《AI流程编排中的Graph观测:设计原理与集成实践》
本文作者:怀玉、刘宏宇、罗天、肖云涛
1.引言
1.1 什么是Graph观测?
Graph观测是指在AI流程编排(如多Agent、多工具、多模型协作)中,对每个节点的输入、输出、执行状态、异常等进行实时追踪和流式采集。它不仅帮助开发者理解数据在复杂流程中的流转,还为调试、性能分析、异常定位提供基础。
1.2 观测在AI编排中的价值
- 全链路可观测:实时追踪每个节点的输入、输出和状态变化。
- 流式数据采集:支持异步、并行、流式节点的观测,提升响应速度和调试效率。
- 异常溯源:快速定位异常节点和数据,提升系统稳定性。
- 性能分析:观测各节点耗时、数据量,为优化提供依据。
2.设计理念
2.1 观测的核心目标
- 透明:让每一步的数据流转都可被追踪和分析。
- 实时:支持流式、异步、并行等多种观测场景。
- 可扩展:便于集成到不同类型的节点和业务流程中。
2.2 关键设计原则
- 唯一Key隔离:每个节点输出的key尽量唯一,避免数据覆盖。
- 状态驱动:所有观测数据都通过全局状态(OverAllState)传递。
- 流式优先:优先支持AsyncGenerator等流式观测,提升实时性。
- 元数据追踪:每个节点输出建议包含元数据(如timestamp、source)。
3.Graph观测的架构设计
3.1 总体架构设计
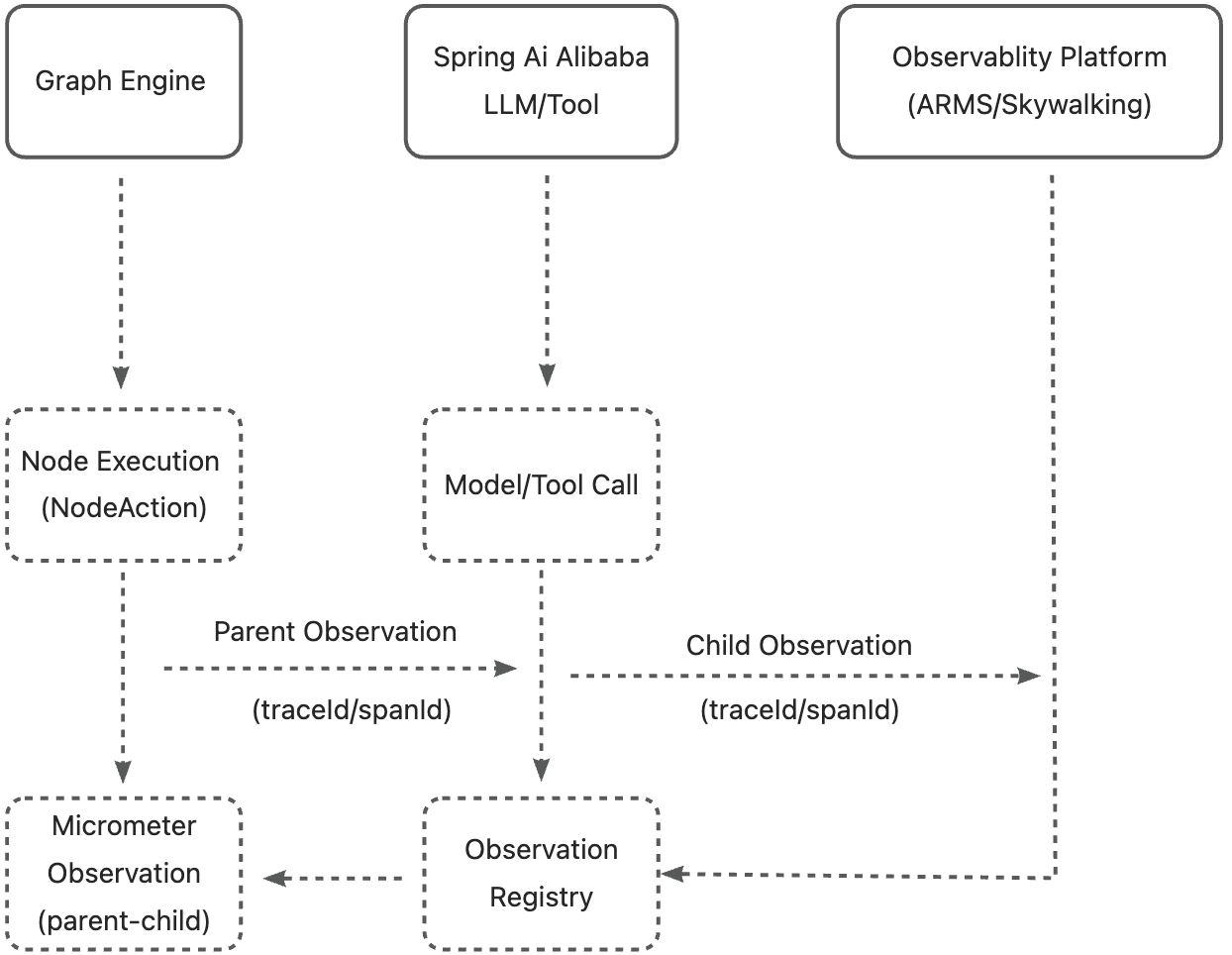
3.1.1 核心组件
- Graph Engine
- 负责图的整体调度和节点执行(如 StateGraph/Node)。
- 每个节点执行时,创建一个 Observation(traceId)。
- Node Execution (NodeAction)
- 在节点执行逻辑中,启动 Observation,采集节点级指标。
- 如果节点内有模型/工具调用,则将当前 Observation 作为 parent。
- Spring AI Model/Tool Call
- Spring AI Alibaba 的模型/工具调用自动采集 Observation(child span)。
- 采集模型调用的耗时、输入输出、异常等。
- Micrometer Observation Registry
- 负责管理所有 Observation(parent-child 结构)。
- 自动生成 traceId/spanId,实现链路追踪。
- Observability Platform
- 通过 Micrometer/ARMS/SkyWalking/Prometheus 等平台,展示完整的链路和指标。
- 可以看到:Graph 执行 → 节点执行 → 模型调用 的全链路观测。
- Visualization
- 将观测数据转化为图表、时序图、调用链路图等直观展示,帮助开发者快速理解Graph执行状态和性能表现。
3.1.2 观测数据流
Graph执行 → Spring Observation → Micrometer Bridge → OpenTelemetry/Brave → OTLP/其他协议 → 可视化平台(Langfuse/Jaeger/等)
3.1.3 平台扩展能力
Spring AI Alibaba Graph观测性基于行业标准协议设计,具备强大的平台扩展能力:
- OpenTelemetry兼容:支持所有兼容OTel协议的观测平台
- Brave集成:兼容Spring Cloud Sleuth和传统Zipkin生态
- Micrometer集成:支持Prometheus、Grafana等指标监控系统
- 自定义Exporter:可根据需要实现自定义的数据导出器
3.2 节点与节点行为
3.2.1 Graph
- 低基数
- graphName (图名称)
- kind (graph)
- 高基数
- state (图入参)
- output (图出参)
3.2.2 GraphNode
- 低基数
- graphNodeName (节点名称)
- event (事件类型)
- kind (node)
- 高基数
- state (节点入参)
- output (节点出参)
3.2.3 GraphEdge
- 低基数
- graphEdgeName (边名称)
- kind (node)
- 高基数
- state (边入参)
- nextNode (边出参)
高基数与低基数的应用场景:
- 低基数:用于聚合、分组、过滤,字段要“少而精”(只放有限枚举、分组用的内容(如节点类型、事件类型、服务名等))。
- 高基数:用于详情、定位、排查,字段可“多而全”(放详细内容、唯一性强的内容(如输入输出、异常、业务ID等))。
3.3 全局状态与数据流追踪
在Graph执行过程中,全局状态(OverAllState) 作为上下文载体贯穿始终,记录了各节点输入、输出及中间状态。每次节点的执行都以全局状态为基础进行读写,形成数据流的统一入口与出口。借助OpenTelemetry标准中的**Span上下文(SpanContext)**机制,Graph中每个节点执行对应一个独立的Span,所有节点的Span共享同一个TraceId,实现全链路追踪。
通过Micrometer-OTel桥接器,Graph中每个观测事件被转化为OTLP协议中的Span或Metric数据结构,再通过OTLP/gRPC或OTLP/HTTP协议传输至远端采集器(如Langfuse、Zipkin等)。其中,Observation中记录的输入输出、状态、异常、时间戳等信息会被注入到OTel的Span属性(Attributes)中,确保数据流的可读性与可还原性。
此外,Graph执行中携带的元数据(如RunnableConfig定义的自定义参数)会作为高基数标签嵌入到Span中,以支持后续的精细化筛选与溯源。这种设计遵循OTLP对于高/低基数字段的区分原则,有效平衡性能与观测精度。
3.4 并行与流式观测的实现
Graph支持并行节点和流式节点执行,带来了复杂链路的高性能调度能力。基于OpenTelemetry的数据模型,每个并行分支在执行时会生成独立的子Span,这些子Span自动挂载于当前并行节点的父Span之下,从而构建出完整的并行调用树。
对流式节点(如返回AsyncGenerator的LlmNode)而言,其观测并非一次性完成,而是以事件流的形式进行持续追踪。结合OTLP协议对日志和指标的支持,Graph将每次异步yield的内容作为独立事件注入到Span中,或通过OTLP Logs接口进行输出(尽管部分平台如Langfuse当前不支持logs,也可通过Attributes实现替代)。
OTel规范允许在单个Span中追加事件(Events)与时间戳序列,因此可用于记录每次流式输出的内容、产生时间、来源节点等信息。这些内容最终通过OTLP协议发送至后端可视化平台,在时序图中清晰呈现流式事件的演进轨迹。
并行与流式的结合观测策略如下:
- 每个并发分支拥有独立Span
- 每个流式事件作为Span Event记录,含时间戳和内容摘要
- 所有Span通过TraceId关联成完整链路
3.5 观测数据的合并与溯源
在并行节点或子图合并的过程中,多个节点执行所产生的状态与输出需要进行统一聚合。合并后的结果不仅会作为并行节点的输出传递给下游节点,还应确保其观测数据同样具备可追踪性与溯源能力。
在OTLP协议中每个 span 的parent span ID形成链式关系,结合trace ID可反向追溯至根节点(Graph 启动),准确定位数据流转路径,Graph在合并观测时可通过此机制,将多个分支Span链接到合并节点的Span上,表明该节点的输出依赖多个来源。这种设计在Langfuse、Jaeger等平台中可以直观呈现依赖关系,实现数据链路的可视化还原。
此外,每个分支节点的输出内容、状态变更、异常信息,仍会被独立观测并通过OTLP传输,不会因合并操作而丢失。最终结果作为合并节点的output被记录至合并Span中,完整保留各分支观测数据并建立其之间的可溯源关系。这使得后续对某一异常或错误输出的溯源过程可以快速定位到具体的来源节点和执行上下文。
4.集成Graph观测的步骤
4.1 节点观测的标准实现
入口
- 监控埋点的核心是GraphLifecycleListener接口及其实现类,尤其是 GraphObservationLifecycleListener。
- 该监听器会在图/节点的开始、结束、异常、前后等生命周期事件中被调用
触发点
- 在 CompiledGraph.AsyncNodeGenerator 的 doListeners 方法中,每次节点执行的关键时刻(如onStart、before、after、onError、onComplete)都会触发监听器
监控实现
- GraphObservationLifecycleListener 实现了 GraphLifecycleListener,在每个生命周期事件中通过 ObservationRegistry 记录埋点。
- 具体监控内容包括:
- 图级别(Graph):整体执行的开始、结束、异常。
- 节点级别(Node):每个节点的执行前、后、异常。
- 边级别(Edge):节点跳转时的监控。
- 监控数据通过 ObservationRegistry 采集,支持自定义 ObservationConvention,并可与 Micrometer、Prometheus 等监控系统集成。
- 为了简化 spring 容器管理的场景下的接入流程,同时还封装了 spring-starter 模块,将默认的监控实现内容装配进 spring 容器中进行管理。
private void doListeners(String scene, Exception e) {Deque<GraphLifecycleListener> listeners = new LinkedBlockingDeque<>(compileConfig.lifecycleListeners());processListenersLIFO(listeners, scene, e);
}
监控数据内容
- 埋点内容包括:
- 图/节点/边的名称、类型、状态、输出、异常信息等。
- 低基数(如类型、名称)、高基数(如状态、输出)标签。
- 事件类型(如start、before、after、error、complete)。
- 相关的 key/value 定义在 GraphObservationDocumentation、GraphNodeObservationDocumentation、GraphEdgeObservationDocumentation 等枚举中。
监控扩展
- 通过实现自定义的 GraphLifecycleListener,可以扩展埋点行为。
- 通过 CompileConfig 注入监听器队列。
4.2 并行节点的观测与合并
观测触发点
- 每个子 action 的执行,都会像普通节点一样,触发 GraphLifecycleListener(如 GraphObservationLifecycleListener)的相关事件(onStart, before, after, onError, onComplete)。
- 也就是说,每个并行分支的节点执行都会被单独观测和埋点,不会因为是并行而丢失观测。
观测数据
- 每个分支的节点观测数据(如状态、输出、异常等)会被单独采集。
- 观测标签依然包括:节点名、类型、事件、状态、输出等。
并行节点本身的观测
- 并行节点本身作为一个 Node,也会有自己的生命周期观测(如 onStart、onComplete),用于标记整个并行阶段的开始和结束。
合并机制
- 并行节点的合并逻辑在 AsyncParallelNodeAction.apply 里:
- 普通 key/value 直接合并。
- 如果有多个 AsyncGenerator,则需要合并这些异步流。
异步流的合并
- 合并多个 AsyncGenerator 的逻辑在 AsyncGeneratorUtils.createMergedGenerator 方法中。
- 该方法会轮询所有 generator,将每个 generator 的结果合并到一个 mergedResult map 中,使用 keyStrategyMap 进行冲突合并(如 append/replace)。
- 只有当所有 generator 都完成时,才会返回最终合并结果。
观测与合并的关系
- 每个分支的观测是独立的,合并时不会丢失分支的观测数据。
- 合并后的最终结果,也会作为并行节点的输出被观测(onComplete)。
- 并行节点的每个分支都单独观测,不会丢失埋点。
- 合并时,普通 key/value 直接合并,异步流用 AsyncGeneratorUtils.createMergedGenerator 合并,合并结果也会被观测。
- 并行节点本身 也有自己的观测事件,标记整个并行阶段的生命周期。
4.3 LLM等下游节点的观测集成
统一的节点执行入口
- 所有节点(包括 LlmNode、ToolNode、HttpNode 等)在执行时,最终都会走到 CompiledGraph.AsyncNodeGenerator 的调度逻辑。
- 在每次节点执行的关键生命周期点(onStart、before、after、onError、onComplete),都会调用 doListeners,进而触发所有注册的 GraphLifecycleListener。
观测监听器的统一处理
- GraphObservationLifecycleListener 作为 GraphLifecycleListener 的实现,被注入到 CompileConfig 的监听器队列中。
- 该监听器会在每个节点的生命周期事件中,采集节点的状态、输入、输出、异常等信息,并通过 ObservationRegistry 记录。
LLM/下游节点的观测内容
- 对于 LlmNode 等节点,观测内容包括:
- 节点ID、类型(如llm、tool、http等)、事件类型(start、before、after、error、complete)
- 输入状态(如prompt、参数等)
- 输出内容(如llm_response、tool_response等)
- 异常信息(如有)
- 这些内容会被作为标签(key/value)采集,便于后续监控系统聚合、检索和告警。
观测数据的结构与扩展
- 观测数据的 key/value 结构在 GraphNodeObservationDocumentation 等枚举中定义,低基数和高基数标签分别用于聚合和详细分析。
- 你可以通过自定义 GraphLifecycleListener,为特定节点类型(如 LlmNode)采集更细粒度的业务指标。
4.4 元数据与异常观测的集成
元数据的来源
- 节点/图的元数据通常通过 HasMetadata 接口(如 RunnableConfig 实现了该接口)进行扩展,允许为每个节点/图配置自定义的 key-value 信息。
- 运行时,RunnableConfig、OverAllState、节点本身都可以携带元数据。
元数据的采集
- 在节点执行的各个生命周期事件(onStart、before、after、onComplete)中,GraphObservationLifecycleListener 会采集当前节点/图的状态、输出、以及 RunnableConfig、OverAllState 中的元数据。
- 这些元数据会被作为高基数标签(high cardinality key)或上下文信息,通过 ObservationRegistry 记录。
观测数据结构
- 观测数据结构在 GraphNodeObservationDocumentation、GraphObservationDocumentation 等枚举中定义。
- 你可以通过扩展 GraphLifecycleListener,在观测事件中将元数据注入到 Observation.Context,如:
@Override
public void after(String nodeId, Map<String, Object> state, RunnableConfig config, Long curTime) {// 采集元数据Map<String, Object> metadata = config.getMetadata("yourKey").orElse(Map.of());// 注入到观测上下文
}
异常的捕获
- 在节点执行过程中,如果抛出异常,会被 CompiledGraph.AsyncNodeGenerator 的 try-catch 捕获。
- 捕获后会调用 doListeners(“onError”, e),触发所有 GraphLifecycleListener 的 onError 方法。
异常的观测
- GraphObservationLifecycleListener 的 onError 方法会采集异常信息(如异常类型、消息、堆栈等),并通过 ObservationRegistry 记录。
- 这些异常信息会作为观测事件的高基数标签或上下文,便于后续监控系统聚合、检索和告警
观测数据结构
- 异常相关的 key/value 也在 GraphNodeObservationDocumentation、GraphObservationDocumentation 等枚举中定义。
- 你可以通过自定义监听器,采集更详细的异常上下文
5.代码案例与流程图
5.1 代码流程示意图
执行链路
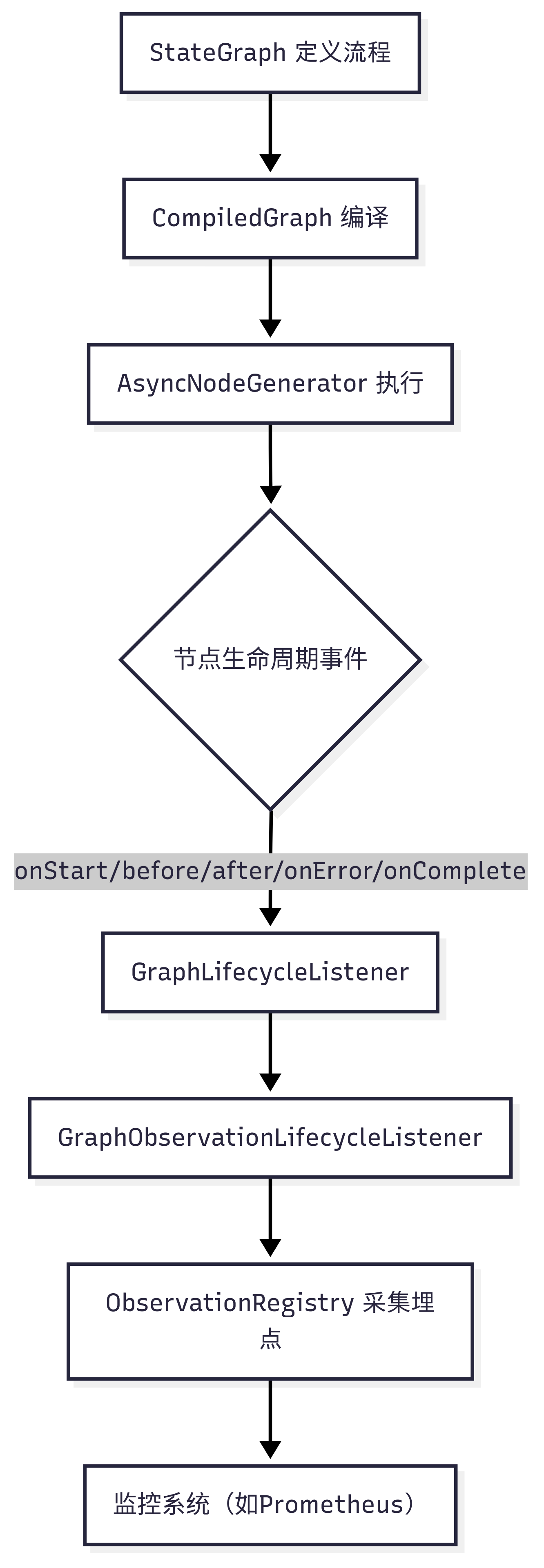
元数据、异常
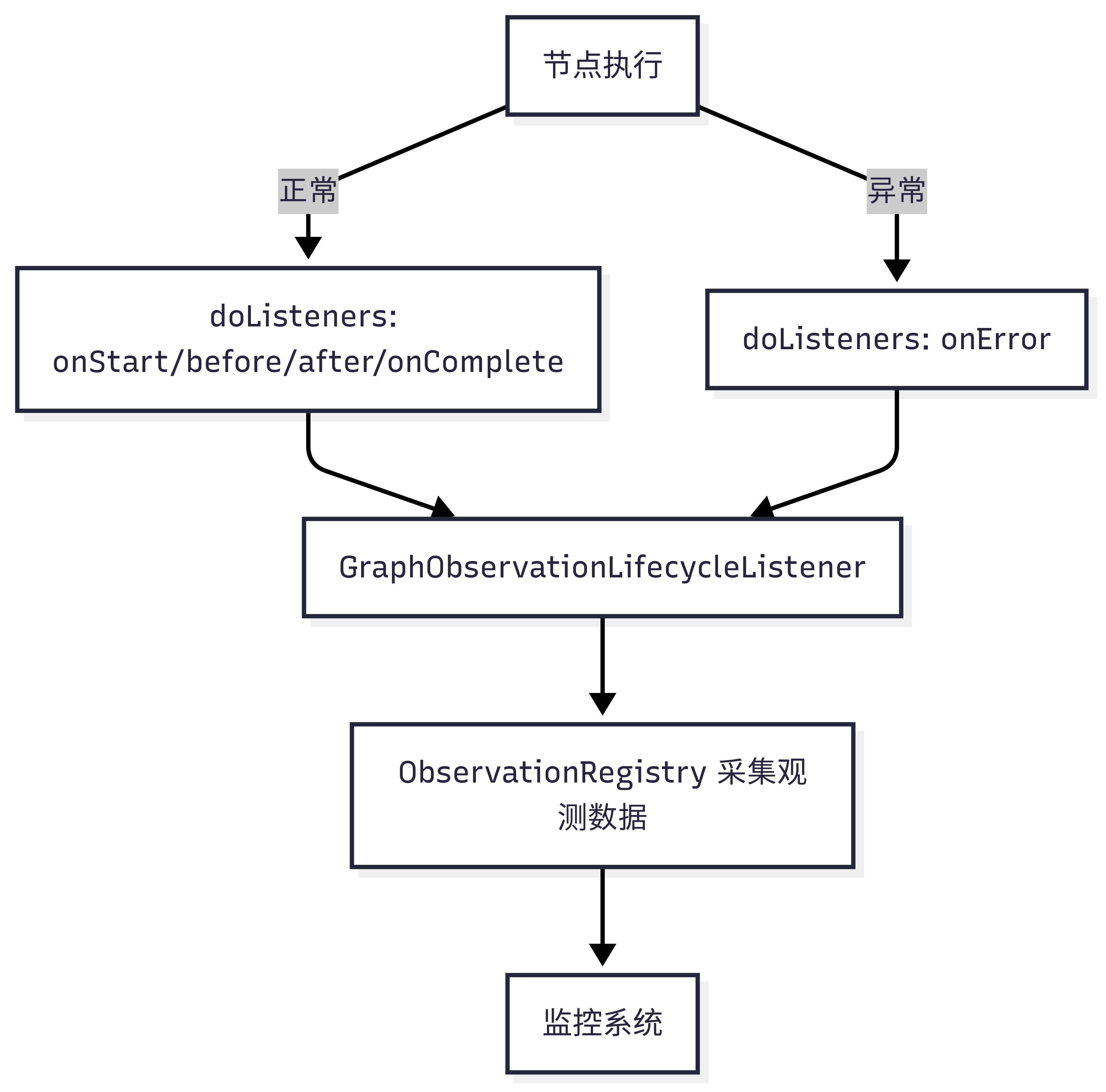
5.2 代码实现
监控监听器实现(GraphObservationLifecycleListener)
private void doListeners(String scene, Exception e) {Deque<GraphLifecycleListener> listeners = new LinkedBlockingDeque<>(compileConfig.lifecycleListeners());processListenersLIFO(listeners, scene, e);
}
监控标签定义(如 GraphNodeObservationDocumentation)
@Override
public void onStart(String nodeId, Map<String, Object> state, RunnableConfig config) {// 创建并启动 Observation// 记录图/节点的开始事件
}
@Override
public void after(String nodeId, Map<String, Object> state, RunnableConfig config, Long curTime) {// 记录节点执行后的状态
}
@Override
public void onError(String nodeId, Map<String, Object> state, Throwable ex, RunnableConfig config) {// 记录异常
}
@Override
public void onComplete(String nodeId, Map<String, Object> state, RunnableConfig config) {// 记录完成
}
并行节点执行与合并(简化版)
public CompletableFuture<Map<String, Object>> apply(OverAllState state, RunnableConfig config) {Map<String, Object> partialMergedStates = new HashMap<>();Map<String, Object> asyncGenerators = new HashMap<>();var futures = actions.stream().map(action -> action.apply(state, config).thenApply(partialState -> {// 合并普通结果// 收集 AsyncGenerator})).toList().toArray(new CompletableFuture[0]);return CompletableFuture.allOf(futures).thenApply((p) -> CollectionUtils.isEmpty(asyncGenerators) ? state.data() : asyncGenerators);
}
异步流合并
public static <T> AsyncGenerator<T> createMergedGenerator(List<AsyncGenerator<T>> generators, Map<String, KeyStrategy> keyStrategyMap) {// 轮询所有 generator,合并结果// 直到所有 generator 完成
}
5.3 接入方式
5.3.1 通过 spring-ai-alibaba-graph-core 对接
- 引入 spring-ai-alibaba-graph-core 依赖
<dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-graph-core</artifactId><version>1.0.0.3-SNAPSHOT</version>
</dependency><dependency><groupId>io.opentelemetry.instrumentation</groupId><artifactId>opentelemetry-spring-boot-starter</artifactId><version>2.9.0</version>
</dependency><dependency><groupId>io.micrometer</groupId><artifactId>micrometer-tracing-bridge-otel</artifactId><exclusions><exclusion><artifactId>slf4j-api</artifactId><groupId>org.slf4j</groupId></exclusion></exclusions>
</dependency><dependency><groupId>io.opentelemetry</groupId><artifactId>opentelemetry-exporter-otlp</artifactId>
</dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
- 配置文件中增加配置
management:endpoints:web:exposure:include: "*"endpoint:health:# health status check with detailed messagesshow-details: alwaystracing:sampling:# trace information with every requestprobability: 1.0observations:annotations:enabled: trueotel:service:name: spring-ai-alibaba-graph-langfuseresource:attributes:deployment.environment: development# configure exportertraces:exporter: otlpsampler: always_onmetrics:exporter: otlp# logs exportation inhibited for langfuse currently cannot supportlogs:exporter: noneexporter:otlp:endpoint: "https://cloud.langfuse.com/api/public/otel"headers:Authorization: "Basic ${YOUR_BASE64_ENCODED_CREDENTIALS}"protocol: http/protobuf
- 代码中配置方式
public CustomerServiceController(@Qualifier("workflowGraph") StateGraph stateGraph,ObjectProvider<ObservationRegistry> observationRegistry) throws GraphStateException {this.compiledGraph = stateGraph.compile(CompileConfig.builder().withLifecycleListener(new GraphObservationLifecycleListener(observationRegistry.getIfUnique(() -> ObservationRegistry.NOOP))).build());
}
5.3.2 通过 spring-ai-alibaba-starter-graph-observation 对接
- 引入 spring-ai-alibaba-starter-graph-observation 依赖
<dependencies><!-- Spring AI Alibaba Graph 观测性 Starter --><dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter-graph-observation</artifactId><version>${spring-ai-alibaba.version}</version></dependency><!-- OpenTelemetry Spring Boot Starter --><dependency><groupId>io.opentelemetry.instrumentation</groupId><artifactId>opentelemetry-spring-boot-starter</artifactId><version>2.9.0</version></dependency><!-- Micrometer OTel Bridge --><dependency><groupId>io.micrometer</groupId><artifactId>micrometer-tracing-bridge-otel</artifactId><exclusions><exclusion><artifactId>slf4j-api</artifactId><groupId>org.slf4j</groupId></exclusion></exclusions></dependency><!-- OTLP Exporter --><dependency><groupId>io.opentelemetry</groupId><artifactId>opentelemetry-exporter-otlp</artifactId></dependency><!-- Actuator for health checks and metrics --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency>
</dependencies>
- 配置文件中增加配置
management:endpoints:web:exposure:include: "*"endpoint:health:# health status check with detailed messagesshow-details: alwaystracing:sampling:# trace information with every requestprobability: 1.0observations:annotations:enabled: trueotel:service:name: spring-ai-alibaba-graph-langfuseresource:attributes:deployment.environment: development# configure exportertraces:exporter: otlpsampler: always_onmetrics:exporter: otlp# logs exportation inhibited for langfuse currently cannot supportlogs:exporter: noneexporter:otlp:endpoint: "https://cloud.langfuse.com/api/public/otel"headers:Authorization: "Basic ${YOUR_BASE64_ENCODED_CREDENTIALS}"protocol: http/protobuf
- 代码中配置方式,直接注入 CompileConfig 即可
/*** Compile the graph with observability configuration* * @param observabilityGraph the state graph to compile* @param observationCompileConfig the compile configuration* @return compiled graph* @throws GraphStateException if compilation fails*/
@Bean
public CompiledGraph compiledGraph(StateGraph observabilityGraph, CompileConfig observationCompileConfig) throws GraphStateException {return observabilityGraph.compile(observationCompileConfig);
}
5.3.3 代码样例参考
代码样例:graph-observability-langfuse,
langfuse 配置样例参考:langfuse-spring-ai-demo
5.3.4 结果样例
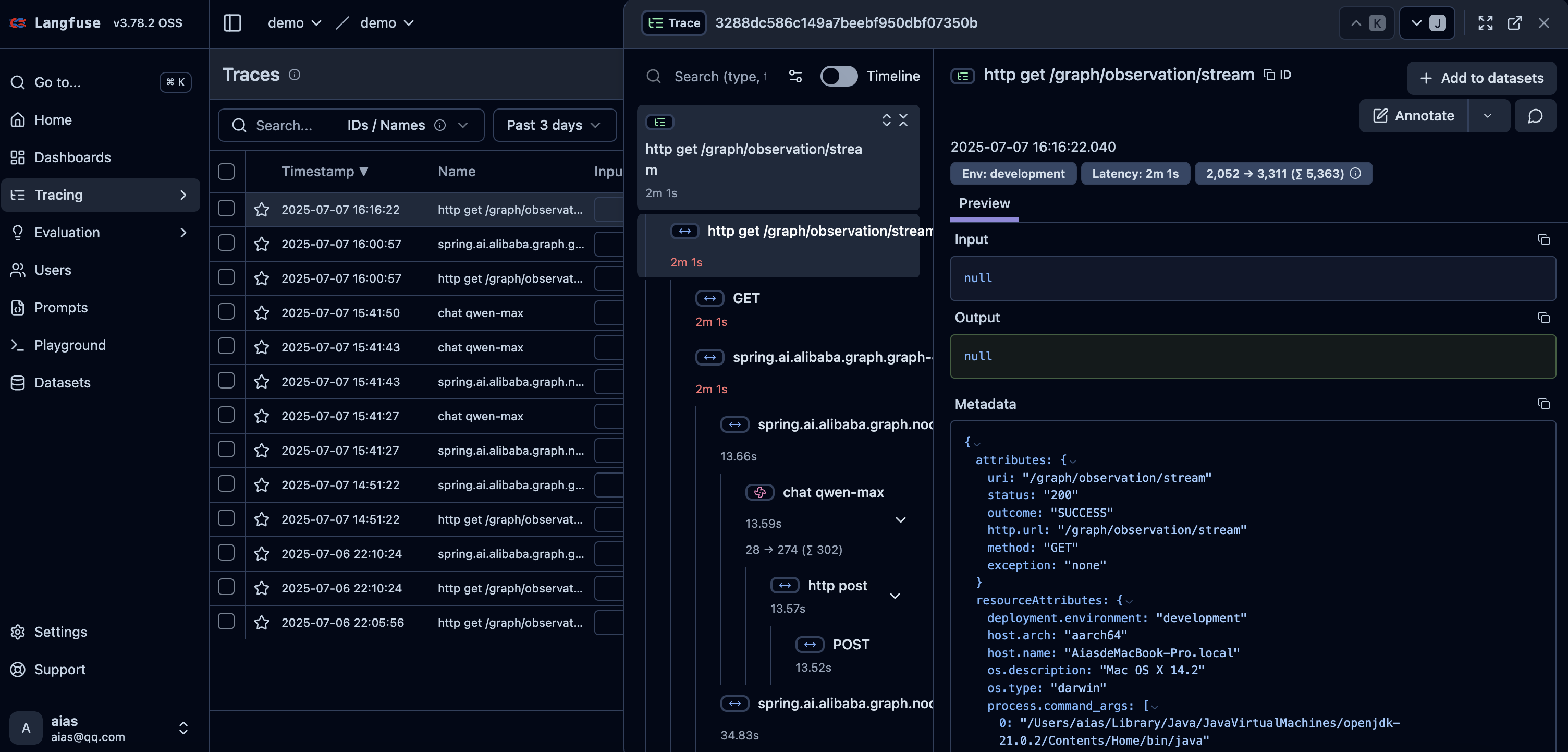
6.可视化平台与数据展示
可视化是Spring AI Alibaba Graph观测性的核心组成部分,它将复杂的执行数据转化为直观的图表和时序图,帮助开发者:
- 快速定位问题:通过可视化的执行链路,快速识别异常节点和性能瓶颈
- 优化性能:观察各节点的耗时分布,识别可优化的环节
- 成本管控:监控Token使用量和API调用成本
- 质量保证:追踪输入输出数据的质量和一致性
- 架构决策:基于真实执行数据优化Graph架构设计
6.1 支持的可视化平台
得益于基于OpenTelemetry和Brave的标准化设计,Spring AI Alibaba Graph观测性具备强大的平台扩展能力,以下选取一些较为常见的观测可视化平台给予示例:
6.1.1 AI专用观测平台
Langfuse
- 专为AI应用设计,内置LLM成本计算和Token统计
- 支持提示工程优化和A/B测试
- 通过OTel协议无缝集成
- 开源便于维护和本地部署
LangSmith
- LangChain官方推出的AI应用观测平台
- 提供强大的调试和性能分析功能
- 支持提示链优化和实验管理
- 通过OpenTelemetry协议接入
# LangSmith配置示例
otel:exporter:otlp:endpoint: "https://api.smith.langchain.com/api/v1/otlp"headers:Authorization: "Bearer ${LANGSMITH_API_KEY}"
6.1.2 通用APM平台(通过OTel/Brave协议)
Jaeger
# 方式1: 通过OpenTelemetry
otel:traces:exporter: jaegerexporter:jaeger:endpoint: "http://jaeger:14268/api/traces"# 方式2: 通过Brave
spring:sleuth:jaeger:http:sender:endpoint: "http://jaeger:14268/api/traces"
Zipkin
# 方式1: 通过Brave(推荐)
spring:sleuth:zipkin:base-url: "http://zipkin:9411"# 方式2: 通过OpenTelemetry
otel:traces:exporter: zipkinexporter:zipkin:endpoint: "http://zipkin:9411/api/v2/spans"
6.1.3 自建监控系统
Prometheus + Grafana(通过Micrometer)
management:metrics:export:prometheus:enabled: true
6.1.4 多平台集成
# 同时支持多个观测平台的配置示例
spring:sleuth:zipkin:base-url: "http://zipkin:9411" # Brave协议 - 本地调试otel:exporter:otlp:endpoint: "https://cloud.langfuse.com/api/public/otel" # OTel协议 - AI专用分析headers:Authorization: "Basic ${LANGFUSE_CREDENTIALS}"management:metrics:export:prometheus:enabled: true # Micrometer协议 - 指标监控# 环境变量设置
# REGION_ID=cn-hangzhou
# WORKSPACE_ID=your_arms_workspace_id
# LANGFUSE_CREDENTIALS=your_base64_encoded_credentials
6.2 Langfuse可视化集成配置及效果展示
6.2.1 LangFuse配置
要集成LangFuse,您需要按照4.1.2节中步骤配置pom.xml依赖以及application.yml。完成后,您有两种方式接入。
方式一:使用Langfuse云服务
- 访问 https://cloud.langfuse.com 注册账户
- 创建新项目
- 获取API密钥对(公钥和私钥)
- 生成Base64编码的认证信息:
# Linux/Mac
echo -n "public_key:secret_key" | base64# Windows PowerShell
[System.Convert]::ToBase64String([System.Text.Encoding]::UTF8.GetBytes("public_key:secret_key"))
接着将生成的密钥填入application.yml对应位置即可:
# LangFuse密钥配置,将${YOUR_BASE64_ENCODED_CREDENTIALS}替换为您生成的base64密钥
otel:exporter:otlp:headers:Authorization: "Basic ${YOUR_BASE64_ENCODED_CREDENTIALS}"
方式二:自托管Langfuse
# 使用Docker部署
docker run -d \--name langfuse \-p 3000:3000 \-e DATABASE_URL=postgresql://user:pass@localhost:5432/langfuse \langfuse/langfuse:latest
6.2.2 LangFuse可视化效果
6.2.2.1 Graph执行的Trace追踪
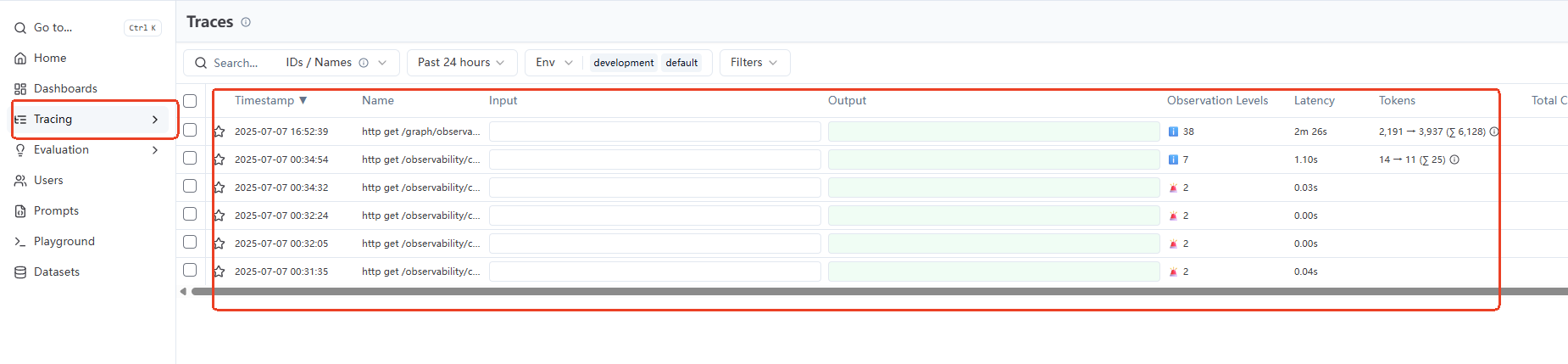
您可以在LangFuze的左侧面版中单击Trace,即可看到每一次调用的Trace列表,包含了每次调用用时、使用模型Token等信息:
单击列表中单次Trace,即可看到详细Trace信息。如下图所示,左侧可以看到完整的调用Span,包括http/graph/node/chat client级别的调用级别和信息;右侧包含了观测Span中的各种Atrributes。
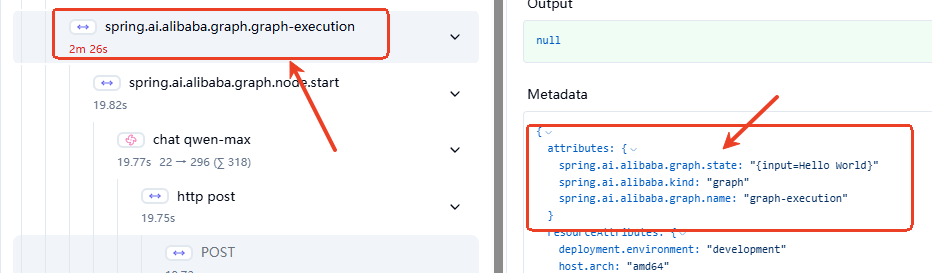
6.2.2.2 Graph级别观测
如图可见,Graph级别的观测包含了Graph名称、状态的信息,同时还可以看到图执行全程用时。
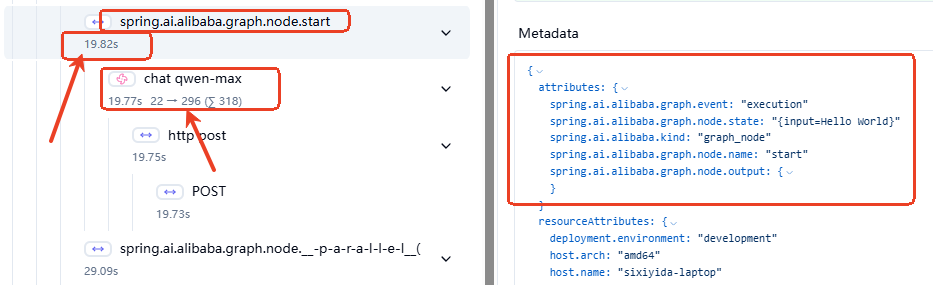
6.2.2.3 Node级别的观测
如图可见,Node级别的观测包含了Node名称,Node执行时长,包括调用模型的时长和使用的Token数量等。
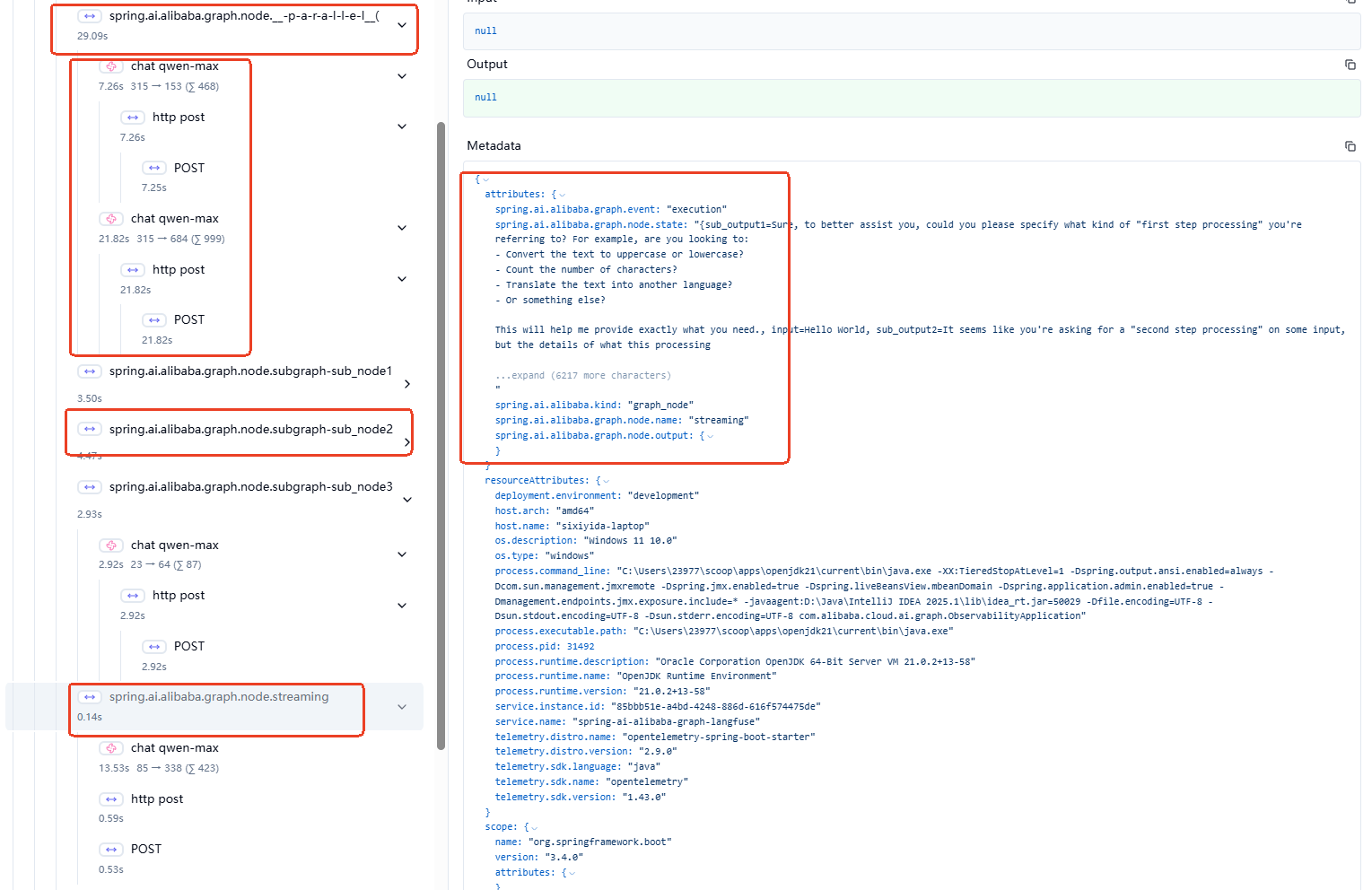
对于并行节点/子图节点/流式透传节点,Graph观测也都是支持的:
6.2.2.4 Graph执行时序
如图,在右上角打开Timeline开关,即可看到整个Graph的执行时序图:
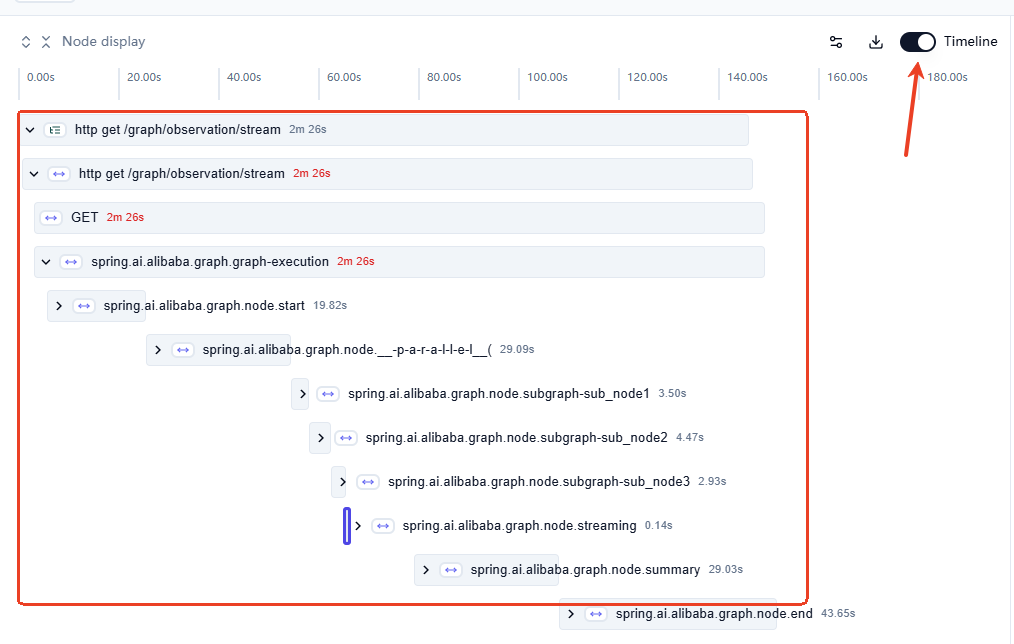
6.2.2.5 Graph调用LLM相关数据图表
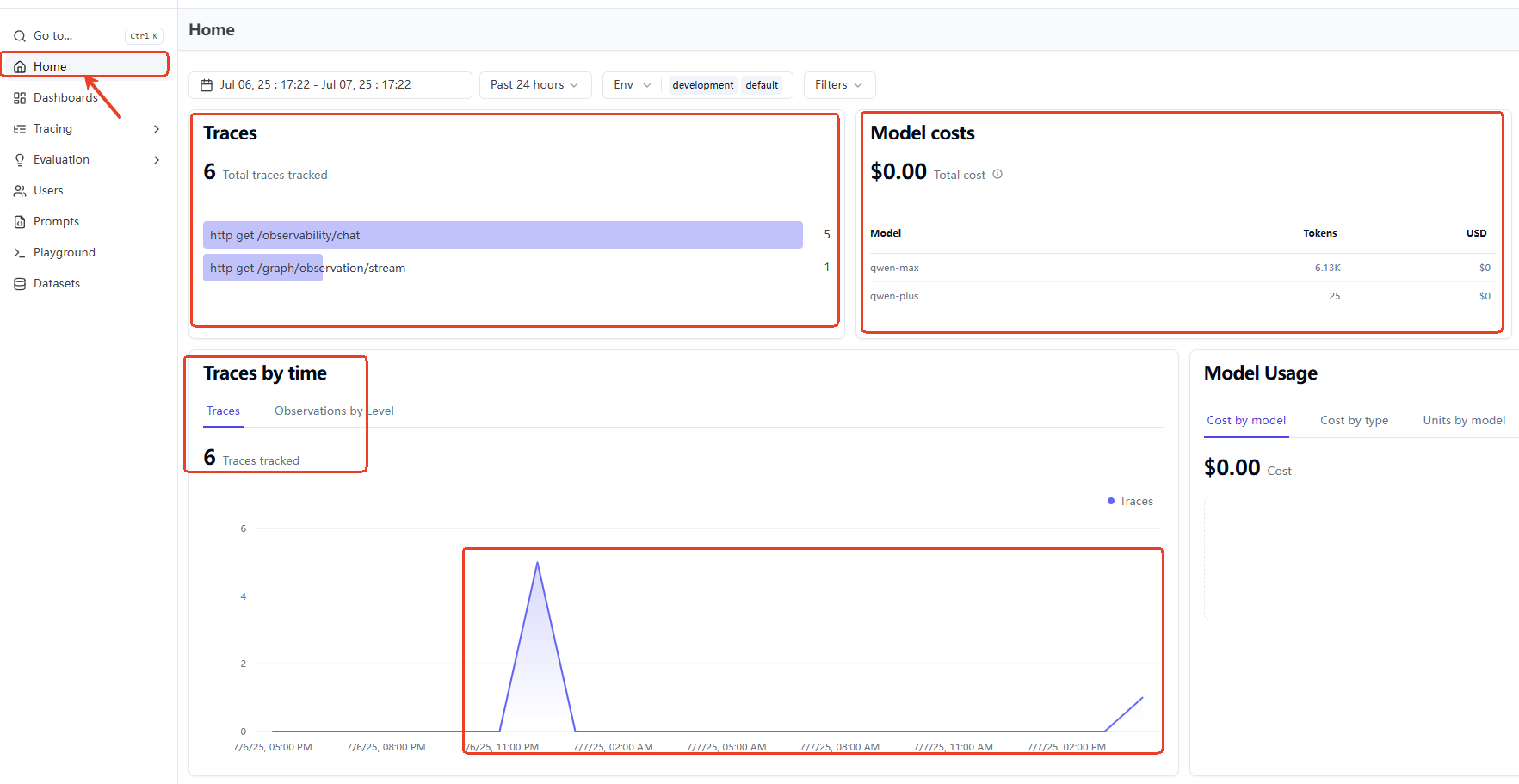
在LangFuse的Home栏下,可以看到一定时间范围内调用LLM的相关数据和图表,包括Trace的统计,LLM Tokens用量和花销等:
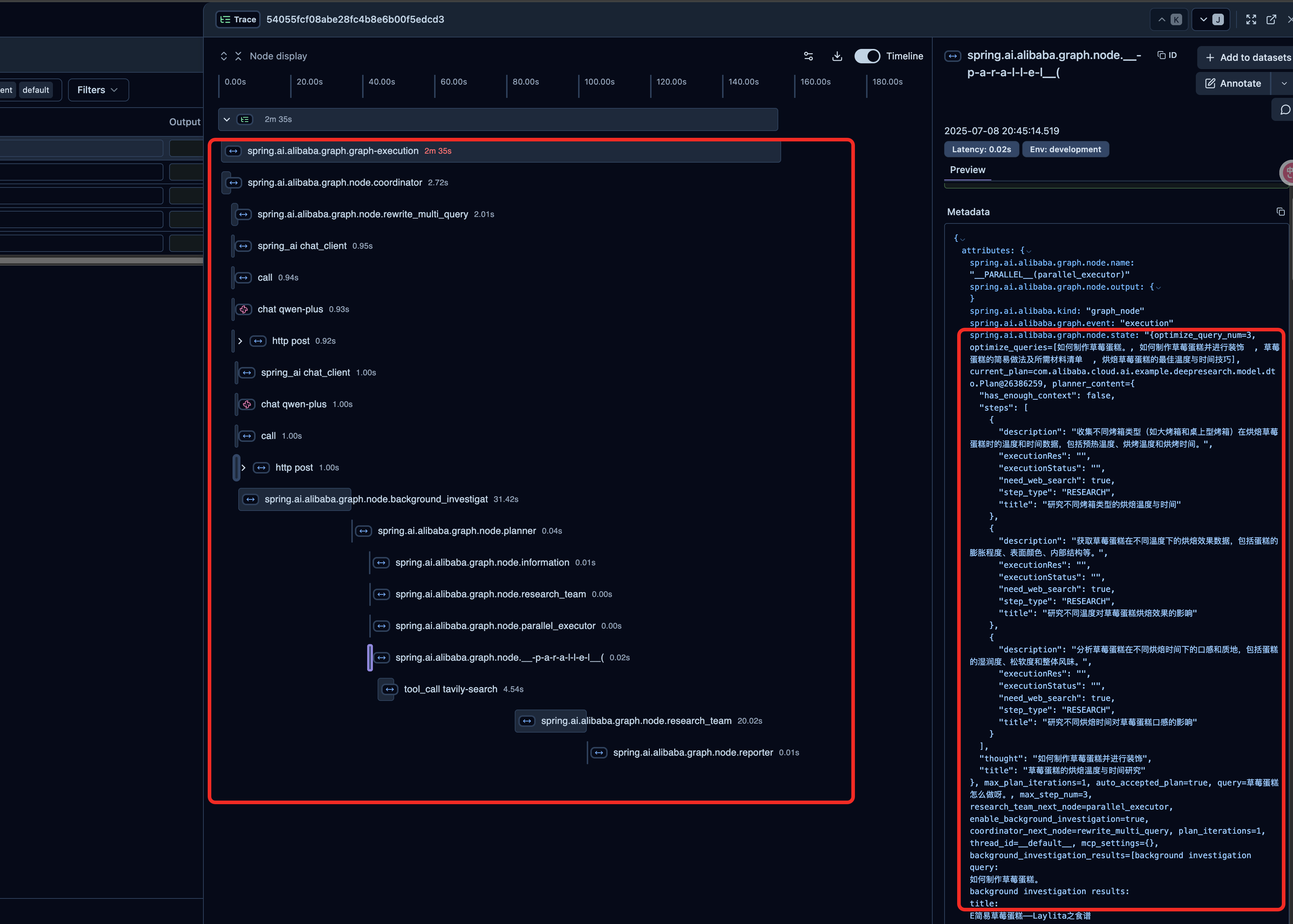
6.2.2.6 社区复杂场景落地案例:DeepResearch
支持查看每个关键节点的执行时序、输入和输出内容,便于后续进行提示词优化和项目架构调试。
7.最佳实践与扩展建议
7.1 唯一key与数据隔离
- 每个节点输出的key尽量唯一,避免数据覆盖和混淆。
- 推荐为每个节点设计专属key,如baidu_result、tavily_result、llm_result等。
7.2 流式观测优先
- 优先使用AsyncGenerator等流式返回,提升观测实时性和用户体验。
- 并行节点输出需通过工具类合并,保证下游节点能完整观测所有上游结果。
7.3 观测链路的可视化与调试
- 建议在开发和调试阶段,输出每个节点的输入、输出和元数据,便于全链路追踪。
- 可结合日志、监控等手段,进一步提升观测能力。