40亿个QQ号,限制1G内存,如何去重?
40亿个unsigned int,如果直接用内存存储的话,需要:
4*4000000000 /1024/1024/1024 = 14.9G ,考虑到其中有一些重复的话,那1G的空间也基本上是不够用的。
想要实现这个功能,可以借助位图。
使用位图的话,一个数字只需要占用1个bit,那么40亿个数字也就是:
4000000000 * 1 /8 /1024/1024 = 476M
相比于之前的14.9G来说,大大的节省了很多空间。
比如要把我的QQ号"907607222"放到Bitmap中,就需要找到第907607222这个位置,然后把他设置成1就可以了。
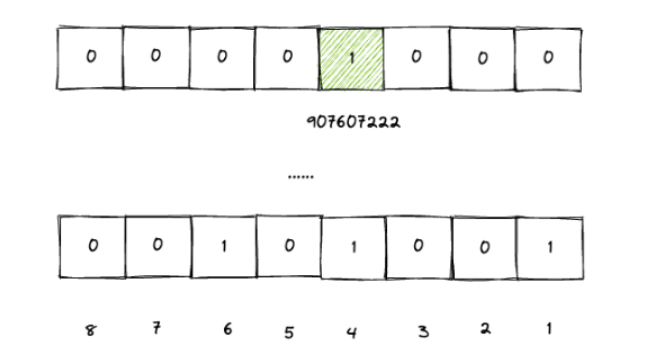
这样,把40亿个数字都放到Bitmap之后,所有位置上是1的表示存在,不为1的表示不存在,相同的QQ号只需要设置一次1就可以了,那么,最终就把所有是1的数字遍历出来就行了。
什么是BitMap?有什么用?
位图(BitMap),基本思想就是用一个bit来标记元素,bit是计算机中最小的单位,也就是我们常说的计算机中的0和1,这种就是用一个位来表示的。
所谓位图,其实就是一个bit数组,即每一个位置都是一个bit,其中的取值可以是0或者1

像上面的这个位图,可以用来表示1,4,6:
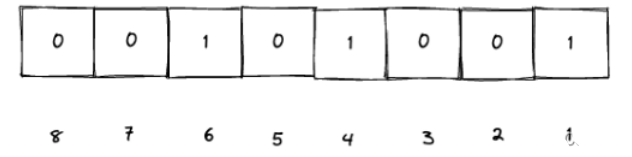
如果不用位图的话,我们想要记录1,4,6 这三个整型的话,就需要用三个unsigned int,已知每个unsigned int占4个字节,那么就是3*4 = 12个字节,一个字节有8 bit,那么就是 12*8 = 96 个bit。
所以,位图最大的好处就是节省空间。
位图有很多种用途,特别适合用在去重、排序等场景中,著名的布隆过滤器就是基于位图实现的。
但是位图也有着一定的限制,那就是他只能表示0和1,无法存储其他的数字。所以他只适合这种能表示ture or false的场景。
什么是布隆过滤器,实现原理是什么?
布隆过滤器是一种数据结构,用于快速检索一个元素是否可能存在于一个集合(bit 数组)中。
它的基本原理是利用多个哈希函数,将一个元素映射成多个位,然后将这些位设置为 1。当查询一个元素时,如果这些位都被设置为 1,则认为元素可能存在于集合中,否则肯定不存在
所以,布隆过滤器可以准确的判断一个元素是否一定不存在,但是因为哈希冲突的存在,所以他没办法判断一个元素一定存在。只能判断可能存在。
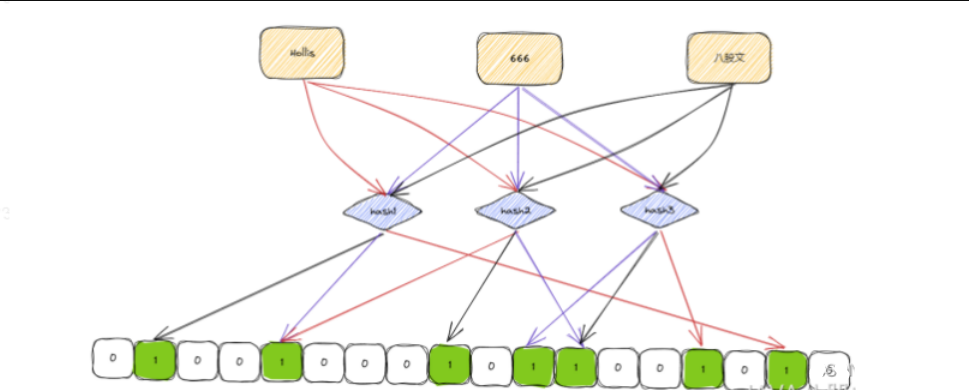
所以,布隆过滤器是存在误判的可能的,也就是当一个不存在的Hero元素,经过hash1、hash2和hash3之后,刚好和其他的值的哈希结果冲突了。那么就会被误判为存在,但是其实他并不存在。
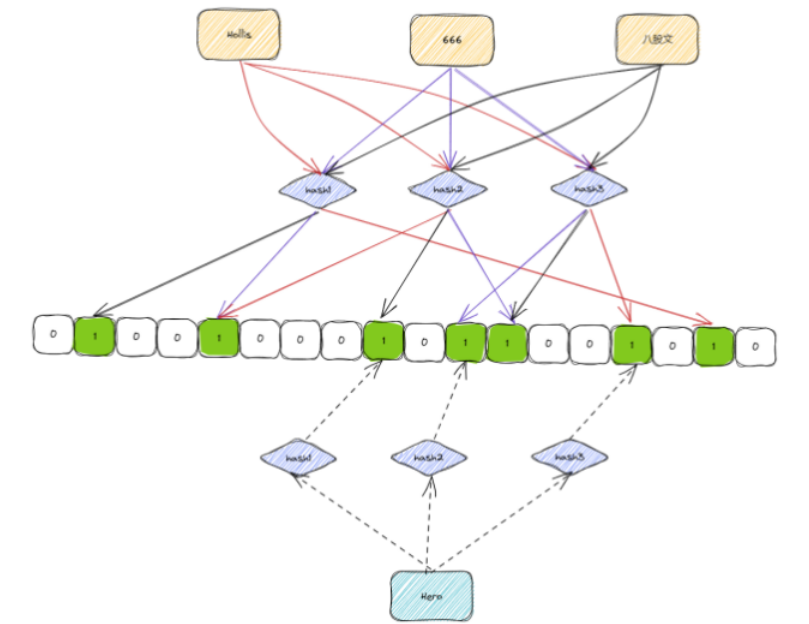
想要降低这种误判的概率,主要的办法就是降低哈希冲突的概率及引入更多的哈希算法。
下面是布隆过滤器的工作过程:
1、初始化布隆过滤器
在初始化布隆过滤器时,需要指定集合的大小和误判率。布隆过滤器内部包含一个bit数组和多个哈希函数,每个哈希函数都会生成一个索引值。
2、添加元素到布隆过滤器
要将一个元素添加到布隆过滤器中,首先需要将该元素通过多个哈希函数生成多个索引值,然后将这些索引值对应的位设置为 1。如果这些索引值已经被设置为 1,则不需要再次设置。
3、查询元素是否存在于布隆过滤器中
要查询一个元素是否存在于布隆过滤器中,需要将该元素通过多个哈希函数生成多个索引值,并判断这些索引值对应的位是否都被设置为 1。如果这些位都被设置为 1,则认为元素可能存在于集合中,否则肯定不存在。
布隆过滤器的主要优点是可以快速判断一个元素是否属于某个集合,并且可以在空间和时间上实现较高的效率。但是,它也存在一些缺点,例如:
-
布隆过滤器在判断元素是否存在时,有一定的误判率。、
-
布隆过滤器删除元素比较困难,因为删除一个元素需要将其对应的多个位设置为 0,但这些位可能被其他元素共享。
应用场景
布隆过滤器因为他的效率非常高,所以被广泛的使用,比较典型的场景有以下几个:
1、网页爬虫: 爬虫程序可以使用布隆过滤器来过滤掉已经爬取过的网页,避免重复爬取和浪费资源。
2、缓存系统: 缓存系统可以使用布隆过滤器来判断一个查询是否可能存在于缓存中,从而减少查询缓存的次数,提高查询效率。布隆过滤器也经常用来解决缓存穿透的问题。
3、分布式系统: 在分布式系统中,可以使用布隆过滤器来判断一个元素是否存在于分布式缓存中,避免在所有节点上进行查询,减少网络负载。
4、垃圾邮件过滤: 布隆过滤器可以用于判断一个邮件地址是否在垃圾邮件列表中,从而过滤掉垃圾邮件。
5、黑名单过滤: 布隆过滤器可以用于判断一个IP地址或手机号码是否在黑名单中,从而阻止恶意请求。
如何使用
Java中可以使用第三方库来实现布隆过滤器,常见的有Google Guava库和Apache Commons库以及Redis。
如Guava:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterExample {public static void main(String[] args) {// 创建布隆过滤器,预计插入100个元素,误判率为0.01BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), 100, 0.01);// 插入元素bloomFilter.put("Lynn");bloomFilter.put("666");bloomFilter.put("八股文");// 判断元素是否存在System.out.println(bloomFilter.mightContain("Lynn")); // trueSystem.out.println(bloomFilter.mightContain("张三")); // false}
}
Apache Commons:
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.collections4.BloomFilter;
import org.apache.commons.collections4.functors.HashFunctionIdentity;
public class BloomFilterExample {public static void main(String[] args) {// 创建布隆过滤器,预计插入100个元素,误判率为0.01BloomFilter<String> bloomFilter = new BloomFilter<>(HashFunctionIdentity.hashFunction(StringUtils::hashCode), 100, 0.01);// 插入元素bloomFilter.put("Lynn");bloomFilter.put("666");bloomFilter.put("八股文");// 判断元素是否存在System.out.println(bloomFilter.mightContain("Lynn")); // trueSystem.out.println(bloomFilter.mightContain("张三")); // false}
}
Redis中可以通过Bloom模块来使用,使用Redisson可以:
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("myfilter");
bloomFilter.tryInit(100, 0.01);
bloomFilter.add("Lynn");
bloomFilter.add("666");
bloomFilter.add("八股文");
System.out.println(bloomFilter.contains("Lynn"));
System.out.println(bloomFilter.contains("张三"));
redisson.shutdown();
首先创建一个RedissonClient对象,然后通过该对象获取一个RBloomFilter对象,使用tryInit方法来初始化布隆过滤器,指定了最多能添加的元素数量为100,误判率为0.01。
然后,使用add方法将元素"Hollis"、"666"和"八股文"添加到布隆过滤器中,使用contains方法来检查元素是否存在于布隆过滤器中。
或者Jedis也可以:
Jedis jedis = new Jedis("localhost");
jedis.bfCreate("myfilter", 100, 0.01);
jedis.bfAdd("myfilter", "Lynn");
jedis.bfAdd("myfilter", "666");
jedis.bfAdd("myfilter", "八股文");
System.out.println(jedis.bfExists("myfilter", "Lynn"));
System.out.println(jedis.bfExists("myfilter", "张三"));
jedis.close();