HTML应用指南:利用GET请求获取全国奈雪的茶门店位置信息
奈雪的茶作为一家以新式茶饮为主打的连锁品牌,自2015年成立以来,凭借其“茶+软欧包”的创新组合模式,迅速在中国市场崭露头角。品牌坚持“高颜值、高品质、高体验”的产品理念,选用优质茶叶、新鲜水果和乳制品,致力于为消费者提供健康、时尚、有品位的茶饮体验。奈雪的茶不仅注重产品品质,也强调门店环境的舒适与品牌文化的传递,营造出一种年轻、潮流、都市化的消费氛围。
本文将探讨如何利用GET请求从官方网站或公开接口中获取奈雪的茶的门店分布信息,并展示使用Python的requests库发送GET请求的方法,以提取详细的门店位置数据。这些信息覆盖全国范围内的所有奈雪的茶门店,并通过解析JSON格式的数据或HTML页面来处理响应内容。这种数据采集方式有助于我们更深入地了解奈雪的茶在不同地区的市场布局策略、门店密度分布及其与消费人群之间的关系。通过结构化整理门店数据,还可以为后续的可视化分析、商圈研究以及品牌扩张趋势预测提供数据基础。
奈雪的茶门店网址:奈雪门店信息 - 奈雪的茶
我们第一步先找到门店数据的存储位置,我们打开开发者模式后Ctrl+Shift+I(Windows),因为加载的数据请求太多,我们直接使用页面(Ctrl+Shift+C)检查来检索数据位置,同时也可以看到地址栏的关键词是"addr";
点击"源代码"发现数据在mdxx的html里面,于是我们切换到"网络",发现为空,打开"响应"同样发现返回的内容依然没有门店的详细信息,只有一段HTML和一些脚本链接。这说明门店数据是通过JavaScript动态加载的,不是直接写在HTML里;
说明现在拿到的只是网页壳,门店数据是通过接口异步请求的,那么通过在网络里检索刚刚的"addr"关键词,来看看数据到底在哪,可以看到,数据在一个js文件里;
门店信息确实就在这个JS文件的内容里,只不过是以HTML片段的形式嵌入的。我们现在只需要用Python把这些HTML片段解析出来,就能批量提取所有门店的详细信息;
我们找到门店地址数据的存储位置后,先看一下标头,是标准的GET 请求;
接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应数据存储位置,获取所有门店的相关标签数据;
- 门店数据进行地理编码和坐标系转换;
- 可视化,数据导入ArcGIS进行可视化;
第一步:找到数据的位置之后,我们就利用使用 requests 库发送 HTTP 请求到指定的 URL(JavaScript 文件地址),找出 JS 文件中通过 document.write() 插入的 HTML 代码,把 JS 文件中的特殊字符(如 \u003c 表示 <)还原成正常的 HTML 标签,解析 HTML 内容,找出所有门店的信息并根据标签进行保存,另存为csv;
完整代码#运行环境 Python 3.11
import requests
import re
import pandas as pd
from bs4 import BeautifulSoup
import urllib3urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)url = 'https://nwzimg.wezhan.cn/pubsf/10166/10166460/cdn-static-pages/pages/mobile/574778_zh-cn.html.Body.js?version=20250430183727'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36','Accept': '*/*','Referer': 'https://www.naixue.com/mdxx',
}# 1. 下载JS文件内容
response = requests.get(url, headers=headers, verify=False)
js_content = response.text# 2. 提取document.write('...')中的内容
match = re.search(r"document\.write\('(.+)'\);", js_content, re.DOTALL)
if not match:print("未找到document.write内容")exit()
html_escaped = match.group(1)# 3. 把\u003c等转义字符还原成HTML
html = html_escaped.encode('utf-8').decode('unicode_escape')html = html.encode('latin1').decode('utf-8')# 4. 用BeautifulSoup解析所有<tr class="row1">...</tr>
soup = BeautifulSoup(html, 'html.parser')
trs = soup.find_all('tr', class_='row1')data = []
for tr in trs:tds = tr.find_all('td')if len(tds) >= 5:index = tds[0].get_text(strip=True)city = tds[1].get_text(strip=True)storename = tds[2].get_text(strip=True)addr = tds[3].get_text(strip=True)memo = tds[4].get_text(strip=True)data.append([index, city, storename, addr, memo])df = pd.DataFrame(data, columns=['序号', '城市', '门店名', '地址', '备注'])
df.to_csv('naixue_stores.csv', index=False, encoding='utf-8-sig')
print('所有门店信息已保存为 naixue_stores.csv')数据会以csv表格的形式,保存在运行脚本的目录下,数据标签包括:城市、门店名称、地址;
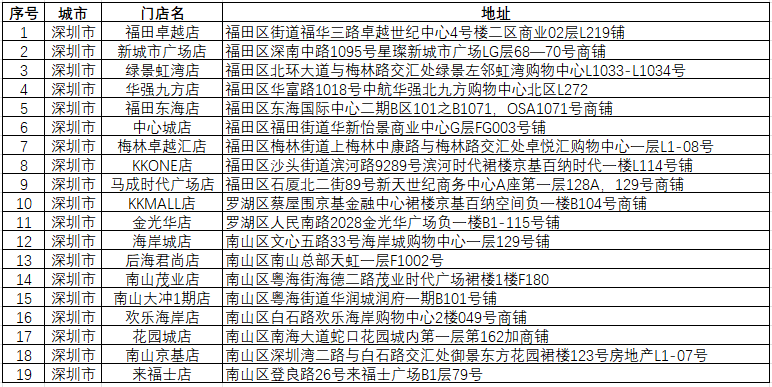
第二步:地理编码和坐标系转换,这里因为数据标签没有直接的坐标数据,需要把获取的门店地址进行地理编码,具体实现方法可以参考我这篇文章:地址转坐标:利用高德API进行批量地理编码_高德地图api-CSDN博客;
这里直接下载转换结果,坐标系GCJ-02,当然还有个别地址描述太模糊的或者格式无法识别,会查不出坐标,手动查一下坐标即可,大部分还是可以查到的,因为当前坐标系是GCJ02,需要批量转成WGS84/BD09的话可以用免费这个网站:批量转换工具:地图坐标系批量转换 - 免费在线工具 (latlongconverter.online),也可以通过coord-convert库实现GCJ-02转WGS84;
第三步:对CSV文件中的门店坐标列进行转换。完成坐标转换后,再将数据导入ArcGIS进行可视化,向地图添加x,y数据即可;
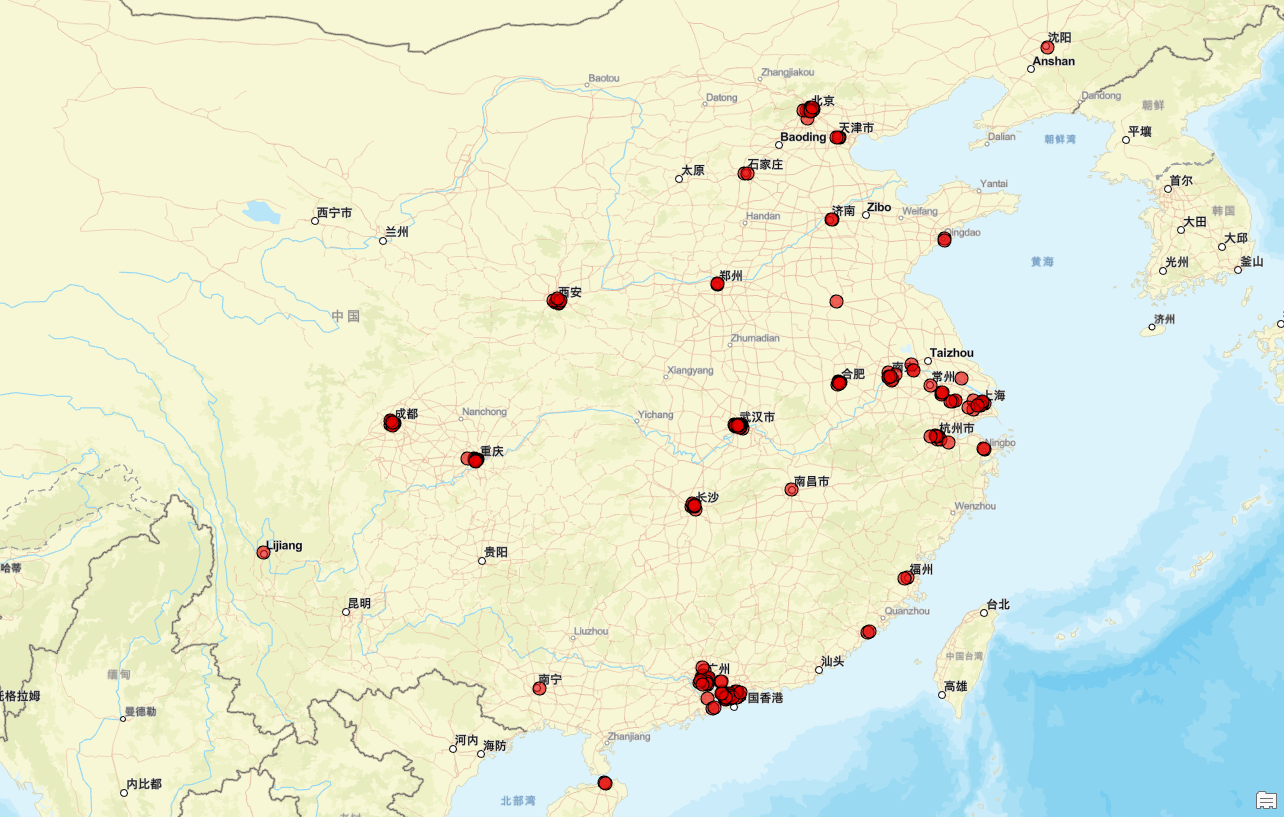
接下来,我们进行看图说话:
奈雪的茶门店分布特征展现出明显的地域偏好,主要集中在经济较为发达、人口密度高且消费能力强的东部沿海地区及一线城市。这些区域包括上海、江苏、浙江和广东等省份,这里不仅是经济活动的核心地带,同时也是年轻消费者聚集的地方,对新鲜事物接受度高,为高端饮品品牌的成长提供了肥沃土壤。在这些地方,奈雪的茶不仅覆盖了北京、上海、广州、深圳这样的传统一线城市,也涵盖了成都、杭州、南京等新一线城市,这表明品牌致力于深耕这些具有较高消费潜力的市场。
与此同时,中部和南部的一些重要城市如武汉、长沙、郑州、合肥等地也有一定数量的奈雪的茶门店布局,显示出品牌向内陆市场的扩展趋势。
整体来看,奈雪的茶的门店布局策略呈现出明显的城市群效应,特别是在长三角、珠三角以及京津冀等城市群内,门店分布尤为密集,形成了强大的品牌影响力和规模效应。这种战略有助于品牌迅速占领核心市场,并逐步实现全国范围内的市场渗透。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。