基于k2-icefall实践Matcha-TTS中文模型训练2
1 背景
1.1 实践2
在《基于k2-icefall实践Matcha-TTS中文模型训练》的实践基础上(后面简称“实践1”),笔者尝试着改变模型训练中的三大要素之一的数据,来对比分析用于训练的语音数据量对Matcha-TTS中文模型的训练时间和输出质量的影响。
在k2-icefall工程中,Matcha-TTS中文模型的训练数据集为BZNSYP语料库(包括10000条中文女性录音,合计语音12小时左右),笔者在“实践1”中epoch-2000轮次训练的时间约19个小时(硬件环境为一台i7-7770 CPU(ubuntu22.04.5)+32G内存+ nvidia RTX 3070 Ti显卡(8G))。
在本次“实践2”中,笔者基于(”实践1“)同一软硬件训练环境,尝试将用于训练的语料数量分别降低为原来的50%和10%,分两次单独进行训练,对比评估其对训练时间和输出质量的影响。
1.2 lhotse库
lhotse由阿里云和达摩院语音实验室共同开发,是一个开源的Python库,旨在简化自然语言处理(NLP)和语音识别(ASR)研究中的数据预处理工作流。lhotse提供了一套强大的工具和接口,使得音频数据的预处理、特征提取和数据集管理变得更加高效和便捷。
k2-icefall工程中的训练数据的准备工作,包括语料库的下载,音频数据的加载,预处理,特征提取,数据增强等准备工作,均依赖于lhotse工具命令行。
关于Lhotse,具体请参见:https://github.com/lhotse-speech/lhotse
2 准备工作
在k2-icefall工程中,Matcha-TTS中文模型的训练源代码位于“.\icefall\egs\baker_zh\TTS\”目录,其训练数据的准备工作主要由该目录下的“prepare.sh”脚本文件来实现(如下)。
... ...(无关部分省略)
if [ $stage -le 1 ] && [ $stop_stage -ge 1 ]; then
log "Stage 1: Prepare baker-zh manifest"
# We assume that you have downloaded the baker corpus
# to $dl_dir/BZNSYP
mkdir -p data/manifests
if [ ! -e data/manifests/.baker-zh.done ]; then
lhotse prepare baker-zh $dl_dir/BZNSYP data/manifests
touch data/manifests/.baker-zh.done
fi
fi
... ...(无关部分省略)
其中,“lhotse prepare baker-zh”命令用于加载全部“$dl_dir/BZNSYP”目录下的语音文件,并预处理输出“baker_zh_supervisions_all.jsonl.gz”和“baker_zh_recordings_all.jsonl.gz”等模型训练所需的输入文件(保存到子目录“data/manifests”),具体逻辑参见“baker_zh.py”。
由于原始“lhotse prepare baker-zh”命令并不支持控制加载用于训练的语料数量,需要我们自己扩展该命令来实现对实际加载的训练语料数量的控制。
2.1 扩展baker_zh命令定义
在.\lhotse\lhotse\bin\modes\recipes\baker_zh.py文件中,增加baker_zh命令的可选扩展项“-n”和参数“dmax”:
@prepare.command(context_settings=dict(show_default=True))
@click.argument("corpus_dir", type=click.Path(exists=True, dir_okay=True))
@click.argument("output_dir", type=click.Path())
@click.option(
"-n",
"--dmax",
type=int,
default=10000,
help="How many wav slices for tain.",
)
def baker_zh(
corpus_dir: Pathlike,
output_dir: Pathlike,
dmax: int,
):
"""bazker_zh data preparation."""
prepare_baker_zh(corpus_dir, output_dir=output_dir, dmax=dmax)
2.2 扩展prepare_baker_zh函数
在./lhotse/blob/master/lhotse/recipes/baker_zh.py文件中,修订baker_zh命令对应的实现函数prepare_baker_zh,扩展参数dmax,当加载语料数量达到最大的dmax数量时结束数据准备工作,具体修订参见如下代码中红色部分:
... ...(无关部分省略)
def prepare_baker_zh(
corpus_dir: Pathlike, output_dir: Optional[Pathlike] = None, dmax: int = 10000
) -> Dict[str, Union[RecordingSet, SupervisionSet]]:
... ...(无关部分省略)
recordings = []
supervisions = []
idx = 0
dmax = dmax
logging.info(f"Started preparing dmax= {dmax}...")
pattern = re.compile("#[12345]")
with open(labeling_file) as f:
try:
while idx < dmax:
first = next(f).strip()
... ...(无关部分省略)
idx += 1
recording = Recording.from_file(audio_path)
... ...(无关部分省略)
上述2.1和2.2修订的python文件需要替换到训练环境对应的lhotse库安装目录,并进行如下命令测试(输出如下表示修订ok):
# lhotse prepare baker-zh --help
Usage: lhotse prepare baker-zh [OPTIONS] CORPUS_DIR OUTPUT_DIRbazker_zh data preparation.
Options:
-n, --dmax INTEGER How many wav slices for tain. [default: 10000]
--help Show this message and exit.
2.3 扩展prepare.sh脚本
扩展数据预处理脚本prepare.sh,增加可以控制加载语料数量的可选参数“WavNum”(默认为10000,即全部加载):
#!/bin/bash
if [ $# -lt 1 ]; then
echo "Usage: $0 <WavNum:default=10000> "
fiWavNum=10000
if [ -n "$1" ];then
WavNum=$1
fi... ...(无关部分省略)
if [ ! -e data/manifests/.baker-zh.done ]; then
#lhotse prepare baker-zh $dl_dir/BZNSYP data/manifests
#扩展参数-n,以支持控制实际加载的训练语料数量
lhotse prepare baker-zh $dl_dir/BZNSYP data/manifests -n $WavNum
touch data/manifests/.baker-zh.done
fi
... ...(无关部分省略)
3 训练过程
3.1 50%语料训练
#进入Matcha-TTS中文模型的训练源代码目录
cd ~\icefall\egs\baker_zh\TTS\
#语料数据加载和预处理命令
./prepare.sh 5000
#开始训练
python3 ./matcha/train.py \
--exp-dir ./matcha/exp-1/ \
--num-workers 4 \
--world-size 1 \
--num-epochs 2000 \
--max-duration 360 \
--save-every-n 100 \
--bucketing-sampler 1 \
--start-epoch 1
补充说明:
1)命令./prepare.sh 5000:语料加载和预处理命令,增加参数5000,表示本次训练只加载50%的训练语料(10000*50%);
2)参数--save-every-n 100:训练命令中,为减少训练过程中间模型参数保存占用的磁盘空间,将save-every-n参数设为100(默认为10,即每10个epoch训练轮次保存一次模型参数);
3.2 10%语料训练
cd ~\icefall\egs\baker_zh\TTS\
#语料数据加载和预处理命令(1000条语料)
./prepare.sh 1000
#开始训练
python3 ./matcha/train.py \
--exp-dir ./matcha/exp-2/ \
--num-workers 4 \
--world-size 1 \
--num-epochs 2000 \
--max-duration 30 \
--save-every-n 100 \
--bucketing-sampler 1 \
--start-epoch 1
补充说明:
1)命令./prepare.sh 1000:参数1000,表示本次训练只加载10%的训练语料(10000*10%);
2)参数 --max-duration 30:由于本训练模式已经大大降低了(只有10%)可用于训练的语料数量,而k2-icefall训练框架使用单次训练批量动态调节模式(dynamic batch size+bucketing samplers),需要将单次训练预加载的最大语音片段时长由原来的360秒同步改小到30秒,以减小单次训练的batch size批量值,否则训练过程可能会碰到如下错误“ZeroDivisionError: division by zero”:
~/icefall/egs/baker_zh/TTS/./matcha/train.py:650: FutureWarning: `torch.cuda.amp.GradScaler(args...)` is deprecated. Please use `torch.amp.GradScaler(“cuda“, args...)` instead. scaler = GradScaler(enabled=params.use_fp16, init_scale=1.0) 2025-07-12 17:22:29,342 INFO [train.py:656] Start epoch 1 Traceback (most recent call last): File "/home/tigerp/k2/icefall/egs/baker_zh/TTS/./matcha/train.py", line 721, in <module> main() File "/home/tigerp/k2/icefall/egs/baker_zh/TTS/./matcha/train.py", line 715, in main run(rank=0, world_size=1, args=args) File "/home/tigerp/k2/icefall/egs/baker_zh/TTS/./matcha/train.py", line 666, in run train_one_epoch( File "/home/tigerp/k2/icefall/egs/baker_zh/TTS/./matcha/train.py", line 578, in train_one_epoch loss_value = tot_loss["tot_loss"] / tot_loss["samples"] ZeroDivisionError: division by zero
根据调测,这里的除零错误实际是由于k2-icefall训练框架的训练批量动态调节模式的计算逻辑限制导致(训练语料数量过小时会触发,同步改小最大语音片段时长可以规避)。
4 结果对比
4.1 训练时间
在同一训练环境下(训练参数略有不同):
1)上次文章所述的完整语料”训练1“,10000个训练语料,8个工作进程,最大语音片段时长360秒,耗时大概19小时;
2)本次3.1所述的”50%语料训练“,5000个训练语料,4个工作进程,最大语音片段时长360秒,耗时大概6.5小时;
3)本次3.2所述的”10%语料训练“,1000个训练语料,4个工作进程,最大语音片段时长30秒,耗时大概1.6小时;
4.2 训练效果
4.2.1 完整语料”训练1“
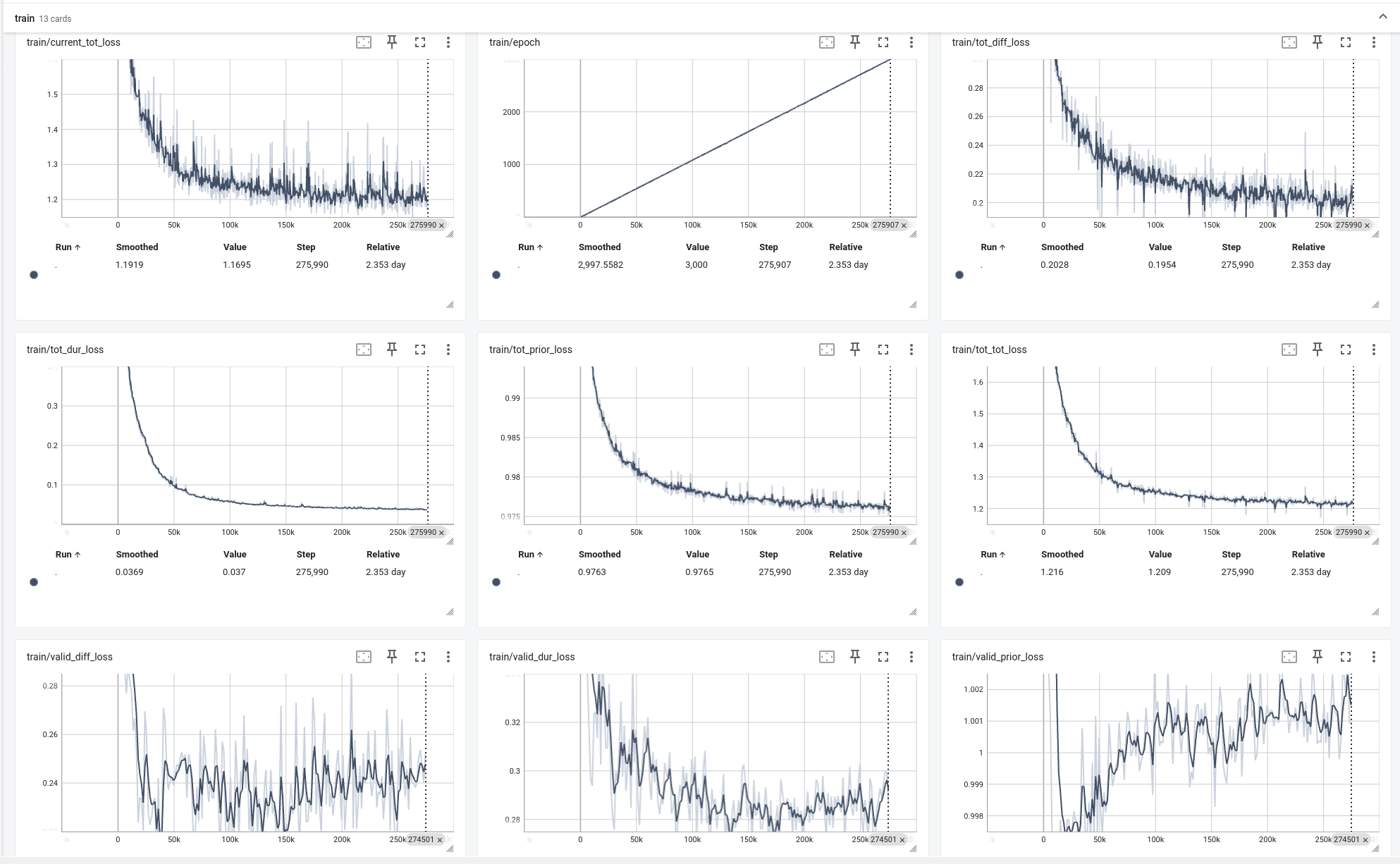
图1 完整语料训练1-TensorBoard图
如图1 为完整语料训练1的TensorBoard效果图,验证数据输出的valid_diff_loss/valid_dur_loss
等质量参数均在有效范围之内,最终生成的模型参数经过实际测试效果良好。
4.2.2 50%语料训练
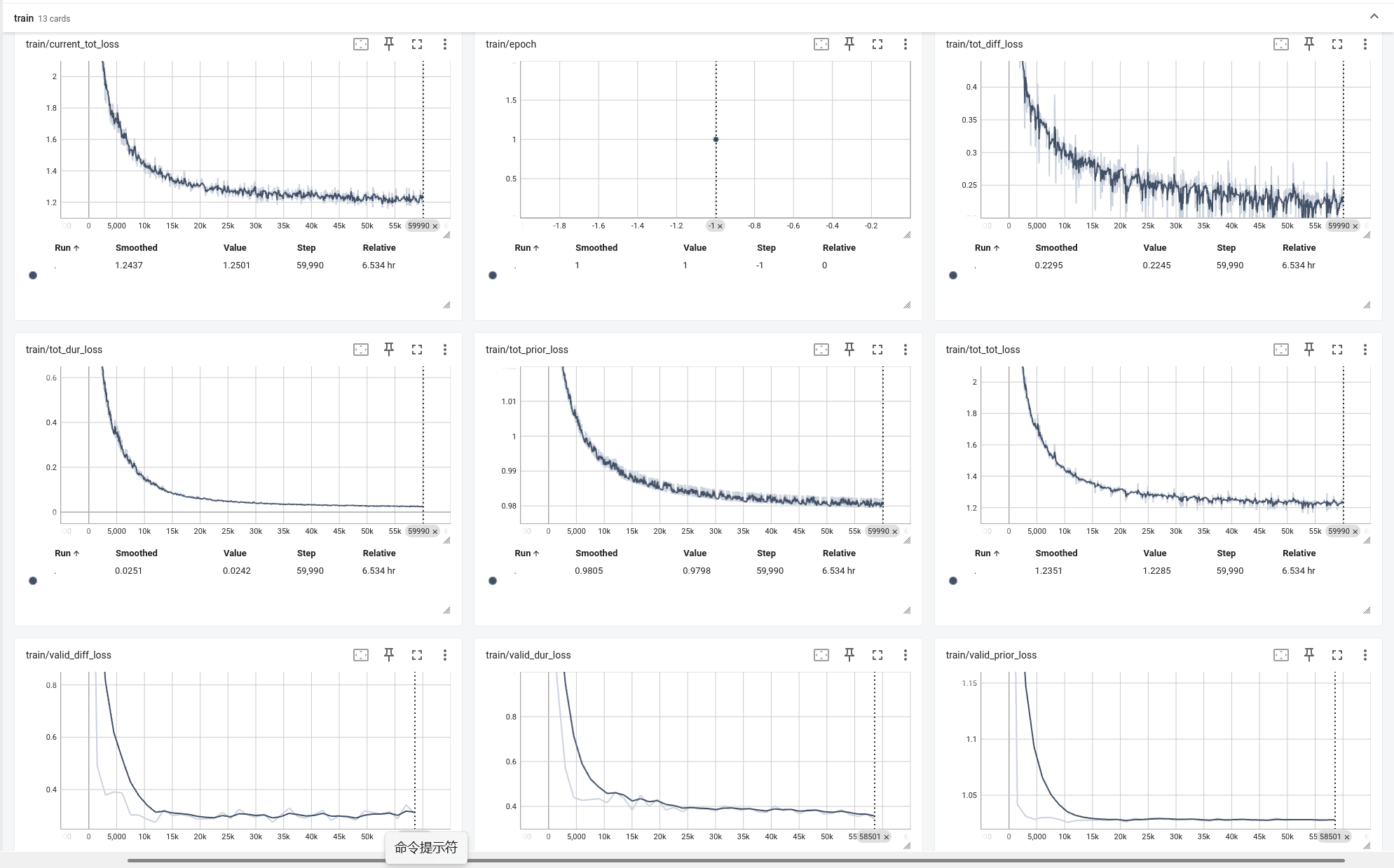
图2 50%语料训练-TensorBoard图
如图2 为50%语料训练的TensorBoard效果图,验证数据输出的valid_diff_loss/valid_dur_loss
等质量参数基本在有效范围之内,最终生成的模型参数经过实际测试效果良好(与4.3.1的模型相比较,人耳听不出差异)。
4.2.3 10%语料训练
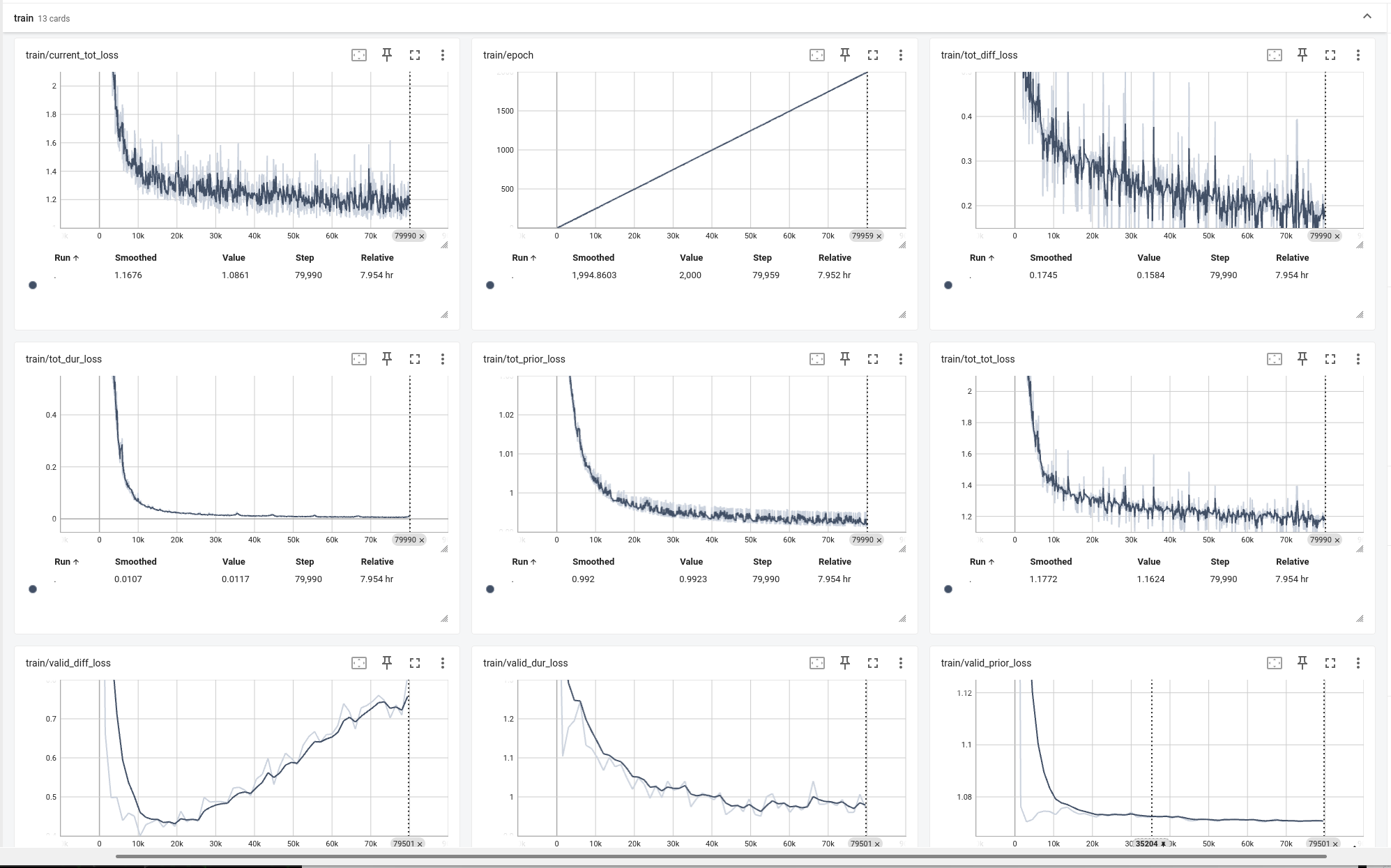
图3 10%语料训练-TensorBoard图
如图3 为10%语料训练的TensorBoard效果图,验证数据输出的valid_diff_loss/valid_dur_loss
质量参数基本没有形成收敛效果(误差值偏大),最终生成的模型参数在实际测试中基本无法听出有效字词,显然此种情况下的模型训练失败。
补充说明:图2中显示训练时间跨度为”7.954 hr“,实际为两次训练叠加(一次36分钟训练+一次1小时接续训练,中间有6小时多的暂停时间)。
4.3 总结
1)从4.1的对比数据来看,训练时间随着训练语料数据的减少基本上成比例减少。
2)50%语料训练的训练时长减少到了6.5小时左右,其输出的模型参数,从TensorBoard效果图和实际测试效果均表明是可用的。
3)对于10%语料训练过程,因为语料数据的过度减少,最终训练的模型参数实际不可用。可见,合理数量的训练语料数据对模型参数的最终成功训练非常关键。