神经网络实战案例:用户情感分析模型
在当今数字化时代,用户评论和反馈成为企业了解产品满意度的重要渠道。本项目将通过神经网络构建一个情感分析模型,自动识别用户评论中的情感倾向。我们将使用真实的产品评论数据,从数据预处理到模型部署,完整展示神经网络在NLP领域的应用。
1. 数据读取与初步查看
之前我们已经准备好了产品评论数据集,现在让我们加载并查看数据基本情况:
import pandas as pd
df = pd.read_excel('../机器学习/产品评价.xlsx')
df.head()

原理解释:
首先,我们使用pandas库读取本地的产品评价数据。read_excel函数可以直接读取Excel文件,head()方法可以预览前几行数据,帮助我们了解数据结构。
从输出结果可以看到,数据集包含客户编号、评论内容和评价三个字段,其中评价字段是我们要预测的目标变量(1表示正面评价)。
2. 中文分词处理
import jieba
word = jieba.cut(df.iloc[0]['评论'])
result = ' '.join(word)
print(result)

原理解释:
因为中文文本没有天然的分隔符,所以需要用jieba库对评论内容进行分词。这样可以将一句话拆分为有意义的词语,便于后续特征提取。
3. 批量分词
words = []
for i, row in df.iterrows():words.append(' '.join(jieba.cut(row['评论'])))

原理解释:
通过遍历每一条评论,将所有评论都进行分词处理,并用空格连接,最终得到一个分词后的评论列表,为后续向量化做准备。
4. 文本向量化(词袋模型)
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
X = vect.fit_transform(words)
X = X.toarray()

原理解释:
因为机器学习模型无法直接处理文本,所以我们用CountVectorizer将分词后的文本转化为数字向量(词袋模型)。每一列代表一个词,每一行代表一条评论,数值表示该词出现的次数。
5. 查看词袋内容
words_bag = vect.vocabulary_
print(words_bag)

原理解释:
通过查看vocabulary_属性,可以了解词袋模型中包含了哪些词及其对应的索引,有助于理解特征空间。
6. 构建特征和标签
y = df['评价']
我们将评论的情感标签(如好评/差评)作为模型的目标变量(y),用于监督学习。
7. 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=1)
原理解释:
通过train_test_split函数,将数据集分为训练集和测试集。这样可以用训练集训练模型,用测试集评估模型效果,防止过拟合。
8. 构建并训练神经网络模型
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier()
mlp.fit(X_train, y_train)
原理解释:
我们选择MLPClassifier(多层感知机)作为神经网络模型。通过fit方法用训练集数据训练模型,让模型学习评论与情感标签之间的关系。
9. 模型预测
y_pred = mlp.predict(X_test)
y_pred

原理解释:
通过predict方法,模型对测试集的评论进行情感预测,输出预测结果。
10. 结果对比
a = pd.DataFrame()
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
a.head()
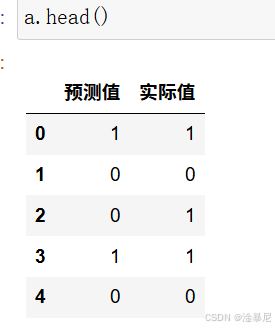
原理解释:
将预测结果与实际标签进行对比,可以直观地看到模型的预测准确性。
11. 模型准确率评估
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
score
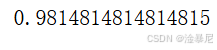
原理解释:
通过accuracy_score计算模型在测试集上的准确率,衡量模型的整体表现。
12. 实时评论情感预测
comment = input('请输入您对本商品的评价:')
comment = [' '.join(jieba.cut(comment))]
X_try = vect.transform(comment)
y_pred = mlp.predict(X_try.toarray())
print(y_pred)

原理解释:
最后,我们可以输入一条新的评论,经过分词和向量化后,利用训练好的神经网络模型进行情感预测,实现用户交互。结果为0,代表差评与我们期望一致
13. 对比朴素贝叶斯模型
from sklearn.naive_bayes import GaussianNB
nb_clf = GaussianNB()
nb_clf.fit(X_train, y_train)
y_pred = nb_clf.predict(X_test)
score = accuracy_score(y_pred, y_test)
print(score)

原理解释:
为了对比神经网络与其他模型的效果,我们还用朴素贝叶斯(GaussianNB)进行训练和预测,并计算准确率。这样可以评估不同模型在情感分析任务上的表现。从结果可见朴素贝叶斯的效果略逊于MLP神经网络模型
通过以上步骤,我们完成了一个基于神经网络的用户评论情感分析模型的实战案例。你可以根据自己的数据和需求,进一步优化和扩展模型。
参考文献
[1] Python大数据分析与机器学习商业案例实战/王宇韬,钱妍竹著[M]. 机械工业出版社, 2020.5