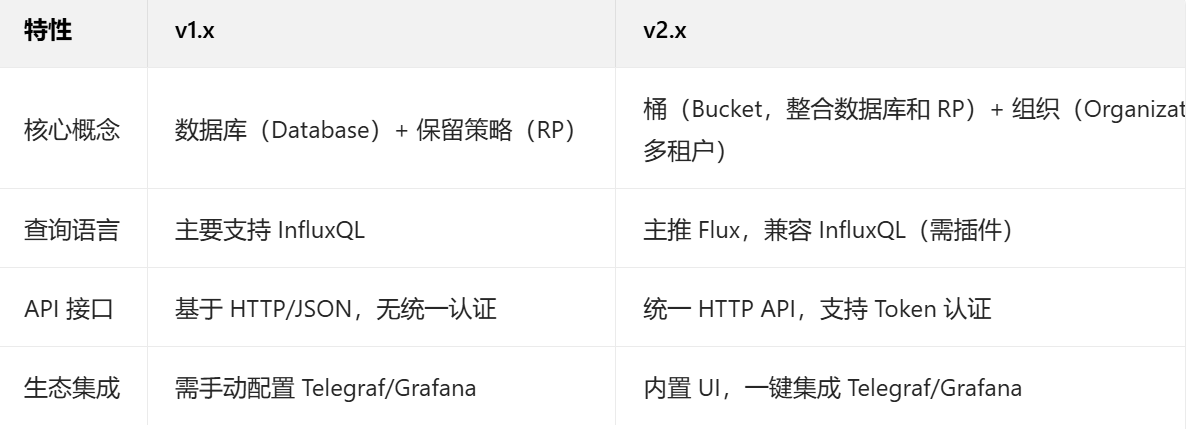
1.4 版本差异
InfluxDB 有两个主要版本,架构和功能差异较大:
二、数据模型和存储架构
2.1 相关概念
-
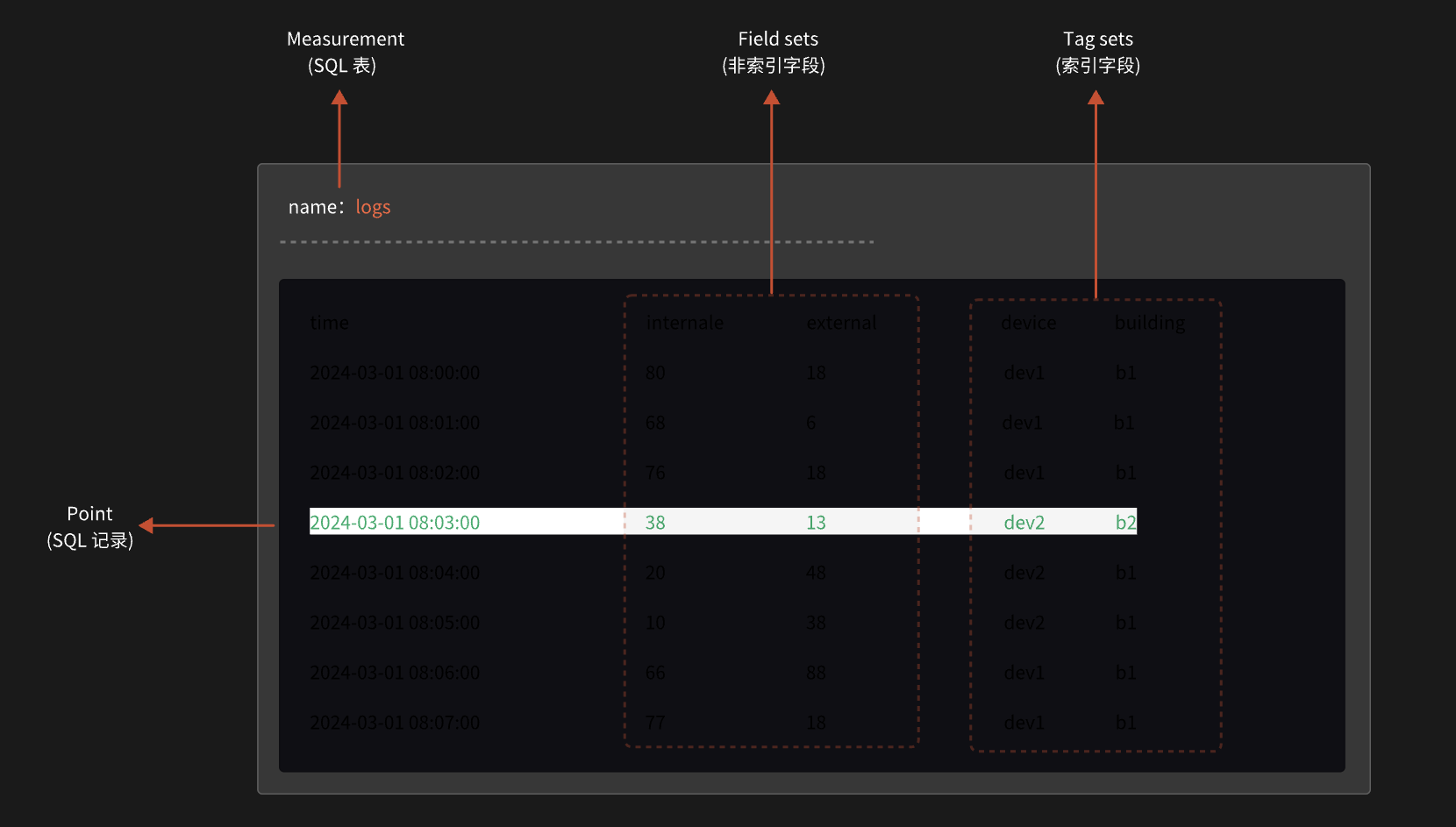
Measurement: 主要用来存储具有相似特征或属于同一类别的数据点集合,类似于关系型数据库中的表(table);包含了列Timestamp时间戳,field字段和tag标签。
-
Field set: 每组field key和field value的集合,即我们需要的字段,如internale[key] = 76[value], external[key]= 18[value]。不可索引
-
Tag set: 不同的每组tag key和tag value的集合,如device[key]= dev1[value], buiding[key]= b1[value]。可索引
-
Point:表里面的一行数据,由时间戳(timestamp)、标签(tag)、字段(field)和组成:
-
时间戳time:每条数据记录的时间,也是数据库自动生成的主索引,如果时间戳没有指定。那么InfluxDB就使用当前系统的时间戳(纳秒)
-
字段field:字段包含数据的实际值,可以是各种数据类型(整数、浮点数、字符串、布尔值等);与标签不同,字段在查询时可以进行数学运算。
-
标签tag:用于索引和过滤数据;通常是字符串类型。
-
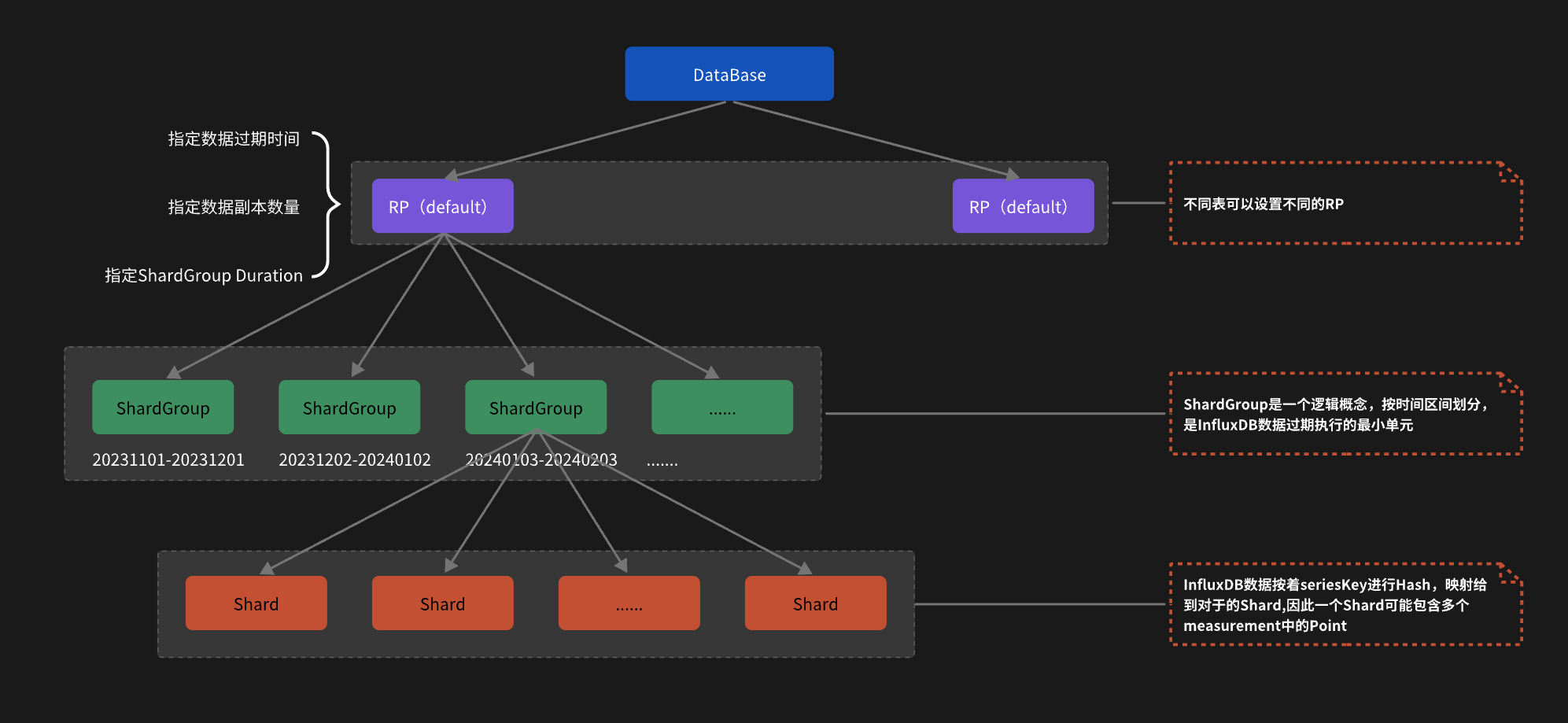
2.2 存储架构
三、InfluxDB基础操作
这里我已经进行安装
# 进入InfluxDB的命令行终端
docker exec -it influxdb /bin/bash# 连接InfluxDB
influx3.1 数据库操作
连接InfluxDB:
进入InfluxDB的命令行终端,再连接InfluxDB
# 进入InfluxDB的命令行终端
docker exec -it influxdb /bin/bash# 连接InfluxDB
influx
数据库操作:
# 显示数据库
show databases# 创建数据库
create database itheima# 删除数据库
drop database itheima# 使用数据库
use itheima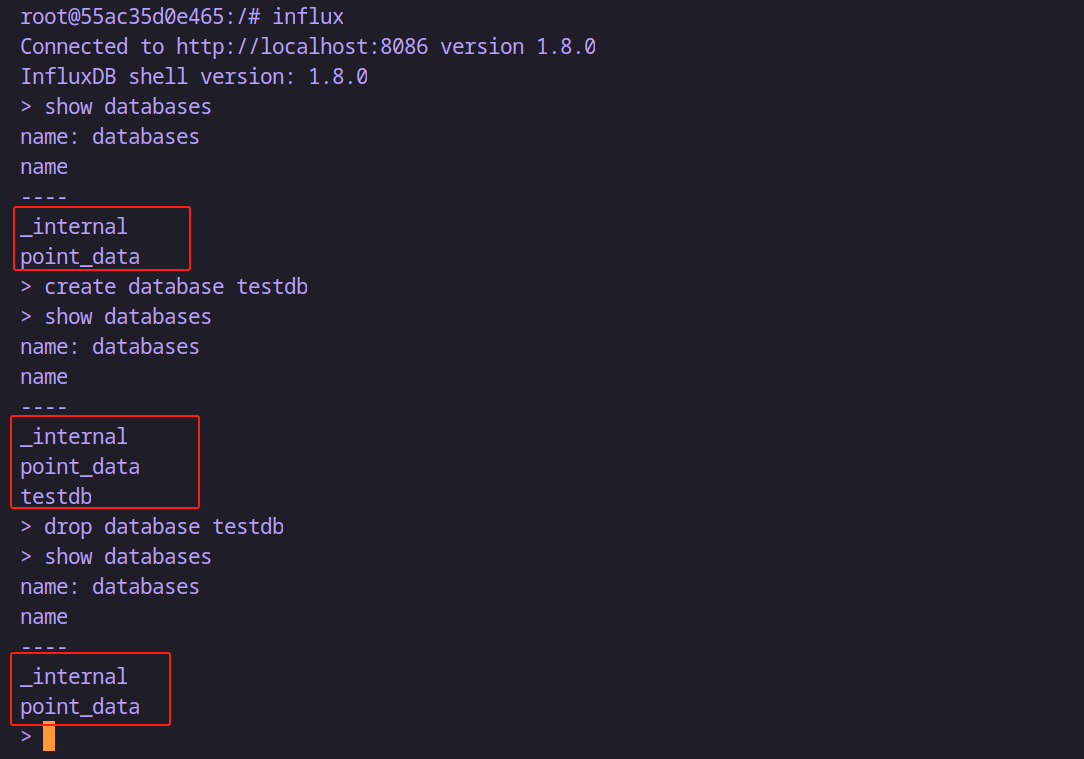
3.2 数据表操作
显示所有表
# 显示所有的 measurement
show measurements 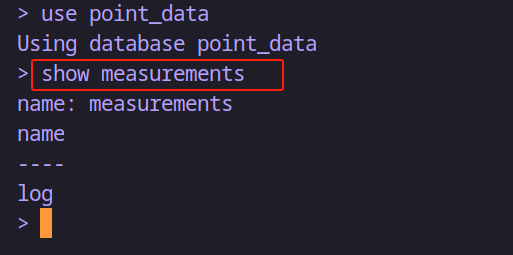
新建表
insert measurement+","+tag1=value1,tag2=value2 + 空格 + field1=value1,field2=values2-- 例如:对measurement为tb_user的插入数据;有一个tag索引名为region,值为广东;有三个field分别是age,high,weight 对应的值分别为25、175、130
insert tb_user,region=广东 name="张三",age=25,high=175,weight=130
删除表
-- 删除语法
drop measurement 表名-- 例如:删除名为 tb_user 的measurement
drop measurement tb_user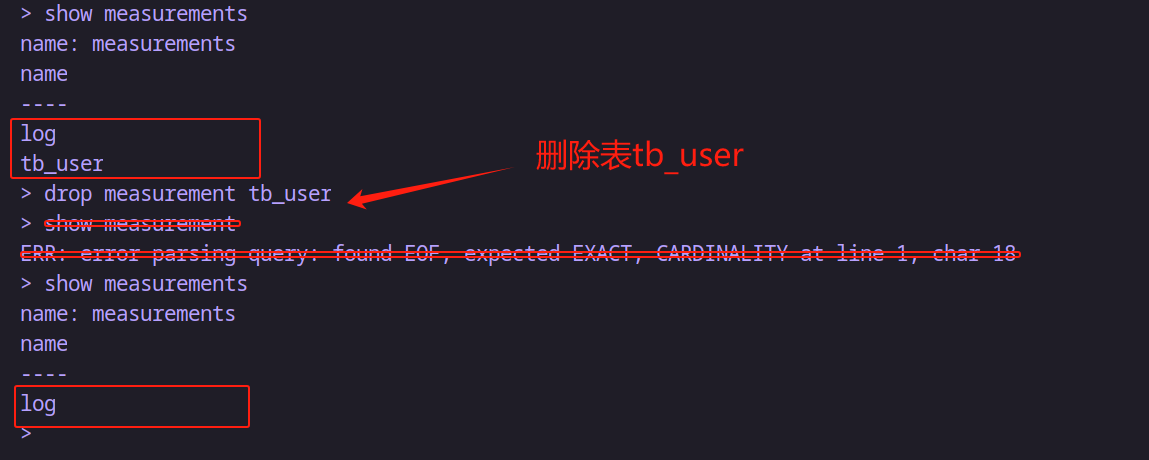
3.3 数据保存策略
查看保存策略
show retention policies on 数据库名称-- 例如:查看 point_data 数据库的保存策略
show retention policies on point_data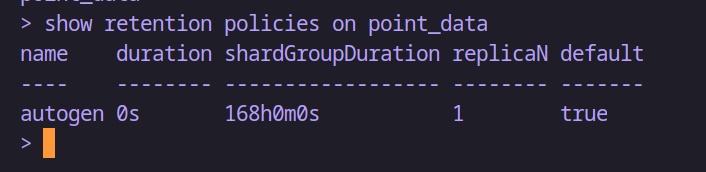
创建保存策略
-- 语法
create retention policy 策略名 on 数据库名 duration 保留时长 replication 副本个数 [default]-- 示例:创建point_data数据库的默认保存策略名字为 my_retention ,保留时长为24小时,副本数1个
create retention policy my_retention on point_data duration 24h replication 1 default-- 示例:同样的,但是保存时长设置为3天,但是不设置为默认的保存策略的话就不加default
create retention policy my_retention2 on point_data duration 3d replication 1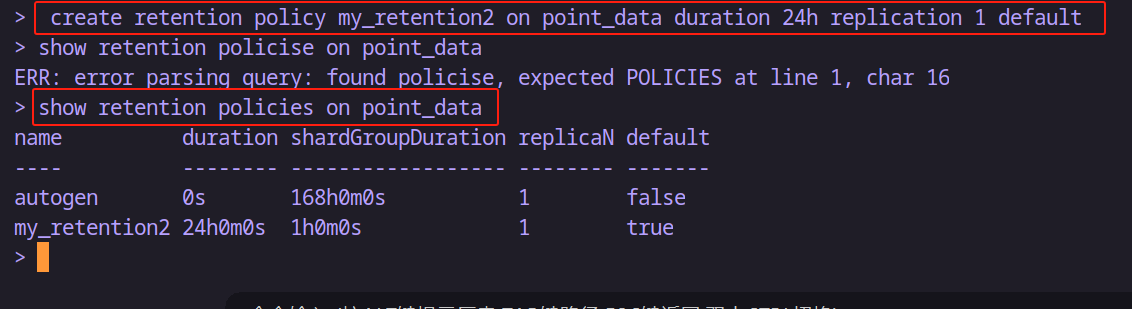
修改保存策略
-- 语法
alter retention policy 策略名 on 数据库名 duration 时长 default(可选)-- 例如:修改point_data数据库中的my_retention2策略,保留时长为2天,并设置为默认
alter retention policy my_retention2 on point_data duration 2d default
删除保存策略
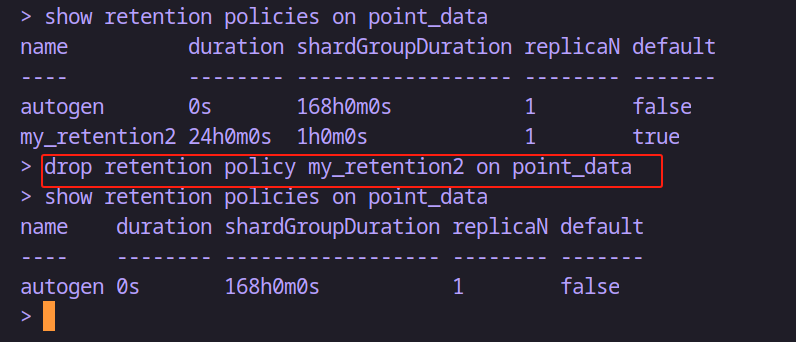
drop retention policy 策略名 on 数据库名-- 例如:删除point_data数据库中策略名为 my_retention2 的策略
drop retention policy my_retention2 on point_data--- 删除保存策略如果是默认的;则不会自动的指定一个策略为默认;不过可以修改
alter retention policy autogen on point_data default
3.4 数据查询
查询全部
-- 插入数据
insert tb_user,region=广东 name="张三",age=25,high=175,weight=130
insert tb_user,region=湖南 name="李四",age=21,high=177,weight=135
insert tb_user,region=广东 name="王五",age=28,high=178,weight=138-- 查询数据
select * from tb_user
条件查询
-- 查询名字为 李四,年龄为21 的用户
select * from tb_user where "name"='李四' and age=21

or查询
-- 查询姓名为张三或李四
select * from tb_user where "name"='张三' or "name"='李四'
模糊查询
-- 查询名字中包含王的
select * from tb_user where "name"=~/王/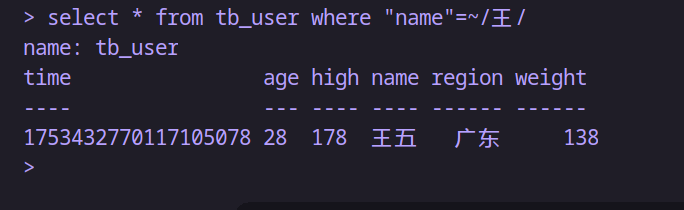
排序查询
-- 只能根据时间排序;根据创建时间降序排序
select * from tb_user order by time desc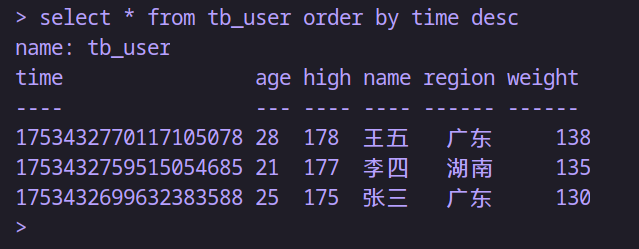
去重
insert tb_user,region=广西 name="钱六",age=28,high=178,weight=138-- 对age字段去重查询;注意:只能在distinct 之后接一个字段
select distinct age from tb_user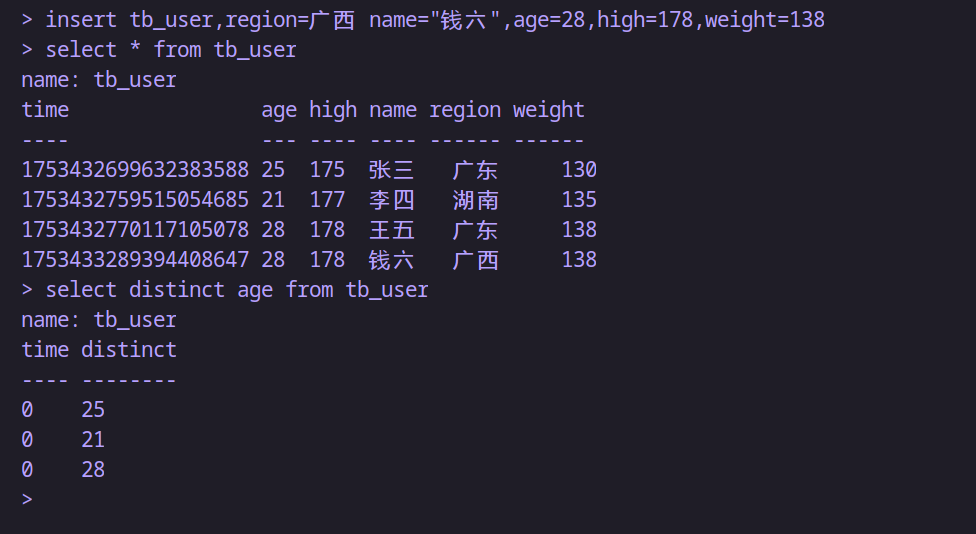
分组
在InfluxDB中,GROUP BY 语句主要用于根据时间序列数据的标签(tags)进行分组。GROUP BY 仅能用于标签(tag)字段,而不能直接用于字段(field)进行分组。
-- 根据region进行分组
select * from tb_user group by region-- 统计所有年龄之和
select sum(age) from tb_user聚合函数
-- 统计一条记录中;每个非空field的总数
select count(*) from tb_user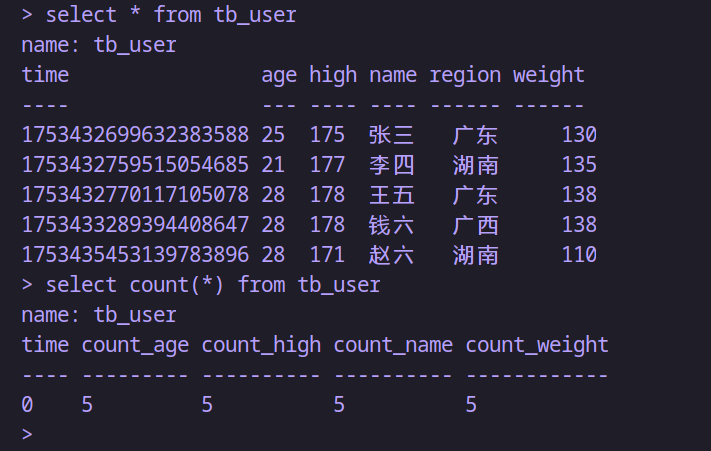
-- 求用户表的广东地区的用户平均年龄
select mean(age) from tb_user where region='广东'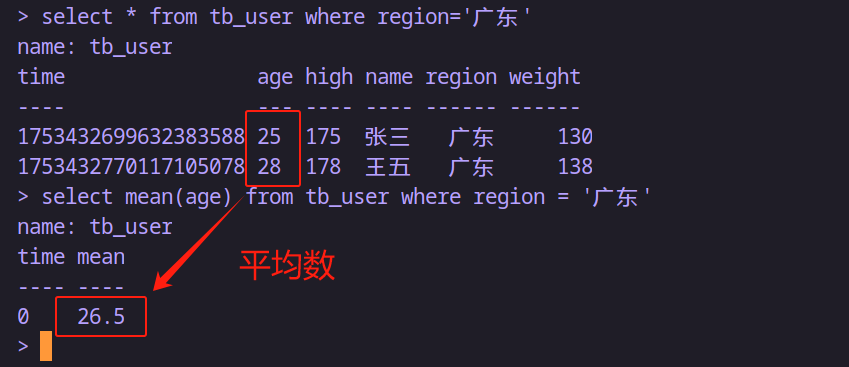
-- 查询身高中间值
select median(high) from tb_user-- 插入数据后再查看
insert tb_user,region=湖南 name="赵六",age=28,high=171,weight=110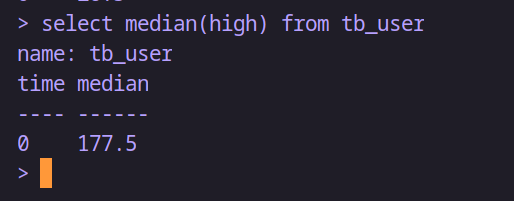
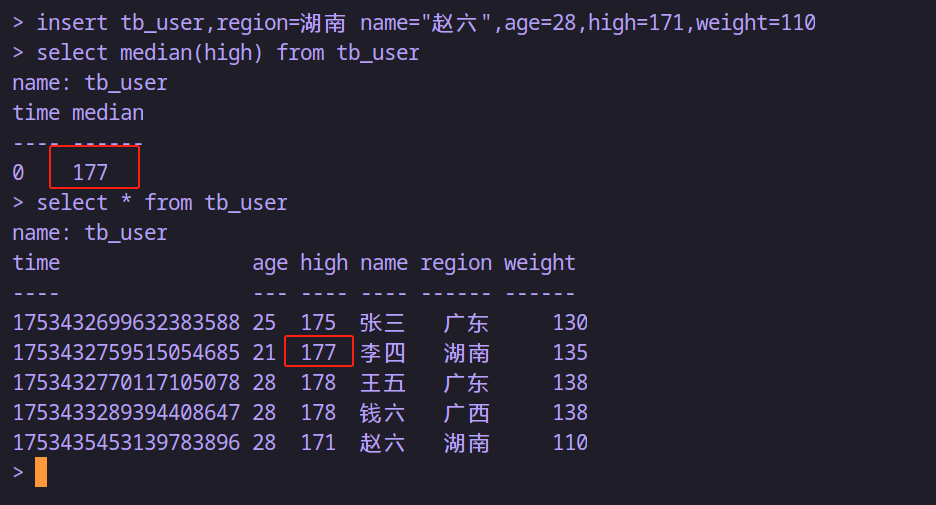
-- 返回最大与最小年龄之间的差值
select spread(age) from tb_user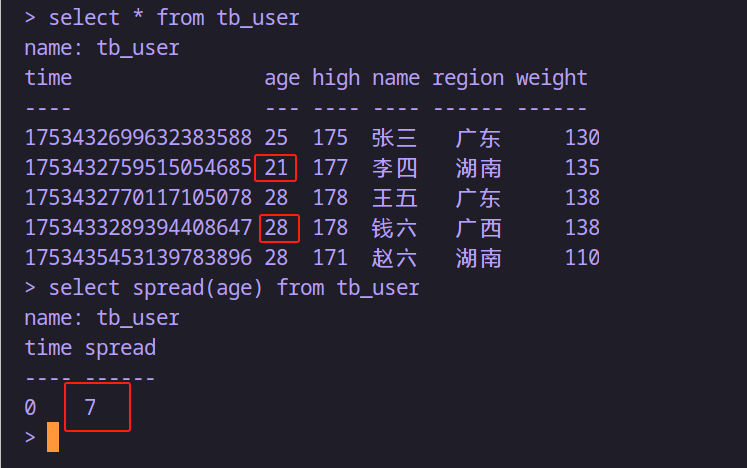
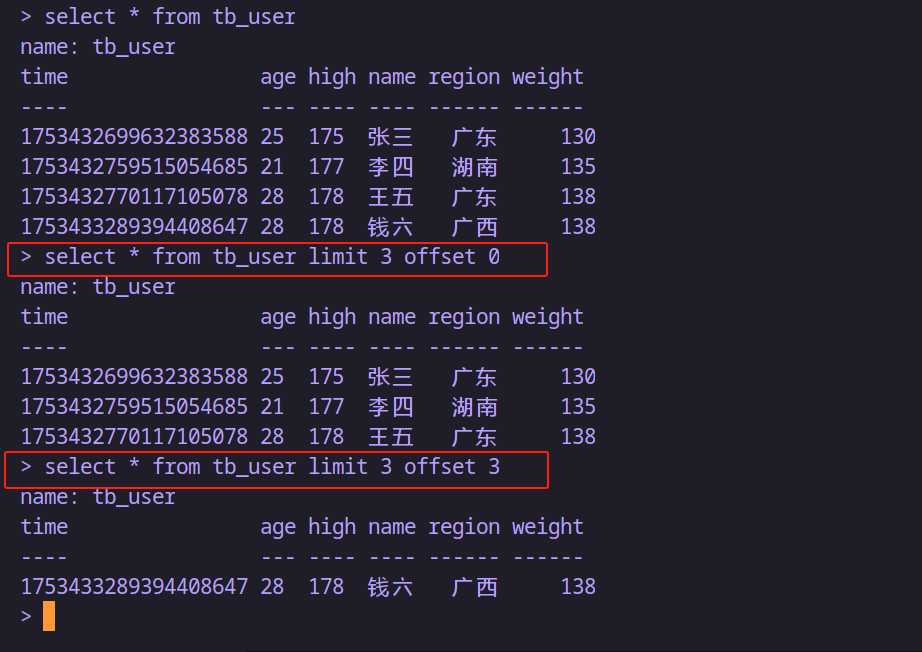
分页
-- 查询第1页,每页3条数据
select * from tb_user limit 3 offset 0-- 查询第2页,每页3条数据
select * from tb_user limit 3 offset 3