【建模与仿真】融合共现网络特征与知识增强语义梯度提升电子邮件分类
导读:
本文针对现有电子邮件分类算法缺乏知识网络特征,并且训练复杂度较高的问题,应用复杂网络理论和知识增强语义模型,设计了一种基于电子邮件知识共现网络特征和知识增强语义的梯度提升算法,研究如何利用电子邮件知识网络和增强深度学习模型的知识表征来提升分类算法性能。在实验中,相较于现在的领先模型,本文算法在准确率、精确率和召回率等指标上均有明显提升,验证了其有效性,揭示了电子邮件知识网络特征能够有效增强现有模型的性能,提供了对其表征能力的有效补充。
作者信息:
艾 均, 邹智洋*, 苏 湛*, 耿爱国, 马菀言:上海理工大学光电信息与计算机工程学院,上海
正文
本文研究了一种基于共现网络特征与知识增强语义的梯度提升电子邮件分类算法,做出了如下贡献:
1) 设计了一种基于共现度计算的电子邮件知识复杂网络构建算法,表征了电子邮件内容的知识网络关系和特征。
2) 基于构建的电子邮件知识复杂网络结构,设计方法提取电子邮件关键信息。
3) 融合ERNIE预训练模型,将电子邮件知识网络的关键信息和ERNIE表征的文本特征结合并设计模型进一步对文本分类任务学习和训练,并设计了对应的电子邮件分类方法。
本文提出的基于电子邮件知识共现网络特征和知识增强语义的梯度提升分类算法(Gradient Boosting Email Classification Algorithm Based on Co-occurrence Network Features and Knowledge-Enhanced Semantics, GBECKS)能够将电子邮件分类为正常类、骚扰类、可疑类和欺诈类。本文算法的框架如图1所示,包含数据预处理模块、复杂网络构建模块、特征提取模块、模型训练和预测模块,然后每个模块的具体实现的功能和目标如下:
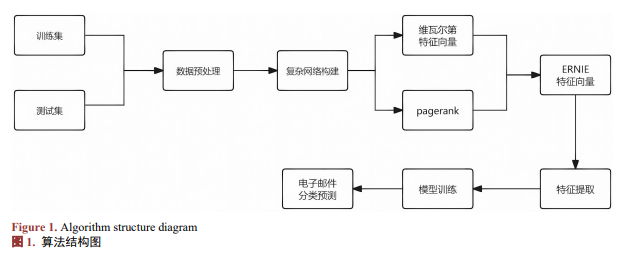
数据预处理是电子邮件分类过程中至关重要的步骤,具体过程详见算法1:

为了构建电子邮件领域的知识网络,本文设计了一种共现度计算方法(算法2),用于衡量词元在电子邮件中的分布情况。

对于复杂网络中的每个词元节点,本文使用Vivaldi算法将其映射到一个高维虚拟空间中,以生成对应的词元向量坐标V(ωi) 。向量的维度为N×M ,其中N 表示电子邮件的总数,M 表示单条电子邮件的向量维度。
给定一个复杂网络G(V,E) ,其中V 表示词元节点集合,E 表示词元节点之间的共现边。对于任意词元节点ωi ,使用Vivaldi算法将其映射到高维空间中的坐标向量V(ωi) 。该过程如公式(6)所示:
![]()
其中,vivaldi表示维瓦尔第算法的映射函数,它基于词元节点在复杂网络中的相对位置来确定其高维空间坐标,映射得到的向量V(ωi) 的维度为N×M ,即V(ωi)RN×M ,其中N 是电子邮件的总数,即整个训练集中包含的电子邮件数。M 是每条电子邮件在向量空间中的表示维度,具体算法流程如算法3所示。
算法4基于电子邮件知识共现网络特征和知识增强语义的梯度提升分类算法的训练过程。

本文选取了4种流行的文本分类模型作为对比实验:
1) 双向长短期记忆网络 (Bidirectional Long Short-Term Memory):该算法通过BiLSTM对邮件的文本内容进行编码,捕捉到文本中单词的上下文信息。将得到的特征表示通过全连接层进行处理,最终通过softmax函数进行分类。
2) 层次化注意力网络(Hierarchical Attention Network):该算法通过分层的方式处理文本内容。首先,HAN处理单个句子中的单词,生成每个句子的表示。接着,通过句子级别的BiLSTM捕捉句子间的上下文关系,并使用注意力机制选择出重要的句子和单词,形成邮件的整体表示。最终利用这些表示进行分类。
3) 双向编码器表示模型(Bidirectional Encoder Representations from Transformers):该算法首先将邮件的文本输入到其双向Transformer编码器中,生成每个词汇的上下文表示。然后,通过一个特殊的分类标记[CLS]对整个邮件进行表示,并利用这个表示进行分类。
4) 知识增强语义模型(Enhanced Representation through Knowledge Integration):该算法中邮件内容首先被编码成词汇表示,并与相关的知识图谱进行整合,生成更具语义信息的表示。随后,通过分类层对邮件进行分类。
实验结果如表2所示:
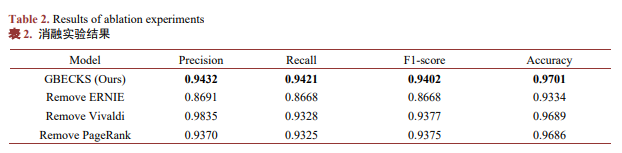
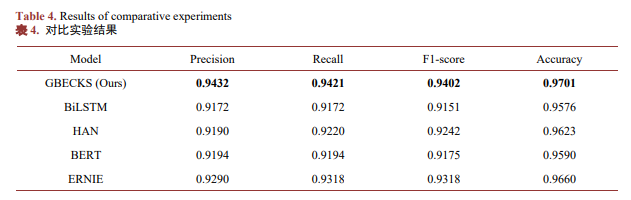
本文通过词汇共现度构建电子邮件知识网络,并提取Vivaldi空间特征和网络中心性特征,结合ERNIE模型的语义特征,在较少的训练成本和训练时间内实现了更加良好的电子邮件分类。实验结果表明,本文提出的GBECKS算法在分类性能上显著优于其他主流算法(表4),同时训练时间和成本也明显低于其他主流算法。
结论
通过统计电子邮件的共现度,构建了基于电子邮件知识的共现网络,并利用Vivaldi算法将这些特征映射到虚拟空间中进行表示。随后,算法将Vivaldi特征、电子邮件网络的中心性特征与ERNIE的语义特征结合,生成电子邮件特征向量,并通过梯度提升模型XGBoost进行分类。
实验结果表明,本文提出的算法在各项指标上均优于ERNIE、BERT、HAN和BiLSTM模型。此结果证明了本文设计的GBECKS算法不仅在准确性上具有显著优势,同时也具备较低的计算复杂度,是一种高效且精确的电子邮件分类方法。
基金项目:
国家自然科学基金项目(61803264)
获取原文请点击原文链接:融合共现网络特征与知识增强语义梯度提升电子邮件分类