AI助力,轻松实现人声分离伴奏提取
亲爱的小伙伴们!前段时间,有一位同事家的可爱小孩参加了一场英语演讲比赛。同事找到我,希望我能帮个忙,把讲视频中的人声去掉,只提取出其中相应的伴奏。今天,我就来和大家分享一下究竟如何实现从 MP4 视频中分离人声,并且成功提取出伴奏视频,相信这个小技巧会在很多时候派上用场哦。
提取音频
首先我们利用python从视频中提取出mp3格式的音频
from moviepy.editor import VideoFileClip
# 输入文件路径
input_video = r"123.mp4"
# 输出文件路径
output_audio = r"123.mp3"
# 加载视频文件
video = VideoFileClip(input_video)
# 提取音频并保存为 MP3 文件
video.audio.write_audiofile(output_audio)
print(f"转换完成!音频文件已保存为 {output_audio}")
工具下载
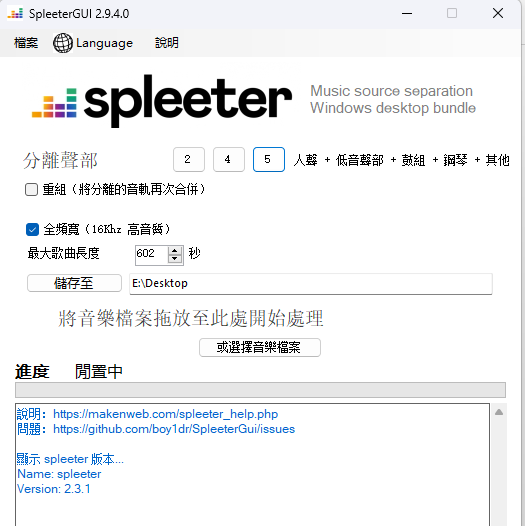
利用工具进行人声分离,这里我们直接适用工具SpleeterGUI直接操作,省去了复杂的python依赖配置,下载后直接使用。
下载网址:SpleeterGUI | Maken It So
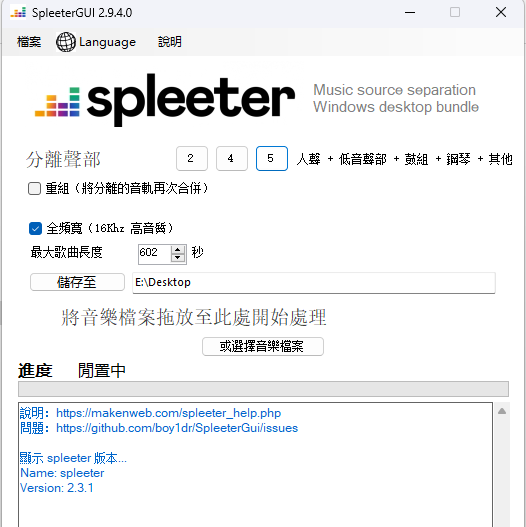
然后下载相应的spleeter模型,这里我已经下载打包好,需要的小伙伴可以关注我私信领取。
将下载好的模型放置到对应的位置。
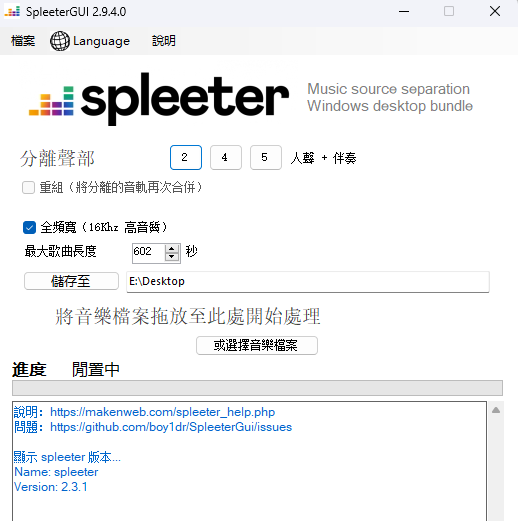
分离的三种模式,各位可根据需要自行选择。
视频合成
最后将伴奏与原视频进行合成,生成新的伴奏视频。
from moviepy import *
from moviepy.editor import *
import glob
video_dirs = glob.glob('视频.mp4')
audio = AudioFileClip("伴奏.mp3") # 提取音轨
for video_dir in video_dirs:video = VideoFileClip(video_dir) # 读入视频video = video.set_audio(audio) # 将音轨合成到视频中video.write_videofile("all.mp4") # 输出
好了,一个只有伴奏的视频做好了,希望得到大家的关注和点赞,我们下期见。