GRU模型
一.前言
通过本章节学习我们要了解GRU内部结构及计算公式.,掌握Pytorch中GRU⼯具的使⽤.以及了解GRU的优势与缺点。
二.GRU介绍
GRU(Gated Recurrent Unit)也称⻔控循环单元结构, 它也是传统RNN的变体, 同LSTM⼀样能够有效捕捉⻓序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时它的结构和计算要⽐LSTM更简单, 它的核⼼结构可以 分为两个部分去解析:
更新⻔
重置⻔
三.GRU结构分析
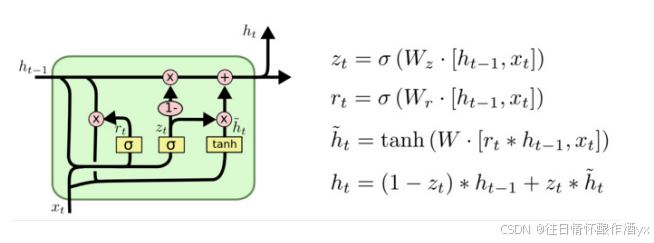
结构解释图:
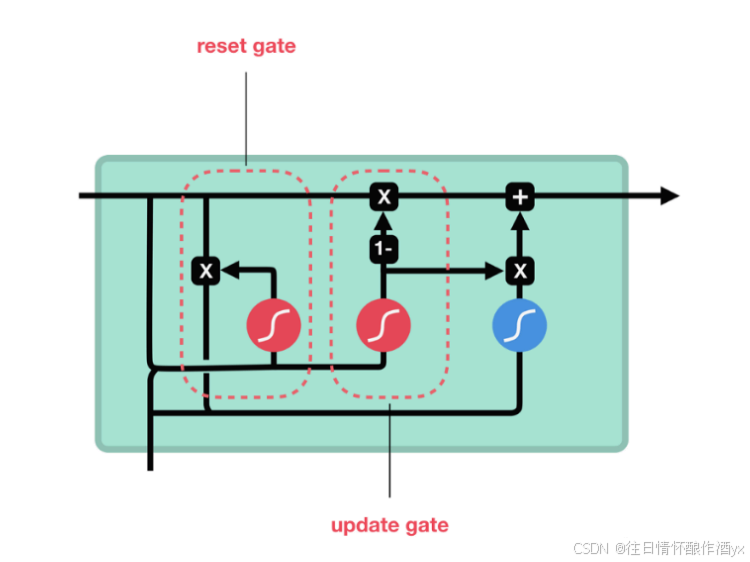
RU的更新⻔和重置⻔结构图:
内部结构分析:
和之前分析过的LSTM中的⻔控⼀样, ⾸先计算更新⻔和重置⻔的⻔值, 分别是z(t)和r(t), 计算⽅法 就是使⽤X(t)与h(t-1)拼接进⾏线性变换, 再经过sigmoid激活. 之后重置⻔⻔值作⽤在了h(t-1)上, 代表控制上⼀时间步传来的信息有多少可以被利⽤. 接着就是使⽤这个重置后的h(t-1)进⾏基本的 RNN计算, 即与x(t)拼接进⾏线性变化, 经过tanh激活, 得到新的h(t). 最后更新⻔的⻔值会作⽤在新 的h(t),⽽1-⻔值会作⽤在h(t-1)上, 随后将两者的结果相加, 得到最终的隐含状态输出h(t), 这个过 程意味着更新⻔有能⼒保留之前的结果, 当⻔值趋于1时, 输出就是新的h(t), ⽽当⻔值趋于0时, 输 出就是上⼀时间步的h(t-1).
四.Bi-GRU介绍
Bi-GRU与Bi-LSTM的逻辑相同, 都是不改变其内部结构, ⽽是将模型应⽤两次且⽅向不同, 再将两次得到的 LSTM结果进⾏拼接作为最终输出. 具体参⻅上章节中的Bi-LSTM.
五.使用Pytorch构建GRU模型
位置: 在torch.nn⼯具包之中, 通过torch.nn.GRU可调⽤.
nn.GRU类初始化主要参数解释:
input_size: 输⼊张量x中特征维度的⼤⼩.
hidden_size: 隐层张量h中特征维度的⼤⼩.
num_layers: 隐含层的数量.
bidirectional: 是否选择使⽤双向LSTM, 如果为True, 则使⽤; 默认不使⽤.
nn.GRU类实例化对象主要参数解释:
input: 输⼊张量x.
h0: 初始化的隐层张量h.
nn.GRU使⽤示例:
# 导入PyTorch库
import torch
import torch.nn as nn # 神经网络模块# 定义一个GRU(门控循环单元)网络
# 参数说明:
# 5: input_size - 输入特征的维度(每个时间步输入向量的长度)
# 6: hidden_size - 隐藏层特征的维度(GRU输出的向量长度)
# 2: num_layers - GRU的层数(堆叠的层数)
rnn = nn.GRU(5, 6, 2)# 定义输入张量
# 参数说明:
# 1: sequence_length - 序列长度(时间步数)
# 3: batch_size - 批次大小
# 5: input_size - 输入特征的维度
input = torch.randn(1, 3, 5) # 随机生成输入数据# 定义初始隐藏状态
# 参数说明:
# 2: num_layers * num_directions(单向GRU,所以num_directions=1)
# 3: batch_size
# 6: hidden_size
h0 = torch.randn(2, 3, 6) # 随机初始化隐藏状态# 前向传播计算
# 输入:input和初始隐藏状态h0
# 输出:
# output: 所有时间步的输出 (seq_len, batch_size, hidden_size)
# hn: 最后一个时间步的隐藏状态 (num_layers, batch_size, hidden_size)
output, hn = rnn(input, h0)# 打印输出结果
print("Output shape:", output.shape) # 预期输出形状:(1, 3, 6)
print(output) # 打印所有时间步的输出(本例中只有一个时间步)print("\nFinal hidden state shape:", hn.shape) # 预期形状:(2, 3, 6)
print(hn) # 打印最终隐藏状态六.GRU优缺点
GRU的优势:
GRU和LSTM作⽤相同, 在捕捉⻓序列语义关联时, 能有效抑制梯度消失或爆炸, 效果都优于传统 RNN且计算复杂度相⽐LSTM要⼩.
GRU的缺点:
GRU仍然不能完全解决梯度消失问题, 同时其作⽤RNN的变体, 有着RNN结构本身的⼀⼤弊端, 即 不可并⾏计算, 这在数据量和模型体量逐步增⼤的未来, 是RNN发展的关键瓶颈.
七.总结
本章节学习了GRU的结构以及代码实现等等,就不过多的给大家总结了,期待大家的点赞关注加收藏。