Selenium自动化浏览器操作指南
驱动真实浏览器(如Chrome、Firefox)模拟用户操作,且浏览器可以实现页面的渲染,因此我们很容易获得选然后的数据信息。(说明这里我们得到的是’检查‘得到的内容)
一 准备工作
selenium可以驱动内核,但我们还是要安装对应版本的浏览器的内核驱动程序以便于更好的驱动浏览器。下面我们来安装下WebDriver
第一步 先查看我们电脑的浏览器版本号(不同浏览器的驱动也不一样,我这里是edge)
在右上角有三个点,下面可以看到关于Microsoft Edfe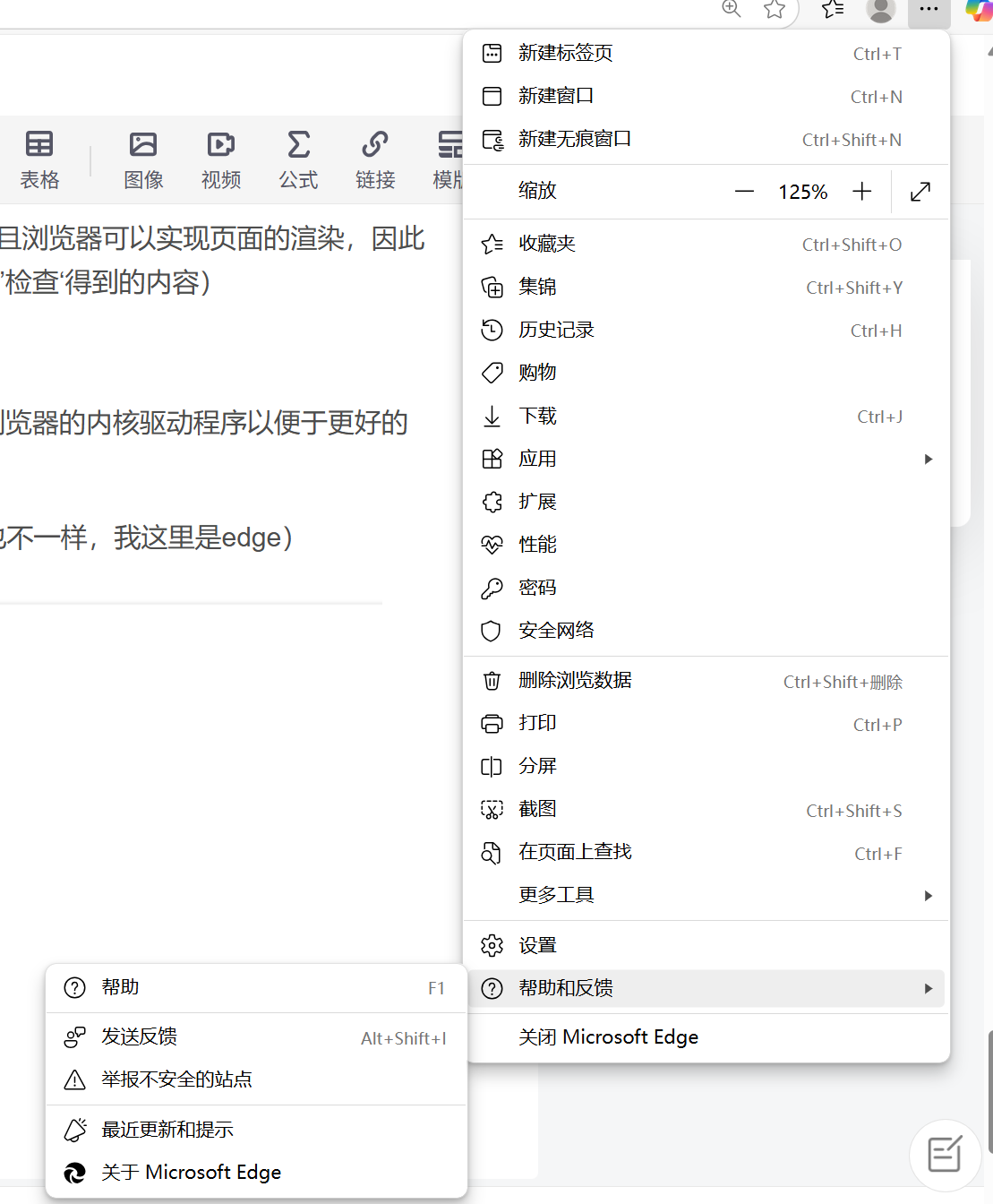

然后可以查看到,我的浏览器内核版本为138.0.3351.95
第二步 去官网下载
Microsoft Edge WebDriver | Microsoft Edge Developer上面可以找到对应版本。一般我们电脑下载x64位就好了
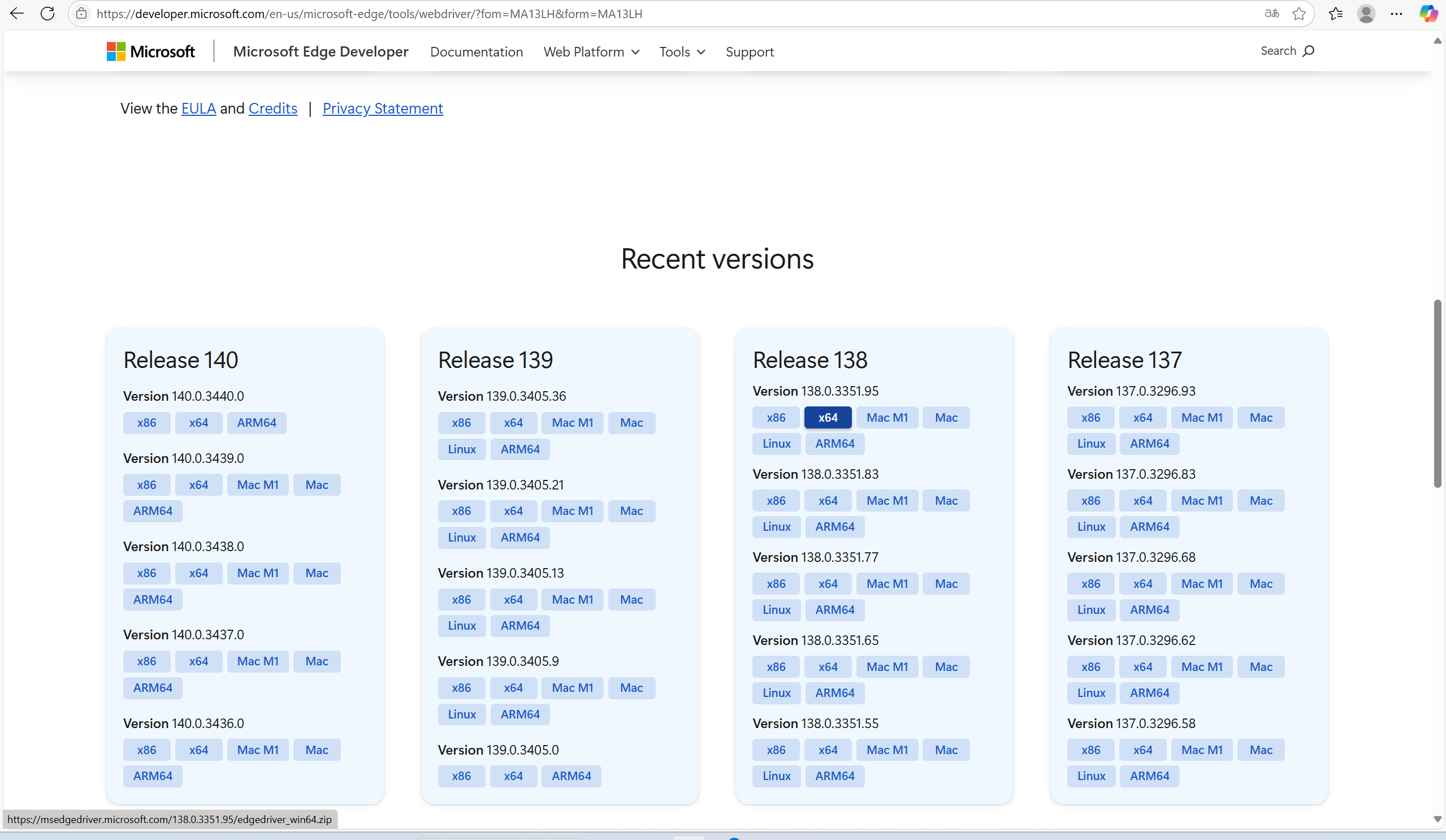
第三步 把msedgedriver放到我们python的Scripts中

(最好scripts中和python所在文件夹中分别放一个)
第四步 下载selenium库
直接在终端pip安装就好
pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple了解selenium操作原理
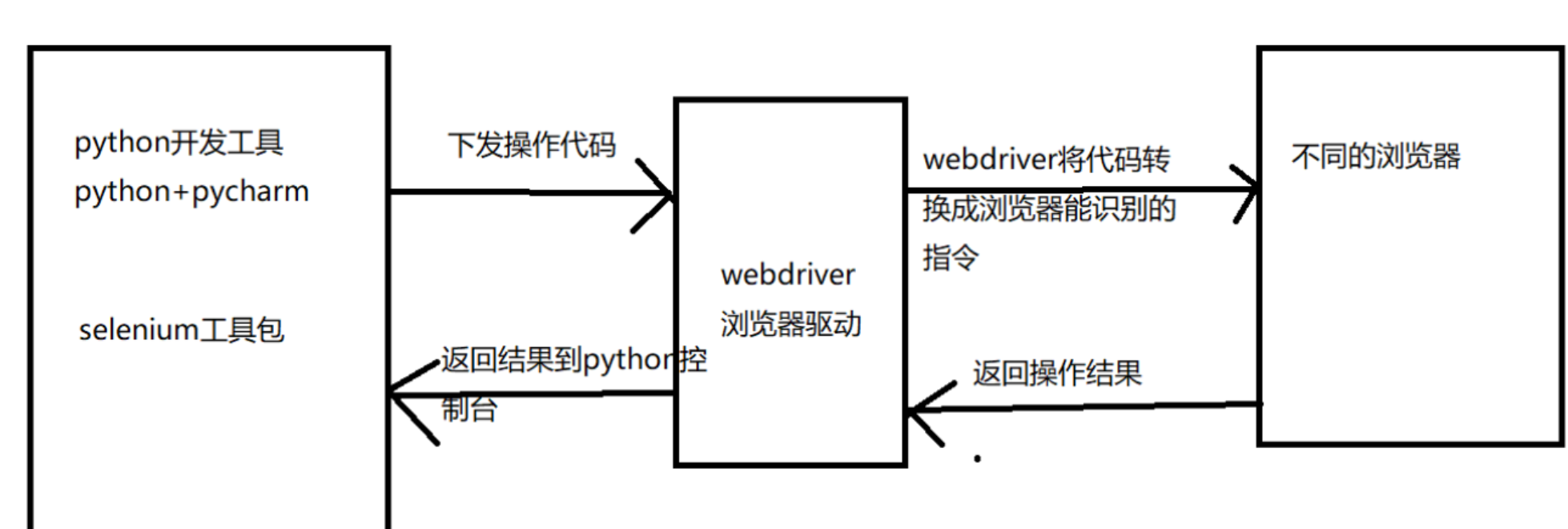
二 驱动浏览器
import time
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
time.sleep(10)- 创建
Options对象后,通过binary_location显式指定Edge浏览器的可执行文件路径 - 创建Edge浏览器实例,传入配置好的
edge_options对象(这里webdriver就是一个类,然后我们的driver就相当于这个类的一个实例化)
这里打开的是一个没有内容的一个网页,然后我最后加了睡眠几秒的目的是为了不让浏览器运行完就退出了。
三 WebDriver类
我们要使用drive,然后这个类又是webdriver的一个实例化。下面我们来学习这个类中存在的一些函数。
1 get()获取页面资源
def get(self, url: str) -> None:"""将浏览器导航到当前窗口或标签页中指定的URL。该方法会阻塞直到页面完全加载(即触发onload事件)。参数:-----------url : str- 要由浏览器打开的URL。- 必须包含协议(例如http://、https://)。示例:-------->>> driver = webdriver.Chrome()>>> driver.get("https://example.com")"""self.execute(Command.GET, {"url": url})我们可以看到,只需要传入一个参数url,就可以转到那个页面了
import time
import requests
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import Byedge_options = Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get("https://www.ptpress.com.cn/shopping/buy?bookId=c1f1792f-d71d-4f2f-bcb4-34fbde839c51")
time.sleep(10)例如上面这个我进入了这个页面,并且停留了十秒
2 page_source()获取页面资源
def page_source(self) -> str:"""获取当前页面的HTML源代码。示例:-------->>> print(driver.page_source)"""return self.execute(Command.GET_PAGE_SOURCE)["value"]无需参数,可以直接得到当前页面渲染后的代码
3 find_element()查找函数
def find_element(self, by=By.ID, value=None):"""在当前页面中查找一个元素。参数:-----------by : By- 定位策略(如By.ID、By.XPATH等)value : str- 定位值返回:-------WebElement- 找到的第一个匹配元素异常:------NoSuchElementException- 如果找不到元素时抛出"""return self.execute(Command.FIND_ELEMENT, {"using": by, "value": value})["value"]这个函数有两个参数,一个是定位策略,一个是定位值
这个函数有许多操作方法
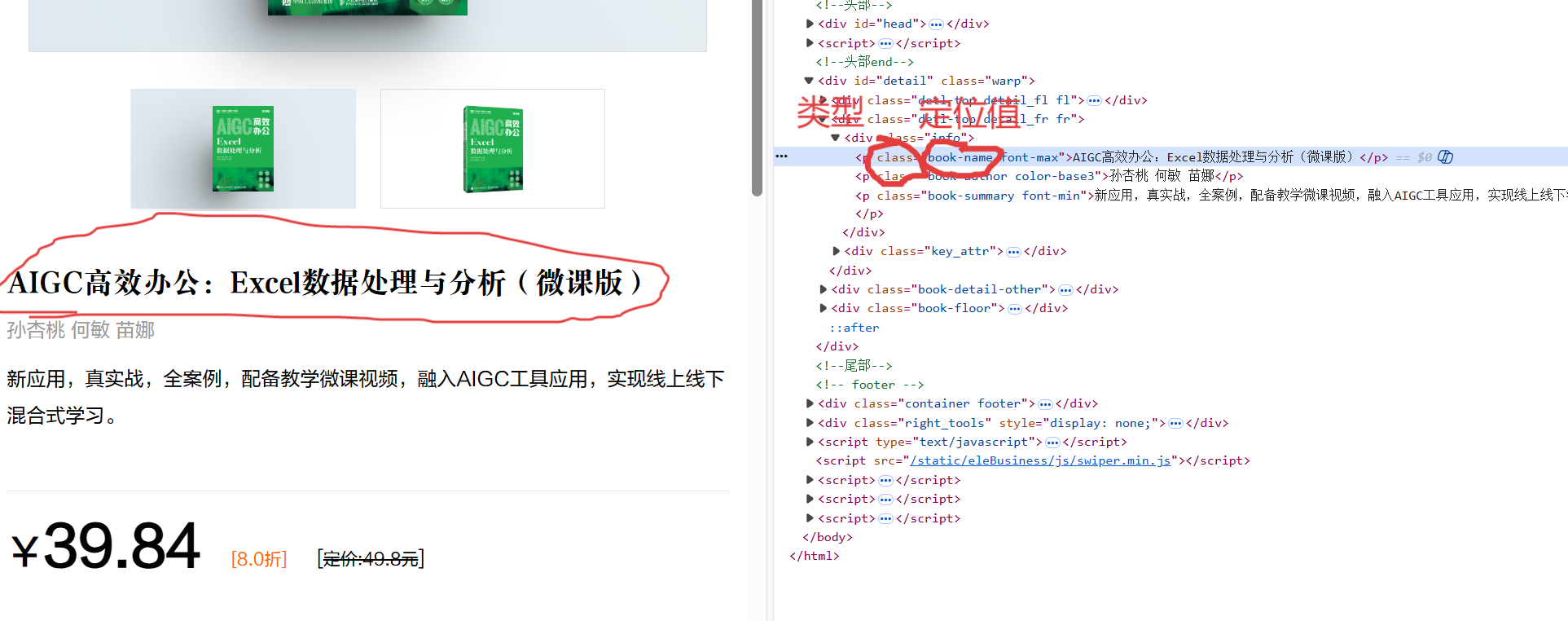
tag_name 获取元素名称,这个应该就是返回标签值
<p class="book-name font-max">AIGC高效办公:Excel数据处理与分析(微课版)</p>返回ptext 获取元素内容
<p class="book-name font-max">AIGC高效办公:Excel数据处理与分析(微课版)</p>
返回AIGC高效办公:Excel数据处理与分析(微课版)click 点击此元素
import time
import requests
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import Byedge_options = Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get("https://www.ptpress.com.cn/shopping/buy?bookId=c1f1792f-d71d-4f2f-bcb4-34fbde839c51")
time.sleep(5)
driver.find_element(By.CLASS_NAME, "cart-btn").click()
time.sleep(3)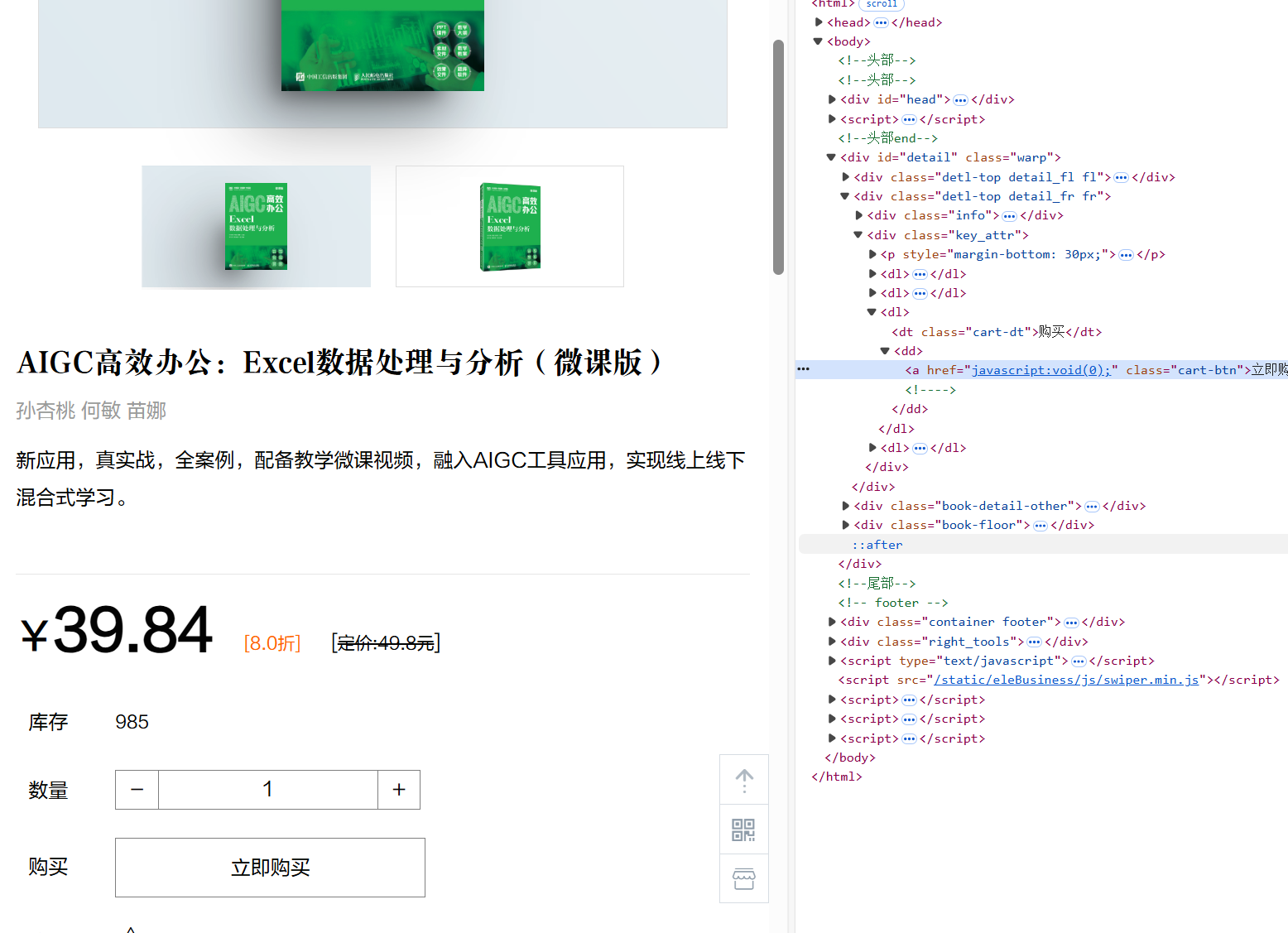
send_keys()
提交信息,这个里面还可以跟参数,例如send_keys('人工智能',Keys.ENTER),后面的Keys.ENTER,是模拟我们键盘敲击enter
import time
import requests
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import Byedge_options = Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get("https://www.ptpress.com.cn/")
driver.find_elements(By.TAG_NAME, "input")[0].send_keys('人工智能',Keys.ENTER)
# a=driver.find_elements_by_tag_name("input")
time.sleep(1000)这个可以实现自动化查找关于人工智能的书。
4 window_handles()返回页面个数
def window_handles(self) -> list[str]:"""返回当前会话中所有浏览器窗口/标签页的句柄列表。每个窗口句柄是由操作系统生成的唯一字符串标识符,用于多窗口切换操作。列表顺序通常与窗口打开顺序一致,最新打开的窗口句柄位于列表末尾[1,6,10](@ref)。示例:-------->>> print(driver.window_handles) # 输出如 ['CDwindow-ABC123', 'CDwindow-XYZ456']典型应用场景:- 点击链接触发新窗口时,需先获取句柄列表再切换[1,7](@ref)- 多窗口操作时跟踪不同页面的焦点状态[8](@ref)- 关闭窗口后需手动切换回有效句柄避免异常[1](@ref)"""return self.execute(Command.W3C_GET_WINDOW_HANDLES)["value"]根据上面源码解释,我们可以知道这个不需要传入参数,可以返回一个列表型数据,里面存放当前每个页面的信息,可以用索引查找
5 switch_to
def switch_to(self) -> SwitchTo:"""返回包含所有焦点切换选项的对象,用于处理多窗口/框架/弹窗等场景。返回值:--------SwitchTo: 提供以下焦点切换方法:- 窗口切换(window_handles管理)- iframe/frame切换- 弹窗处理(alert/confirm/prompt)- 当前活动元素获取典型应用场景:-------------------1. 多窗口管理:>>> handles = driver.window_handles # 获取所有窗口句柄[2,5](@ref)>>> driver.switch_to.window(handles[-1]) # 切换到最新窗口[1,6](@ref)2. 嵌套iframe操作:>>> driver.switch_to.frame("login_frame") # 通过name/id切换[3,4](@ref)>>> driver.switch_to.parent_frame() # 返回父级框架[5,7](@ref)3. 弹窗处理:>>> alert = driver.switch_to.alert # 获取弹窗对象[6,7](@ref)>>> print(alert.text) # 获取弹窗文本[2](@ref)>>> alert.accept() # 确认操作[1](@ref)4. 主文档/活动元素:>>> driver.switch_to.default_content() # 返回主文档[3,5](@ref)>>> active_elem = driver.switch_to.active_element # 获取当前焦点元素[4](@ref)示例:-------->>> # 多窗口切换流程>>> main_handle = driver.current_window_handle>>> driver.find_element(By.LINK_TEXT, "新窗口").click()>>> new_handle = [h for h in driver.window_handles if h != main_handle][0]>>> driver.switch_to.window(new_handle) # 切换到新窗口[2,5](@ref)>>> # 嵌套iframe操作流程>>> driver.switch_to.frame("outer_frame")>>> driver.switch_to.frame("inner_frame") # 多层嵌套需逐层切换[3](@ref)>>> driver.switch_to.parent_frame() # 返回外层frame[7](@ref)"""return self._switch_to看源码介绍知道,这个常常和.window()一起用,这个window()中参数也就是上一个我们得到的页面,然后根据索引,可以达到转换页面的目的。
6 基本操作
back()返回上一个页面
forward()前进到下一个页面
refresh()刷新页面
quit()关闭当前页面
close()关闭浏览器
四 项目实战
我们来实现一个爬取人民邮电出版社中所有excel书的数据,其中包含书名,作者,价格
import re
import time
import requests
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.common.devtools.v136.system_info import get_info
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import Bydef fun(driver):time.sleep(1)ls=driver.find_elements(By.CLASS_NAME, "book_item")for item in ls:item.click()time.sleep(3)handles = driver.window_handlesdriver.switch_to.window(handles[-1])time.sleep(1)name=driver.find_element(By.CLASS_NAME, "book-name").textprice=driver.find_element(By.CLASS_NAME, "price").textauthor=driver.find_element(By.CLASS_NAME, "book-author").textprint(name,price,author)file.write('图书名:{0},价格:{1},作者:{2}\n'.format(name,price,author))driver.close()handles = driver.window_handlesdriver.switch_to.window(handles[-1])file=open('book.txt','w')
edge_options = Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get("https://www.ptpress.com.cn/")
driver.find_elements(By.TAG_NAME, "input")[0].send_keys('excel', Keys.ENTER)
handles = driver.window_handles
driver.switch_to.window(handles[-1])
driver.find_element(By.ID, "booksMore").click()
handles = driver.window_handles
driver.switch_to.window(handles[-1])
time.sleep(5)
fun(driver)while True:time.sleep(1)driver.find_elements(By.CLASS_NAME, "ivu-page-next")[0].click()fun(driver)首先我们先定义了一个函数,用于读取页面所有图书的信息,就要依次点击每一本书,跳转到有书详细内容的页面,然后读取保存内容,然后关闭这个页面,然后再点击下一个书(这里用循环控制,循环中提前保存了他们书的信息)
函数外部就先在主页在搜索栏搜索excel,然后跳转进那个页面,然后点击更多,然后开始执行函数读取这个页面内书的内容,然后while循环,点击下一页。
运行结果不符合我们预期的时候,记得sleep一下,页面读取信息较快,可能没渲染出来就去读取,可能会读取为空,或者读取失败报错!!!