(Arxiv-2025)HiDream-I1:一种高效图像生成基础模型,采用稀疏扩散Transformer
HiDream-I1:一种高效图像生成基础模型,采用稀疏扩散Transformer
paper title:HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
paper是智象未来发布在Arxiv 2025的工作
Code:链接
Abstract
近年来,图像生成基础模型在质量方面取得了显著进展,但通常以计算复杂度和推理延迟增加为代价。为解决这一关键权衡问题,我们提出 HiDream-I1,一种拥有170亿参数的全新开源图像生成基础模型,能够在数秒内实现最先进的图像生成质量。HiDream-I1 基于一种全新的稀疏扩散变换器(Sparse Diffusion Transformer, DiT)结构构建。具体而言,其采用双流解耦设计与动态专家混合(Mixture-of-Experts, MoE)架构,首先通过两个独立编码器分别处理图像 token 和文本 token;随后采用单流稀疏 DiT 架构与动态 MoE,以成本高效的方式触发多模态交互,从而进行图像生成。为满足不同使用需求,我们提供 HiDream-I1 的三个版本:
- HiDream-I1-Full:完整版,50+扩散步;
- HiDream-I1-Dev:指导蒸馏版本,28步;
- HiDream-I1-Fast:最快版本,仅14步即可完成生成。
此外,我们在传统文本生成图像任务的基础上,对 HiDream-I1 进行改造,引入图像条件信息,实现精确的基于指令的图像编辑任务,从而构建出新一代指令编辑模型 HiDream-E1。最终,通过融合文本生成图像与指令图像编辑两大能力,HiDream-I1 演化为综合图像智能体 HiDream-A1,具备完整的交互式图像生成与优化能力。为加速多模态 AIGC 研究,我们已开源 HiDream-I1-Full、HiDream-I1-Dev、HiDream-I1-Fast 和 HiDream-E1 的全部代码与模型权重,项目地址如下: - https://github.com/HiDream-ai/HiDream-I1
- https://github.com/HiDream-ai/HiDream-E1
所有功能可通过 https://vivago.ai/studio 在线体验。

图1 | Hidream-I1生成的图像。
1. Introduction
近年来,图像生成模型取得了突破性进展,彻底改变了创意领域的格局。Stable Diffusion、Midjourney、DALLE-3 和 Imagen 等开创性模型不断突破文本生成图像的极限,在视觉保真度与创意性方面设立了新标杆,广泛应用于数字艺术、娱乐、设计等多个领域。尽管这些模型在输出效果上令人惊艳,但许多最先进的模型在推理时间和计算复杂度方面仍存在瓶颈,阻碍了实时和低成本部署的落地。
为弥合这一差距,我们提出 HiDream-I1,一款拥有170亿参数的全新开源图像生成基础模型,可在数秒内实现最先进的图像质量。HiDream-I1 构建于一种全新的稀疏扩散变换器(Sparse Diffusion Transformer, DiT)结构之上,首先采用双流 DiT 架构分别处理图像和文本 token,然后采用单流 DiT 架构实现多模态交互。双流与单流 DiT 架构均融合了动态专家混合(Mixture-of-Experts, MoE)设计,该结构可根据输入特征动态路由数据至不同的专家模块,从而在计算效率与图像生成质量之间取得优异平衡。
考虑到不同应用场景下用户需求差异较大,我们提供 HiDream-I1 的三种版本:
1)HiDream-I1-Full:完整版,采用50+扩散步,适用于追求极致图像质量的场景;
2)HiDream-I1-Dev:蒸馏优化版本,28步扩散,在质量与计算资源之间取得平衡;
3)HiDream-I1-Fast:最快版本,仅14步扩散,适合实时生成需求,在数秒内输出高质量图像。
除了强大的文本生成图像能力,HiDream-I1 还为交互式图像操作(即基于指令的图像编辑)奠定了基础。我们进一步推出 HiDream-E1,通过引入图像条件,使用户能够使用自然语言精确修改图像。该项拓展使 HiDream-I1 从一款生成模型演化为多功能的 AIGC 工具,不仅能够生成图像,还支持迭代式编辑,最终形成全面图像智能体 HiDream-A1。HiDream-A1 支持完全交互式图像创作与编辑,为生成式 AI 带来下一代用户体验。
总结而言,HiDream-I1 在多个方面做出了贡献:
-
卓越的性价比:稀疏扩散变换器架构。整体采用 Sparse DiT 架构,在 DiT 框架中优雅地集成稀疏 MoE 技术。不同的专家模块能够学习处理不同类型的文本输入,使模型更准确理解语义,并生成风格与题材多样的图像。更重要的是,Sparse DiT 提升了模型性能,同时控制了计算开销,显著提高了性价比。
-
强大的蒸馏技术:基于GAN的扩散模型蒸馏。通过将生成对抗学习(GAN)引入扩散模型蒸馏过程中,本方法利用 GAN 擅长捕捉图像细节与边缘清晰度的优势,弥补了传统扩散模型蒸馏中常见的模糊问题。因此,该方法不仅对扩散模型进行有效蒸馏,同时进一步增强生成图像的写实度与清晰度,实现速度与质量的双重优化。
-
性能优势:在人类偏好与语义对齐评估中表现领先。目前,HiDream-I1 在三大基准测试中取得领先成绩。首先,在 HPS 基准上,综合评估语义相关性、图像质量与美学表现的 Human Preference Score v2.1(HPSv2.1)评估中,HiDream-I1 在动画、概念艺术、绘画与摄影等多个风格上表现最优。此外,在 GenEval 与 DPG-Bench 两个文本-图像语义对齐评估中,HiDream-I1 同样取得最高语义相关性,展现出卓越的提示理解与跟随能力。
-
优异的可扩展性:从图像生成走向多模态智能体。在 HiDream-I1 的基础上,我们快速扩展至指令编辑模型 HiDream-E1,继而整合文本到图像生成与交互式图像编辑,HiDream-I1 与 HiDream-E1 实现了类似 GPT-4o 的“说出即所得”效果。进一步地,我们推出了新一代图像智能体 HiDream-A1,集图像生成、理解与交互式编辑于一体,构建对话式大模型。HiDream-A1 的推出代表了用户交互体验的升级,用户无需切换平台或调整复杂参数,大大降低了使用 AIGC 工具进行创作的门槛。
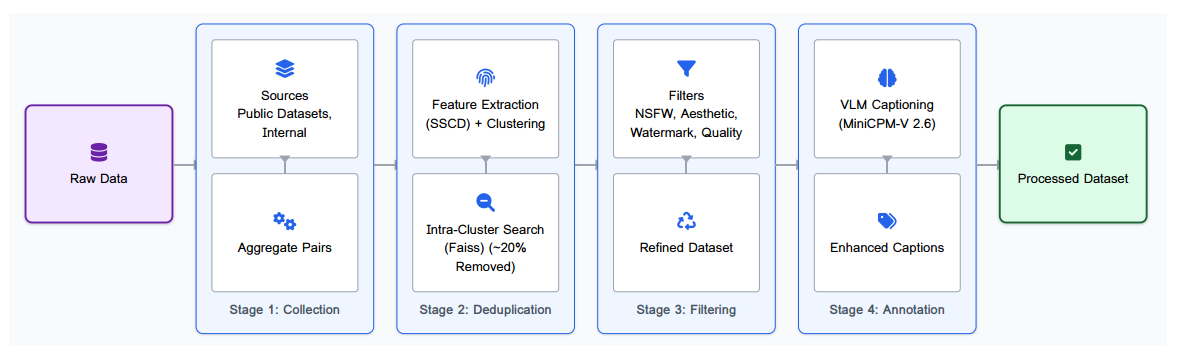
图2|数据预处理流程。
2. Data Pre-processing
大规模文本生成图像模型的能力通常依赖于其训练数据的质量、多样性和规模。因此,我们构建了一条严格的数据整理流程,包括系统性数据收集、精细化去重、全面多维度过滤以及详细标注。整体流程如图2所示。
2.1. Data Collection
我们的数据收集策略旨在兼顾广度与多样性。我们最初汇聚了大规模的候选数据,来源包括网络公开数据集和内部版权图像。对于网络数据,我们不仅收集图像本身,还包括其附带的文本信息(如标签、描述等)。在初始收集阶段,我们特别关注有意涵盖广泛的视觉内容,覆盖多样的艺术风格、主题、分辨率和纵横比。
2.2. Data Deduplication
为提升训练效率并降低模型记忆风险(参考 Somepalli 等,2023),我们设计并实施了一套全面的数据去重流程,旨在去除完全重复及视觉相似的图像。考虑到数据集规模,直接进行所有图像的两两比较在计算上是不可行的。因此,我们采用了高效的两阶段策略:
-
特征提取与近似聚类。首先,我们利用最先进的 SSCD 模型(Pizzi 等,2022)为每张图像提取鲁棒的视觉特征。然后,在代表性特征子集中(N=200万)应用 k-means 聚类,将整个特征空间划分为16,000个不同的聚类,从而将潜在相似图像归为一组。
-
聚类内去重。其次,在每个聚类内部,我们利用 GPU 加速的 Faiss 库(Douze 等,2024)执行精确的相似度搜索。凡是其特征向量相似度超过设定阈值的图像对,均被识别为近似重复,并从数据集中移除。
该两阶段去重策略最终清除约20%的初始收集图像,有效减少了数据冗余。
2.3. Data Filtering
原始图像集合中常常包含质量较低、无关或可能对模型训练与安全性造成负面影响的内容。为此,我们对数据集应用了一系列过滤步骤以进行精炼:
• 内容安全过滤:使用预训练的 NSFW 分类器(LAION-AI,2024b)识别并剔除潜在不适宜的图像。
• 美学质量过滤:采用美学评分模型(LAION-AI,2024a)预测每张图像的视觉吸引力。所有得分低于指定阈值的图像被丢弃。
• 水印过滤:利用专门的检测模型(LAION-AI,2024c)识别并移除带有明显水印的图像。
• 技术质量过滤:采用客观图像质量指标进行进一步筛选。其中,Top-IQ 图像质量评估指标(Chen 等,2024)评分较低的图像被移除。图像临时编码为 JPEG 格式后,根据其每像素字节比(bytes-per-pixel ratio)进行计算,过低的比值通常意味着细节缺失或压缩伪影严重,此类图像也被过滤。
2.4. Data Annotation
接下来,为实现大规模图像描述生成,我们采用了 MiniCPM-V 2.6 视觉语言模型(Vision-Language Model, VLM)(OpenBMB,2024)对每张图像进行自动标注。为提升生成描述的具体性与事实准确性,VLM 的输入不仅包括图像内容,还结合了已有的元数据(如用户标签或原始简要描述)作为上下文信息。
在特定指令下,VLM 被引导生成详细且客观的图像描述。这些指令强调捕捉图像中的关键视觉元素——包括物体、属性、空间关系与艺术风格——同时严格限制幻觉现象,并对时态与长度进行约束。值得注意的是,我们引入了一种新的提示策略,以鼓励生成长度不一的描述,更好地反映典型用户提示的多样性。
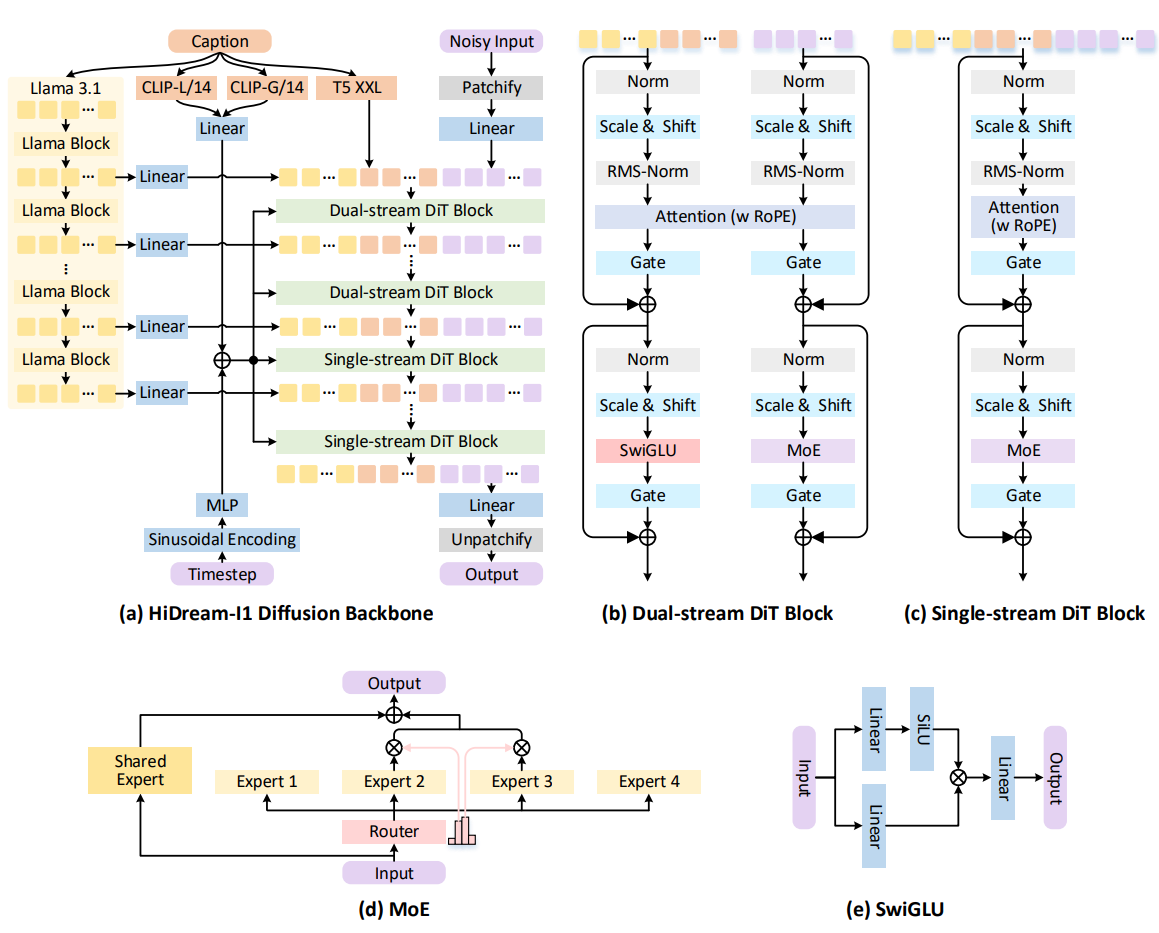
图3|HiDream-I1模型的整体框架。
3. Model Architecture: HiDream-I1
HiDream-I1 是一个基于流匹配(flow matching)原理(参考 Lipman 等,2022)并采用稀疏扩散变换器(Diffusion Transformer, DiT)架构构建的大规模图像生成基础模型。流匹配的目标是通过建模速度场,将一个简单的先验分布(如高斯噪声)连续地映射到一个复杂的数据分布(即目标图像)。
具体来说,我们在一个噪声样本 x0∼N(0,I)x_0 \sim \mathcal{N}(0, I)x0∼N(0,I) 与目标图像 x1x_1x1 之间定义一条路径。这里使用的常见选择是线性插值路径:
xt=(1−t)⋅x0+t⋅x1,t∈[0,1]x_t = (1 - t) \cdot x_0 + t \cdot x_1, \quad t \in [0, 1] xt=(1−t)⋅x0+t⋅x1,t∈[0,1]
对应的恒定速度场为 vt=x1−x0v_t = x_1 - x_0vt=x1−x0。我们的模型以参数 θ\thetaθ 表示,预测该速度场:
u(xt,y,t;θ)u(x_t, y, t; \theta) u(xt,y,t;θ)
其中输入包括带噪图像 xtx_txt、文本嵌入 yyy 和时间步 ttt。训练目标是最小化预测速度与目标速度之间的均方误差:
LFM=Et,x0,x1,y[∥u(xt,y,t;θ)−(x1−x0)∥2](1)\mathcal{L}_{\text{FM}} = \mathbb{E}_{t, x_0, x_1, y} \left[ \| u(x_t, y, t; \theta) - (x_1 - x_0) \|^2 \right] \tag{1} LFM=Et,x0,x1,y[∥u(xt,y,t;θ)−(x1−x0)∥2](1)
核心架构如图3所示,由两个主要模块组成:一个混合文本编码模块,以及一个独特的 DiT 主干结构,融合了稀疏专家混合(Sparse Mixture-of-Experts, MoE)机制。与 SD3(Esser 等,2024)和 FLUX bla(2024)等先前工作类似,HiDream-I1 在潜空间中运行。
3.1. Hybrid Text Encoding
将文本提示准确转换为有效的条件信号对于实现高保真的文本生成图像至关重要。考虑到不同文本编码器架构具有互补优势,HiDream-I1 采用一种混合策略,从四种不同来源整合表示信息:
-
Long-Context CLIP:我们使用扩展上下文版本的 CLIP-L/14 和 CLIP-G/14(Zhang 等,2024),该版本能够处理比标准 CLIP 模型更长的 token 序列。这些模型提供鲁棒、具备全局感知能力的视觉锚定嵌入,通常汇聚成一个向量 hclip∈Rdh_{\text{clip}} \in \mathbb{R}^dhclip∈Rd,用于通过自适应层归一化(adaLN)进行全局条件建模。
-
T5 编码器:采用 T5-XXL 编码器,因其在解析复杂文本结构方面的优势,可生成一系列上下文 token 嵌入 ht5∈RM×dh_{t5} \in \mathbb{R}^{M \times d}ht5∈RM×d。
-
Decoder-only LLM:为捕捉深层语义理解,我们使用仅解码式的大语言模型(如 Llama 3.1 8B Instruct)。关键在于从该 LLM 的多个中间层提取特征,记作 hllm∈RL×M×dh_{\text{llm}} \in \mathbb{R}^{L \times M \times d}hllm∈RL×M×d,其中 LLL 是所提取的层数,MMM 是序列长度,ddd 是特征维度。这种方式保留了细粒度语义信息,避免其在最终层输出中被稀释。
如图3(a)所示,来自 T5 的序列嵌入 ht5h_{t5}ht5 与 LLM 中间层提取的嵌入 hllmh_{\text{llm}}hllm 会被进一步处理(例如通过线性投影),随后拼接形成主文本条件序列 T∈RNT×dT \in \mathbb{R}^{N_T \times d}T∈RNT×d,并输入至 DiT 主干结构中。该多源融合策略为生成过程提供了丰富、全面的文本表征。
3.2. Sparse Diffusion Transformer (DiT) Backbone
HiDream-I1 在分块化的潜在表示上采用了一种新颖的 DiT 架构。该架构起初采用双流结构以独立处理不同模态,随后过渡到单流架构。值得注意的是,稀疏专家混合机制(Mixture-of-Experts, MoE)被集成到初始的双流阶段以及后续的单流阶段。
Dual-stream DiT Blocks. 初始的 DiT 模块采用双流结构,灵感来自 MMDiT(Esser 等,2024),如图3(b)所示。图像 patch token Il∈RNI×dI_l \in \mathbb{R}^{N_I \times d}Il∈RNI×d(由分块化的带噪输入 xtx_txt 得到)和文本 token T∈RNT×dT \in \mathbb{R}^{N_T \times d}T∈RNT×d(由混合编码器生成)在模块内沿各自通路并行处理。这种结构在注意力机制交互前,为每个模态实现了专用的初始特征提取。
Single-stream DiT Blocks. 经过若干双流 DiT 模块(LdualL_{\text{dual}}Ldual)后,架构转变为单流配置。在这一阶段,来自最后一个双流层的图像 token 与文本 token(ILdualI_{L_{\text{dual}}}ILdual / TLdualT_{L_{\text{dual}}}TLdual)沿序列维度拼接,后续所有 Transformer 层(l≥Lduall \ge L_{\text{dual}}l≥Ldual)均在该融合序列上操作。这些单流模块同样集成稀疏 MoE 结构,用于前馈计算。
Sparse Mixture-of-Experts (MoE). HiDream-I1 中的双流与单流 DiT 模块均采用稀疏 MoE 架构,如图3 (c,d) 所示,用以替代传统的稠密前馈网络(FFN)。每个 MoE 块中,一个轻量级路由器网络会根据输入 token 的特征,将其动态分配到一小部分特化 FFN “专家”中。该机制同时允许每个 token 被路由到一个共享专家,如图3 (d) 所示。每个专家模块采用 SwiGLU 激活函数(Shazeer,2020),如图3 (e) 所示。该稀疏激活策略显著扩展了模型容量,同时保持了相较等规模稠密模型的计算效率。
Conditioning and Stability. 全局条件由池化后的 Long-CLIP 特征 hcliph_{\text{clip}}hclip 和正弦时间步嵌入提供,并注入至每个 Transformer 模块中。该过程通过自适应层归一化(adaLN)实现,调控作用于 token 的缩放与偏移参数(即图3 (b,c) 中的 “Scale & Shift” 层)。此外,在自注意力机制中引入了 QK-normalization(Esser 等,2024),以增强训练稳定性。
4. Model Training Strategy
总体而言,HiDream-I1 采用多阶段训练策略,首先在压缩的潜在空间中构建基础生成能力,然后通过后续阶段提升图像质量、语义对齐性以及用户偏好一致性。整个过程基于潜空间流匹配(Latent Flow Matching),主要包括两个阶段:多分辨率预训练与后处理对齐微调。
4.1. Pre-training Stage
预训练阶段的主要目标是训练稀疏 DiT 主干结构(见第3.2节),以在潜空间中建模从噪声到复杂图像表示的流动过程。
• 潜空间操作(Latent Space Operation):我们使用预训练的 VAE(bla,2024),包含编码器 E\mathcal{E}E 和解码器 D\mathcal{D}D。在数据准备阶段,所有训练图像 X1X_1X1 首先被编码为潜在表示 Z1=E(X1)Z_1 = \mathcal{E}(X_1)Z1=E(X1)。为加快训练速度,这些潜在表示 Z1Z_1Z1 会预先计算并缓存。
• 分辨率递进训练(Progressive Resolution Training):训练开始于由 Z1Z_1Z1 表示的潜在码,其源自调整大小至最大不超过 256×256256 \times 256256×256 分辨率的图像。该阶段训练共进行 600,000 步,单卡批量为 24,图像在缩放过程中保持其原始纵横比。之后,模型权重将使用来源于 512×512512 \times 512512×512 图像的潜在表示初始化训练 200,000 步(单卡批量为 8),并最终使用 1024×10241024 \times 10241024×1024 图像的潜在表示训练最后的 200,000 步(单卡批量为 2)。
• 优化策略(Optimization):模型采用 AdamW 优化器(Loshchilov 和 Hutter,2017)进行训练。初始学习率设为 0.0001,包含1000步的线性预热阶段,之后根据需要进行衰减。训练过程中使用 Fully Sharded Data Parallel(FSDP,Paszke,2019)、混合精度训练以及梯度检查点机制以实现高效训练。
4.2. Post-Training Stage
我们进一步引入精调阶段,以提升提示语对齐度、美学质量和用户偏好一致性。模型在一组高质量人工标注的图文对上进行微调。该数据集中的图像具有更高的美学质量和丰富的结构,图文对齐关系也经过人工标注者验证。模型微调共进行 20,000 步,学习率设为 0.00001,使用全局批量大小为 64。
5. Inference Acceleration via GAN-powered Diffusion Model Distillation
经过完整训练的 HiDream-I1 模型(记作 HiDream-I1-Full)在生成过程中通常需要约50个采样步,这可能会限制其实时应用能力。为缓解这一问题,我们采用知识蒸馏技术(Yin 等,2024),将全模型蒸馏为两个采样步更少的加速版本:HiDream-I1-Dev(目标步数为28)和 HiDream-I1-Fast(目标步数为16)。
扩散模型蒸馏过程训练学生模型(HiDream-I1-Dev 与 HiDream-I1-Fast)以逼近教师模型(HiDream-I1-Full)在更少采样步下的生成函数。我们采用 DMD(Yin 等,2024)作为主要蒸馏目标函数 LDMD\mathcal{L}_{\text{DMD}}LDMD。DMD 的目标是使学生模型预测的轨迹分布与教师模型保持一致,从而在更少步数下实现稳定生成。
为了在加速模型中维持高感知质量与图像锐度,我们在 DMD 损失基础上引入对抗训练目标 Ladv\mathcal{L}_{\text{adv}}Ladv。学生模型(生成器)与判别器网络同时训练,判别器用于判断学生生成的图像(通过解码器 D\mathcal{D}D 生成)与真实图像的相似度。判别器利用教师模型骨干提取的多层特征进行判别分类。
最终,该基于 GAN 的蒸馏训练目标为两项损失的加权和:
Ltotal=LDMD+λadvLadv\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{DMD}} + \lambda_{\text{adv}} \mathcal{L}_{\text{adv}} Ltotal=LDMD+λadvLadv
6. Extension for Image Editing: HiDream-E1
接下来,我们展示如何将 HiDream-I1 框架扩展为支持基于指令的图像编辑,从而根据文本编辑指令 yyy 对源图像 XSX_SXS 进行修改。
为了实现视觉上依赖于原图的编辑,我们采用一种提供强“上下文内”视觉条件的方法。在微调过程中,源图像 XSX_SXS 和目标图像 XTX_TXT(即将指令 yyy 应用于 XSX_SXS 所得到的结果)被编码至 VAE 潜空间中,得到潜在表示 (ZS,ZT)(Z_S, Z_T)(ZS,ZT)。这两个潜在图在空间上并排拼接。随后,模型通过潜空间流匹配训练,以生成目标潜在图 ZTZ_TZT,其条件为源潜图 ZSZ_SZS(即视觉上下文)与编辑指令 yyy。
为了促使模型聚焦于与指令相关的修改区域,我们引入了一种空间加权损失函数(LEdit-Weighted\mathcal{L}_{\text{Edit-Weighted}}LEdit-Weighted)。该损失函数对潜空间中 ZTZ_TZT 与 ZSZ_SZS 差异较大的区域分配更高的权重,从而优先优化编辑区域的生成质量,同时帮助保持源图像提供的不变视觉上下文。
该基于指令的图像编辑模型称为 HiDream-E1,是在预训练的 HiDream-I1 基础上微调得到的,使用了一个包含500万条三元组(源图像、编辑指令、目标图像)的数据集。在推理阶段,用户输入源图像和编辑指令,模型即可利用已学习的上下文编辑能力生成相应修改后的图像。
7. Extension for Image Agent: HiDream-A1
我们进一步介绍全新的图像智能体 HiDream-A1(部署于 vivago.ai),这是一个统一的多模态智能体系统,旨在在对话式 AI 接口中无缝整合文本生成图像、图像编辑与交互式理解功能。它使用户能够通过自然语言对话完成复杂的视觉内容创作与操作。图4展示了图像智能体的交互界面,并提供了两个示例,分别对应文本生成图像与基于指令的图像编辑任务。
具体而言,图像智能体的处理流程起始于用户输入(User Input),其支持自然语言输入与图像输入。该输入首先由协调模块(Coordinator)接收,Coordinator 是管理整个流程的核心枢纽。该模块负责判断任务类型是图像生成类(Generation),还是对话交互类(Chat)。
若任务属于图像生成类,系统会调用规划模块(Planner)制定满足用户请求的执行计划。例如,针对具体任务,Planner 可能调用图像生成器(HiDream-I1)执行文本生成图像任务,或调用图像编辑器(HiDream-E1)执行基于指令的图像编辑任务。
若任务属于对话交互类,则智能体将与用户展开对话交互。
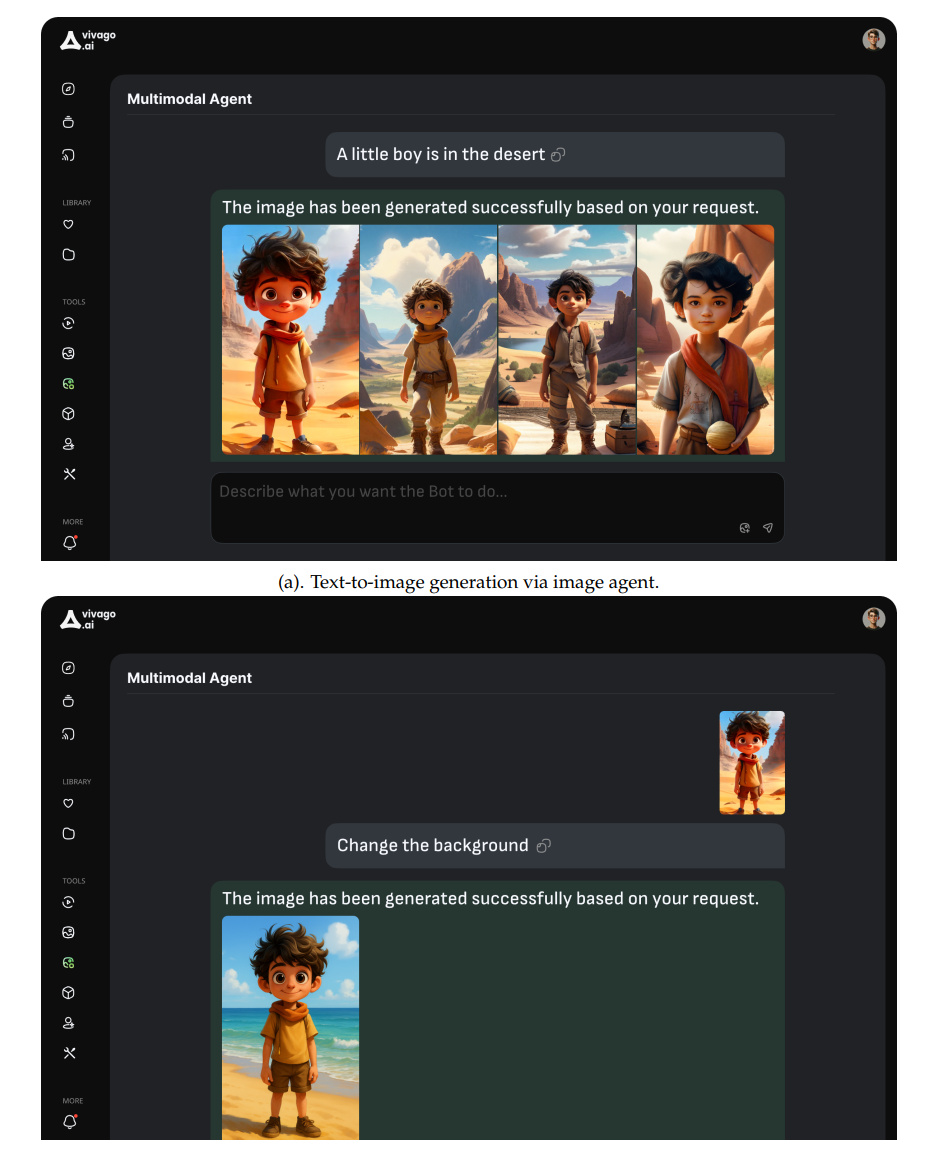
图4|vivago.ai 上图像智能体的交互界面。
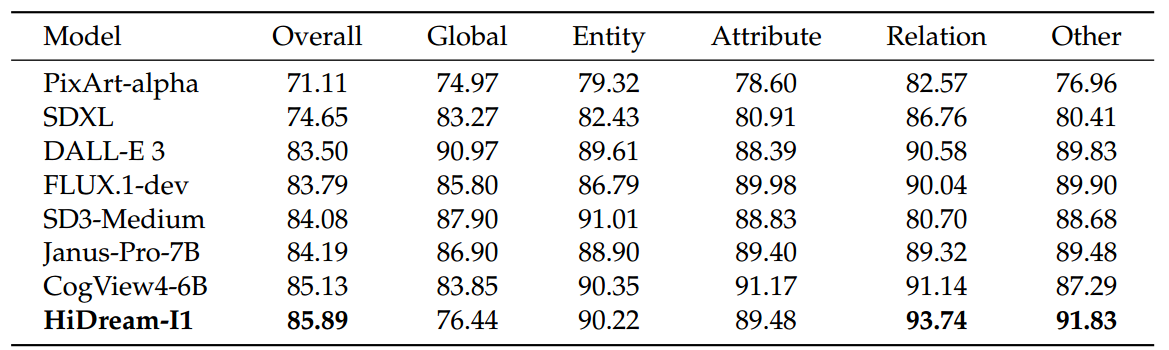
表1|DPG-Bench上的评估结果。分数表示提示对齐准确率(%)。数值越高越好。