自己训练大模型?MiniMind 全流程解析 (一) 预训练
自己训练大模型?MiniMind 全流程解析 (一) 预训练
https://github.com/jingyaogong/minimind
MiniMind 是一个高效、灵活的大语言模型框架,旨在提供完整的模型训练、微调和推理解决方案。本教程详细解析 MiniMind 的预训练流程,涵盖从数据准备到模型保存的完整技术实现。
从0实现预训练、指令微调、LoRA、DPO强化学习,白盒模型蒸馏。关键算法几乎不依赖第三方封装的框架,且全部开源。
一、整体流程概述
今天我们先来学习一下预训练阶段的代码和流程,整体流程如下:
基本上流程和深度学习的流程没有太大的区别。
二、核心算法详解
1. 余弦退火学习率调度
实现公式:
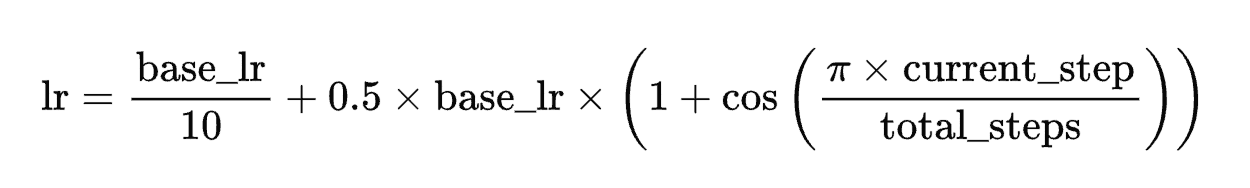
源码位置:train_pretrain.py 第27-29行
def get_lr(current_step, total_steps, lr):return lr / 10 + 0.5 * lr * (1 + math.cos(math.pi * current_step / total_steps)) # 使用余弦退火学习率调度
特点:
- 前期快速收敛
- 后期精细调整
- 自动适应不同训练阶段
2. 混合精度训练
混合精度训练通过 同时使用低精度(如 float16/bfloat16 )和高精度(float32 ) 加速计算:
前向计算:用低精度(如 float16 )执行矩阵乘法、激活函数等,减少显存占用、加速计算。
反向传播:梯度用低精度存储会导致溢出,因此用 GradScaler 缩放梯度到 float32 范围,更新参数时再反缩放,避免精度丢失。
实现方式:
ctx = nullcontext() if device_type == "cpu" else torch.cuda.amp.autocast() # 根据设备类型选择上下文管理器
scaler = torch.cuda.amp.GradScaler(enabled=(args.dtype in ['float16', 'bfloat16'])) # 创建梯度缩放器用于混合精度训练
源码位置:train_pretrain.py 第143-144行
torch.cuda.amp.autocast()
作用:自动将模型前向计算中的操作 / 张量转换为低精度(float16 或 bfloat16 ,依硬件支持),无需手动修改模型代码。
触发条件:仅在 GPU 训练时生效(CPU 不支持低精度加速,用 nullcontext 空上下文)。
精度选择逻辑:PyTorch 会根据操作类型(如矩阵乘法、激活函数),自动判断是否适合低精度,对不适合的操作(如数值不稳定的小梯度)保留 float32 ,平衡速度与精度。torch.cuda.amp.GradScaler
核心功能:解决低精度梯度溢出问题。
前向计算后,scaler.scale(loss).backward() 会 放大损失值(比如乘以 2^N ),让反向传播的梯度落在 float16 可表示范围内,避免下溢(梯度变成 0 )。
参数更新前,scaler.step(optimizer) 会 反缩放梯度(除以 2^N ),保证参数更新正确。
enabled 参数:控制是否启用混合精度。仅当训练精度是 float16/bfloat16 时开启,否则退化为普通训练(用 float32 ,scaler 不生效 )。
优势:
- 自动选择最优精度
- 减少内存占用
- 加速训练过程
3. 梯度累积
梯度累积是 “用多次小 Batch 模拟大 Batch 训练” 的技巧:
正常训练:1 个大 Batch 前向→反向→更新参数(显存不够时跑不通大 Batch )。
梯度累积:
分 N 次(accumulation_steps )跑小 Batch ,每次计算梯度后 不清空,累加梯度。
累计 N 次后,用 平均梯度 更新参数 → 等效于 1 个 N×小 Batch 的大 Batch 训练。
实现方式:
loss = loss / args.accumulation_steps # 梯度平均:避免累积后梯度过大
if (step + 1) % args.accumulation_steps == 0: # 累计 N 次后更新参数scaler.step(optimizer) # 执行优化器步骤(反缩放梯度 + 参数更新)scaler.update() # 更新混合精度缩放系数
源码位置:train_pretrain.py 第68-72行
优势:
- 支持小显存设备
显存瓶颈突破:大 Batch 训练需要同时存储 “输入数据 + 中间激活 + 梯度”,显存占用与 Batch Size 正相关。
例:显存只能跑 Batch=8 ,设 accumulation_steps=4 → 等效跑 Batch=32 的大 Batch ,但每次仅用 8 的显存。
适用场景:笔记本 GPU(如 2060 )、旧服务器 GPU(如 1080Ti )训练大模型(如 LLaMA 7B )时,梯度累积是 “能跑通训练” 的关键。 - 提高梯度估计稳定性
梯度更 “准”:大 Batch 训练的梯度是 “单次大样本平均”,小 Batch 梯度累积是 “多次小样本平均”。
小 Batch 梯度噪声大,但多次累积后 → 噪声相互抵消,最终梯度更接近真实大 Batch 的梯度方向。
极端场景:Batch Size=1 时梯度极不稳定,但累积 10 次后,等效于 Batch=10 的梯度,稳定性显著提升。 - 等效于大 Batch 训练
数学等价性:假设损失函数是均值函数(如 CrossEntropyLoss ),梯度累积 N 次小 Batch ,与直接跑 N×小 Batch 的大 Batch 训练,参数更新公式完全一致。
验证方式:对比两种训练方式的参数更新量、损失曲线,会发现几乎重合(前提:学习率、优化器配置相同 )。
4. 分布式训练
分布式训练通过 多 GPU / 多机并行计算 加速模型训练:
- 数据并行(最常见):
- 将相同模型复制到每个 GPU / 机器(称为 进程 )。
- 每个进程处理不同批次的数据,计算梯度后 同步梯度(而非参数)。
- 所有进程用平均梯度更新各自模型,保持参数同步。
- 通信后端:
NCCL(NVIDIA Collective Communications Library):专为 GPU 优化的通信库,支持快速点对点和集合通信(如 AllReduce),是 NVIDIA GPU 集群的首选。
实现方式:
if ddp: # 如果是分布式训练init_distributed_mode() # 初始化分布式模式model = DistributedDataParallel(model, device_ids=[ddp_local_rank]) # 包装模型为分布式数据并行
源码位置:train_pretrain.py 第169-171行和第109-116行
def init_distributed_mode(): # 定义分布式模式初始化函数if not ddp: return # 如果不是分布式训练则直接返回global ddp_local_rank, DEVICE # 声明全局变量dist.init_process_group(backend="nccl") # 初始化分布式进程组,使用NCCL后端ddp_rank = int(os.environ["RANK"]) # 获取进程排名ddp_local_rank = int(os.environ["LOCAL_RANK"]) # 获取本地进程排名ddp_world_size = int(os.environ["WORLD_SIZE"]) # 获取总进程数DEVICE = f"cuda:{ddp_local_rank}" # 设置设备为对应的CUDA设备torch.cuda.set_device(DEVICE) # 设置当前CUDA设备
特点:
- 使用 NCCL 通信后端
- 支持多GPU并行
- 自动管理进程组
三、训练流程详解
1. 初始化阶段
初始化阶段主要完成参数解析、随机种子设置和分布式环境配置:
parser = argparse.ArgumentParser(description="MiniMind Pretraining") # 创建命令行参数解析器
# ... 参数定义 ...
args = parser.parse_args() # 解析命令行参数base_seed = 1337 # 设置基础随机种子
torch.manual_seed(base_seed) # 设置PyTorch随机种子
torch.cuda.manual_seed(base_seed) # 设置CUDA随机种子if ddp: # 如果是分布式训练init_distributed_mode() # 初始化分布式模式args.device = torch.device(DEVICE) # 设置设备rank = dist.get_rank() # 获取进程排名torch.manual_seed(base_seed + rank) # 为每个进程设置不同的随机种子torch.cuda.manual_seed(base_seed + rank) # 为每个进程设置不同的CUDA随机种子
关于种子:
这些参数设置的作用是确保深度学习训练的可复现性(Reproducibility),即让同一实验在相同条件下能够得到相同的结果。具体来说:
深度学习中有很多随机因素会影响训练结果:
数据加载:随机打乱数据集(如 DataLoader(shuffle=True))。
模型初始化:神经网络权重的随机初始化。
Dropout 层:训练时随机 “丢弃” 部分神经元。
CUDA 算法:部分 CUDA 操作存在非确定性实现(如卷积算法)。
设置随机种子是深度学习实验的标准操作,通过固定随机数生成序列,让实验结果可复现。
2. 数据准备阶段
数据准备阶段加载分词器、构建数据集和数据加载器:
model, tokenizer = init_model(lm_config) # 初始化模型和分词器
train_ds = PretrainDataset(args.data_path, tokenizer, max_length=args.max_seq_len) # 创建预训练数据集
train_sampler = DistributedSampler(train_ds) if ddp else None # 如果是分布式训练则创建分布式采样器
tain_loader = DataLoader( # 创建训练数据加载器train_ds, # 数据集batch_size=args.batch_size, # 批次大小pin_memory=True, # 将数据固定在内存中以加速传输drop_last=False, # 不丢弃最后一个不完整的批次shuffle=False, # 不打乱数据(使用采样器控制)num_workers=args.num_workers, # 工作进程数sampler=train_sampler # 采样器
)
3. 训练循环阶段
训练循环阶段包含多个epoch,每个epoch中进行多个训练步骤:
for epoch in range(args.epochs): # 遍历训练轮次train_epoch(epoch, wandb) # 执行单轮训练
模型的设计
minimind使用的模型(MiniMindForCausalLM)的前向传播具有以下核心特点,结合其架构设计和代码实现可总结为:
- 输入处理与嵌入层设计
输入通过nn.Embedding转换为词向量,嵌入权重与输出层(lm_head)共享,减少参数总量(权重绑定)。
嵌入后立即应用dropout,增强模型泛化能力,符合语言模型常规正则化策略。 - 位置编码:基于 RoPE 的相对位置信息
采用旋转位置编码(RoPE),通过预计算的freqs_cos和freqs_sin(注册为缓冲区,避免重复计算)在注意力层中动态应用旋转操作(apply_rotary_pos_emb)。
相对位置编码特性使其更适合长序列(max_position_embeddings支持 32768),无需显式存储绝对位置向量,降低内存占用。 - 注意力机制:高效化与灵活性
支持分组查询注意力(GQA):通过num_key_value_heads设置 key/value 头数量,repeat_kv函数将 key/value 头重复以匹配 query 头数量(n_rep = num_attention_heads // num_key_value_heads),平衡效率与性能。
集成Flash Attention(flash_attn=True):使用F.scaled_dot_product_attention实现高效注意力计算,减少内存访问并加速长序列处理,非 Flash 模式下则用传统 softmax 注意力 + 因果掩码(上三角无穷大)确保因果性。
支持KV 缓存(past_key_values):生成式任务中复用历史 token 的 key/value,避免重复计算,显著提升增量解码效率(如文本生成时的逐 token 预测)。 - 前馈网络:支持普通 / SwiGLU 与 MoE 两种模式
普通模式:采用 SwiGLU 激活函数(gate_proj * up_proj),中间层大小(intermediate_size)默认设为hidden_size * 8/3并对齐 64 的倍数(硬件友好型设计),计算效率优于传统 ReLU。
MoE 模式(use_moe=True):
多个专家网络(n_routed_experts)与可选共享专家(n_shared_experts),每个 token 通过MoEGate路由至多个专家(num_experts_per_tok),用 softmax 评分函数选择。
包含辅助损失(aux_loss):通过平衡专家负载(如seq_aux控制序列级损失)稳定训练,推理时用moe_infer按专家分组处理 token,优化计算效率。 - 归一化与层结构:轻量化与稳定性
采用RMSNorm(而非 LayerNorm):仅做均方根归一化(无均值减法),减少计算量,常见于大模型设计(如 LLaMA),每层包含输入层归一化(input_layernorm)和注意力后归一化(post_attention_layernorm),属于预归一化(Pre-LN)结构,提升训练稳定性。 - 输出与生成适配
输出层(lm_head)生成 logits 时,支持仅保留最后logits_to_keep个 token 的结果(适配生成任务中仅关注最新 token 的场景)。
返回CausalLMOutputWithPast,包含past_key_values(供后续生成复用)、aux_loss(MoE 模式下)等,完整支持因果语言建模的训练与推理流程。
前向传播与损失计算
res = model(X) # 前向传播计算模型输出
loss = loss_fct( # 计算交叉熵损失res.logits.view(-1, res.logits.size(-1)), # 将logits重塑为二维张量Y.view(-1) # 将标签重塑为一维张量
).view(Y.size()) # 将损失重塑回原始形状
loss = (loss * loss_mask).sum() / loss_mask.sum() # 应用损失掩码并计算平均损失
loss += res.aux_loss # 添加辅助损失(如果模型有MoE等结构)
loss = loss / args.accumulation_steps # 除以梯度累积步数
反向传播与参数更新
scaler.scale(loss).backward() # 使用梯度缩放器进行反向传播if (step + 1) % args.accumulation_steps == 0: # 如果达到梯度累积步数scaler.unscale_(optimizer) # 取消梯度缩放torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip) # 梯度裁剪scaler.step(optimizer) # 执行优化器步骤scaler.update() # 更新梯度缩放器optimizer.zero_grad(set_to_none=True) # 清零梯度
日志记录与模型保存
Logger( # 记录训练日志'Epoch:[{}/{}]({}/{}) loss:{:.3f} lr:{:.12f} epoch_Time:{}min:'.format(epoch + 1, # 当前轮次args.epochs, # 总轮次step, # 当前步骤iter_per_epoch, # 每轮总步数loss.item() * args.accumulation_steps, # 当前损失值optimizer.param_groups[-1]['lr'], # 当前学习率spend_time / (step + 1) * iter_per_epoch // 60 - spend_time // 60)) # 预计剩余时间if (step + 1) % args.save_interval == 0 and (not ddp or dist.get_rank() == 0): # 如果达到保存间隔且是主进程model.eval() # 切换模型到评估模式moe_path = '_moe' if lm_config.use_moe else '' # 如果使用MoE则添加后缀ckp = f'{args.save_dir}/pretrain_{lm_config.hidden_size}{moe_path}.pth' # 构造检查点文件路径if isinstance(model, torch.nn.parallel.DistributedDataParallel): # 如果是分布式数据并行模型state_dict = model.module.state_dict() # 获取模型状态字典else: # 如果是普通模型state_dict = model.state_dict() # 获取模型状态字典state_dict = {k: v.half() for k, v in state_dict.items()} # 将参数转换为半精度以节省存储空间torch.save(state_dict, ckp) # 保存模型检查点model.train() # 切换模型回训练模式