2022年新一代kaldi团队技术输出盘点
目录
1. 技术创新
1.1 Pruned RNN-T loss
1.2 RNN-T 的快速 GPU 解码
1.3 多码本量化索引的知识蒸馏
1.4 RNN-T 和 CTC 的低延时训练
1.5 Zipformer
1.6 Small tricks
2. 模型部署
2.1 Sherpa
2.1 Sherpa-ncnn
3. 更多的 recipe 和模型
参考资料
1. 技术创新
1.1 Pruned RNN-T loss
该项工作是新一代 Kaldi 针对 RNN-T 损失函数的创新性改进。原始的 RNN-T 损失函数在处理长文本或者长语音的时候显存占用较大,训练时间较长。对此,我们提出对 RNN-T 的 log-probability lattice 进行裁剪,能够在不损失训练精度的前提下大幅缩短 RNN-T 损失函数的计算时间。该工作[1]已经被Interspeech2022 收录,我们也撰写了多篇文章详细介绍其中的细节:
-
初探 Pruned RNN-T:多快好省的 RNN-T 训练
-
细聊 Pruned RNN-T: Pruned RNN-T 何以又快又好
1.2 RNN-T 的快速 GPU 解码
在该项工作中我们在 GPU 上实现了高效的 FSA 解码,为此我们对 RNN-T 做了一些改造,首先我们在 RNN-T 中使用了无状态的 decoder 网络,使用有限的 left context;另外,我们在解码时限制每一帧语音只能输出一个 symbol。在这两个前提下,我们基于 k2 中的 RaggedTensor 实现了帧同步的 beam search 解码。这可能是现今唯一既能使用 FSA 又能运行于 GPU 的解码方法,我们测试发现使用 80M 的模型在英伟达 V100 显卡上能并行跑 200 路以上的语音,LibriSpeech 数据集上的解码实时率低至 0.0025。该工作[2]已经提交至 ICASSP2023,icefall中的fast_beam_search实现了该种解码办法,欢迎大家尝试!
1.3 多码本量化索引的知识蒸馏
知识蒸馏是常见的提升模型表现的办法。针对传统知识蒸馏框架中的训练效率和教师标签存储成本的问题,新一代 Kaldi 团队创新性地提出了基于多码本量化索引的知识蒸馏。该办法能够在几乎不影响知识蒸馏的效果的前提下,实现对教师标签上百倍的压缩,有效的解决了传统知识蒸馏办法在大数据集下面临的困境。该工作[3]目前也已经提交至 ICASSP2023,我们也撰写了一篇详细的文章介绍标签压缩的算法:新一代 Kaldi 中基于量化的蒸馏实验(写得特别好,小编强烈推荐!)

1.4 RNN-T 和 CTC 的低延时训练
时延是流式ASR模型的一项重要指标。新一代 Kaldi 团队针对流式 RNN-T 模型的时延惩罚做了大量研究,最终探索出一条简单有效的时延惩罚策略。根据 lattice 中不同通路的产生的时延,对 RNN-T 的 log-probability lattice 进行简单的修正,让模型更倾向于学习时延更短的通路。通过控制时延惩罚的参数,我们可以精准的控制时延和模型准确率之间的 trade-off。该工作已经提交 ICASSP2023,论文的链接在这里[4],欢迎大家阅读!
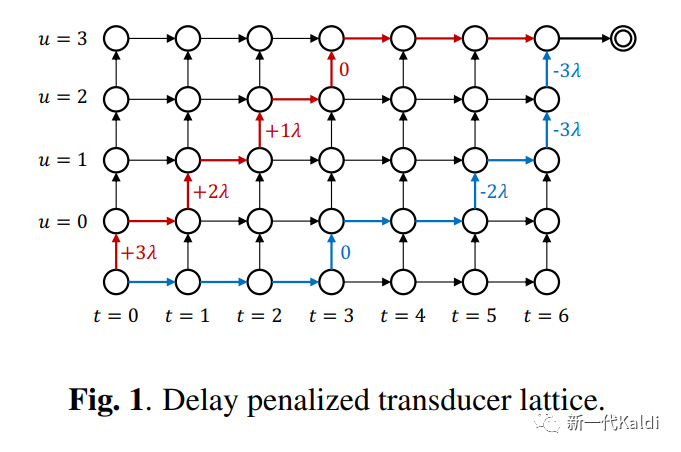
在 CTC 模型中,我们也借鉴了该思路实现了一套时延惩罚策略。有兴趣的读者请移步Delay Penalty For RNN-T and CTC,我们对 RNN-T 和 CTC 中的时延惩罚策略都做了详细的介绍。
1.5 Zipformer
Zipformer 模型是新一代 Kaldi 团队提出的新型声学建模架构。针对传统Conformer 的诸多细节做了大幅度改动,包括
-
优化器(ScaledAdam)
-
时间维度 U-Net(通过降采样和升采样大幅降低计算量)
-
注意力权重复用,减少计算量
-
多个创新性的子模块
-
...
目前 Zipformer 模型已经在诸多测试集上取得了出色的识别准确率,代码也已经合并在 icefall[5]的中,欢迎大家尝试。再告诉大家一个小秘密,Dan 哥现在正在对 Zipformer 的诸多子模块做进一步优化,预计在不远的将来会有新一版的 Zipformer 和大家见面,敬请期待!
1.6 Small tricks
除了上述的几项,我们还做了如下的一些工作:
-
模型平均算法,简单有效的 ensemble 技巧。通过维护一个
averaged_model变量,高效的实现更细粒度的模型平均; -
升点小技巧之—在icefall中巧用语言模型,让你的模型越来越好;
-
训练小助手之新一代 Kaldi 中的 RandomCombiner,有效训练更深的模型;
-
训练小助手之新一代 Kaldi 中的 LSTM GradientFilter,实时追踪并且剔除可能导致梯度爆炸的坏样本,让你的LSTM模型更加稳定;
-
提速小助手之跳帧 Blank-skipping[7]。在解码 RNN-T 模型时,利用 CTC 的概率输出跳过输出 Blank 的帧,大幅提升解码的效率(详见原论文[8])。该方案我们在 icefall 中也有实现,欢迎大家尝试。
-
...
读读读(小编有话说:简单有效,说不定哪天就能用在自己的模型上了呢!)
2. 模型部署
2.1 Sherpa
sherpa[9]是新一代 Kaldi 团队推出的服务端 ASR 模型部署方案。包含了特征提取,神经网络计算和解码三个部分,并且提供了 Python 接口方便使用。部署完成后,只需要一个浏览器,你就可以流畅体验icefall中提供的诸多自动语音识别模型。使用教程详见极速上手新一代 Kaldi 服务端框架 sherpa。
2.1 Sherpa-ncnn
如果你在寻找一个适合于移动端或者嵌入式端的部署方案,那不妨试试sherpa-ncnn。Sherpa-ncnn[10]是新一代Kaldi团队在去年推出的安装便捷,支持实时语音识别的 Python 包。仅需一行代码
pip install sherpa-ncnn
便可以体验新一代 Kaldi 支持的诸多语音识别模型。sherpa-ncnn现在已经支持Linux,Windows,macOS,Android 等常见平台。在嵌入式平台上,sherpa-ncnn也实现了实时语音识别。我们还实现了基于ncnn的 int8 模型量化,能够进一步压缩模型大小,提升推理速度。更多细节欢迎大家阅读这几篇文章:
-
sherpa-ncnn 简介:sherpa + ncnn 进行语音识别
-
移动端使用案例:新一代 Kaldi - 移动端语音识别;
-
嵌入式端使用案例:新一代 Kaldi - 嵌入式端实时语音识别;
每篇都干货满满,并且展示了诸多 demo!(小编注:军哥手把手教你,零基础教你玩转语音识别,一看就会!)
3. 更多的 recipe 和模型
过去的一年中,我们在icefall中增添了不少新的 recipe,涵盖了诸多公开数据集其中包括:
-
中文数据集:aishell2[11], aishell4[12], wenetspeech[13];
-
英文数据集:gigaspeech[14],tedlium3[15];
-
中英文数据集:tal_csasr[16]
-
藏语数据集:xbmu_amdo31[17]
我们还新增支持了多种模型结构,包括
-
Reworked Conformer[18],是新一代 Kaldi 提出的改进版 Conformer 模型;
-
LSTM[19],使用了 LSTM 模型作为 Encoder,并加入了诸多改动提升训练的稳定性;
-
Emformer[20],是 facebook 提出的低内存占用的流式模型。
icefall中的实现详见这里[21]; -
Zipformer[22],小编在上文已经介绍过了,这里不做重复啦;
参考资料
[1]工作: https://arxiv.org/abs/2206.13236
[2]工作: https://arxiv.org/abs/2211.00484
[3]工作: https://arxiv.org/abs/2211.00508
[4]这里: https://arxiv.org/abs/2211.00490
[5]icefall: https://github.com/k2-fsa/icefall/tree/master/egs/librispeech/ASR/pruned_transducer_stateless7
[6]语言模型融合: https://mp.weixin.qq.com/s/MkvKF5JJch3DT2RA87v9lQ
[7]跳帧Blank-skipping: https://github.com/k2-fsa/icefall/tree/master/egs/librispeech/ASR/pruned_transducer_stateless7_ctc_bs
[8]原论文: https://arxiv.org/abs/2210.16481
[9]sherpa: https://github.com/k2-fsa/sherpa
[10]Sherpa-ncnn: https://github.com/k2-fsa/sherpa-ncnn
[11]aishell2: https://github.com/k2-fsa/icefall/tree/master/egs/aishell2/ASR
[12]aishell4: https://github.com/k2-fsa/icefall/tree/master/egs/aishell4/ASR
[13]wenetspeech: https://github.com/k2-fsa/icefall/tree/master/egs/wenetspeech/ASR
[14]gigaspeech: https://github.com/k2-fsa/icefall/tree/master/egs/gigaspeech/ASR
[15]tedlium3: https://github.com/k2-fsa/icefall/tree/master/egs/tedlium3/ASR
[16]tal_csasr: https://github.com/k2-fsa/icefall/tree/master/egs/tal_csasr/ASR
[17]xbmu_amdo31: https://github.com/k2-fsa/icefall/tree/master/egs/xbmu_amdo31/ASR
[18]Reworked Conformer: https://github.com/k2-fsa/icefall/tree/master/egs/librispeech/ASR/pruned_transducer_stateless5
[19]LSTM: https://github.com/k2-fsa/icefall/tree/master/egs/librispeech/ASR/lstm_transducer_stateless2
[20]Emformer: https://arxiv.org/abs/2010.10759
[21]这里: https://github.com/k2-fsa/icefall/tree/master/egs/librispeech/ASR/conv_emformer_transducer_stateless2
[22]Zipformer: https://github.com/k2-fsa/icefall/tree/master/egs/librispeech/ASR/pruned_transducer_stateless7