大模型【进阶】(四)QWen模型架构的解读
一、Qwen 大模型的背景
Qwen(通义千问)是阿里巴巴云开发的大型语言模型(LLM)和多模态模型系列,旨在提供强大的自然语言理解、文本生成、图像理解、音频处理及工具使用能力。
Qwen 系列包括 Qwen、Qwen1.5、Qwen2、Qwen2.5 和 Qwen3 等版本,涵盖了从小型(0.5B 参数)到超大型(480B 参数)的模型规模,支持多语言(119 种语言)和多模态任务(文本、图像、音频、视频)。本文将重点探讨 Qwen 的模型架构、训练方法及关键技术创新。
二. 模型架构概述
Qwen 系列基于 Transformer 架构,主要采用 解码器-only(Decoder-only) 的因果语言模型(Causal Language Model, CLM)设计,专注于自回归任务(如下一词预测)。其架构分为两种主要类型:密集(Dense)模型 和 专家混合(Mixture-of-Experts, MoE)模型,以下分别介绍。
2.1 密集模型(Dense Models)
- 架构基础:基于经典 Transformer 解码器架构,包含多层自注意力机制(Self-Attention with Causal Mask)和前馈神经网络(Feed-Forward Networks, FFNs)。
- 参数规模:Qwen3 系列提供多种参数规模,包括 0.6B、1.7B、4B、8B、14B 和 32B 参数,适用于不同计算资源和应用场景。
- 关键优化:
- Grouped Query Attention (GQA):在 Qwen2 和 Qwen3 中引入 GQA,优化键值(Key-Value, KV)缓存使用,减少推理时的内存占用并提升吞吐量。GQA 通过将查询头分组,降低 KV 缓存的存储需求,同时保持多头注意力(Multi-Head Attention, MHA)的性能。
- Dual Chunk Attention (DCA):为支持长上下文(最高 128K token,部分模型通过 YaRN 扩展至 1M token),Qwen2 引入 DCA,将长序列分割为可管理的块,捕获块内和块间的相对位置信息,提升长上下文任务性能。
- Rotary Positional Embeddings (RoPE):Qwen 使用 RoPE 改进模型对词序和位置的理解,增强长序列处理能力。RoPE 是一种基于旋转的相对位置编码方法,相比传统绝对位置编码更适合长上下文建模。
- Flash Attention:通过优化注意力计算,加速训练和推理过程,降低计算复杂度。
2.2 专家混合模型(MoE Models)
- 架构特点:MoE 模型通过在每层 Transformer 中引入多个前馈神经网络(FFNs,称为“专家”),并通过门控网络(Gated Network)动态选择激活的专家,显著降低推理时的计算成本。
- 参数规模:
- Qwen3-235B-A22B:总参数 2350 亿,激活参数 220 亿。
- Qwen3-30B-A3B:总参数 300 亿,激活参数 30 亿。
- Qwen3-Coder-480B-A35B:总参数 4800 亿,激活参数 350 亿。
- 关键优化:
- Global-Batch Load Balancing:Qwen3 MoE 模型通过智能分配输入批次至 128 个专家(每 token 激活 8 个专家),减少路由偏差和专家利用不足问题,确保高效的训练和推理。
- 稀疏激活:MoE 模型仅激活部分参数(约 10%),大幅降低计算成本,同时保持与密集模型相当的性能。例如,Qwen3-235B-A22B 的性能可媲美更大规模的密集模型(如 DeepSeek-R1)。
- 优势:MoE 架构在资源受限环境下提供高性能,适合大规模部署和推理。
2.3 分词器(Tokenizer)
- 分词方法:Qwen 使用基于 Byte Pair Encoding (BPE) 的子词分词方法,词汇表大小为 151,646 个常规 tokens(regular tokens)加 3 个控制 tokens(control tokens)。
- 特点:
- 高压缩率:相比其他分词器(如 SentencePiece),Qwen 的分词器在多语言数据上具有更高的编码效率,支持 119 种语言。
- 特殊 token 处理:为支持对话格式(ChatML),Qwen 的聊天模型已学习特殊 token,简化了微调和推理过程。
- 多语言支持:通过在多语言数据(2-3 万亿 token)上预训练,Qwen 在英语、汉语及其他语言(如西班牙语、法语、日语)上表现优异。
三. 训练流程
Qwen 系列的训练流程分为 预训练(Pretraining) 和 后训练(Post-training) 两个阶段,结合了大规模数据和多种优化技术。
3.1 预训练
- 数据规模:
- Qwen3:训练数据超过 36 万亿 token,覆盖 119 种语言,包括编程语言、科学文献和领域特定数据集。
- Qwen2.5:高达 18 万亿 token,Qwen2.5-Max 超过 20 万亿 token。
- 训练目标:基于下一词预测(Next-Token Prediction),捕获语言的统计模式和结构。
- 长上下文优化:
- 通过持续预训练(Continual Pretraining)扩展上下文长度,使用高质量长序列数据。
- 结合 RoPE 和 DCA,支持 128K token 上下文(部分模型可扩展至 1M token)。
- 多语言数据:预训练数据涵盖多语言文本,确保模型在英语和汉语上的强大能力,并支持其他语言。
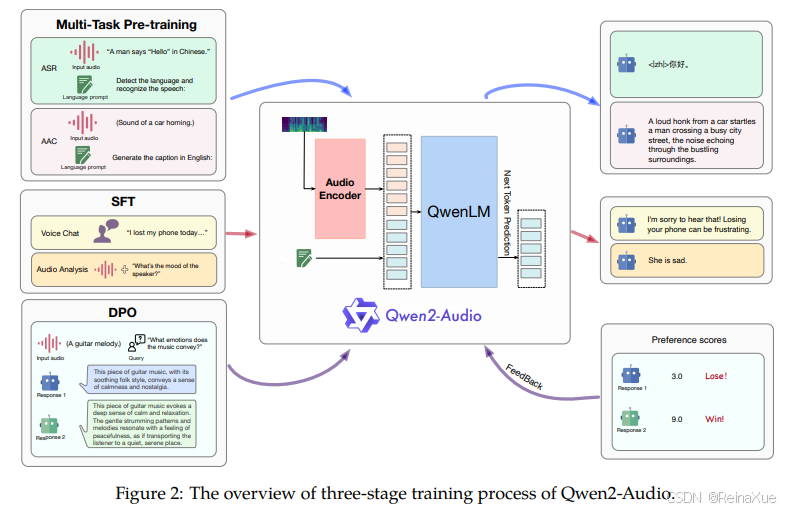
3.2 后训练
Qwen 的后训练包括 监督微调(Supervised Fine-Tuning, SFT) 和 强化学习(Reinforcement Learning, RL),以对齐人类偏好并提升特定任务性能。
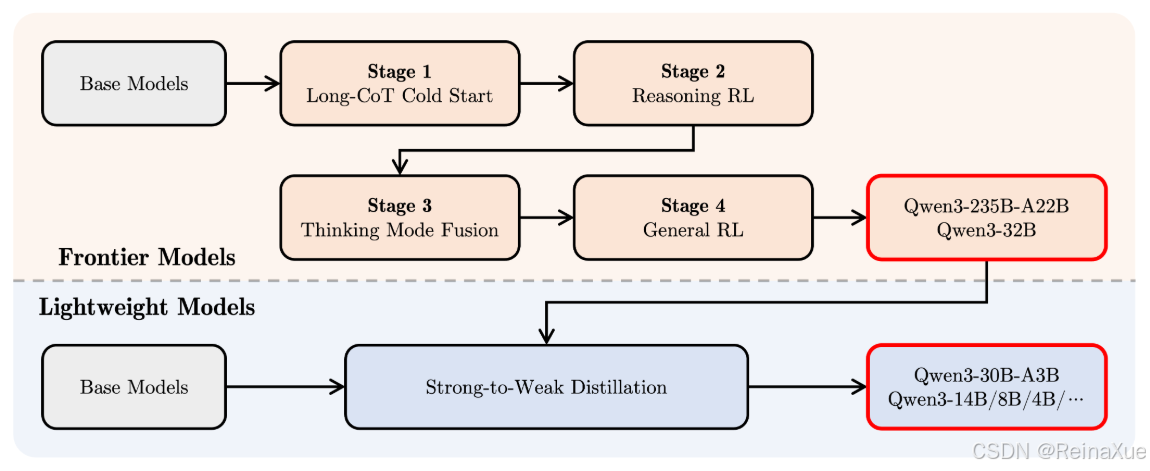
QWen3后训练的四个步骤:
(1)长思维链冷启动
在第一阶段,使用多样的的长思维链数据对模型进行了微调,涵盖了数学、代码、逻辑推理和 STEM 问题等多种任务和领域。这一过程旨在为模型配备基本的推理能力。
(2)长思维链强化学习
第二阶段的重点是大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力。
(3)思维模式融合
第三阶段,在一份包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中。确保了推理和快速响应能力的无缝结合。
(4)通用强化学习
在第四阶段,在包括指令遵循、格式遵循和 Agent 能力等在内的 20 多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力并纠正不良行为。
3.2.1 监督微调(SFT)
- 数据:使用高质量的指令跟随数据和长链式推理(Chain-of-Thought, CoT)示例,覆盖数学、代码和逻辑推理等多个领域。
- 目标:提升模型的指令遵循能力、格式合规性和领域特定性能。
3.2.2 强化学习(RL)
- 方法:
- RLHF(Reinforcement Learning from Human Feedback):通过人类反馈优化模型响应,增强安全性、对齐性和通用任务性能。
- DAPO(Direct Alignment from Preferences Optimization):在 Qwen3 中可能使用了 DAPO,减少对 RLHF 的依赖,优化人类偏好对齐。
- 多阶段训练管道(以 Qwen3 为例):
- 长 CoT 冷启动:在长链式推理数据上进行 SFT,增强复杂推理能力。
- 基于推理的 RL:针对数学、代码和逻辑推理任务进行强化学习,提升推理性能。
- 思考模式融合:将 CoT 输出与标准指令数据混合微调,实现“思考模式”(Thinking Mode)和“非思考模式”(Non-Thinking Mode)的无缝切换。
- 通用 RL:在广泛任务上进行最终 RL 优化,提升指令遵循、格式合规性和安全性。
3.2.3 思考模式与非思考模式
- 思考模式(Thinking Mode):专为复杂推理任务(数学、代码、逻辑)设计,支持逐步推理(Step-by-Step Reasoning),通过 tokenizer 启用或禁用。
- 非思考模式(Non-Thinking Mode):针对快速响应和通用对话优化,适合低延迟场景。
- 实现:通过四阶段后训练管道,Qwen3 实现两种模式的无缝切换,兼顾推理深度和响应速度。
四. 多模态扩展
Qwen 系列不仅限于语言模型,还包括多模态模型,如 Qwen-VL(视觉-语言)和 Qwen-Audio(音频-语言)。
4.1 Qwen-VL
- 架构:结合视觉 Transformer 和语言模型,支持图像理解和生成。
- 能力:识别图像中的对象、文本和动作,生成基于图像的内容。例如,Qwen-VL 可以识别图片中的人物和动作(如高五)。
- 最新版本:Qwen2.5-VL(3B、7B、32B 参数),支持 128K token 上下文。
4.2 Qwen-Audio
- 架构:支持音频和文本输入,生成文本输出。
- 能力:处理多种音频类型(语音、自然声音、音乐),支持情感分析、语音识别和问题回答。
- 应用:音频内容总结、音乐类型分类等。
4.3 Qwen2.5-Omni
- 架构:Thinker-Talker 架构,支持文本、图像、音频和视频输入,生成文本和语音输出。
- 创新:引入 TMRoPE(Time-aligned Multimodal RoPE),同步视频和音频的时间戳,提升多模态一致性。
- 应用:实时语音对话、视频分析、图像生成等。
五. 关键技术创新
- MoE 架构优化:通过全局批处理负载均衡和稀疏激活,Qwen3 的 MoE 模型在性能和效率之间取得平衡。
- 长上下文支持:通过 RoPE、DCA 和持续预训练,Qwen 支持超长上下文(128K 至 1M token),适合长文档处理和复杂任务。
- 多语言能力:训练数据覆盖 119 种语言,分词器优化多语言编码效率。
- 高效推理:
- 支持多种推理框架,如 vLLM、SGLang、SkyPilot 和 TensorRT-LLM,优化内存使用和推理速度。
- 提供量化模型(GGUF、AWQ、GPTQ),降低硬件需求。
- 开源策略:Qwen3 系列(包括 6 个密集模型和 2 个 MoE 模型)在 Apache 2.0 许可下开源,支持社区创新。
六. 性能与基准测试
- Qwen3 性能:
- Qwen3-235B-A22B 在编码、数学和通用能力基准测试中与 DeepSeek-R1、Grok-3 和 Gemini-2.5-Pro 等顶级模型竞争。
- 小型 MoE 模型(如 Qwen3-30B-A3B)性能超过 QwQ-32B,激活参数仅为其 1/10。
- Qwen3-4B 的性能可媲美 Qwen2.5-72B-Instruct,显示出高效的架构设计。
- 关键基准:
- MMLU-Pro:评估多任务语言理解能力。
- Arena-Hard、LiveBench、LiveCodeBench:测试编码和推理能力。
- GPQA-Diamond:评估复杂问题解答能力。
七. 应用场景
- 编码:Qwen3-Coder(480B-A35B-Instruct)在代理编码、浏览器使用和工具使用任务中表现优异,媲美 Claude Sonnet 4。
- 教育:作为虚拟导师,解释概念、生成摘要。
- 智能助手:支持任务管理、翻译、内容生成。
- 多模态应用:处理图像、音频和视频,适用于实时对话、内容分析等。
八. 部署与微调
- 部署框架:
- vLLM:优化大模型推理的内存和速度。
- SGLang:支持可扩展部署。
- TensorRT-LLM:在 NVIDIA GPU 上优化推理性能。
- llama.cpp:支持轻量级推理,适合资源受限环境。
- 微调:
- Q-LoRA:支持高效微调,仅更新部分参数,适合单 GPU 训练。
- 注意事项:微调聊天模型(如 Qwen-7B-Chat)时,需注意特殊 token 的处理;基础模型需更新嵌入层和输出层以学习新 token 。
九. 未来展望
- 模型架构优化:进一步改进 MoE 和 Transformer 架构,提升效率和性能。
- 数据规模扩展:继续增加训练数据量(已达 36 万亿 token),提升模型智能。
- 多模态增强:扩展 Qwen-Omni 的能力,支持更多模态和实时交互。
- 强化学习改进:通过环境反馈优化长程推理能力,迈向 AGI 和 ASI。
十. 参考资料
- Qwen3 官方博客:Qwen
- Qwen2 技术报告:[2407.10759] Qwen2-Audio Technical Report
- Qwen 模型介绍:Cloud Computing Services and Cloud Solutions - Alibaba Cloud
- Hugging Face Qwen 页面:https://huggingface.co/Qwen
- GitHub 仓库:https://github.com/QwenLM/Qwen