flink1.17.0 集成kafka,并且计算
前言
flink是实时计算的重要集成组件,这里演示如何集成,并且使用一个小例子。例子是kafka输入消息,用逗号隔开,统计每个相同单词出现的次数,这么一个功能。
一、kafka环境准备
1.1 启动kafka
这里我使用的kafka版本是3.2.0,部署的方法可以参考,
kafka部署
cd kafka_2.13-3.2.0
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
启动后查看java进程是否存在,存在后执行下一步。
1.2 新建topic
新建一个专门用于flink消费topic
bin/kafka-topics.sh --create --topic flinkTest --bootstrap-server 192.168.184.129:9092
1.3 测试生产消费是否正常
生产端:
bin/kafka-console-producer.sh --topic flinkTest --bootstrap-server 192.168.184.129:9092
客户端:
bin/kafka-console-consumer.sh --topic flinkTest --from-beginning --bootstrap-server 192.168.184.129:9092
1.4 测试生产消费
在生产端输入aaa

查看客户端是否能消费到
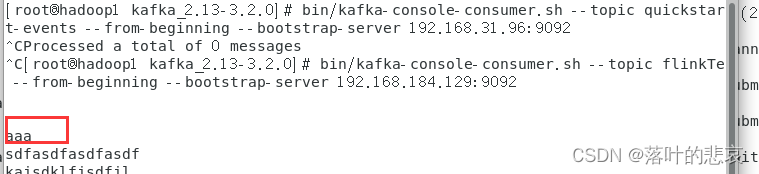
可以看到客户端已经消费成功了,kafka环境准备好了。
二、flink集成kafka
2.1 pom文件修改
pom文件修改之前,先看看官网的指导依赖是什么样的,
这里我们使用的是datastream api去做,
flink1.17.0官方文档
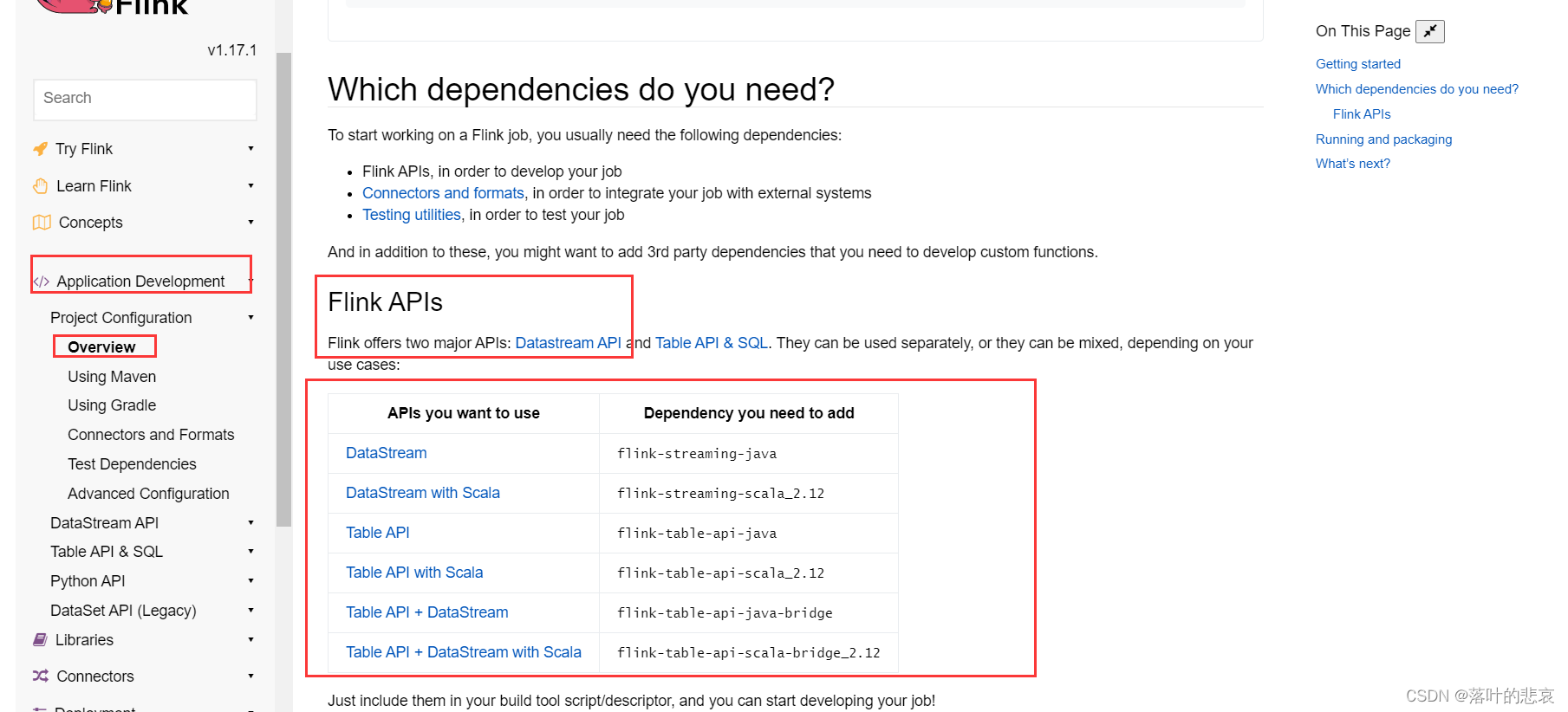
这里说明了相关的依赖需要引入的依赖包的版本,还有使用kafka消费的时候需要引入的连接包版本
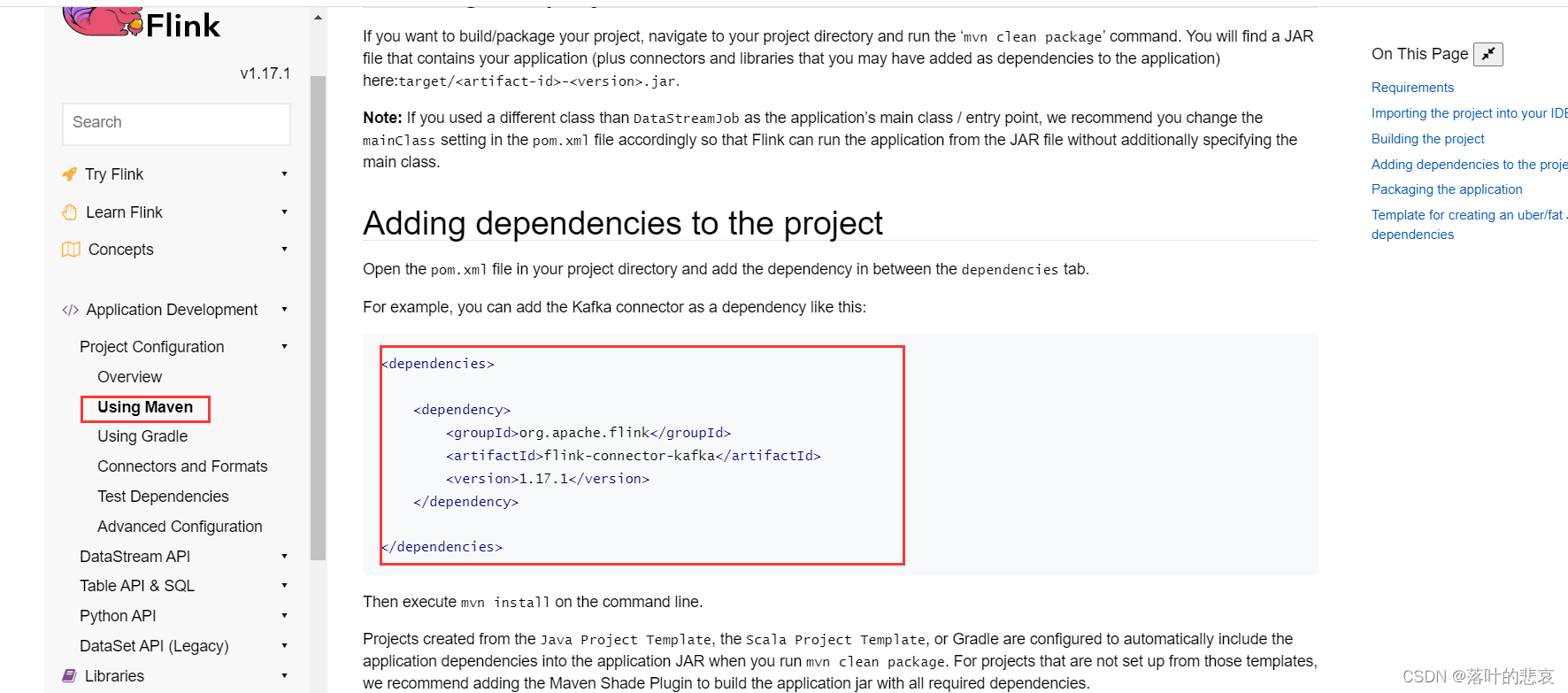
完整的pom引入依赖如下:
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.wh.flink</groupId><artifactId>flink</artifactId><version>1.0-SNAPSHOT</version><name>flink</name><!-- FIXME change it to the project's website --><url>http://www.example.com</url><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><flink.version>1.17.1</flink.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency><!-- Flink 依赖 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><!--<scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><!--<scope>provided</scope>--></dependency><!-- Flink Kafka连接器的依赖 -->
<!-- <dependency>-->
<!-- <groupId>org.apache.flink</groupId>-->
<!-- <artifactId>flink-connector-kafka-0.11_2.11</artifactId>-->
<!-- <version>${flink.version}</version>-->
<!-- </dependency>--><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><!-- Flink 开发Scala需要导入以下依赖 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.12</artifactId><version>${flink.version}</version><!--<scope>provided</scope>--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>${flink.version}</version><!--<scope>provided</scope>--></dependency><!--<dependency>--><!--<groupId>org.scala-lang</groupId>--><!--<artifactId>scala-library</artifactId>--><!--<version>2.11.12</version>--><!--</dependency>--><!-- log4j 和slf4j 包,如果在控制台不想看到日志,可以将下面的包注释掉--><!--<dependency>--><!--<groupId>org.slf4j</groupId>--><!--<artifactId>slf4j-log4j12</artifactId>--><!--<version>1.7.25</version>--><!--<scope>test</scope>--><!--</dependency>--><!--<dependency>--><!--<groupId>log4j</groupId>--><!--<artifactId>log4j</artifactId>--><!--<version>1.2.17</version>--><!--</dependency>--><!--<dependency>--><!--<groupId>org.slf4j</groupId>--><!--<artifactId>slf4j-api</artifactId>--><!--<version>1.7.25</version>--><!--</dependency>--><!--<dependency>--><!--<groupId>org.slf4j</groupId>--><!--<artifactId>slf4j-nop</artifactId>--><!--<version>1.7.25</version>--><!--<scope>test</scope>--><!--</dependency>--><!--<dependency>--><!--<groupId>org.slf4j</groupId>--><!--<artifactId>slf4j-simple</artifactId>--><!--<version>1.7.5</version>--><!--</dependency>--></dependencies><build><plugins><!-- 在maven项目中既有java又有scala代码时配置 maven-scala-plugin 插件打包时可以将两类代码一起打包 -->
<!-- <plugin>-->
<!-- <groupId>org.scala-tools</groupId>-->
<!-- <artifactId>maven-scala-plugin</artifactId>-->
<!-- <version>2.15.2</version>-->
<!-- <executions>-->
<!-- <execution>-->
<!-- <goals>-->
<!-- <goal>compile</goal>-->
<!-- <goal>testCompile</goal>-->
<!-- </goals>-->
<!-- </execution>-->
<!-- </executions>-->
<!-- </plugin>--><plugin><artifactId>maven-assembly-plugin</artifactId><version>2.4</version><configuration><!-- 设置false后是去掉 MySpark-1.0-SNAPSHOT-jar-with-dependencies.jar 后的 “-jar-with-dependencies” --><!--<appendAssemblyId>false</appendAssemblyId>--><archive><manifest><mainClass>com.hadoop.demo.service.flinkDemo.FlinkDemo</mainClass></manifest></archive><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>assembly</goal></goals></execution></executions></plugin></plugins></build>
</project>
项目结构如图
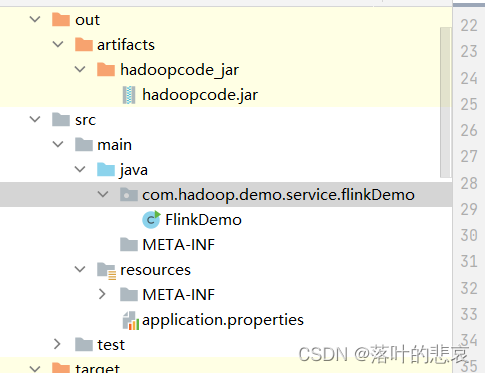
2.2 代码编写
package com.hadoop.demo.service.flinkDemo;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.functions.FlatMapIterator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Arrays;
import java.util.Iterator;public class FlinkDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//新建kafka连接KafkaSource<String> kfkSource = KafkaSource.<String>builder().setBootstrapServers("192.168.184.129:9092").setGroupId("flink").setTopics("flinkTest").setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema()).build();//添加到flink环境DataStreamSource<String> lines = env.fromSource(kfkSource, WatermarkStrategy.noWatermarks(), "kafka source");//根据逗号分组SingleOutputStreamOperator<Tuple2<String, Integer>> map = lines.flatMap(new FlatMapIterator<String, String>() {@Overridepublic Iterator<String> flatMap(String s) throws Exception {return Arrays.asList(s.split(",")).iterator();}}).map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String s) throws Exception {return new Tuple2<>(s, 1);}});//统计每个单词的数量SingleOutputStreamOperator<Tuple2<String, Integer>> sum = map.keyBy(0).sum(1);sum.print();//System.out.println(sum.get);env.execute();}}2.3 maven打包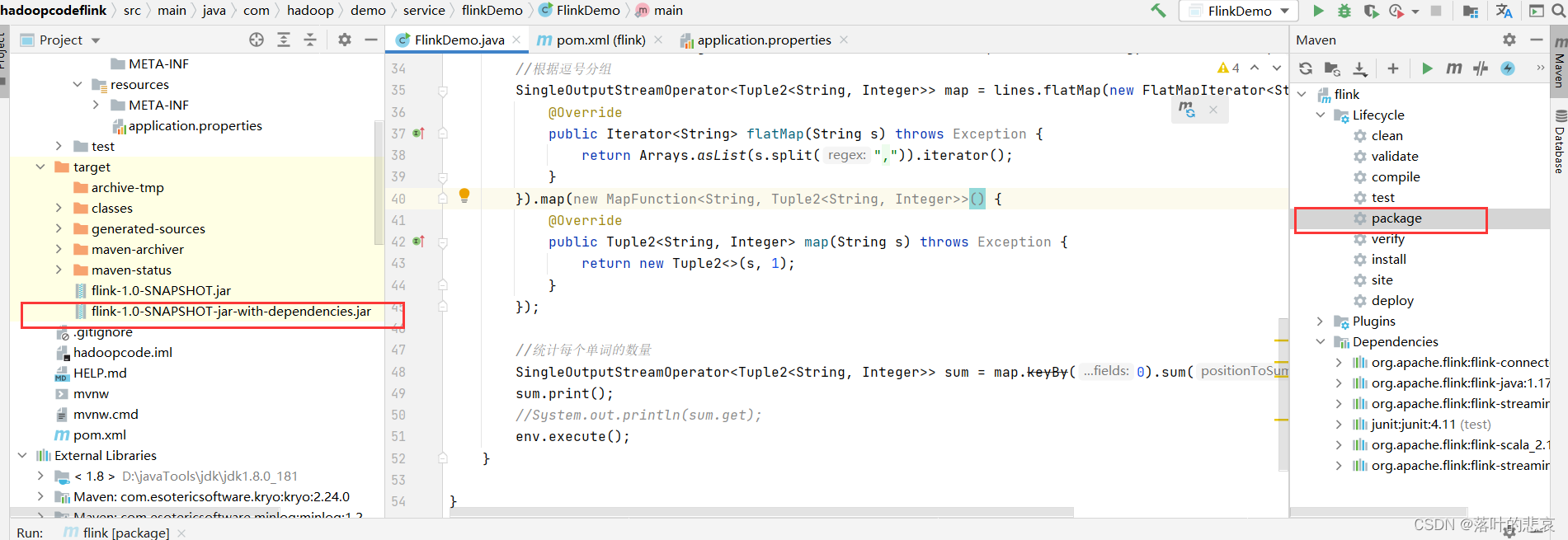
点击打包按钮,这里注意要选择带依赖的jar包,否则会出现以下错误。
NoClassDefFoundError: org/apache/flink/connector/kafka/source/KafkaSource
三、测试
3.1启动 hadoop集群,启动flink集群
这里如果不知道怎么搭建这两个集群可以看我其他文章
hadoop集成flink
./hadoop.sh start
./bin/yarn-session.sh --detached
3.2 上传jar包到flink集群
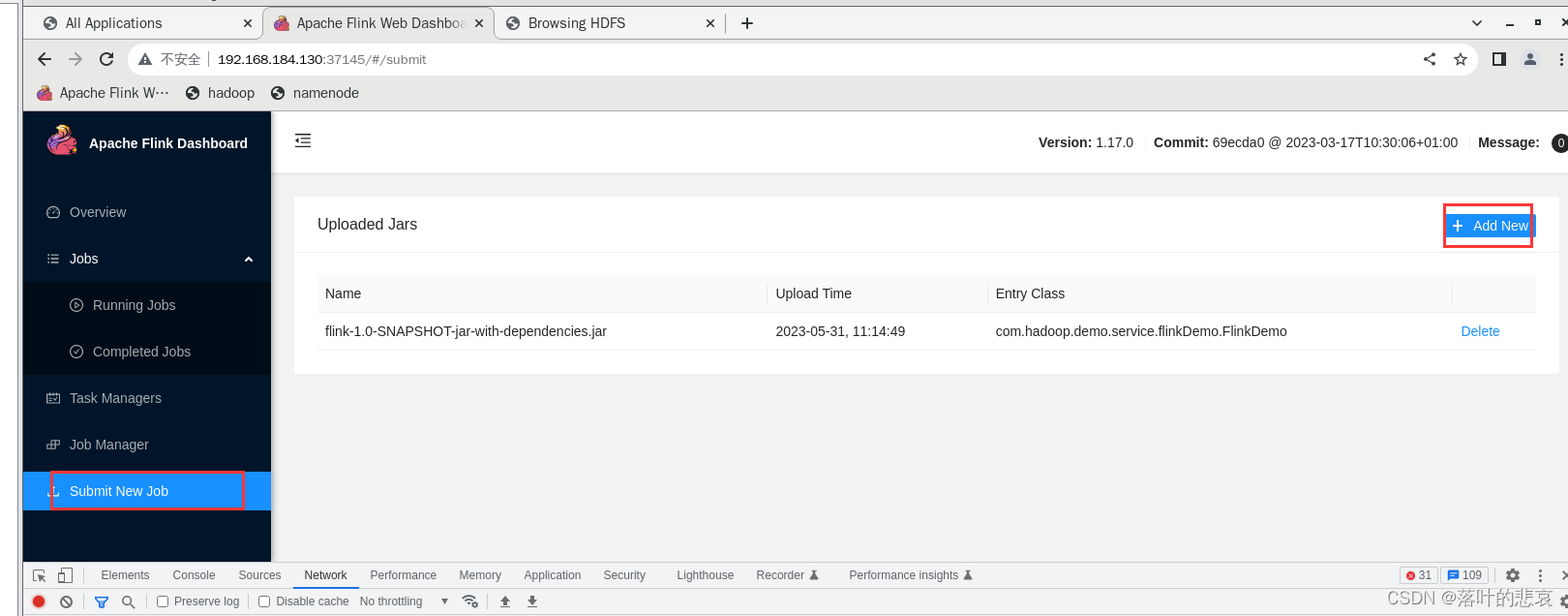
上传后填写主类类名,点击提交
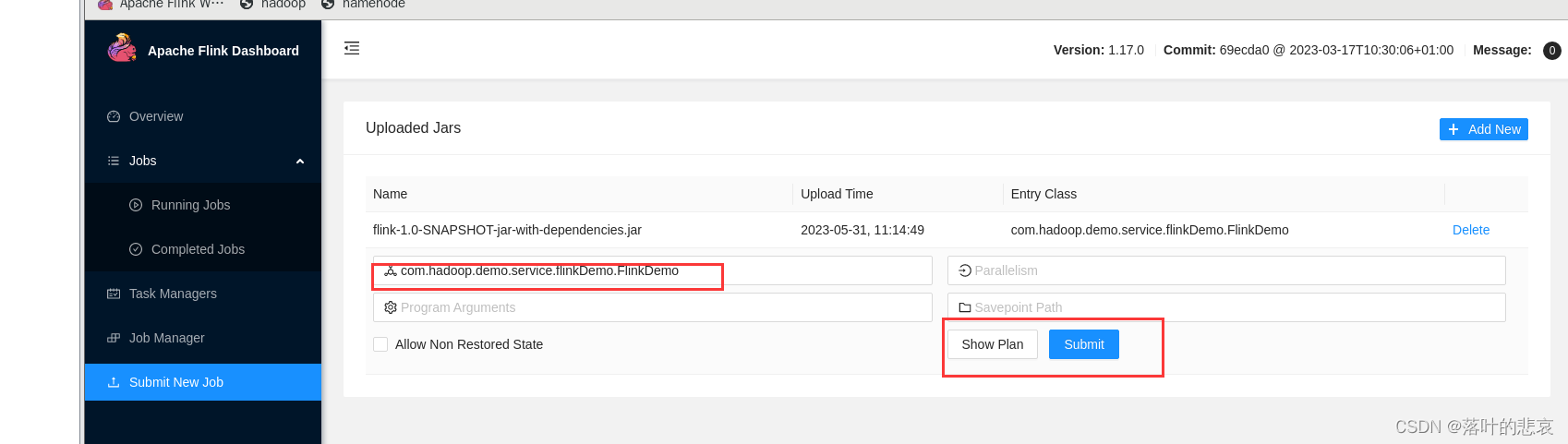
3.3 测试
点击后,可以看到执行job这里能看到在运行的job
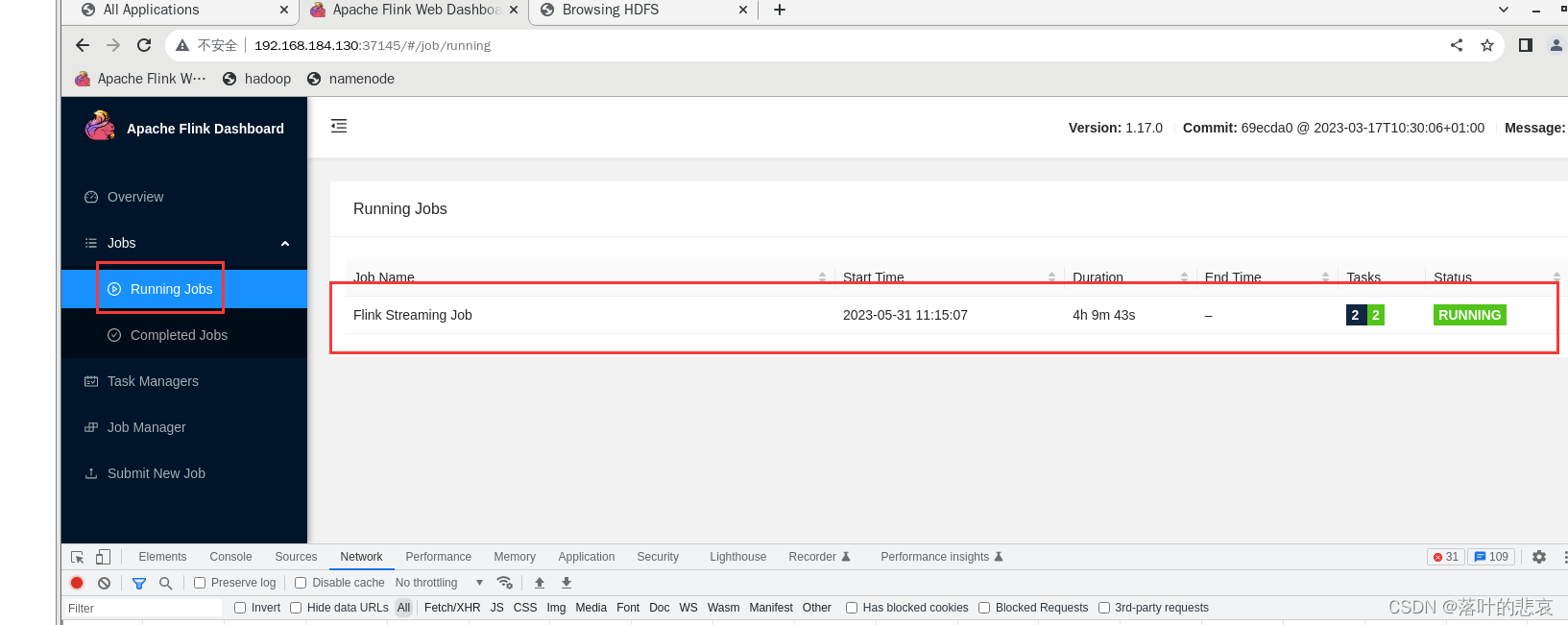
点击运行的task
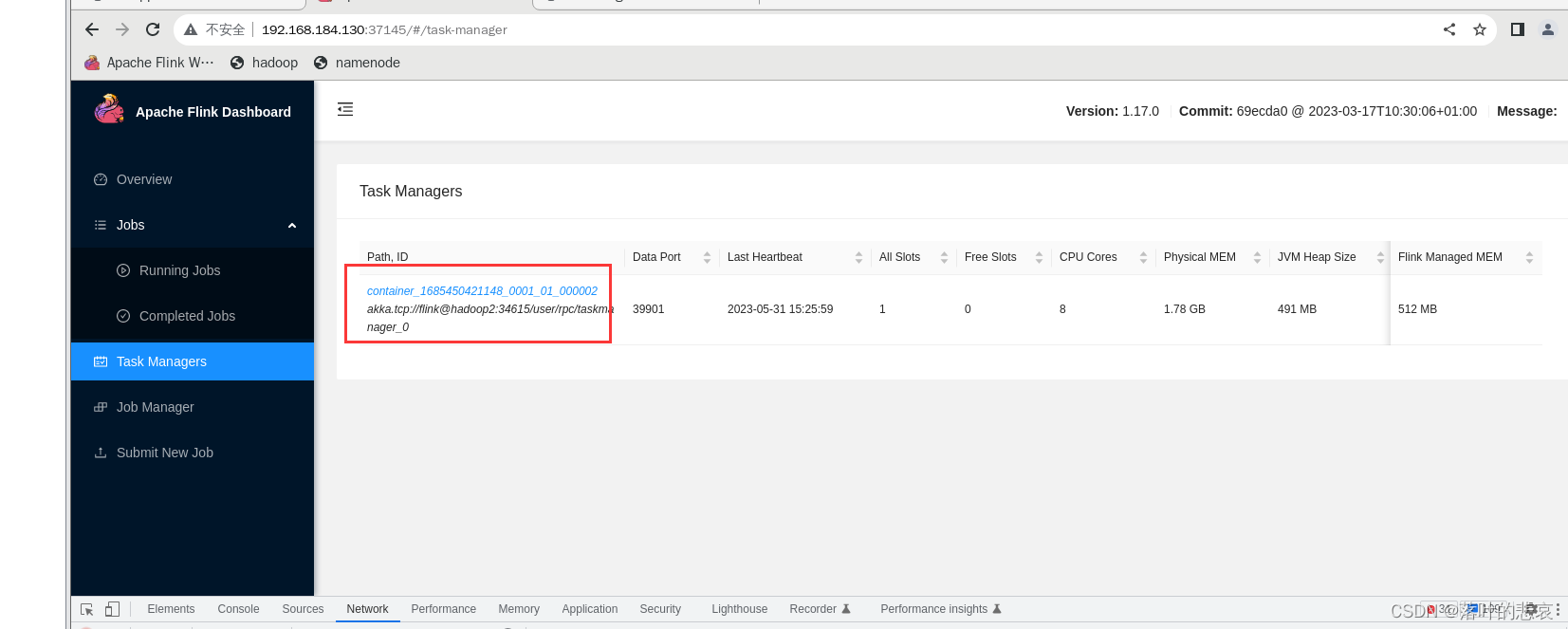
点击输出
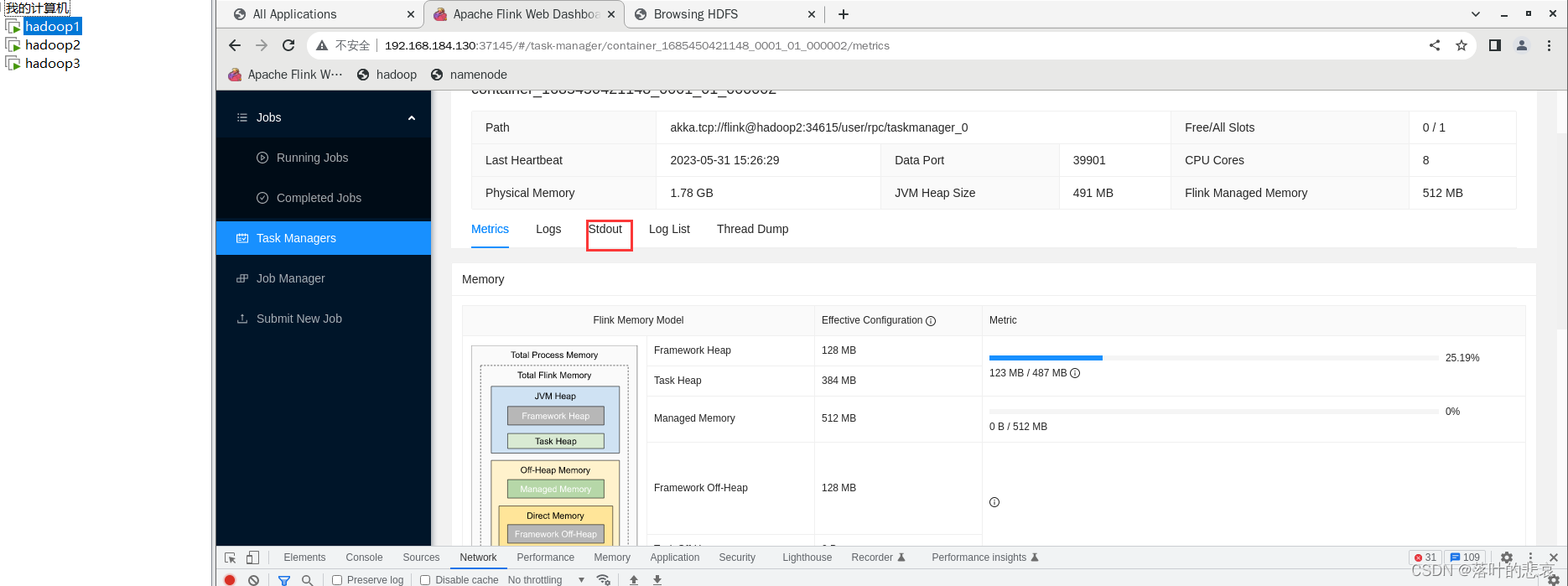
这里可以看到输出内容,
在kafka消费端输入内容,
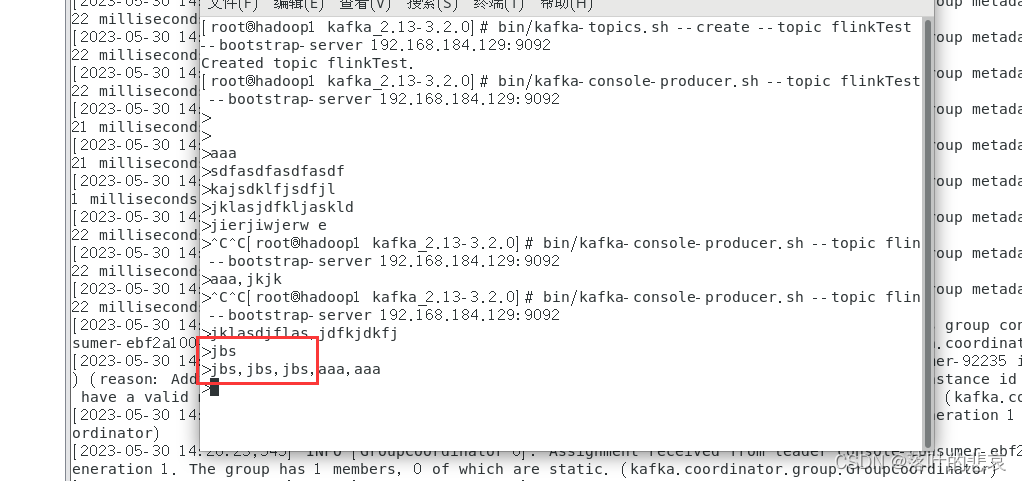
这里的jbs出现了4次,看下输出控制台,
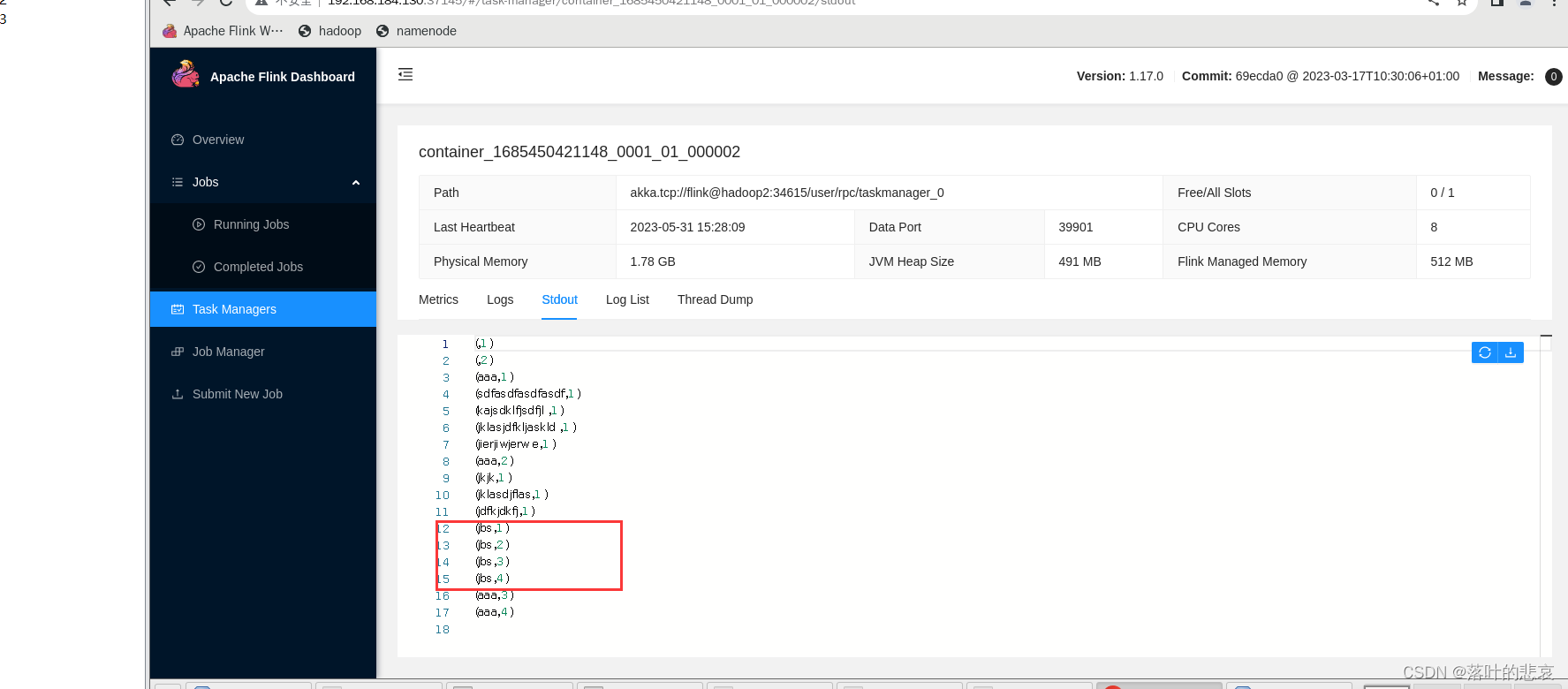
可以看到这里依次累加了四次,说明统计生效了。
总结
这里只是做了一个简单的消费kafka的flink例子,消费成功后还可以通过sink发送出去,还可以用transform进行转换,这里后面再演示,如果不对的可以指出。