基于pdf2docx模块Python实现批量将PDF转Word文档(安装+完整代码教程)
PDF文件是一种常见的文档格式,但是在编辑和修改时不太方便,因为PDF本质上是一种静态的文档格式。因此,有时候我们需要将PDF文件转换成Word格式,以便更好地编辑和修改文档。在本篇文章中,我们将介绍如何使用Python实现PDF转Word的功能。
文章目录
- 1. 为什么用Python实现?
- 2. 模块安装
- 3. 模块介绍
- 4. 需求
- 5. 注意事项
- 6. 完整代码实现
- 7. 运行结果
- 《100天精通Python》专栏推荐白嫖80g Python全栈视频
1. 为什么用Python实现?
最近想将一些PDF文件转换为Word文档,第一时间想到W某S系列都有Pdf文档转Word文档的功能,结果还要会员???这里针对不想付费的情况所设计的一套方案。
2. 模块安装
这里主要用到的第三方模块是pdf2docx,用下面的pip命令安装即可:
pip install pdf2docx
3. 模块介绍
pdf2docx是一个Python模块,可以用来将PDF文件转换成Word文档。它是基于Python的pdfminer和python-docx库开发的,可以在Windows、Linux和Mac系统上运行。
pdf2docx模块可以直接从PDF文件中提取文本和图片,并将其转换成可编辑的Word文档。它可以处理包含复杂布局和格式的PDF文件,并保留原始的字体、颜色、大小和格式等属性。
使用pdf2docx模块非常简单,只需要安装pdf2docx库并导入相应的函数即可。以下是一个简单的示例代码:
import pdf2docx# 将PDF文件转换成Word文档
pdf2docx.parse('example.pdf', 'example.docx')
在上述代码中,我们首先导入pdf2docx模块,然后使用parse函数将PDF文件example.pdf转换成Word文档example.docx。
pdf2docx模块还提供了一些其他的函数和选项,可以根据需要进行配置和使用。以下是一些常用的函数和选项:
- parse:将PDF文件转换成Word文档
- parse_pages:将PDF文件中的一页转换成Word文档
- parse_images:将PDF文件中的图片提取出来
- parse_text:将PDF文件中的文本提取出来
- parse_layout:将PDF文件中的页面布局提取出来
pdf2docx模块还支持一些高级选项,如自定义字体、颜色、大小、格式等,可以根据需要进行配置和使用。
总结:pdf2docx是一个非常实用的Python模块,可以将PDF文件转换成可编辑的Word文档。它基于pdfminer和python-docx库开发,可以处理包含复杂布局和格式的PDF文件,并保留原始的字体、颜色、大小和格式等属性。使用pdf2docx模块非常简单,只需要安装pdf2docx库并导入相应的函数即可。
4. 需求
Python实现批量将PDF转Word文档j,用到pdf2docx和os模块。
5. 注意事项
1、PDF文档的后缀务必是“.pdf”,否则转换不成功
2、大部分的PDF文档都可用这个程序来转换,如果是图片生成的Pdf文档,则转换不成功,原因是要将图片里的文字转换成文档涉及到人工智能的知识,它已超出这个程序的能力范围。但也不用慌,遇到此情况,可以用QQ的文件助手来帮忙,此处不赘述。
6. 完整代码实现
下方代码只需要修改file_path 文件路径即可:
import os
from pdf2docx import Converterdef pdf_docx():# 获取当前工作目录file_path = r'C:\Users\test'# 遍历所有文件for file in os.listdir(file_path):# 获取文件后缀suff_name = os.path.splitext(file)[1]# 过滤非pdf格式文件if suff_name != '.pdf':continue# 获取文件名称file_name = os.path.splitext(file)[0]# pdf文件名称pdf_name = file_path + '\\' + file# 要转换的docx文件名称docx_name = file_path + '\\' + file_name + '.docx'# 加载pdf文档cv = Converter(pdf_name)cv.convert(docx_name)cv.close()if __name__ == '__main__':pdf_docx()
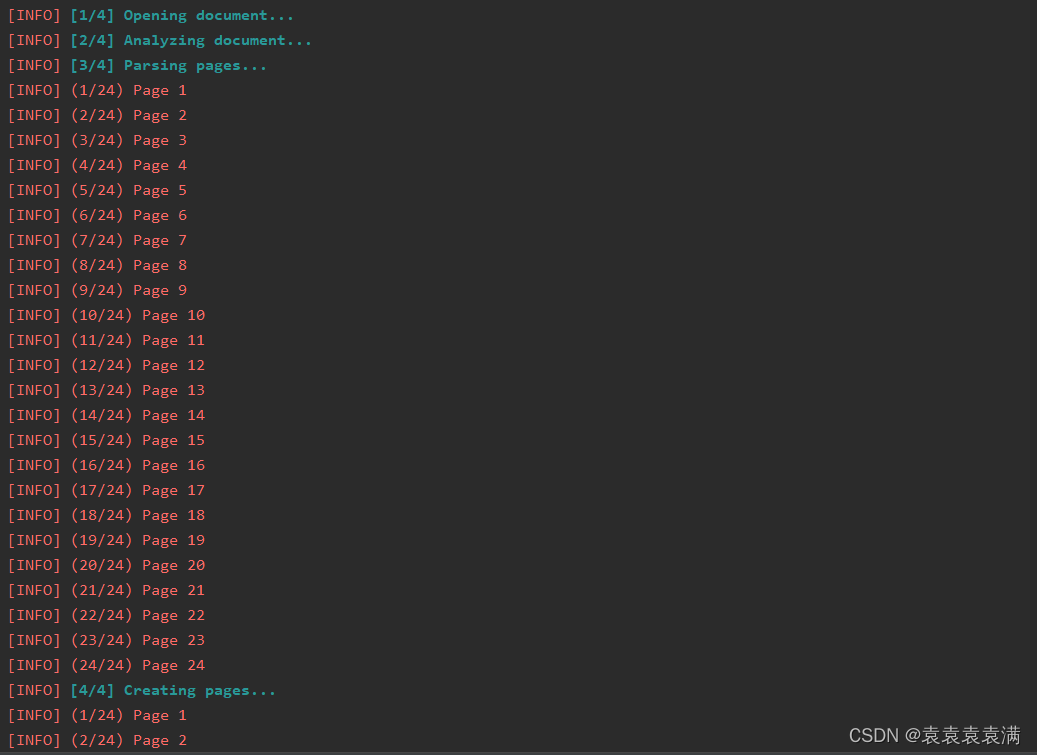
7. 运行结果
控制台实现打印转换的页码进程:
实现了PDF转Word:

打开的效果:
《100天精通Python》专栏推荐白嫖80g Python全栈视频
《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
- 优点:订阅限时9.9付费专栏进入千人全栈VIP答疑群,作者优先解答机会(代码指导、远程服务),群里大佬众多可以抱团取暖(大厂内推机会)!
- 专栏福利:简历指导、招聘内推、每周送实体书、80G全栈学习视频、300本IT电子书:Python、Java、前端、大数据、数据库、算法、爬虫、数据分析、机器学习、面试题库等等