200.Spark(七):SparkSQL项目实战
一、启动环境
需要启动mysql,hadoop,hive,spark。并且能让spark连接上hive(上一章有讲)
#启动mysql,并登录,密码123456
sudo systemctl start mysqld
mysql -uroot -p#启动hive
cd /opt/module/
myhadoop.sh start#查看启动情况
jpsall#启动hive
cd /opt/module/hive/bin/
hiveservices.sh start#查看启动状态
/opt/module/hive/bin/hiveservices.sh status启动beeline:
#启动thriftserver
cd /opt/module/spark-local/
sbin/start-thriftserver.sh#通过spark的beeline连接
bin/beeline -u jdbc:hive2://hadoop102:10000 -n root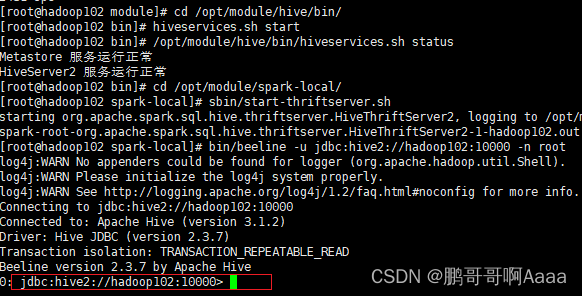
创建数据库:
show databases;
create database atguigu;
二、数据准备
将三个txt文件放到datas目录下: