Python中常用标准库(时间库、随机库、正则表达式)
一、标准库
1.什么是标准库:
标准库是python自带的库,无需下载,可以直接使用。
可以·通过以下代码(import)获取:
import sys
print(sys.exec_prefix) #获取python的安装路径
2.标准库的导入方式
#标准库的导入方式
使#用保留字 from 和 import 导入相应标准库
import time
from time import sleep #从time库中导入sleep()函数
from time import * #全部导入
导入库时,python内部设置了3个优先搜索路径
例如 import water
1.在当前代码目录下搜索
2.搜素python安装路径下lib目录下是否有该库
3.在lib目录中的site-package目录中寻找
二、常用的标准库
1.时间库
a.获取时间戳:
时间戳:当前时间与1970年1月1日0时0分0秒的时间差
代码:
import time #导入时间库
a = time.time() #time()时间戳
print(a) 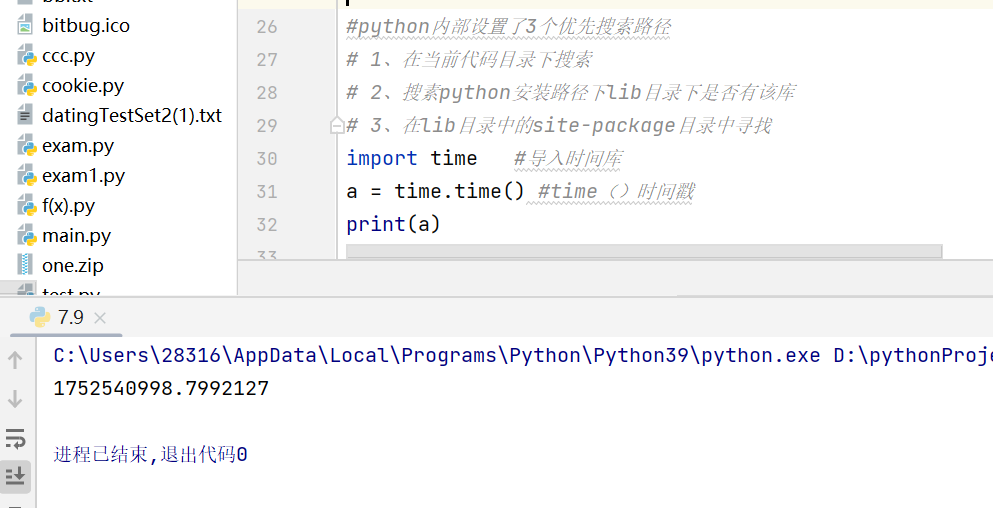
time()不仅可以检测程序代码在何时被执行,还可以测量程序的运行速度
可以判断程序是否优良
判断程序优良一般从两个方面,通过方运行的稳定性和 速度
import time
strat = time.time() #开始时间
i = 1
while i<100000000: #该循环执行100000000i+=1print(i)
end = time.time() #结束时间
print("开始时间:",strat,"结束时间:",end,"用时: ",end-strat) #执行100000000次所需要的时间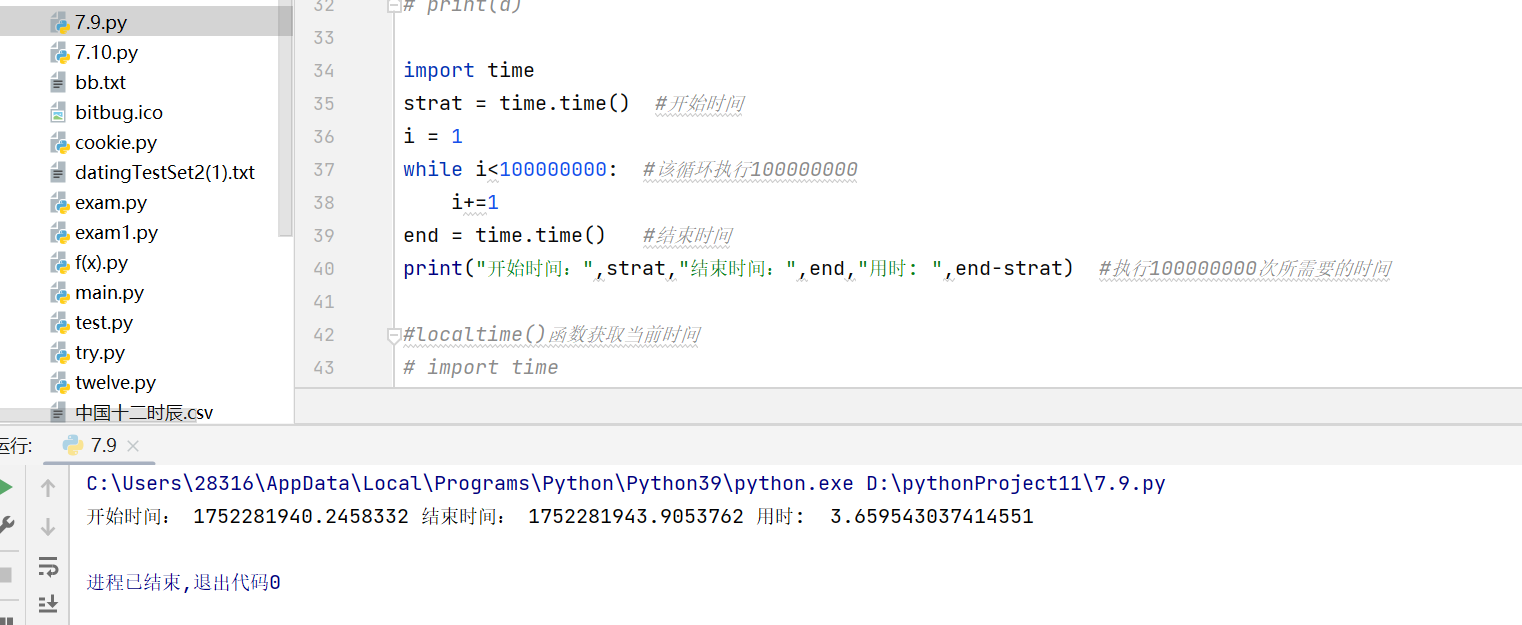
b.获取时间:
- localtime()函数
功能:获取本地时间。
使用形式:localtime(second=None)
参数second:为None时表示获取当前时间
为时间戳值表示将时间戳seconds转换为本地当前时间
返回值:该函数返回值为struck_time数据对象。struct_time数据对象是python的内置函数,其形式类似于元组,具体可见代码输出结果。
示例代码:
#localtime()函数获取当前时间
import time
a=time.localtime()
print(list(a))
print(a) #struct_time
- gmtime()函数
gmtime()函数用于获取UTC(世界协调时,又称世界标准时间,与中国时间相差8个小时)时间 。
使用形式
def gmtime(seconds=None)
参数seconds :值可以为None或时间戳值。如果为None表示获取当前UTC时区的时间,如果为时间戳表示将时间戳转换为UTC时区(0时区)的时间。
返回值:struct_time数据对象
示例代码:(与上面的区别就是时区不一样)
import time
a = time.gmtime() #
print(a)

- ctime()函数
ctime()函数用于获取字符串形式的时间。
#ctime()
import time
a = time.ctime() #字符串形式的时间值
print(a)
此表达式为外国人常常使用,顺序依次为:星期、月份、日期、小时(后加冒号)、分钟(后加冒号)、秒、年份
b.时间格式转换
- mktime()函数
mktime()函数用于将struct_time对象变量转化为时间戳。
使用形式如下:
mktime(p_tuple)
参数p_tuple:为struct_time对象,参数必须给出,否则会抛出错误。
示例代码:
import timeprint(time.localtime()) #获取时间戳print(time.mktime(time.localtime()))

- strftime()函数
strftime()函数用于将struct_time对象变量转换为格式化的字符串(与字符串的format()方法类似)。
其使用形式如下:
strftime(format,p_tuple=None)
参数format:根据format格式定义输出时间。
| 格式符 | 含义描述 | 示例(以 2024-07-23 15:30:45 周二为例) |
|---|---|---|
| %Y | 4 位年份 | 2024 |
| %y | 2 位年份(00-99) | 24 |
| %m | 2 位月份(01-12) | 07 |
| %B | 完整的月份名称(本地化) | July(英文)、七月(中文) |
| %b | 缩写的月份名称(本地化) | Jul(英文)、七(中文) |
| %d | 2 位日期(01-31) | 23 |
| %A | 完整的星期名称(本地化) | Tuesday(英文)、星期二(中文) |
| %a | 缩写的星期名称(本地化) | Tue(英文)、周二(中文) |
| %H | 24 小时制的小时(00-23) | 15 |
| %I | 12 小时制的小时(01-12) | 03 |
| %M | 2 位分钟(00-59) | 30 |
| %S | 2 位秒数(00-59) | 45 |
| %p | 上下午标识(本地化,AM/PM 或上午 / 下午) | PM(英文)、下午(中文) |
| %w | 星期几(0-6,0 代表周日) | 2(周二) |
| %j | 年内的第几天(001-366) | 205 |
| %U | 年内的第几个星期(00-53,以周日为一周的第一天) | 29 |
| %W | 年内的第几个星期(00-53,以周一为一周的第一天) | 29 |
| %x | 本地化的日期表示 | 07/23/24(英文)、2024/7/23(中文) |
| %X | 本地化的时间表示 | 15:30:45(英文)、15:30:45(中文) |
| %c | 本地化的日期和时间表示 | Tue Jul 23 15:30:45 2024(英文)、2024 年 7 月 23 日 15:30:45(中文) |
| %% | 百分号本身 | % |
示例代码:
import time
a = time.localtime()
b = time.strftime('%Y-%m-%d-%H:%M:%S',a)
print(a,'\n',b)
- strptime()函数
strptime()函数用于把一个格式化时间字符串转化为struct_time数据对象(与strftime()互为逆操作)
使用形式如下:
strptime(string,format)
参数string:为字符串,与strftime()函数输出的字符串相同,例如‘2021-09-30-12:36:19’
参数format:生成参数string时所需的格式,与strftime()函数中的format参数相同
示例代码:
import time
a = time.strptime('2021-09-30','%Y-%m-%d')
print(a)
- time.sleep (参数)
时间休眠,让代码等待一段时间,参数为程序休眠的时长,值可以为小数或整数,单位为秒。
示例代码:
import time
print('开始')
time.sleep(10)
print('此消息10秒后输出')2.随即库
a.随机生产数字
unifor()方法:
uniform(参数1,参数2)方法用于生成参数1和参数2之间的随机小数,其中参数的类型都为数值类型。
示例代码:
import random
a = random.uniform(1,5)
print(a)

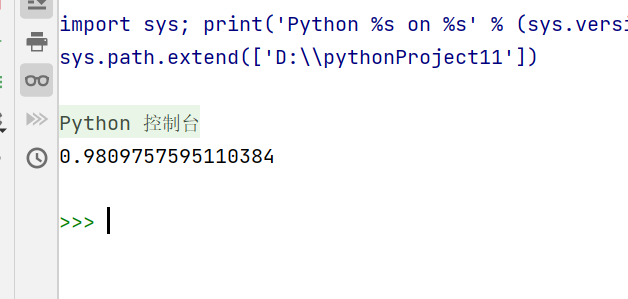
random()方法
random()方法用于生成0-1(不包含1)的随机小数,无需填入参数
示例代码:
import random
a = random.random()
print(a)
randint(参数1,参数2)方法
用于生成参数1到参数2之间的整数
示例代码:
import random
a = random.randint(3,8)
print(a)
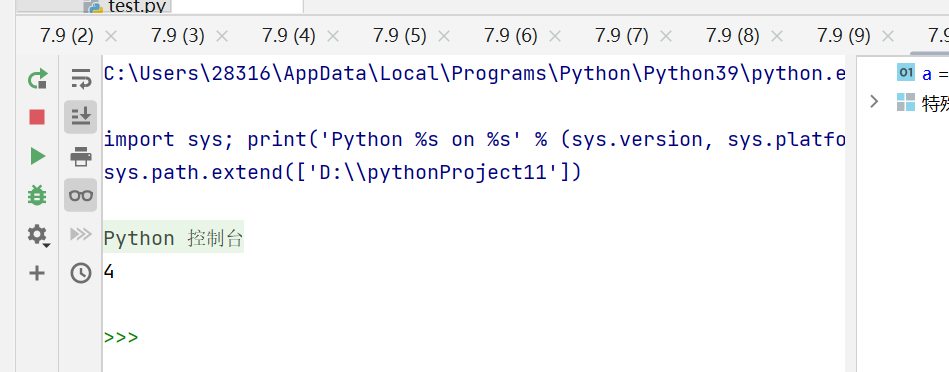
randrange(参数1,参数2,参数3)方法
randrange()方法用于生成在参数1和参数2之间步长为参数3的随机整数
示例代码:
import random
a = random.randrange(0,20,5)
print(a)会在(0、5、10、15)中随机选取一个数值,执行代码后的输出结果为15
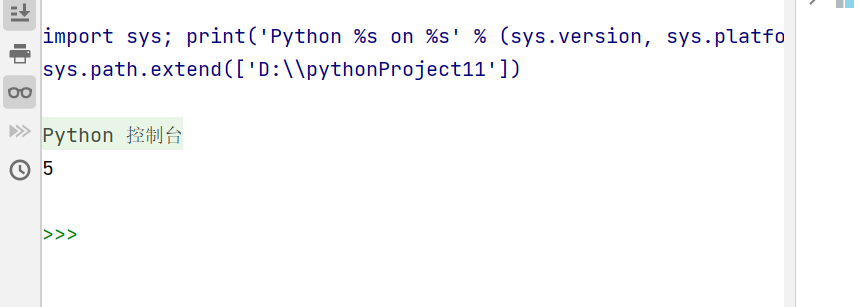
b.随机选择
choice()函数:
choice(参数)从参数中随机选择一个元素,参数通常是序列类型(可以通过索引方式获取元素)数据,例如列表、字符串。
示例代码:
import random
ls = ['一等奖','二等奖','三等奖','谢谢惠顾']
a = random.sample(ls,2) #随机选择两个元素
print(a)
拓展:随机种子 seed(种子)
示例代码:
# 随机种子
# seed(种子)
import random
ls = ['一等奖','二等奖','三等奖','谢谢惠顾']
random.seed(100) #种下种子后种下说明发什么芽
print((random.choice(ls))) #随机从ls中选择一个数据
random.seed(88) #一旦有了结果这个芽不会变
print(random.choice(ls))
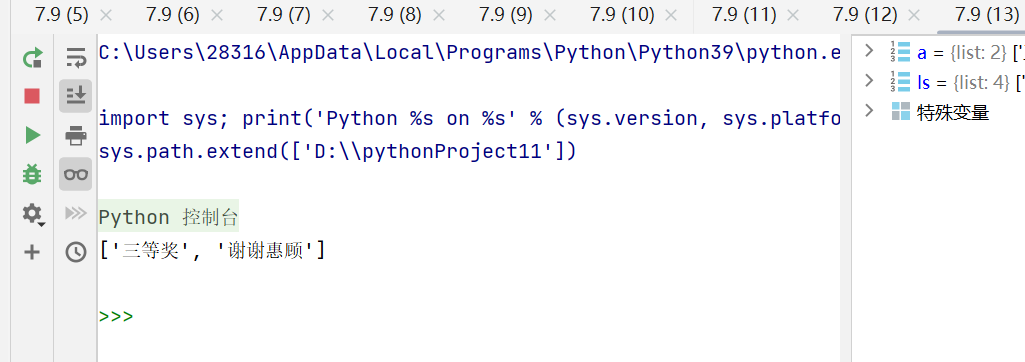
shuffle()函数
shuffle(参数)将参数中的元素打乱,参数是序列类型数据
示例代码:
import random
ls = ['一等奖','二等奖','三等奖','谢谢惠顾']
random.shuffle(ls)
print(ls)
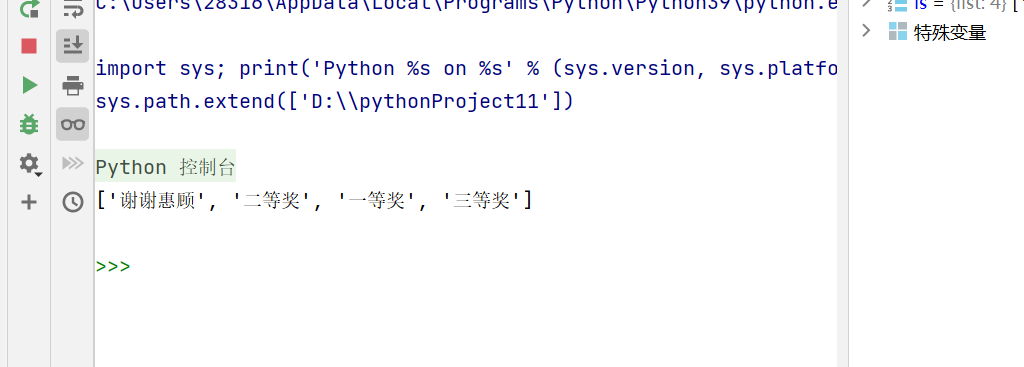
sample()函数 :
sample(参数1,参数2)从参数中随机选取2个元素,参数1为序列类型数据,参数2为整数
从参数1中选取参数2个元素。
示例代码:
import random
ls = ['一等奖','二等奖','三等奖','谢谢惠顾']
a = random.sample(ls,2)
print(a) 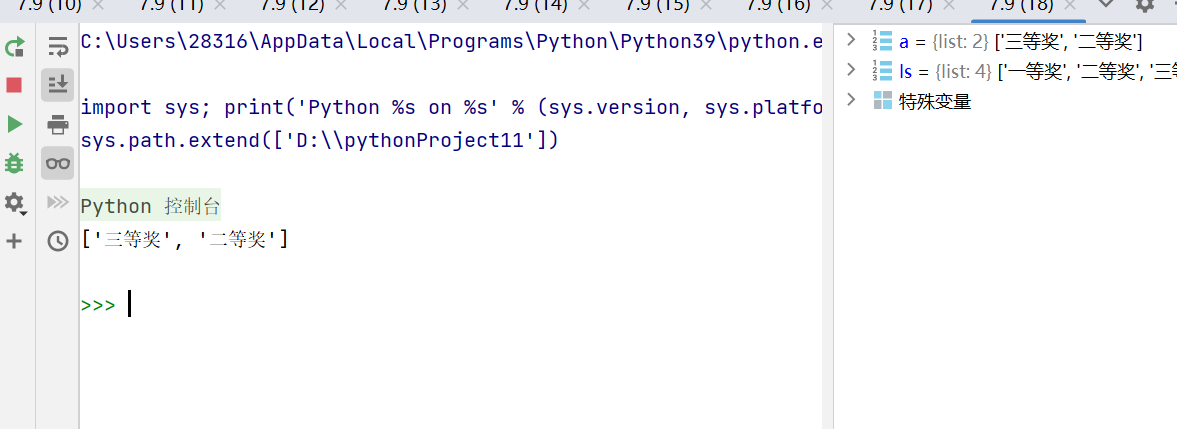
三、正则表达式
1.匹配字符串
匹配字符串表示从字符串中筛选出满足条件的信息,这里的条件要使用一种特殊的表达式即正则表达式。
- match()函数
match(参数1,参数2)
从参数2中找出满足参数1(正则表达式)的内容,如果参数2起始位置匹配不成功返回none;如果起始位置匹配成功,就返回匹配的内容。
示例代码:
# 正则表达式
# match(参数1,参数2) 功能:参数2 中查找满足参数1(正则表达式)的内容
import re
message = 'zs、l、w、z'
result = re.match('s',message) #起始位置找不到就找不到,开头就要匹配上
print(result) #span表明匹配的位置 起始位置匹配不成功: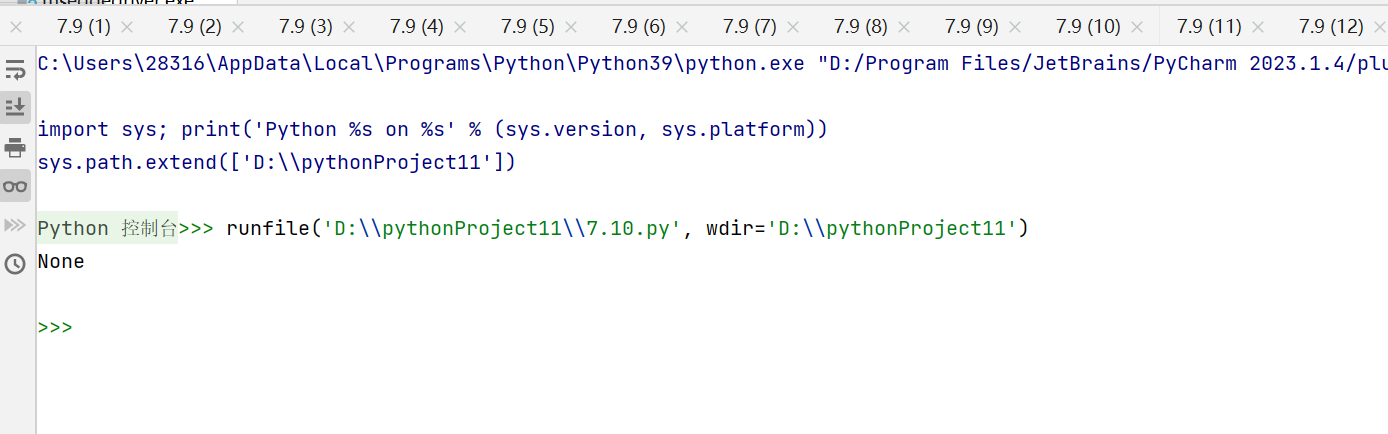
匹配成功
import re
message = '张三、李四、王二、赵六'
result = re.match('张三',message) #起始位置找不到就找不到,开头就要匹配上
print(result) #span表明匹配的位置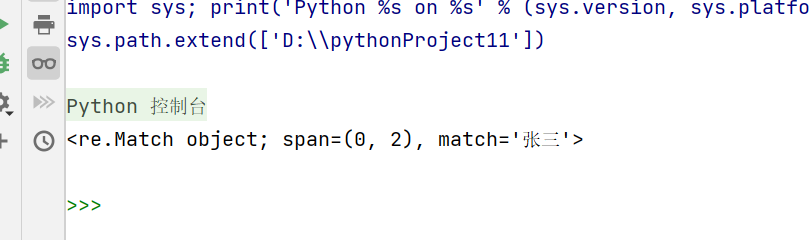
- search()函数
search(参数1,参数2)
表示从参数2中查找满足参数1(正则表达式)的内容,如果匹配了多个参数1,则只返回第1个匹配成功的信息
示例代码:
import re
message = '张三,李四,王五,赵六,王五'
result = re.search('五',message)
print(result) 只返回第一个“五”
- findall()函数
findall()函数的使用形式如下:
findall(参数1,参数2)
表示从参数2中查找满足参数1(正则表达式)的内容,如果匹配了多个参数1,则返回匹配成功的全部信息。
示例代码:
import re
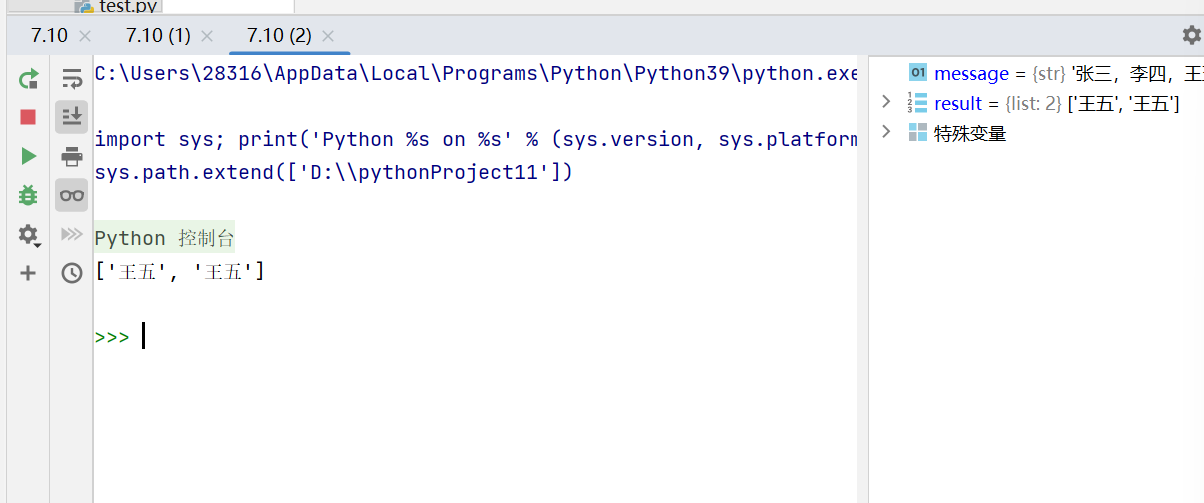
message = '张三,李四,王五,赵六,王五'
result = re.findall('王五',message)
print(result)
2.正则表达式
- 表示字符范围
[xyz]:字符集合,匹配中括号包含的任意一个字符
[a-z]:字符范围 ,匹配指定范围内的任意字符。
示例代码:
import re
message = 'Python93,C87,Java63,C++88'
result_1 = re.search('[cn]',message)
result_2 = re.findall('[0-9]',message)
result_3 = re.findall('[a-z][0-9][0-9]',message)
print(result_1,result_2,result_3)

- 匹配字符出现的次数
| 元字符 | 含义描述 | 示例 | 匹配说明 |
|---|---|---|---|
* | 匹配前面的字符或子模式 0 次或多次(尽可能多匹配) | a* | 匹配 "","a","aa","aaa" 等 |
+ | 匹配前面的字符或子模式 1 次或多次(尽可能多匹配) | a+ | 匹配 "a", "aa", "aaa" 等(不匹配空) |
? | 匹配前面的字符或子模式 0 次或 1 次 | a? | 仅匹配 ""或"a" |
{n} | 精确匹配前面的字符或子模式 n 次(n 为非负整数) | a{3} | 仅匹配 "aaa" |
{n,} | 匹配前面的字符或子模式 至少 n 次 | a{2,} | 匹配 "aa", "aaa", "aaaa" 等 |
{n,m} | 匹配前面的字符或子模式 至少 n 次,最多 m 次(n≤m) | a{2,4} | 匹配 "aa", "aaa", "aaaa" |
^ | 匹配字符串的开始位置 | ^a | 匹配以 "a" 开头的字符串(如 "apple" 中的 "a") |
$ | 匹配字符串的结束位置 | b$ | 匹配以 "b" 结尾的字符串(如 "bob" 中的最后一个 "b") |
*:匹配前面的子表达式任意次
import re
message = 'da2a7ddre77yifed77t3fefd777b'
result = re.findall('[a-z]*[0-9][a-z]',message)
print(result)
+:匹配前面的子表达式一次或多次
import re
message = 'da2a7ddre77yifed77t3fefd777b'
result = re.findall('[a-z]+[0-9][a-z]',message) #+前面表达式要表达多次,数字前面必须带有字母
print(result)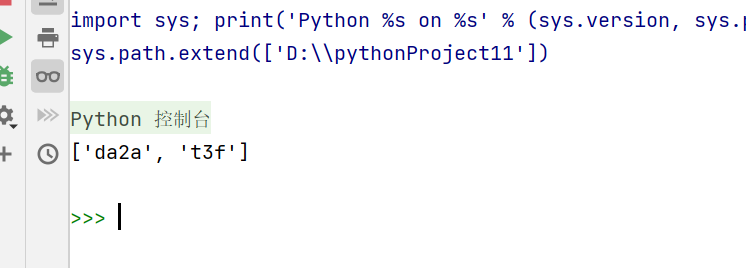
?:匹配前面的子表达式零次或多次
import re
message = 'da2a7ddre77yifed77t3fefd777b'
result = re.findall('[a-z]?[0-9][a-z]',message) #+前面表达式要表达多次,数字前面必须带有字母
print(result) 
^:匹配输入行首
$:匹配输入行尾
示例代码(输入手机号):
{}:代表匹配10次一个12位的手机号
^1:表示第一个数字只能为1
import re
phone_num = input("shoujihao:")
result = re.findall('^1[0-9]{10}$',phone_num)
print(result)

3.表示同一类字符
\d:匹配数字,等价于[0-9]。\D:匹配非数字,等价于[^0-9]。\w:匹配单词字符(字母、数字、下划线),等价于[a-zA-Z0-9_]。\W:匹配非单词字符,等价于[^a-zA-Z0-9_]。\s:匹配空白字符(空格、制表符、换行等)。\S:匹配非空白字符- \B:匹配非单词边界。例如:“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”,因为“er”是“never”的单词边界
- .:匹配除"\n"和"\r"之外的任何单个字符(.)
示例代码:
^[A-Za-z_]:输入用户名:开头是字母
\w{7,}:后续字符可以是任意单词字符(字母、数字、下划线),且至少要有 7 个字符(加上第一个字符,总长度至少为 8)。
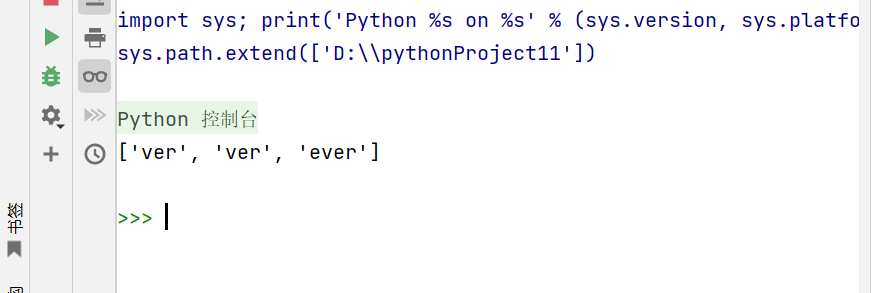
import re
use_name = input("输入用户名:")
result = re.findall('^[A-Za-z_]\w{7,}$',use_name)
print(result)匹配非单词边界:
import re
message = "verb very never every"
result = re.findall(r'\w+er\B',message)
print(result)
.:匹配除了“\n”和“\r”之外的任何单个字符:
import re
message = "verb very never every"
result = re.findall('.e',message)
print(result)4.贪婪模式和非贪婪模式
贪婪模式:贪婪模式是正则表达式的默认匹配行为,它会尽可能多地匹配字符。
非贪婪模式:非贪婪模式(也称为懒惰模式)会尽可能少地匹配字符,在量词后加上?即可启用非贪婪模式。
贪婪模式:
ccc:匹配前三个c
/d:匹配一个数字字符
+:匹配一次或多次
import re
message= 'ccc74679955436hd'
result = re.findall('ccc\d+',message)
print(result)
非贪婪模式:加上:?
一旦满足不在匹配
import re
message= 'ccc74679955436hd'
result = re.findall('ccc\d+?',message)
print(result)

5.或和组
- 或操作
正则表达式中的|符号表示"或"逻辑,用于匹配多个模式中的任意一个。
示例代码:
import retext = "我喜欢苹果和香蕉"
pattern = r"苹果|香蕉"
result = re.findall(pattern, text)
print(result) # 输出: ['苹果', '香蕉']注:
|的优先级很低,通常需要使用分组来限定范围- 会按照从左到右的顺序尝试匹配
- 分组
分组是正则表达式中非常重要的功能,使用圆括号()实现。
示例代码:
import re
pattern = r"(ab)+"
text = "ababab"
result = re.fullmatch(pattern, text)
print(result.group()) # 输出: ababab