Python爬虫--Xpath的应用
1.XPath 基本语法
在开始学习前,请遵守网站的robots协议。掌握这项技术能帮助我们高效获取资源,这些知识仅限个人学习使用。
XPath(XML Path Language)是一种在XML和HTML文档中定位节点的语言,常用于数据解析。以下是一些核心语法规则:
节点选择
/:从根节点开始选取(绝对路径)。//:从当前节点选择任意层级的子节点(相对路径)。.:当前节点。..:父节点。
属性选择
@:选择属性。例如://div[@class="content"]选择所有class属性为"content"的<div>。
谓语(条件筛选)
[n]:选择第n个节点(索引从1开始)。[last()]:选择最后一个节点。[contains(@attr, "value")]:属性包含特定值。
2.常用表达式示例
文本提取
//p/text():获取所有<p>标签的文本内容。//a/@href:获取所有<a>标签的href属性值。
层级嵌套
//div[@id="main"]//li:选择id="main"的<div>下的所有<li>(任意层级)。
逻辑条件
//input[@type="text" and @name="user"]:选择type为"text"且name为"user"的<input>。
3.高级用法
轴(Axis)
ancestor:::选择所有祖先节点。following-sibling:::选择后续同级节点。- 示例:
//td[text()="Price"]/following-sibling::td[1]选择“Price”后的第一个<td>。
函数
normalize-space():去除文本多余空格。starts-with(@attr, "prefix"):属性值以特定前缀开头。
4.实际应用场景
爬虫数据提取
- 定位动态生成的元素:
//div[contains(@class, "dynamic-content")]。 - 处理表格数据:
//table//tr[position()>1]跳过表头行。
- 定位动态生成的元素:
XML/JSON解析
- 配合
lxml库(Python)使用:from lxml import etree html = etree.HTML(response.text) result = html.xpath('//title/text()')
- 配合
5.注意事项
- 避免过度依赖绝对路径(如
/html/body/div),结构变化易导致失效。 - 优先使用
contains或starts-with匹配部分属性值,提高容错性。 - 浏览器开发者工具(如Chrome)可直接复制XPath路径,但需人工优化。
通过灵活组合上述语法,可以高效定位并提取结构化数据。
正文:
以上是人工智能的回答,以我不太清晰逻辑来表达我的流程体验及应用
2025.7.23 -20:12
阔别已久,我经过查阅和寻找对我的性认知希望能够得到正确的纠正,我第一次接触到性,大概是在初二时,我看到别人看那样的场景,第一次觉得特别恶心,后面自己不懂,也有些其他的奇奇怪怪的想法,所以我应该有挺长的自慰史了,哈哈,我想把这个戒掉,起码在我进步的这段时间里,因为每次完事后,我伴随的是无尽的悔恨;所以下定决心了好多次,这个事,也难以启齿。同时经过我的了解网络上的概念:性缘脑,好像很符合我,我也想对自己做出改变;
正确的性教育对我来说很重要,是浏览不良网站的愧疚,所以我也查阅了相关的教育片,日本的“”17.3“”这部性教育片,在b站上有,我看了有了体验,也学习到了知识。讲的是三位女性对于性的不同认知,三个角度,但她们都相互帮忙,是很好的友谊。所以我更希望让自己正确认识性知识,面对它,自慰不可怕,但在少之又少的性教育来说,我在进行着这样教育的时候,和同学低头笑语,好像自己很懂,其实自己不懂,害羞、更为自己的行为可耻,受不良网站的侵扰,我不止一次下令痛改前非,所以这一次更像是对自己的告诫,加油,少年!
自重自尊自爱自愈
“没写错,我要正确的认识自己,我想在CSDN上发布的原因是,我想正确的认识自己,也想以此来约束自己,我喜欢过一个女孩子,她很漂亮,然后我也想通过自己的努力(我自卑)表白我的心意,是激励我前行的动力。但我是自卑的,我害怕但我要勇敢的面对自己。”
2025.7-20:32
一、进入正题
首先,我们需要先安装一个插件来辅助我们解析Xpath,这是安装的方法,推荐使用谷歌浏览器,用极简插件来安装,这是它的一个安装完成的插件图标,因为在CSDN上已存在资源,我无法直接上传安装包。可自行查阅网络资源下载,或着给我发消息。
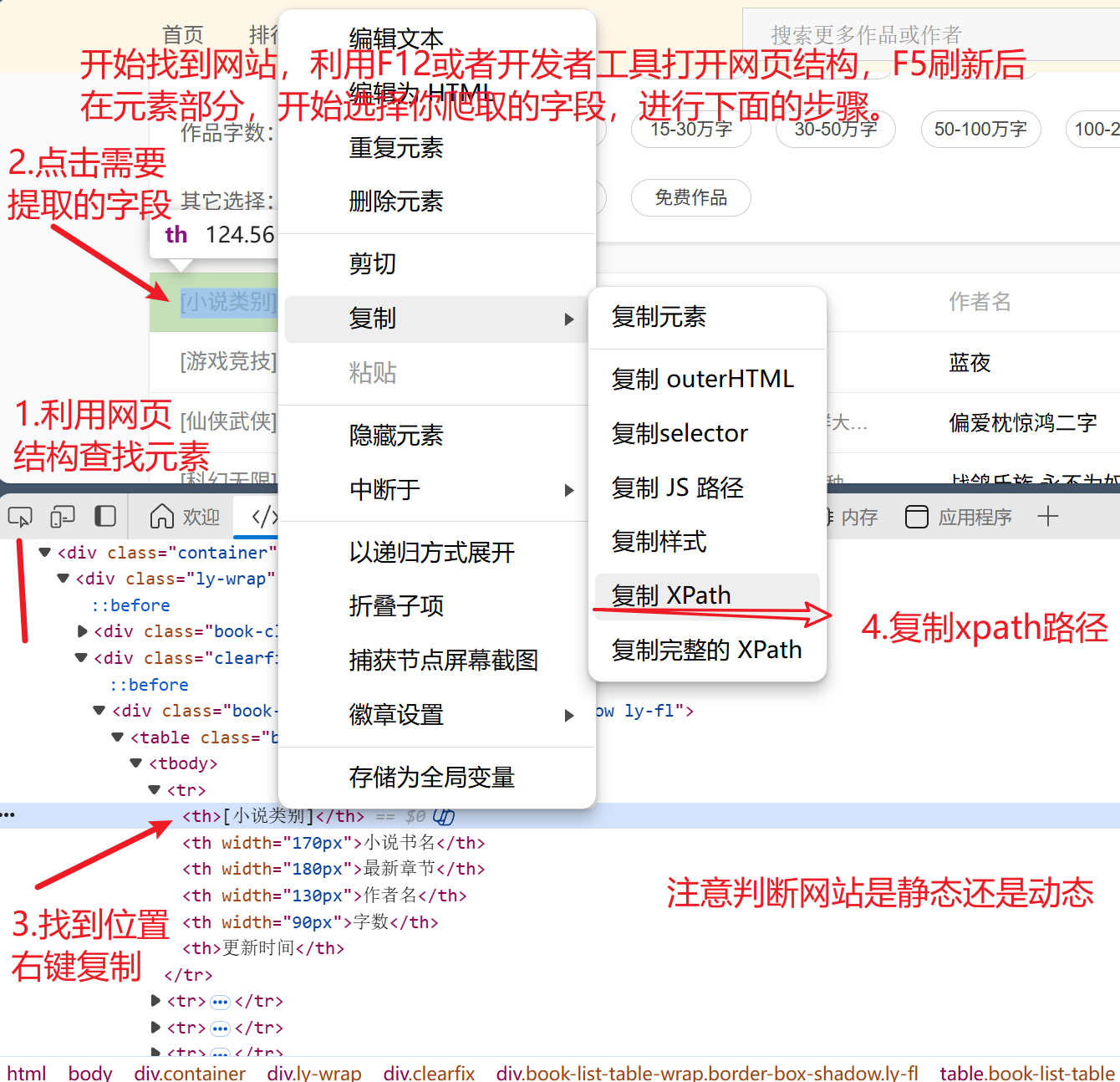
我将进行一步实例展示其应用
二、查看页面源代码
该网站通常是静态的,特别适合使用Xpath提取新闻类和小说类内容。
图片展示
判断网站是静态还是动态的方法
这个呢,我有时也不理解,静态网站:由纯 HTML、CSS 构成,内容固定,除非手动修改代码。
动态网站:使用 JavaScript 和/或服务器端技术,内容可根据条件或用户输入变化;通常需要与数据库交互,无需服务器端处理;可以截图网页源代码利用AI问问。AI回答
--------------------------------------------------------------------------------------------------
一、观察URL结构特征
静态网站URL特征:
- 通常包含文件扩展名(如.html、.htm、.css、.js等)
- 示例:
www.example.com/about.html - URL结构简单直观,反映文件目录结构
- 参数较少或没有查询字符串
动态网站URL特征:
- 常包含问号(?)和参数(如?id=123&category=5)
- 示例:
www.example.com/product.php?id=123 - 可能使用伪静态URL(如
www.example.com/news/2023/10/15) - 可能包含会话ID或其他标识符
静态页面特征:
- HTML代码中不包含服务器端脚本标签(如PHP、ASP、JSP等)
- 内容在源代码中完全可见
- 没有明显的动态生成标记
动态页面特征:
- 可能包含服务器端脚本标签(如
<?php ... ?>、<% ... %>等) - 常见动态内容占位符
- 可能包含模板引擎标记
- 可能包含服务器端脚本标签(如
---------------------------------------------------------------------------------------------------------------------
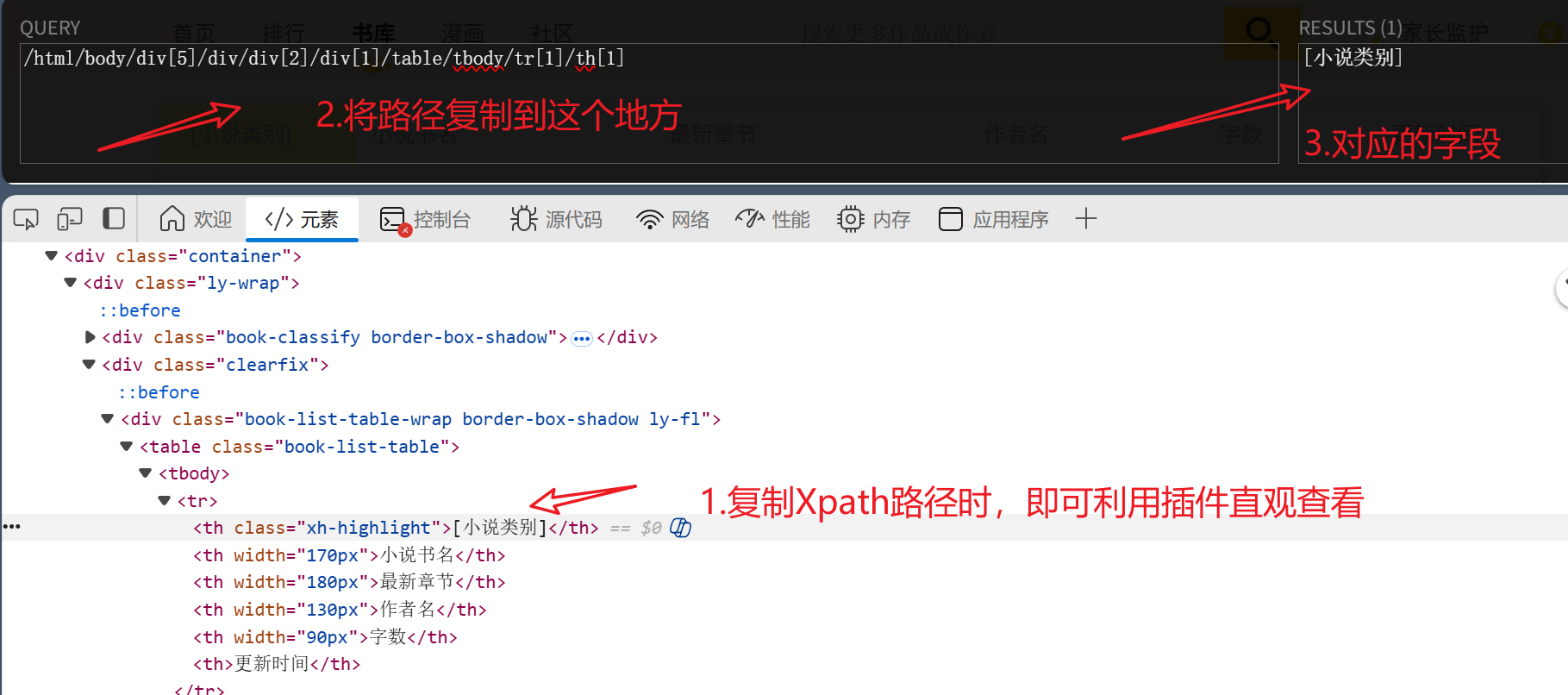
查看结果:
使用之前,介绍这个情景题要》
在使用XPath解析HTML文档之前,我们需要明确这个代码片段的具体应用场景和实现原理。这个示例展示了如何从网页响应中提取<title>标签的文本内容,是网络爬虫开发中常见的HTML解析场景。
具体实现步骤如下:
response.text:通常来自requests库的网络请求响应,包含网页的HTML源代码
etree.HTML():将HTML字符串转换为可解析的Element对象
xpath():使用XPath表达式定位目标元素
//title:查找文档中所有<title>标签
/text():提取元素的文本内容
from lxml import etree
html = etree.HTML(response.text)
result = html.xpath('//title/text()')
注释
为了多爬取字段,观察不同的xpath路径。来查看相关关联
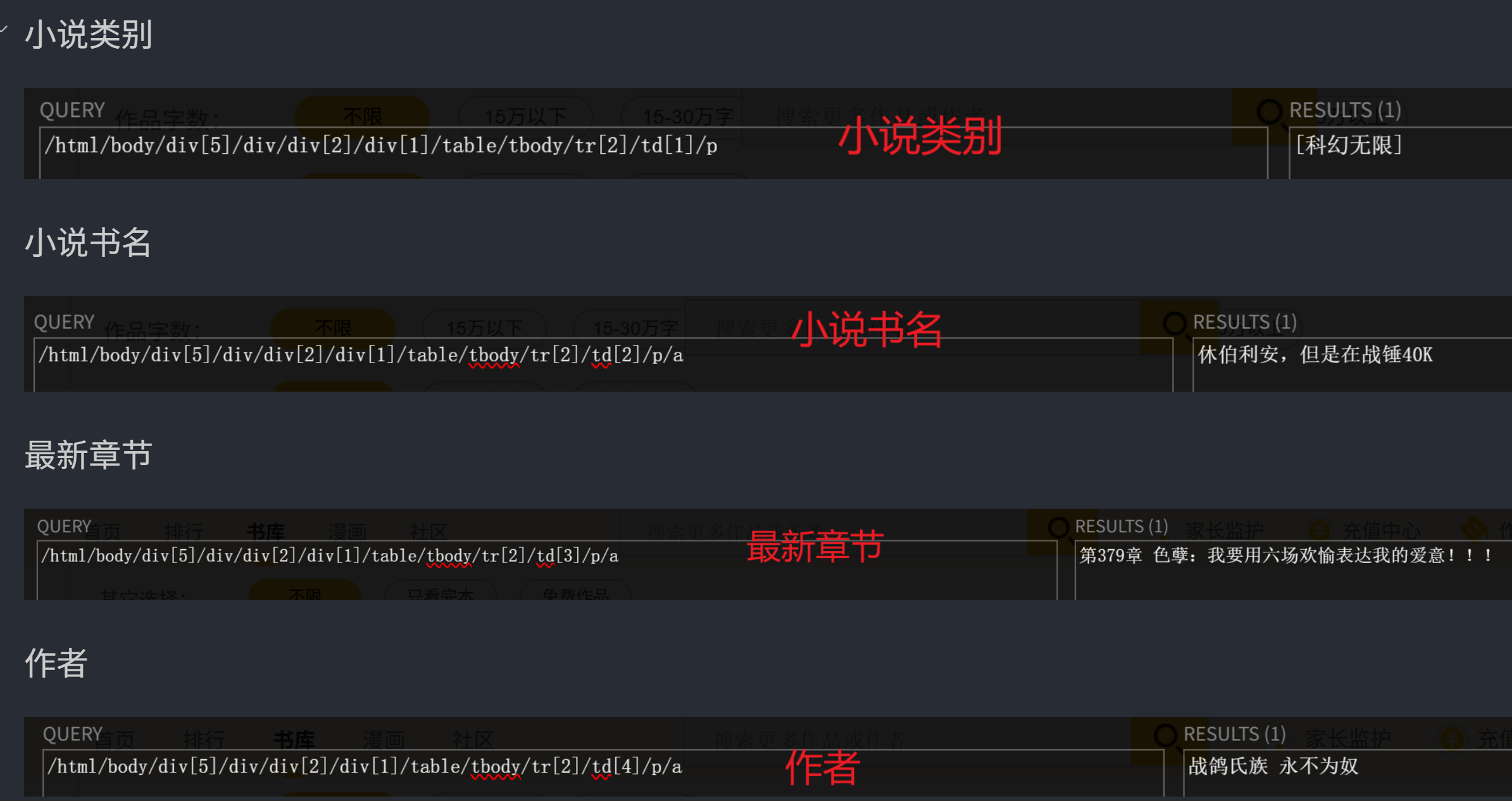
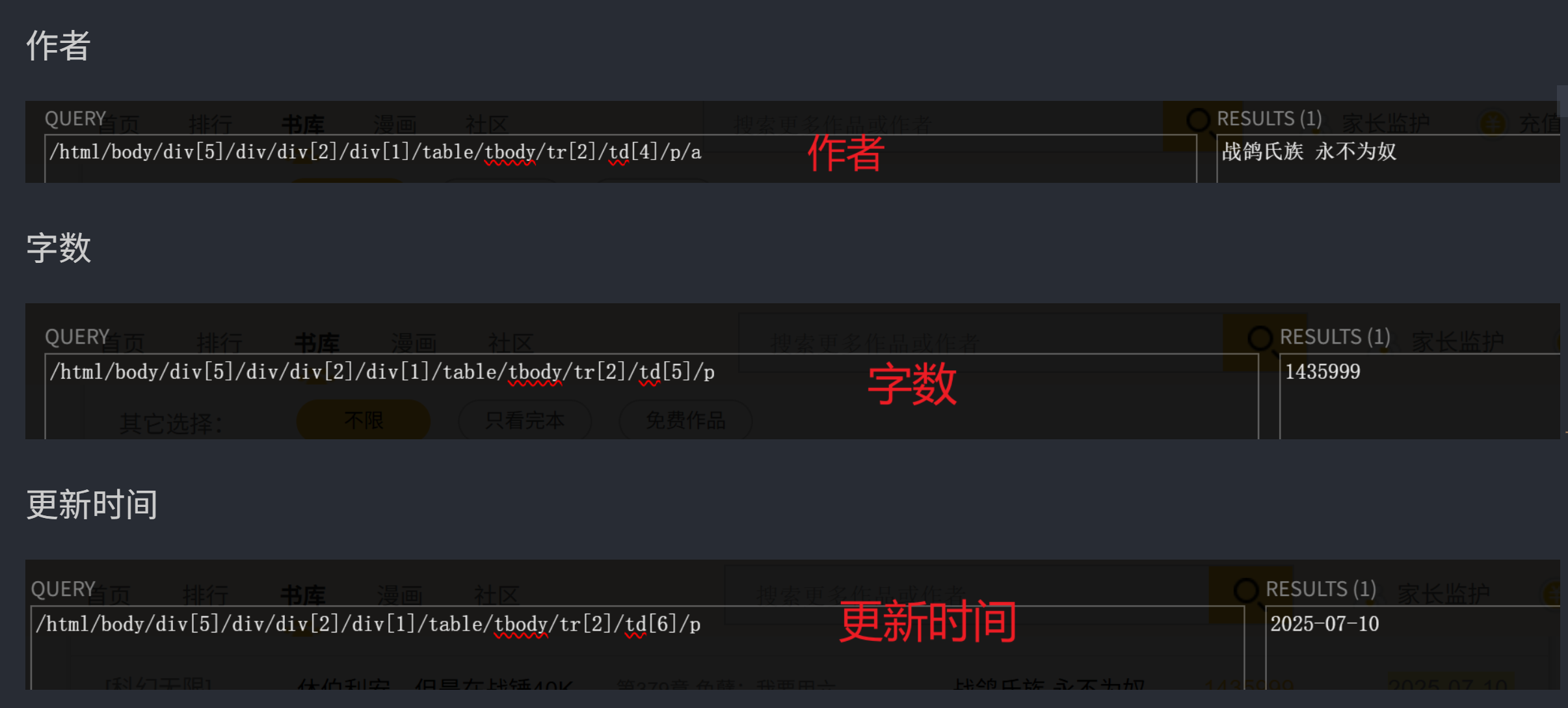
这是小说类别的具体字段的xpath对应,对应下面的category
/html/body/div[5]/div/div[2]/div[1]/table/tbody/tr[2]/td[1]/p
category = html.xpath('/html/body/div[5]/div/div[2]/div[1]/table/tr[2]/td[1]/p/text()')
book_name = html.xpath('/html/body/div[5]/div/div[2]/div[1]/table/tr[2]/td[2]/p/a/text()')
latest_chapter = html.xpath('/html/body/div[5]/div/div[2]/div[1]/table/tr[2]/td[3]/p/a/text()')
author = html.xpath('/html/body/div[5]/div/div[2]/div[1]/table/tr[2]/td[4]/p/a/text()')
word_count = html.xpath('/html/body/div[5]/div/div[2]/div[1]/table/tr[2]/td[5]/p/text()')
update_date = html.xpath('/html/body/div[5]/div/div[2]/div[1]/table/tr[2]/td[6]/p/text()')经过对比后,发现tbody删除,在后面加上了 "/text()" 提取文本内容
/html/body/div[5]/div/div[2]/div[1]/table/tbody/tr[2]/td[1]/p
1、category = html.xpath('/html/body/div[5]/div/div[2]/div[1]/table/tr[2]/td[1]/p/text()')
- 该路径绝对定位,对网页结构变化非常敏感
相对路径:
2、category = html.xpath('//table//tr[2]/td[1]/p/text()')
- 第一个XPath路径:
/html/body/div[5]/div/div[2]/div[1]/table/tr[2]/td[1]/p/text()
- 是绝对的完整路径
- 从html根节点开始层层往下定位
- 每个层级都指定了具体的位置索引(如div[5])
- 一旦网页结构中任意层级的元素位置/数量发生变化就会失效
- 第二个XPath路径:
//table//tr[2]/td[1]/p/text()
- 使用双斜杠//表示相对路径
- 可以直接查找文档中任意位置的table元素
- 避免了从根节点开始的冗长路径
- 对网页结构变化的适应性更强(只要table的层级关系不变)
- 仍保留了部分精确位置定位(如tr[2])
总结
有什么问题欢迎在评论区讨论,我积极改正。不断进步。