hadoop(服务器伪分布式搭建)
1. 报错 Windows 上写的脚本 拷贝到 Linux(比如 CentOS)系统时会出现。
bash: ./set_java_home.sh: /bin/bash^M: bad interpreter: No such file or directory
报错原因
^M 是 Windows 的换行符(\r\n)
Linux 使用的是 Unix 格式的换行符(\n)
所以你的脚本第一行的 #!/bin/bash 实际上变成了:
#!/bin/bash^M
解决方法把脚本转换为 Unix 格式
使用 dos2unix 命令
dos2unix set_java_home.sh
##如果没有下面就是安装命令
yum install dos2unix -y
2. 解决centos里面多版本java,统中默认的 Java(通过 alternatives 指定的)自动同步到 JAVA_HOME,以保证一致性。
#!/bin/bash# 配置你的 Java 安装路径(按你提供的内容)
JAVA8_PATH="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.412.b08-1.el7_9.x86_64"
JAVA11_PATH="/usr/lib/jvm/java-11-openjdk-11.0.23.0.9-2.el7_9.x86_64"# 参数校验
if [[ $1 == "8" ]]; thenecho "🔄 正在切换到 Java 8..."sudo alternatives --set java $JAVA8_PATH/jre/bin/javasudo alternatives --set javac $JAVA8_PATH/bin/javacexport JAVA_HOME=$JAVA8_PATH
elif [[ $1 == "11" ]]; thenecho "🔄 正在切换到 Java 11..."sudo alternatives --set java $JAVA11_PATH/bin/javasudo alternatives --set javac $JAVA11_PATH/bin/javacexport JAVA_HOME=$JAVA11_PATH
elseecho "❌ 参数错误,请输入 8 或 11,例如:"echo " source ./switch-java.sh 8"echo " source ./switch-java.sh 11"return 1
fi# 清理旧 PATH 中的 JAVA_HOME 相关路径
export PATH=$(echo "$PATH" | awk -v RS=: -v ORS=: '/java/ {next} {print}' | sed 's/:$//')# 加入新 JAVA_HOME/bin
export PATH=$JAVA_HOME/bin:$PATH# 显示结果
echo "✅ 已切换至 JAVA_HOME: $JAVA_HOME"
java -version##到对应位置运行这个脚本,前面加上source,就是全局运行,不加的话就是在一个进程里面运行,检查的时候可能检查不到
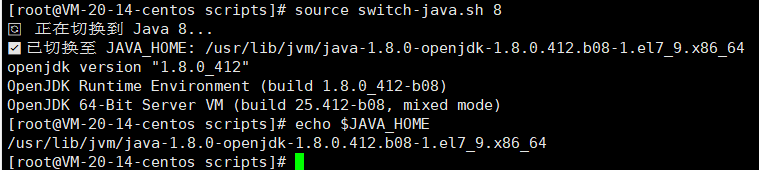
source switch-java.sh 8
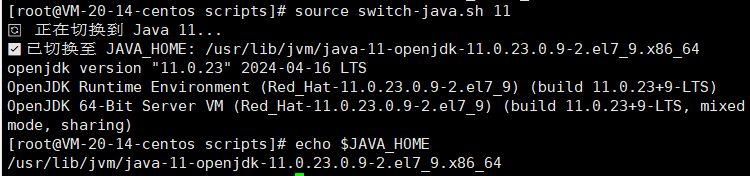
source switch-java.sh 11
##检查命令
echo $JAVA_HOME
下图是切换Java8的source scripts/switch-java.sh 8
下图是切换java11的source scripts/switch-java.sh 11
设置重新启动服务器,以后默认的环境变量中的java的版本
vim ~/.bashrc
##添加
# 每次登录自动设置 Java 8 为默认(你自己上面脚本存放的位置)
source $HOME/scripts/switch-java.sh 8
或
# 每次登录自动设置 Java 11 为默认$HOME指的是根目录root
source $HOME/scripts/switch-java.sh 11
# 最后执行
source ~/.bashrc
Hadoop
安装教程
官网链接:https://hadoop.apache.org/releases.html
不同的安装包的区别
| 文件名 | 含义 |
|---|---|
| source | 源码包,需要你自己编译(不推荐初学者) |
| binary | 官方编译好的二进制包(✅推荐) |
| binary-aarch64 | 针对 ARM 架构的电脑(如苹果 M1/M2、树莓派) |
| binary-lean | 精简版本(一般不推荐) |
推荐下载的安装包:Hadoop 3.3.6 binary
下载地址:https://downloads.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
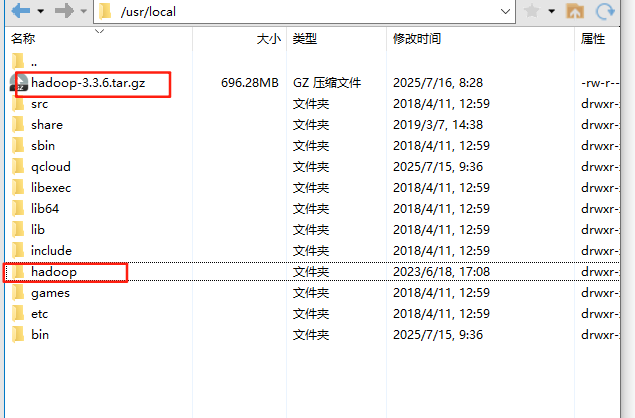
下载完成后上传到服务器
我上传的目录是/usr/local
cd /usr/local/
tar -zxvf hadoop-3.3.6.tar.gz
mv hadoop-3.3.6 hadoop
执行完上述命令后Hadoop 安装路径是 /usr/local/hadoop
配置环境变量配置文件
vim ~/.bashrc
#把下面的内容写到配置文件里面
#我的java已经配置了,不需要配置java了如图
# Hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

#让配置文件生效重新加载
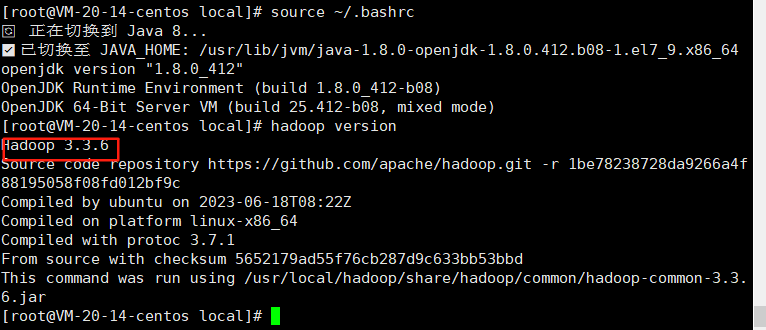
source ~/.bashrc
#测试是否生效,如下图已经安装完成
hadoop version
hadoop理解
干嘛用的:
是为了解决“单机无法处理超大数据”的问题,通过“分布式存储(HDFS)+ 分布式计算(MapReduce)”来高效地处理海量数据。
用于存储和处理超大规模数据(TB、PB 级别)。
原理:
1.把大文件切成小块分布存储在多台机器上(HDFS)
2.把任务拆成小任务并行处理,最后汇总结果(MapReduce)
核心组件与原理图解
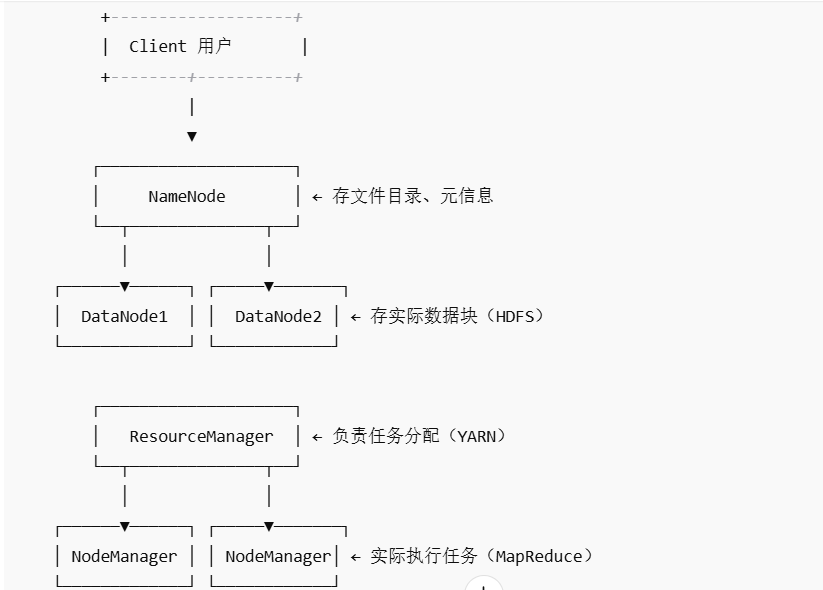
Hadoop 核心原理组件解释
| 组件 | 功能 |
|---|---|
| HDFS | 分布式文件系统,把大文件切成块存到多台机器,每块默认保存 3 份(容错) |
| MapReduce | 分布式计算框架,把任务拆成 map → shuffle → reduce,分布式并行处理 |
| YARN | 资源调度框架,决定哪些机器执行哪些任务 |
| NameNode | HDFS 中的“总目录”,保存文件结构、块位置(元数据) |
| DataNode | 实际存储数据块的节点 |
| ResourceManager | 管理所有节点资源,分配任务 |
| NodeManager | 每个节点的“本地资源控制器”,接收任务并执行 |
应用场景:分布式存储和海量数据计算,用在“大数据”场景下。
| 场景 | 描述 |
|---|---|
| 日志分析 | 网站、APP、大型平台的用户访问日志分析(TB 级) |
| 数据仓库(Hive) | 用 SQL 处理海量结构化数据 |
| ETL 处理(+Sqoop) | 数据抽取(从 MySQL 导入)、转换、加载 |
| 搜索引擎爬虫 | 把抓取网页分布式处理、存储 |
| 图像视频处理 | 多节点同时处理图片/视频数据(如压缩、转码) |
| 机器学习预处理 | 对大规模训练数据进行 MapReduce 处理 |
| 互联网企业分析系统 | 淘宝、百度、腾讯、头条等早期都用了 Hadoop 搭建离线数据处理平台 |
Hadoop优势
| 优势 | 说明 |
|---|---|
| 高可扩展 | 加机器就能扩容(线性扩展) |
| 高容错 | 自动备份副本,节点宕了也不会丢数据 |
| 大规模处理 | 支持 TB/PB 级别数据处理 |
| 高性价比 | 可用普通商用服务器构建分布式平台 |
| 开源生态丰富 | Hive、Spark、HBase、Flink 都能集成 Hadoop 存储 |
不适合的地方
| 不适合场景 | 说明 |
|---|---|
| 实时计算(ms 级) | Hadoop 是离线批处理,延迟分钟级 |
| 小数据场景 | 启动 MapReduce 比处理本身还慢 |
| 高频低延迟系统 | 比如金融交易系统、秒杀系统,不适合 Hadoop |
| 高并发 OLTP | Hadoop 不支持事务处理和高并发读写操作 |
运行模式
| 模式 | 是否需要配置 XML | 是否需要创建 tmp、namenode、datanode 等目录 | 是否需要启动服务 |
|---|---|---|---|
| 1. 本地模式(Local Mode) | ❌ 不需要 | ❌ 不需要 | ❌ 不需要 |
| 2. 伪分布式模式 | ✅ 需要 | ✅ 必须创建 | ✅ 启动 HDFS/YARN |
| 3. 真分布式模式 | ✅ 需要 | ✅ 必须创建(不同节点) | ✅ 启动多节点服务 |
hadoop部署伪分布式
第一步创建 Hadoop 所需的工作目录
mkdir -p /usr/local/hadoop/tmp
mkdir -p /usr/local/hadoop/hdfs/namenode
mkdir -p /usr/local/hadoop/hdfs/datanode
| 目录 | 作用 |
|---|---|
/usr/local/hadoop/tmp | Hadoop 运行时的临时文件目录(如锁文件、缓存) |
/usr/local/hadoop/hdfs/namenode | 存储 NameNode 元数据(如文件目录结构、块位置) |
/usr/local/hadoop/hdfs/datanode | 存储 DataNode 的实际数据块(HDFS 文件数据) |
NameNode 认为 /usr/local/hadoop/hdfs/namenode 是它的持久存储位置。
DataNode 把数据块写入 /usr/local/hadoop/hdfs/datanode。
tmp 用来缓存、写日志、写运行时中间文件。
第 2 步:编辑配置文件
配置文件路径:/usr/local/hadoop/etc/hadoop/
2.1. core-site.xml
vim /usr/local/hadoop/etc/hadoop/core-site.xml
内容:需要外部访问配置hdfs://主机名称:9000
<configuration><property><name>fs.defaultFS</name><value>hdfs://主机名称(或者是你的ip注意要和下面的文件中的保持一致):9000</value></property><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop/tmp</value></property>
</configuration>
2.2 hdfs-site.xml
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
内容:
<configuration><!-- 设置副本数为1(伪分布式) --><property><name>dfs.replication</name><value>1</value></property><!-- NameNode 存储目录 --><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/hdfs/namenode</value></property><!-- DataNode 存储目录 --><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/hdfs/datanode</value></property><!-- DataNode 注册使用公网IP(重要) --><property><name>dfs.datanode.hostname</name><value>你自己的主机名称或者是ip</value></property><!-- DataNode 与客户端通信使用 hostname(IP) --><property><name>dfs.datanode.use.datanode.hostname</name><value>true</value></property><!-- 客户端使用 hostname(IP) 访问 DataNode --><property><name>dfs.client.use.datanode.hostname</name><value>true</value></property><!-- 开放 NameNode RPC(绑定到所有网卡) --><property><name>dfs.namenode.rpc-bind-host</name><value>0.0.0.0</value></property><!-- 可选:关闭主机名校验,允许 IP 注册 --><property><name>dfs.namenode.reject-unresolved-datanode-hostname</name><value>false</value></property></configuration>2.3 mapred-site.xml
vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
内容:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>2.4 yarn-site.xml
vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
内容:
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>第三步配置免密登录
ssh-keygen -t rsa # 全部回车
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
ssh localhost # 确保不需要输入密码
第四步:格式化 HDFS(只做一次)
hdfs namenode -format
#后面如果再需要格式化需要关闭这两个
stop-dfs.sh
stop-yarn.sh
第五步:启动命令
#停止命令
stop-dfs.sh
#启动命令
start-dfs.sh
start-yarn.sh
#jps用于列出当前系统中所有的HotSpot Java虚拟机进程
jps # 查看服务是否正常## 报错
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
#你在用 root 用户执行 start-dfs.sh 命令
#Hadoop 默认不允许你用 root 来启动 HDFS 守护进程(安全考虑)## 下面是解决方法 以及其他命令
#创建用户
useradd hadoop
passwd hadoop
#把Hadoop 安装目录权限改给 hadoop 用户:
chown -R hadoop:hadoop /usr/local/hadoop
#给hadoop用户赋予sudo权限(centos7)
usermod -aG wheel hadoop
#其他关于防火墙的命令可选
sudo firewall-cmd --permanent --add-port=9000/tcp
sudo firewall-cmd --reload
sudo firewall-cmd --list-ports
#切换用户
su - hadoop
vim ~/.bashrc #编辑,不同用户不同的环境变量文件
#切换完用户后从新配置java和hadoop的环境变量(如下图)
#我Java的环境变量是一个脚本文件(Java8 和java11需要切换),根据自己的需求配置
#保存后再执行(让配置文件生效)
source ~/.bashrc
#验证是否生效
echo $JAVA_HOME
echo $HADOOP_HOME
which hadoop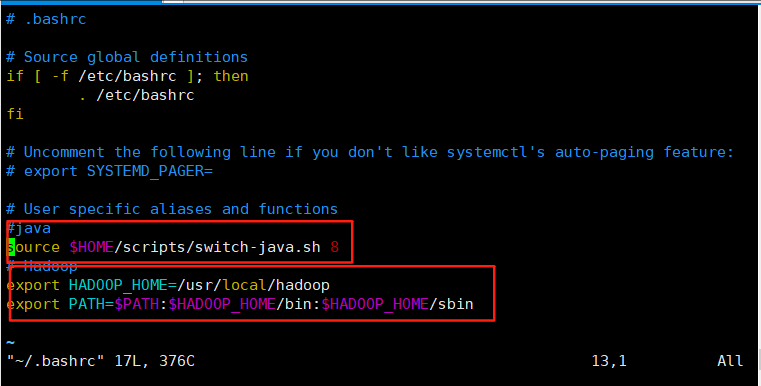
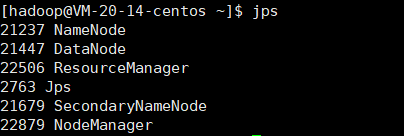 总总结:hadoop是什么,是用来处理海量数据的,然后有两大核心模块,一个就是,分布式文件HDFS(Hadoop Distributed File System),里面有两种节点NameNode和DataNode ,HDFS会把一个大文件分成块(block默认大小是128MB)每个块会有多个副本存在不同的服务器上(默认3个),具体的内容存在DataNode里面,而NameNode相当于DataNode的目录。
总总结:hadoop是什么,是用来处理海量数据的,然后有两大核心模块,一个就是,分布式文件HDFS(Hadoop Distributed File System),里面有两种节点NameNode和DataNode ,HDFS会把一个大文件分成块(block默认大小是128MB)每个块会有多个副本存在不同的服务器上(默认3个),具体的内容存在DataNode里面,而NameNode相当于DataNode的目录。
hadoop操作上传,下载,读取文件的命令
#查看HDFS的根目录
hdfs dfs -ls /
# 创建用户目录
hdfs dfs -mkdir -p /user/hadoop
# 创建临时目录(某些程序可能会用到)
hdfs dfs -mkdir /tmp
# 设置临时目录权限为 777(某些程序依赖)
hdfs dfs -chmod -R 777 /tmp上传文件
hdfs dfs -put /本地路径/文件名 /HDFS目标路径
#列子
hdfs dfs -put /home/hadoop/files/剑来01.mp4 /user/hadoop/
#查看是否上传成功
hdfs dfs -ls /user/hadoop/

# 查看文件块和位置
hdfs fsck /user/hadoop/剑来01.mp4 -files -blocks -locations
输出:
Status: HEALTHY
# ✅ 文件健康,未缺块、未损坏Number of data-nodes: 1
# 📦 当前集群中只有1个 DataNode(单节点伪分布式)Number of racks: 1
# 📶 当前仅配置了1个机架(Rack)Total dirs: 0
# 📁 总共目录数量为0(因为只检查了一个文件)Total symlinks: 0
# 🔗 符号链接数量为0(HDFS中很少使用符号链接)Replicated Blocks:Total size: 2655188930 B# 📄 文件总大小约 2.65GBTotal files: 1# 📁 本次检查的文件数量Total blocks (validated): 20 (avg. block size 132759446 B)# 📦 文件被切分为20个块,每个块平均约132MB(符合HDFS默认128MB)Minimally replicated blocks: 20 (100.0 %)# ✅ 所有块至少有1个副本,符合设定的副本数Over-replicated blocks: 0 (0.0 %)# 📈 没有副本数量超出配置的块Under-replicated blocks: 0 (0.0 %)# 📉 没有副本数量不足的块Mis-replicated blocks: 0 (0.0 %)# ⚠️ 块没有分布不合理(如所有副本都集中在同一节点)的问题Default replication factor: 1# 🔁 当前系统默认副本数为1(单节点无法设置更高)Average block replication: 1.0# 📊 所有块平均有1个副本Missing blocks: 0# ❌ 没有缺失的块Corrupt blocks: 0# ❌ 没有损坏的块Missing replicas: 0 (0.0 %)# ❌ 所有副本都存在,没有副本缺失Blocks queued for replication: 0# 📋 没有等待复制的块(说明副本充足)Erasure Coded Block Groups:Total size: 0 BTotal files: 0Total block groups (validated): 0Minimally erasure-coded block groups: 0Over-erasure-coded block groups: 0# ✳️ 未使用 Erasure Coding(纠删码),这是一种高级存储方式,用于节省空间,当前未启用# 查看集群副本默认配置
hdfs getconf -confKey dfs.replication
# 输出文件大小
hdfs dfs -du -h /user/hadoop/
#下载
hdfs dfs -get /user/hadoop/剑来01.mp4 ./
#预览内容
#查看文件的开头
hdfs dfs -cat /user/hadoop/data1.txt | head
#查看结尾(日志)
hdfs dfs -tail /user/hadoop/log.txt
#查看前几行
hdfs dfs -cat /user/hadoop/data2.csv | head -n 5
#过滤
hdfs dfs -ls /user/hadoop/ | grep '\.csv'
#查找
hdfs dfs -find / -name "*.csv"
#查找特定名字
hdfs dfs -find / -name "data2025-*.txt"
#删除
hdfs dfs -rm /user/hadoop/剑来01.mp4
#用 hdfs dfs -ls 查看上传了哪些文件
#用 -cat、-tail、head 查看内容判断是不是你要的
#用 -du -h 看大小,或 grep / find 辅助筛选Hadoop端口介绍
| 端口 | 类型 | 服务 | 用法 | 是否浏览器能访问 |
|---|---|---|---|---|
9000 | RPC通信端口 | NameNode | Hadoop 命令通信(如 put、get、ls) | ❌ 不行,后台服务端口 |
9870 | Web UI | NameNode Web | 浏览 HDFS 目录、查看块位置 | ✅ 可以 |
9864 | Web UI | DataNode Web | 查看 DataNode 状态和数据块 | ✅ 可以 |
8088 | Web UI | YARN ResourceManager | 查看作业运行状态 | ✅ 可以 |
hadoop安全模式
重新启动的时候会进入到安全模式
# 查看安全模式状态
hdfs dfsadmin -safemode get
#强制退出安全模式
hdfs dfsadmin -safemode leave
# 输出示例:
# Safe mode is ON
# 或
# Safe mode is OFF