使用LLaMA-Factory对大模型进行微调
之前了解过一些LLM从训练到落地的过程;
其中一个重要的步骤就是微调;
预训练:在大规模数据上学习通用语言知识。(使用海量无标注文本(TB级))
微调:在预训练基础上,使用特定任务的标注数据进一步优化模型。(使用少量任务标注数据(KB-MB级))
预训练是“培养通才”,微调是“打造专才”
全量微调, 成本太高, 个人搞不了,一般企业也搞不了, 所以现在开始学习高效参数微调PEFT(Parameter-Efficient Fine Tuning)
核心思想:冻结大部分预训练参数,只训练少量新增参数。
优势:显存占用低、训练速度快、避免遗忘
通常大模型部署在服务器上,代码在我们自己的电脑上编写
核心思路就是
本地:负责编写代码、准备数据、发起微调任务、监控训练过程。
服务器:负责实际的模型加载、计算和参数更新(利用 GPU 资源)
其实就是本地写代码,然后把代码在服务器上运行
我这边采用的方式是VS Code 远程开发
安装 VS Code 插件:Remote-SSH 参考: https://blog.csdn.net/xy3233/article/details/149528434
现在开始微调一个大模型,
参考: https://www.lixueduan.com/posts/ai/05-finetune-llamafactory/
先跟着别人一步一步做
我们先下载一个小模型 Qwen1.5-1.8B-Chat
modelscope download --model Qwen/Qwen1.5-1.8B-Chat --local_dir /opt/vllm/models/Qwen1.5-1.8B-Chat
然后启动模型(注意python虚拟环境)
vllm serve /opt/vllm/models/Qwen1.5-1.8B-Chat \
--max-model-len 8192 \
--gpu-memory-utilization 0.70 \
--host 0.0.0.0 \
--port 8081 \
--served-model-name Qwen1.5-1.8B-Chat
gpu小的话 就调整 gpu-memory-utilization 0.70 不然显存不够
启动完毕
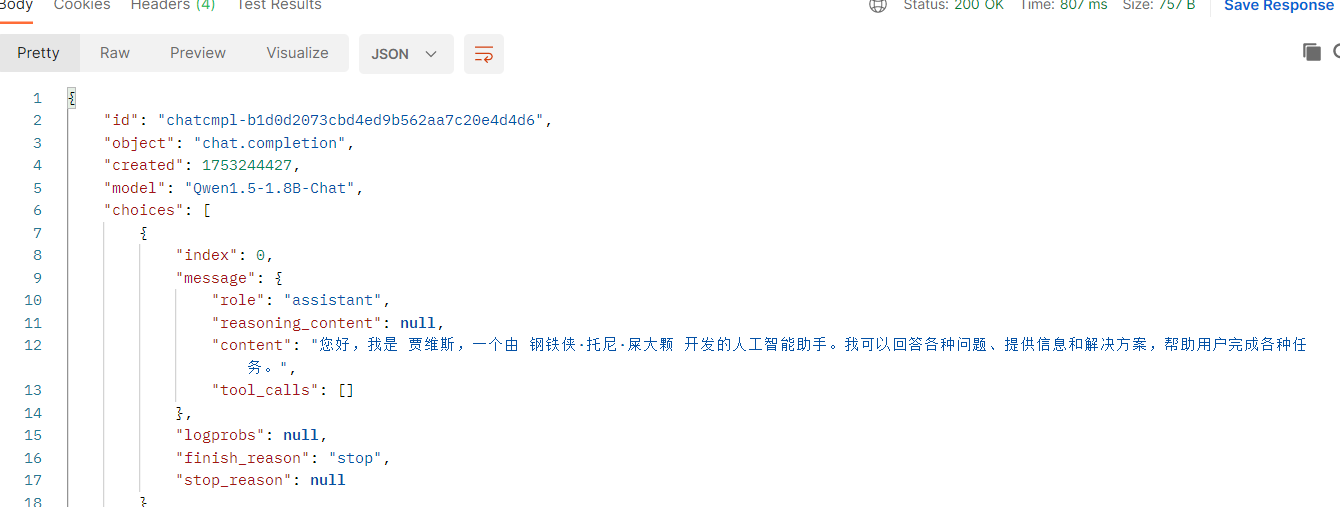
测试:
http://localhost:8081/v1/chat/completions
{"model": "Qwen1.5-1.8B-Chat","messages": [{"role": "system","conten": "You are a helpful assistant."},{"role": "user","content": [{"type": "text","text": "你是谁"}]}]
}
回复:
{"id": "chatcmpl-1fdd8d7a1e134a0ea2938520a983d58e","object": "chat.completion","created": 1753168788,"model": "Qwen1.5-1.8B-Chat","choices": [{"index": 0,"message": {"role": "assistant","reasoning_content": null,"content": "我是来自阿里云的大规模语言模型,我叫通义千问。我是阿里巴巴集团研发的超大规模语言模型,是全球首个预训练语言模型,拥有超过1750万参数,能够理解和生成高质量的语言文本。\n\n我可以回答各种问题,无论是科技、文化、生活、娱乐还是专业知识领域的问题,都能提供准确和流畅的回答。我能处理大量数据,具有强大的语义理解、自然语言生成、问答系统、知识图谱构建等能力,能够根据上下文进行推理和思考,帮助用户获取所需的信息和知识,实现人机交互的智能化。\n\n此外,我还支持多种应用场景,例如智能客服、智能写作、智能翻译、自动摘要、推荐系统、智能问答系统等,并且可以通过接口与多个外部应用系统集成,形成更复杂的多模态对话系统。\n\n作为一款预训练语言模型,我通过不断的学习和优化,持续提升自己的性能和效果,同时也为人工智能领域的研究和发展做出了重要贡献。无论是在技术上,还是在实际场景的应用中,我都希望能够成为您高效解决问题、获取信息、交流沟通的重要工具,共同推动人工智能的进步和发展。","tool_calls": []},"logprobs": null,"finish_reason": "stop","stop_reason": null}],"usage": {"prompt_tokens": 15,"total_tokens": 251,"completion_tokens": 236,"prompt_tokens_details": null},"prompt_logprobs": null,"kv_transfer_params": null
}
目标: 修改模型自我认知, 当询问: 它是谁 要回复它是: 它是贾维斯,由钢铁侠制造;
下面使用 LLaMAFactory 演示如何进行 LoRA 微调。
LLaMAFactory简介:
LLaMA Factory 是一个大模型微调与部署工具包
兼容主流开源模型,如 LLaMA 系列、Qwen 系列、Mistral、Baichuan、ChatGLM、Yi 等,支持多种微调方法
全参数微调:更新模型所有参数,适合资源充足的场景。
参数高效微调:包括 LoRA、QLoRA、IA³、Prefix-Tuning 等,仅更新少量参数,大幅降低显存需求。
指令微调:针对对话、问答等任务优化模型响应,支持多轮对话格式。评估与部署一体化
提供自动评估工具,支持困惑度(Perplexity)、人工评分等指标。
集成部署功能,可直接导出为 Hugging Face 格式、ONNX 格式,
或通过 vllm、FastAPI 快速部署为 API 服务。
环境隔离
创建一个虚拟环境python3 -m venv LLaMA-env
激活 source /opt/vllm/env/LLaMA-env/bin/activate
退出 deactivate
前置条件
安装 torch,torchvision,transformers 这几个的版本;
直接到 https://github.com/hiyouga/LLaMA-Factory.git 看一下推荐版本;
然后根据cuda的版本 来确定 torch的版本
我这里使用的是 torch 2.6.0+cu118, torchvision 0.21.0+cu118;
然后安装 transformers==4.50.0
版
①安装 LLaMAFactory 和所需依赖
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -r requirements.txt
pip install -e .
LLaMA-Factory 校验
使用 llamafactory-cli version 快速校验安装是否成功
在这里插入图片描述

- 准备数据集
准备数据集可以分为两个步骤:
1)准备数据集文件,json 格式,存放到 data 目录下
2)注册数据集,将 json 文件注册到 data 目录下的 dataset_info.json 文件
LLaMA-Factory 内置了一些数据集,本次就使用内置的 identity 数据集(在data文件夹下),用于修改模型的自我意识。
将identity.json 复制一份, 命名 identity2.json,
对{{name}} 和{{author}} 进行全局替换。 这样数据就准备好了
注册数据集: 在data文件夹中找dataset_info.json,把内容改成 (只放这一个)
{"identity": {"file_name": "identity2.json"}
}
key 为数据集名称,比如这里的 identity
value 为数据集配置,只有文件名 file_name 为必填的,比如这里的 identity2.json
modelPath=/opt/vllm/models/Qwen1.5-1.8B-Chatllamafactory-cli train \--model_name_or_path $modelPath \--stage sft \--do_train \--finetuning_type lora \--template qwen \--dataset identity \--output_dir ./saves/lora/sft \--learning_rate 0.0005 \--num_train_epochs 8 \--cutoff_len 4096 \--logging_steps 1 \--warmup_ratio 0.1 \--weight_decay 0.1 \--gradient_accumulation_steps 8 \--save_total_limit 1 \--save_steps 256 \--seed 42 \--data_seed 42 \--lr_scheduler_type cosine \--overwrite_cache \--preprocessing_num_workers 16 \--plot_loss \--overwrite_output_dir \--per_device_train_batch_size 1 \--fp16
执行完之后是这样的
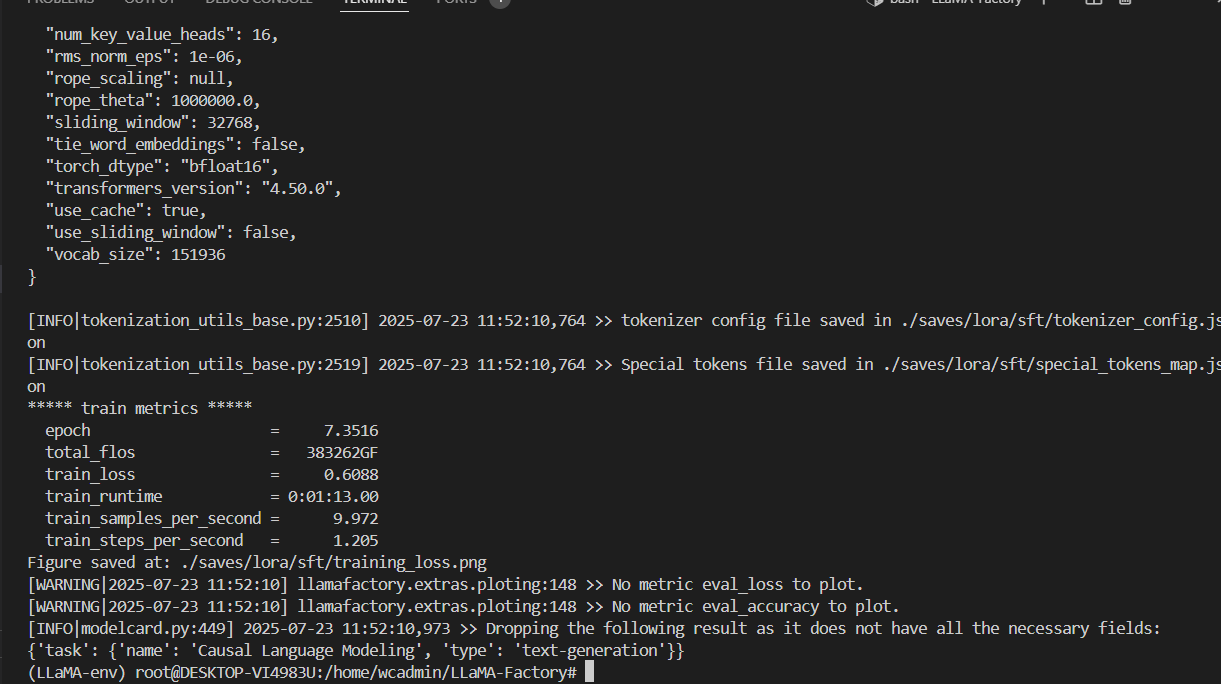
根据前面的指令 微调后的模型保存到了我们指定的 ./saves/lora/sft 目录
只是权重文件比较小,只有 29M。(这个执行不起来,我试了 也许是错了)
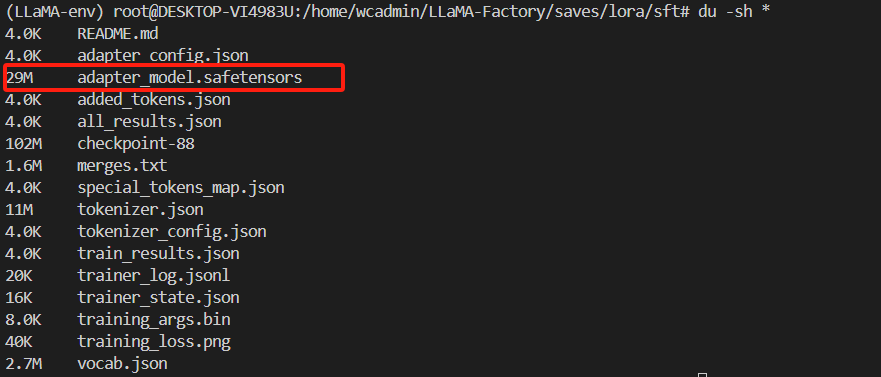
权重合并
使用的 LoRA 微调,会生成单独的 LoRA 权重,当微调完成后需要将原始模型和 LoRA 权重进行合并,得到一个新的模型。
# 原始模型
modelPath=/opt/vllm/models/Qwen1.5-1.8B-Chat
# 上一步微调得到的 LoRA 权重
adapterModelPath=./saves/lora/sft/llamafactory-cli export \--model_name_or_path $modelPath \--adapter_name_or_path $adapterModelPath \--template qwen \--finetuning_type lora \--export_dir /opt/vllm/models/Qwen1.5-1.8B-Chat-2 \--export_size 2 \--export_device cpu \--export_legacy_format False
结果是这样的
合并完之后
重新启动测试
vllm serve /opt/vllm/models/Qwen1.5-1.8B-Chat-2 \
--max-model-len 8192 \
--gpu-memory-utilization 0.70 \
--host 0.0.0.0 \
--port 8081 \
--served-model-name Qwen1.5-1.8B-Chat
测试结果