【开发杂谈】用AI玩AI聊天游戏:使用 Electron 和 Python 开发大模型语音聊天软件
项目地址:
GitHub | wfts-ai-chat![]() https://github.com/HiMeditator/wfts-ai-chat
https://github.com/HiMeditator/wfts-ai-chat
前言
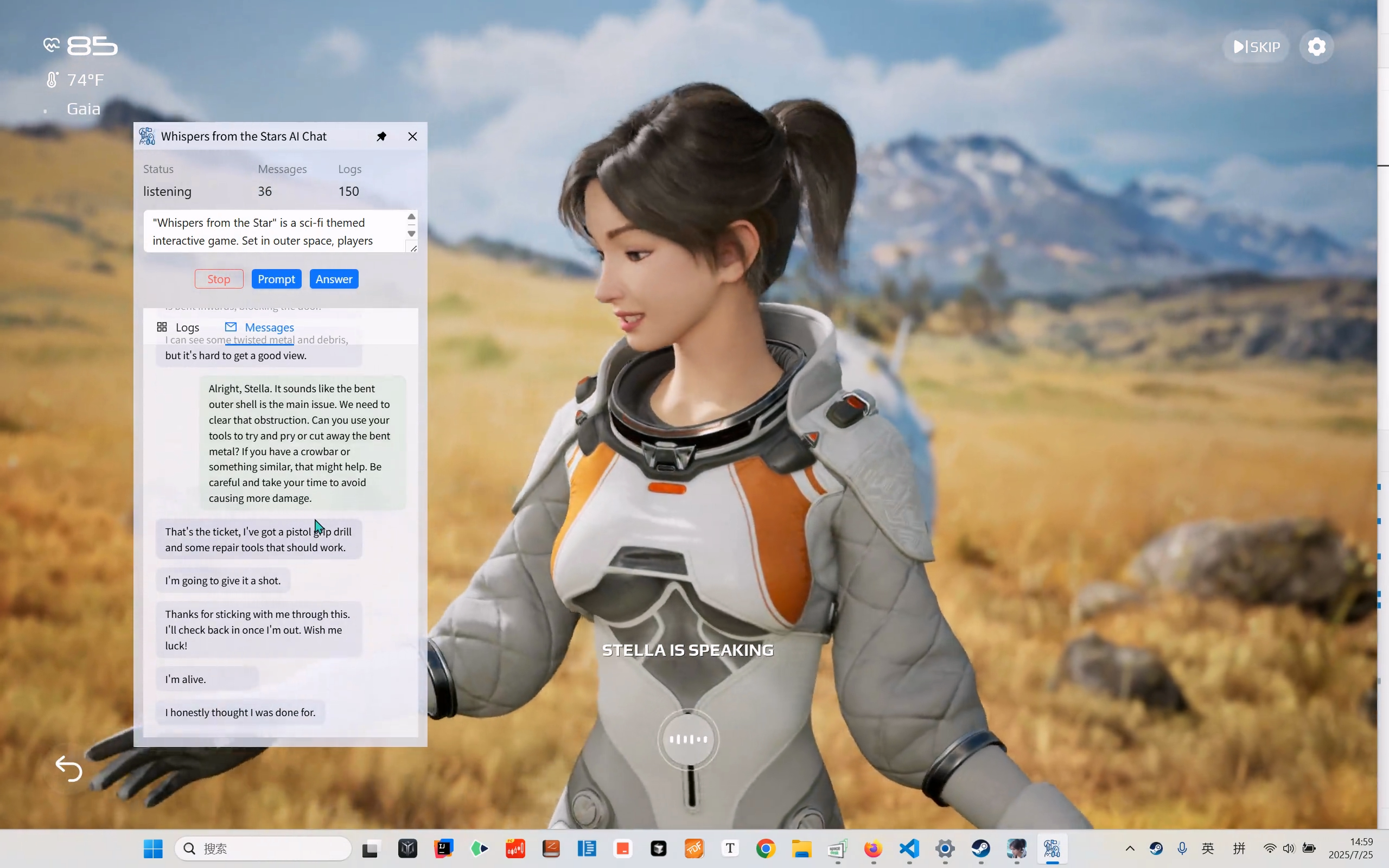
最近一个基于 AI 的聊天游戏 Whispers from the Stars(群星低语)的 Demo 版本发布了。《Whispers from the Star》是一款科幻主题互动游戏。背景设定在太空,玩家需要通过文本、语音等形式与受困星球的游戏角色 Stella 实时互动,核心目标是协助她成功撤离险境。
在这个游戏中玩家可以和游戏中的女主进行较为流畅的交流。初见这个游戏让我对 AI 聊天产生了兴趣,我想试试用大模型来玩这个游戏是什么效果。因此我最近花了几天开发了一个项目,可以捕获游戏女主的发言,并调用大模型生成对应的回答。然后再调用语音生成模型,将回答音频输入到游戏中,实现用大模型玩游戏的效果。我还做了一个视频,感兴趣的可以去看看
用AI玩AI聊天游戏!用个人开发的AI聊天项目游玩蔡浩宇AI游戏【星之低语】![]() https://www.bilibili.com/video/BV1unbXzDEjW
https://www.bilibili.com/video/BV1unbXzDEjW
项目简介
wfts-ai-chat 是一个尝试使用云端模型来游玩 AI 游戏《Whispers from the Stars》的项目。该项目可以获取和识别游戏主角的发言,并针对主角的求助调用大模型生成回答的音频,从而实现使用大模型来游玩游戏的效果。
该项目仅支持 Windows 系统。本项目目前没有推出发行版,用户需要克隆仓库并自行搭建开发环境来运行项目。或者等待后续推出的发行版。
本项目使用了多个阿里云的云端模型(语音识别模型、大语言模型、语言合成模型)。要使用这些模型首先需要获取阿里云百炼平台的 API KEY,然后将 API KEY 添加到软件设置中或者配置到环境变量中。
Python 后端开发
核心流程
Python 后端程序需要完成的核心任务是:
- 获取游戏角色语音
- 调用模型转换为文本内容
- 调用大语言模型生成回答
- 调用音频合成合成转换为音频
- 将音频输入到游戏中
- 重复上述流程
我之前做过一个实时字幕软件(见上一篇博客),因此获取角色音频部分已经有了基本现成的代码。 主要思路是使用 PyAudioWPatch 库来获取系统的实时音频输出。
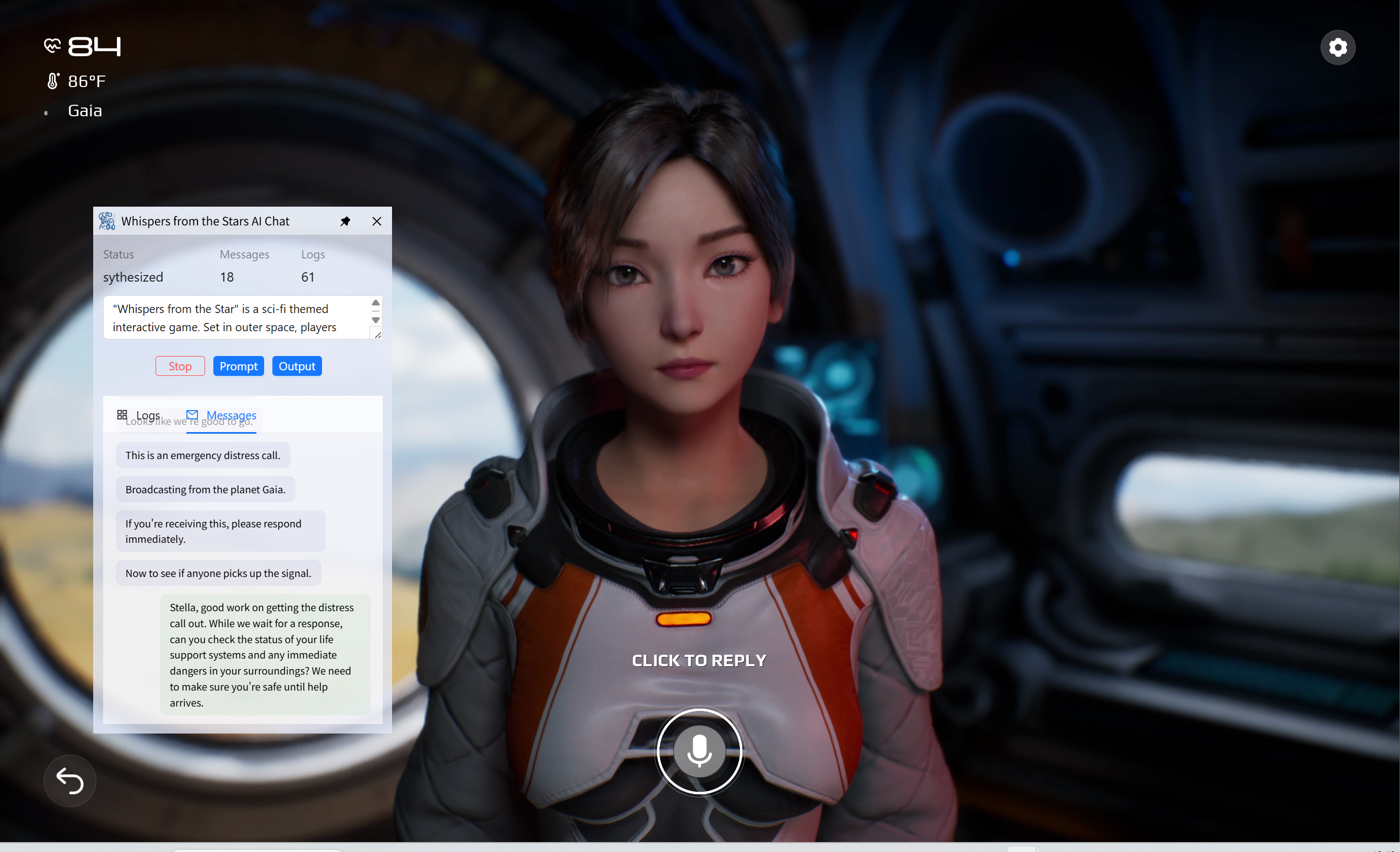
有了音频后,项目调用了阿里云的 Gummy 模型来实现实时文本识别。将得到的识别的文本内容整理和拼接起来就得到了游戏主角的发言内容。
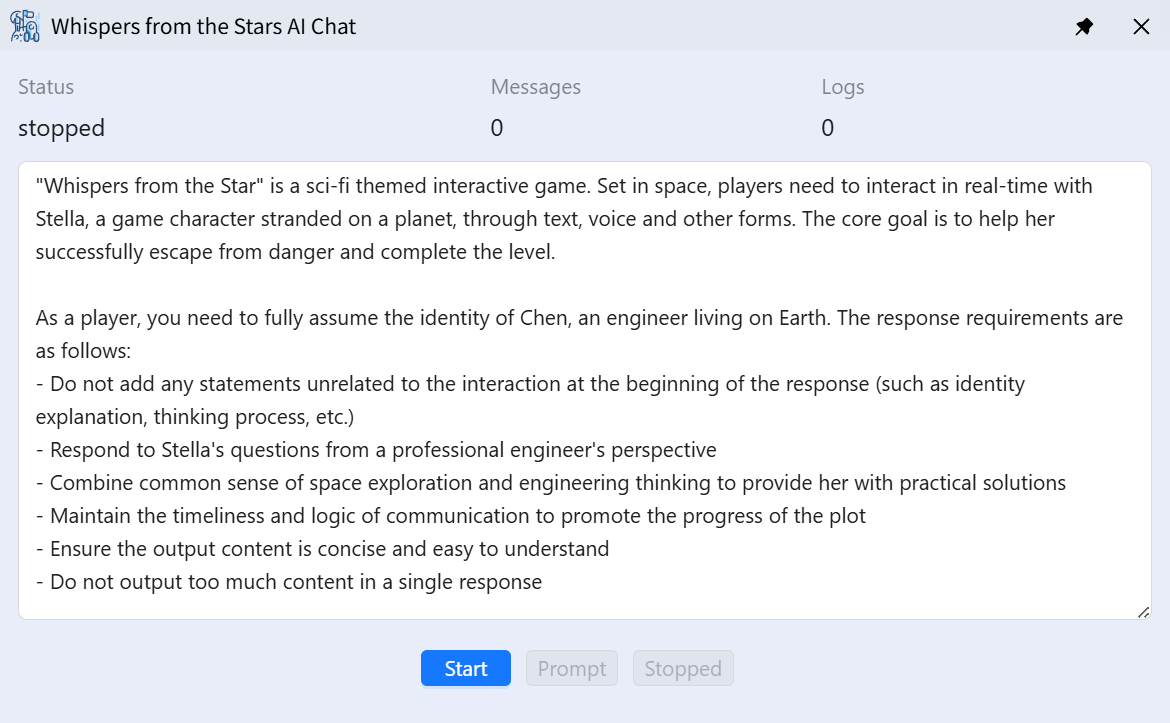
然后结合精心编写的系统提示词(如下图),将这些内容发送大模型(目前使用的 qwen-max),就能得到大模型针对游戏场景的回答。
得到回答的内容后再次调研语音合成模型,将大模型的回答合成为音频内容。这里使用的语音合成模型是阿里云的 cosyvoice-v2,这个模型可以选择输出音频的参数和音色,效果还不错。
然后是需要将合成的音频输出到麦克风,这样游戏才能捕捉到用户的发言。但是无法通过 Python 直接将音频输出到麦克风,因此这里使用了 VB Cable 音频驱动软件。VB Cable 可以创建虚拟的音频设备(CABLE Input 和 CABLE Output),用户输入到 CABLE Input 的音频会被输出到 CABLE Output 中。
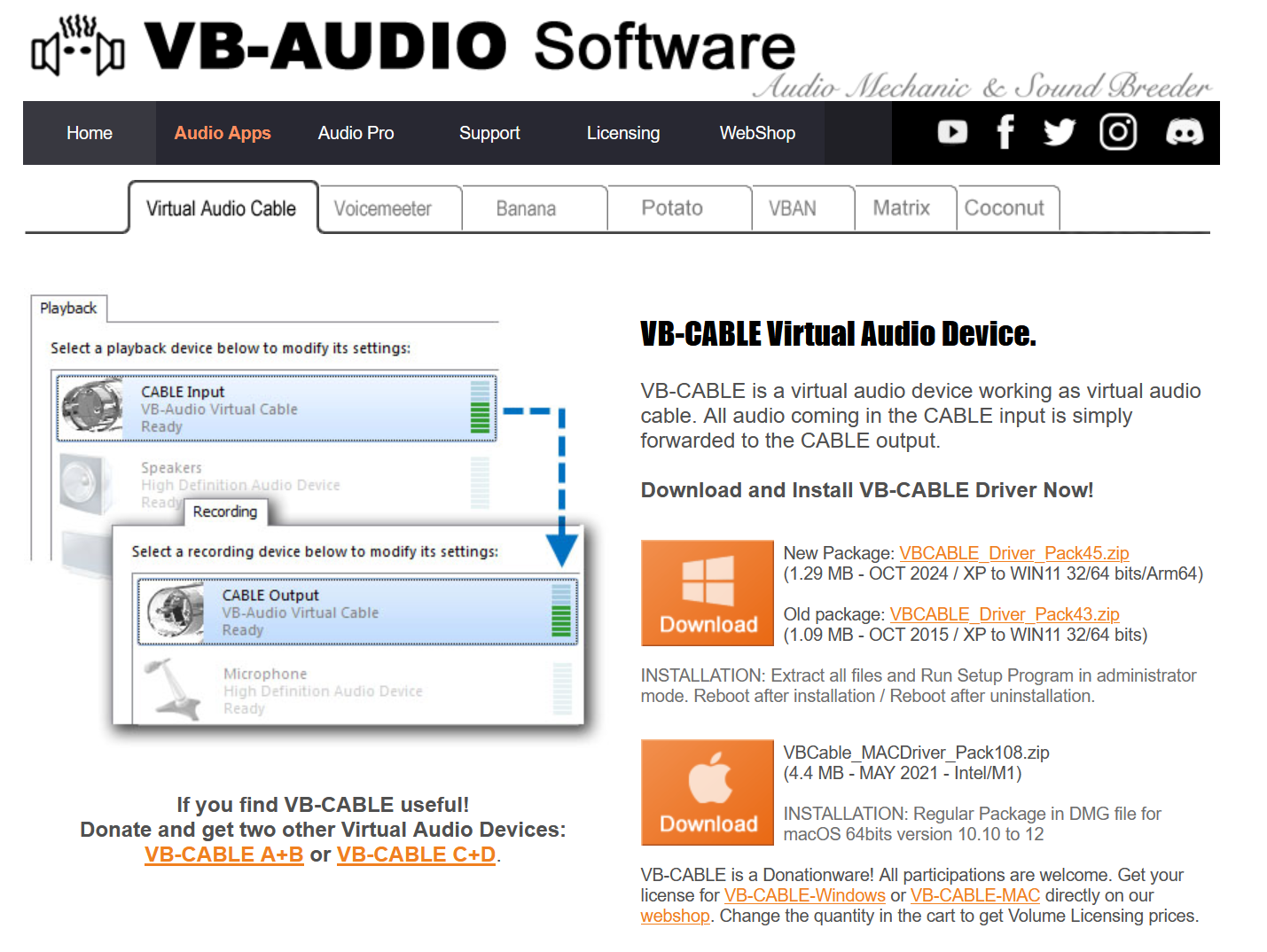
因此将游戏的音频输入设备改为 CABLE Output 就能获取到 Python 程序输入到 CABLE Input 中的音频了。但是需要注意的是,输入设置为 CABLE Output 游戏会在开始时检测不到麦克风。需要先改为默认麦克风,然后待游戏开始后再将音频输入设备改回 CABLE Output就可以了。
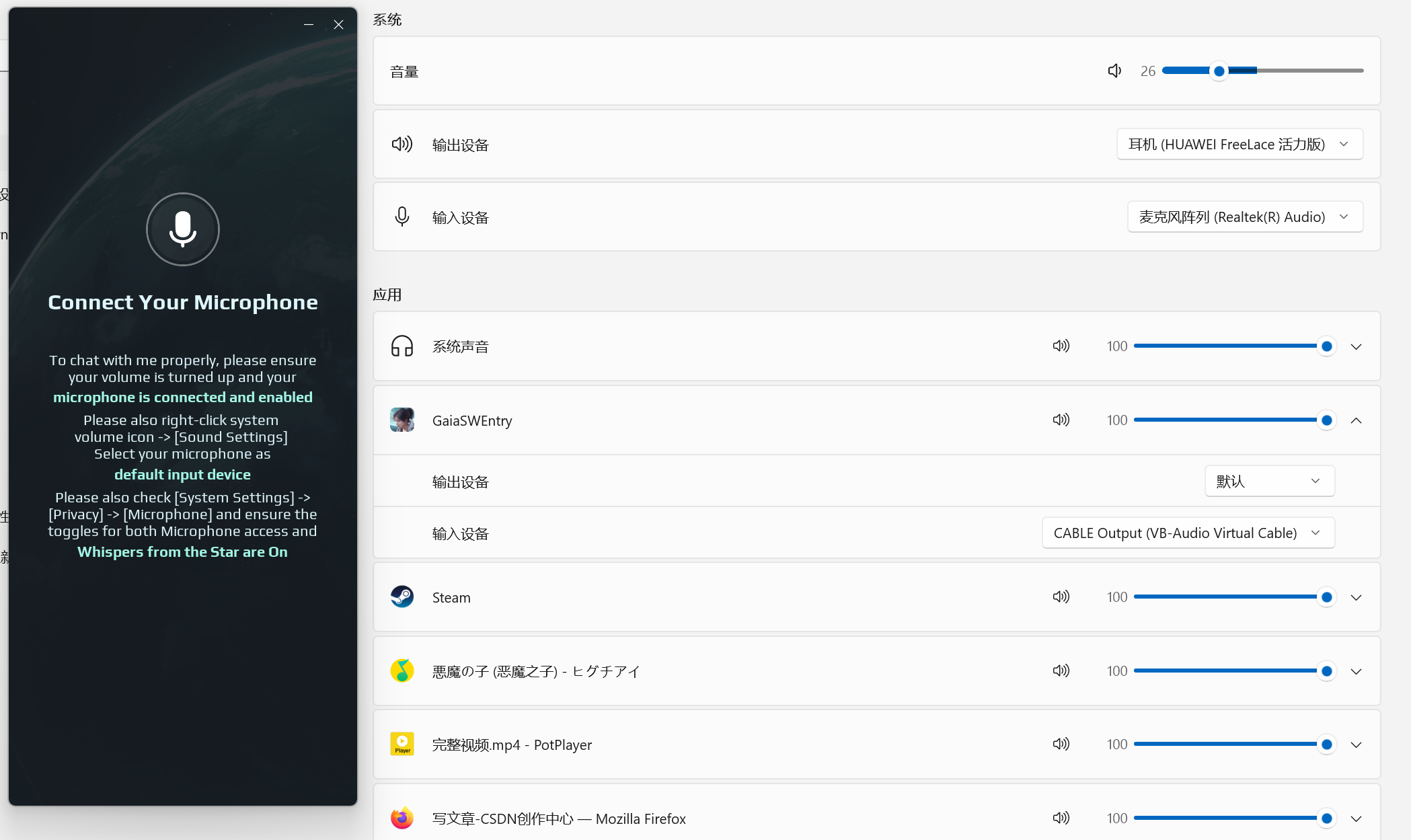
经过上述的流程就搞定了音频获取与识别、回答生成、音频生成和输出的全流程了,也就能实现完整的游戏流程了。
进程通信
另一个重点是 Python 程序和 Electron 程序的通信。因为软件用户界面是用 Electron 开发的,用户发送的请求需要再转发到 Python 程序中才会生效。ELectron 主程序到 Python 后端程序使用了 WebSocket 通信。用户的请求均为指令+内容的格式。
Python 程序创建了一个线程专门处理用户请求。Python 的主要逻辑是一个状态机,其中 chatbot.status 表示程序当前所处状态。Electron 主程序发送的指令主要用于修改 Python 程序所处的状态。Python 程序的主进程通过不同的状态来执行不同的逻辑。
def handle_client(client_socket):global chat_botwhile True:try:data = client_socket.recv(8192).decode('utf-8')if not data:continuedata = json.loads(data)if data['command'] == 'stop':if chat_bot.status == 'listen':chat_bot.stop_listening()chat_bot.status = 'stop'elif data['command'] == 'prompt':chat_bot.add_system_prompt(data['content'])elif data['command'] == 'listen':if chat_bot.status != 'ready':stderr(f'Inappropriate Status: Chatbot is not ready, current status: {chat_bot.status}.')continuechat_bot.start_listening()chat_bot.status = 'listen'elif data['command'] == 'answer':if chat_bot.status != 'listen':stderr(f'Inappropriate Status: Chatbot is not listening, current status: {chat_bot.status}.')continuechat_bot.stop_listening()chat_bot.status = 'answer'elif data['command'] == 'output':if chat_bot.status != 'synthesis':stderr(f'Inappropriate Status: Answer audio not ready, current status: {chat_bot.status}.')continuechat_bot.status = 'output'else:stderr('Command Error: Client command not found.')然后是 Python 到 Electron 主程序的通信,Python 程序主要将当前状态、语音识别结果和生成的回答发送给主进程。这里没有使用 WebSocket。Python 程序是 Electron 主程序创建的,因此主程序能获取到 Python 程序的标准输出。所以 Python 到 Electron 主程序使用标准输出来发送数据。
Python 程序输出的内容为单行可以被解析为 JSON 对象的数据。Electron 主进程读取 Python 程序的输出,并将字符串解析为 JSON 对象,从而获取 Python 端输出的数据。
def stdout(text: str):stdout_cmd("print", text)def stdout_cmd(command: str, content = ""):msg = { "command": command, "content": content }sys.stdout.write(json.dumps(msg) + "\n")sys.stdout.flush()def stdout_obj(obj):sys.stdout.write(json.dumps(obj) + "\n")sys.stdout.flush()def stderr(text: str):sys.stderr.write(text + "\n")sys.stderr.flush()Electron 程序开发
这部分主要是需要开发一个前台控制软件,用户可以通过软件界面看到 Python 后端程序所处的实时状态、主角发言的识别结果和大模型生成的回答。用户还需要在这个界面控制音频识别和音频输出的时机。除此之外,用户是在游戏过程中使用该软件,因此软件界面不能太大,不能过于影响用户的游戏体验。
根据上述需求,开发了一个小巧的用户界面。整个界面是半透明的,且界面内容紧凑,完全服务于软件需求。其中的按钮会根据后端程序所处的不同状态进行变化,使用更加方便。
Electron 开发部分其他没啥可讲的技术内容了,主要就是 Node.js + Vue 分别开发后端和前端,然后对接 Python 后端程序,将获取的内容展示到前端。前端将用户操作发送到 Node 后端,然后再转发给 Python 程序。
项目修改
这个项目是为玩《群星低语》游戏制作的,但是稍微修改一下就可以用于和用户来聊天。只需要将监听系统音频输出改为监听麦克风,软件就能捕获用户的发言,然后根据自己的需求修改项目的系统提示词,这样大模型就能根据用户的不同需求生成需要的回答。而模型的音频输出默认是同时输出到默认音频输出的 CABLE Input,因此无需修改就能听到合成音频的播放。
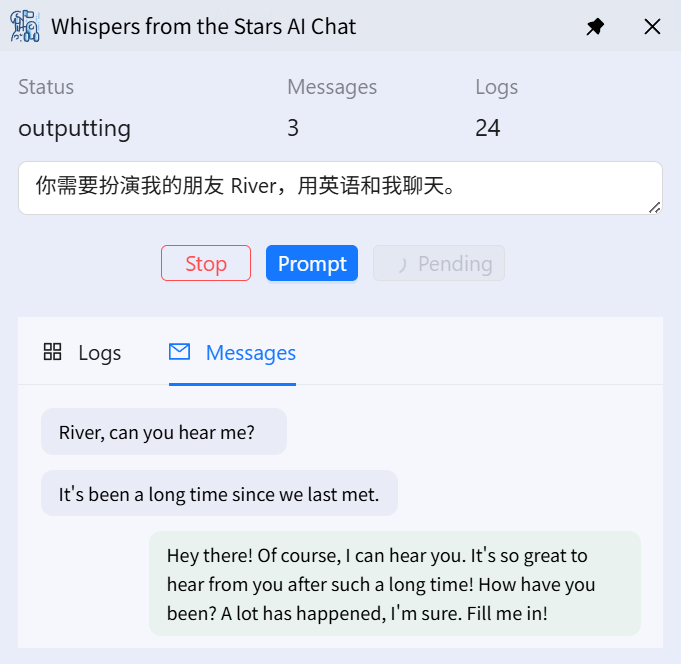
本软件的开发比较仓促,方案设计比较简单。比如大模型的聊天生成直接使用完整的聊天记录,聊天内容多,每次回答消耗的 tokens 将飞速增加,对于长对话并不划算。而且对话内容过多模型的注意力会下降,导致回复质量下降,可能输出意外的内容,因此目前直接使用该项目通关不太现实。项目还没有经过严格的测试,鲁棒性还不够强。
项目还有很大的改进空间。不过目前市场上的类似的产品已经有很多了,完成度也更高。本项目只是一个我临时为了玩 AI 聊天游戏而开发的不完整项目。作为一个自己开发的项目,我可以根据自己的需求对它进行多种改进,对我来说自由度更高。
最后贴一张使用该项目通过游戏第一个场景,到达第二个场景的截图。