mycat分库分表实验
在分库分表(如 MyCat 等中间件)场景中,全局表、分片表、ER 表是三种常见的表类型,分别不同的业务场景设计,用于解决数据分布和关联查询问题。
1. 全局表(Global Table)
定义:全局表是在所有分库中都存在完全相同副本的表,数据在所有分库中保持一致。
特点:
- 表结构和数据在每个分库中完全相同(同步更新)。
- 通常是数据量小、变动少、被频繁关联查询的表(如字典表、配置表)。
适用场景:
- 系统配置表(如
sys_config,存储全局参数)。 - 字典表(如
dict_region,存储省市地区信息)。 - 公共代码表(如
sys_code,存储性别、状态等枚举值)。
优势:
- 避免跨库关联查询(任何分库都能直接访问本地的全局表数据),提升查询效率。
- 数据变更时,MyCat 等中间件会自动同步到所有分库,保证一致性。
2. 分片表(Sharded Table)
定义:分片表是按一定规则(如哈希、范围、枚举)拆分到多个分库 / 分表中的表,单表数据被分散存储。
特点:
- 表结构相同,但数据分散在不同分库 / 分表中(每个分库只存一部分数据)。
- 依赖分片规则(如
mod_hash(CUSTOMER_ID))决定数据存储位置。
适用场景:
- 数据量大、增长快的核心业务表(如订单表、用户表、交易记录表)。
- 例:
orders表按CUSTOMER_ID哈希分片,不同用户的订单存储在不同分库。
优势:
- 突破单库单表的存储和性能瓶颈(数据分散后,单库压力降低)。
- 可根据业务规则灵活扩展(增加分库分表数量)。
3. ER 表(Entity Relationship Table)
定义:ER 表是与主表存在强关联关系(如父子关系)的表,跟随主表的分片规则存储,确保关联数据在同一分库。
特点:
- 依赖主表的分片键(如主表按
user_id分片,ER 表也按user_id分片)。 - 主表和 ER 表的数据一定在同一个分库,避免跨库关联。
适用场景:
- 存在紧密业务关联的表(如订单表
orders和订单明细表order_items)。- 主表
orders按customer_id分片,ER 表order_items也按customer_id分片,确保同一用户的订单和明细在同一分库。
- 主表
优势:
- 解决关联查询问题(主表和 ER 表在同一分库,可直接执行
JOIN查询,无需跨库)。 - 保证数据一致性(关联数据同库,事务操作更简单)。
三者对比
| 类型 | 数据分布特点 | 核心作用 | 典型场景 |
|---|---|---|---|
| 全局表 | 所有分库都有完整副本 | 支持高频关联查询,避免跨库 | 字典表、配置表 |
| 分片表 | 数据分散在不同分库 / 分表 | 拆分大数据量表,突破性能瓶颈 | 订单表、用户表 |
| ER 表 | 跟随主表分片,与主表同库 | 解决关联表的跨库查询问题 | 订单表与订单明细表 |
1. 全局表(Global Table)创建
全局表需要在所有分库中保持数据一致,创建时需指定 GLOBAL 关键字:
-- 创建全局表(字典表:存储省份信息)
CREATE TABLE province (id INT PRIMARY KEY,province_name VARCHAR(50) NOT NULL,province_code VARCHAR(20) NOT NULL
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4
GLOBAL; -- 关键:声明为全局表
特点体现:
- 表结构会同步到所有分库,且每个分库都有完整数据。
- 插入 / 更新数据时,MyCat 会自动同步到所有分库(例如
INSERT INTO province VALUES(1, '北京', '110000')会在所有分库生效)。 - 适用于数据量小、极少变动的公共表。
2. 分片表(Sharded Table)创建
分片表需指定分片规则(分库、分表策略),数据会按规则分散存储:
CREATE TABLE 表名 (字段定义... -- 常规表结构(主键、字段类型等)
) ENGINE=存储引擎 DEFAULT CHARSET=字符集
[分库规则配置]
[分表规则配置];
-- 创建分片表(订单表:按用户ID哈希分库分表)
CREATE TABLE orders (id BIGINT PRIMARY KEY AUTO_INCREMENT,order_type INT,customer_id INT NOT NULL, -- 分片键:用于确定数据存储位置amount DECIMAL(10,2),create_time DATETIME
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4
-- 分库规则:按 customer_id 哈希取模,分 2 个库
dbpartition BY mod_hash(customer_id)
dbpartitions 2
-- 分表规则:按 customer_id 哈希取模,每个库分 2 个表
tbpartition BY mod_hash(customer_id)
tbpartitions 2;
举例:
mod_hash(customer_id):对customer_id进行哈希计算后,再对分库数量(2)取模。- 计算结果只有两种可能:
0或1,分别对应两个不同的物理库(假设为db0和db1)。 - 当
customer_id=100时:hash(100) % 2 = 0→ 数据存到db0库。 - 当
customer_id=101时:hash(101) % 2 = 1→ 数据存到db1库。 - 与分库算法一致,也是对
customer_id哈希后对分表数量(2)取模。 - 计算结果为
0或1,对应目标库中的两个表(如orders_0和orders_1)。 - 若
customer_id=100已确定存到db0库,再计算hash(100) % 2 = 0→ 最终存到db0.orders_0表。 - 若
customer_id=102计算得存到db0库,且hash(102) % 2 = 1→ 存到db0.orders_1表。
特点体现:
- 表结构在所有分库中相同,但数据分散存储(例如
customer_id=100的订单和customer_id=101的订单会存在不同分库)。 - 插入数据时,MyCat 会根据
customer_id计算存储位置(如100%2=0存到第 1 个库,101%2=1存到第 2 个库)。 - 适用于数据量大、需拆分的核心业务表。
例子2
CREATE TABLE orders (id BIGINT PRIMARY KEY AUTO_INCREMENT,customer_id INT NOT NULL, -- 分库键order_id INT NOT NULL, -- 分表键amount DECIMAL(10,2),create_time DATE
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4
-- 分库:按 customer_id 哈希取模,分 2 个库
dbpartition BY mod_hash(customer_id)
dbpartitions 2
-- 分表:按 order_id 哈希取模,每个库分 3 个表
tbpartition BY mod_hash(order_id)
tbpartitions 3;3. ER 表创建
ER 表需关联主分片表,跟随主表的分片规则(确保关联数据在同一分库):
-- ER表:订单明细表(关联orders表)
CREATE TABLE order_items (id BIGINT PRIMARY KEY AUTO_INCREMENT,order_id BIGINT NOT NULL, -- 关联订单表的订单IDproduct_id INT NOT NULL, -- 商品IDquantity INT, -- 数量price DECIMAL(10,2), -- 单价-- 关键:必须包含与主表相同的分片键customer_id 主库的分片键customer_id INT NOT NULL, FOREIGN KEY (order_id) REFERENCES orders(id) -- 逻辑外键(实际由中间件维护)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4
!!-- 核心:分库分表规则必须与主表orders完全一致
dbpartition BY mod_hash(customer_id) -- 同主表的分库算法和分片键
dbpartitions 2 -- 同主表的分库数量
tbpartition BY mod_hash(customer_id) -- 同主表的分表算法和分片键
tbpartitions 2 -- 同主表的分表数量
-- 显式声明为orders表的ER表(部分中间件需要,增强可读性)
ER_PARENT = orders;
必须包含主表的分片键
order_items表中包含customer_id,且与主表orders的分片键完全一致,这是 ER 表路由的基础。分库分表规则与主表完全相同
- 分库算法(
mod_hash(customer_id))、分库数量(2)与主表一致。 - 分表算法(
mod_hash(customer_id))、分表数量(2)与主表一致。
确保customer_id相同的订单和其明细会被路由到同一个物理库、同一个物理表。
- 分库算法(
数据分布效果
若orders表中某订单的customer_id=100(存于db0.orders_0),则其对应的所有order_items记录也会存于db0.order_items_0,实现 “主表与 ER 表同库同表”。
三者核心区别对比
| 维度 | 全局表 | 分片表 | ER 表 |
|---|---|---|---|
| 数据分布 | 所有分库都有完整副本 | 数据分散在不同分库 / 分表 | 与主分片表存放在同一分库 |
| 创建关键字 | GLOBAL | 分库分表规则(如 dbpartition) | ER_PARENT(关联主表) |
| 同步性 | 数据变更自动同步到所有分库 | 数据仅存于对应分片,不同步 | 跟随主表分片,无需额外同步 |
| 关联查询 | 可直接与任何表本地关联 | 跨分片关联需中间件聚合 | 与主表同库,可 |
补充:
一、分库规则配置(dbpartition)
语法:
dbpartition BY 分片算法(分片键)
dbpartitions 分库数量;
1. 关键参数解析
dbpartition BY:指定分库的算法和分片键(用于计算数据存储的库)。dbpartitions:指定分库的总数量(必须与算法匹配)。
2. 常用分库算法(以 MyCat 为例)
| 算法 | 语法示例 | 适用场景 |
|---|---|---|
| 哈希取模 | dbpartition BY mod_hash(customer_id) | 按分片键哈希后取模,均匀分配数据(如用户 ID、订单 ID) |
| 范围分片 | dbpartition BY range(createtime) | 按时间、数值范围分片(如按月份分库:1-3 月存库 1,4-6 月存库 2) |
| 枚举分片 | dbpartition BY enum(city) | 按固定枚举值分片(如城市:北京存库 1,上海存库 2) |
| 一致性哈希 | dbpartition BY consistent_hash(id) | 解决哈希取模扩容时数据迁移问题,适合动态扩缩容 |
二、分表规则配置(tbpartition)
语法:
tbpartition BY 分片算法(分片键)
tbpartitions 分表数量;
1. 关键参数解析
tbpartition BY:指定分表的算法和分片键(用于计算数据存储的表)。tbpartitions:指定每个分库下的分表数量(总表数 = 分库数 × 每个库的分表数)。
2. 分表算法与分库的关系
- 分表算法可以与分库相同(如都按
customer_id哈希),确保同一用户的数据在同一库的同一表中。 - 也可以不同(如分库按
customer_id,分表按order_id),更灵活但需注意关联查询效率。
三、完整示例:分库 + 分表配置
CREATE TABLE orders (id BIGINT PRIMARY KEY AUTO_INCREMENT,customer_id INT NOT NULL, -- 分库键order_id INT NOT NULL, -- 分表键amount DECIMAL(10,2),create_time DATE
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4
-- 分库:按 customer_id 哈希取模,分 2 个库
dbpartition BY mod_hash(customer_id)
dbpartitions 2
-- 分表:按 order_id 哈希取模,每个库分 3 个表
tbpartition BY mod_hash(order_id)
tbpartitions 3;
数据分布逻辑:
- 当插入一条数据时,MyCat 先计算
customer_id % 2:- 结果 = 0 → 路由到第 1 个分库(如 db0)
- 结果 = 1 → 路由到第 2 个分库(如 db1)
- 再在目标分库中计算
order_id % 3:- 结果 = 0 → 存到表
orders_0 - 结果 = 1 → 存到表
orders_1 - 结果 = 2 → 存到表
orders_2
- 结果 = 0 → 存到表
最终总共有 2 个库 × 3 个表 = 6 个物理表 存储数据。
四、特殊配置:仅分库或仅分表
只分库不分表(每个库 1 张表):
CREATE TABLE orders (... ) dbpartition BY mod_hash(customer_id) dbpartitions 2; -- 不分表则不写 tbpartition 配置只分表不分库(1 个库多张表):
CREATE TABLE orders (... ) tbpartition BY mod_hash(order_id) tbpartitions 3; -- 不分库则不写 dbpartition 配置
10.3.1 准备四个数据库
| 名称 | ip | port |
|---|---|---|
| dw0 | 192.168.1.10 | 3306 |
| dr0 | 192.168.1.20 | 3306 |
| dw1 | 192.168.1.40 | 3306 |
| dr1 | 192.168.1.50 | 3306 |
10.3.2 配置MyCAT数据源
通过上面的配置,我们准备了两组主从,分别为:
1)主服务器dw0 从服务器dr0
2)主服务器dw1 从服务器dr1
注意每台服务器都要有远程账号并且有权限,两两配为主从
#### 1. 配置第一组主从(dw0 → dr0)
(1)主库 dw0(192.168.1.10)配置
编辑 MySQL 配置文件(/etc/my.cnf):
ini
[mysqld]
server-id = 105 # 唯一ID
log-bin = mysql-bin # 开启binlog重启 MySQL:systemctl restart mysqld
登录 dw0 的 MySQL,创建复制用户:
sql
CREATE USER 'rep'@'%' IDENTIFIED BY '123.com';
GRANT REPLICATION SLAVE ON *.* TO 'rep'@'%';
FLUSH PRIVILEGES;-- 查看主库状态(记录文件名和位置)
SHOW MASTER STATUS;
(2)从库 dr0(192.168.1.20)配置
编辑配置文件:
ini
[mysqld]
server-id = 106
relay-log = mysql-relay # 中继日志
重启 MySQL 后,登录配置主从:CHANGE MASTER TOMASTER_HOST = '192.168.1.10',MASTER_USER = 'rep',MASTER_PASSWORD = '123.com',MASTER_LOG_FILE = 'mysql-bin.000001',MASTER_LOG_POS = 824;START SLAVE;
-- 检查状态(确保Slave_IO_Running和Slave_SQL_Running为Yes)
SHOW SLAVE STATUS\G;
2. 配置第二组主从(dw1 → dr1)
(1)主库 dw1(192.168.1.40)配置
编辑/etc/my.cnf:
ini
[mysqld]
server-id = 107
log-bin = mysql-bin
重启 MySQL,创建复制用户:
sql
CREATE USER 'repl'@'%' IDENTIFIED BY '123.com';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
FLUSH PRIVILEGES;SHOW MASTER STATUS;
(2)从库 dr1(192.168.1.50)配置
编辑/etc/my.cnf:
ini
[mysqld]
server-id = 108
relay-log = mysql-relay
重启后配置主从:CHANGE MASTER TOMASTER_HOST = '192.168.1.40',MASTER_USER = 'repl',MASTER_PASSWORD = '123.com',MASTER_LOG_FILE = 'master.000002',MASTER_LOG_POS = 826;START SLAVE;
SHOW SLAVE STATUS\G; # 检查状态在mycat里配置
-- 添加dw0数据源
/*+ mycat:createDataSource
{ "name":"dw0","password":"123.com","url":"jdbc:mysql://192.168.1.10:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8", "user":"root",}
*/;-- 添加dr0数据源
/*+ mycat:createDataSource
{ "name":"dr0","password":"123.com","url":"jdbc:mysql://192.168.1.20:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8", "user":"root",}
*/;-- 添加dw1数据源
/*+ mycat:createDataSource
{ "name":"dw1","password":"123.com","url":"jdbc:mysql://192.168.1.40:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8","user":"root",}
*/;-- 添加dr1数据源
/*+ mycat:createDataSource
{ "name":"dr1","password":"123.com","url":"jdbc:mysql://192.168.1.60:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8","user":"root",}
*/;-- 查看数据源
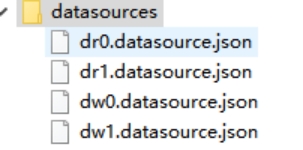
/*+ mycat:showDataSources{} */;执行之后我们在MyCAT里面看到如下数据源的配置文件。
10.3.3 配置MyCAT集群配置
注意:自动分片默认要求集群名字以c为前缀,数字为后缀:
1)c0就是分片表第一个节点;
2)c1就是第二个节点。
一般情况下我们使用默认的就可以了。
/*! mycat:createCluster{ "name":"c0", "masters":[ "dw0" ], "replicas":[ "dr0" ]} */;/*! mycat:createCluster{ "name":"c1", "masters":[ "dw1" ], "replicas":[ "dr1" ]} */;-- 查看集群
/*+ mycat:showClusters{} */;
创建完成之后查看MyCAT配置文件里面内容如下:
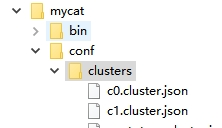
这个是文件里的东西就是我们前面命令执行的结果
{"clusterType": "MASTER_SLAVE","heartbeat": {"heartbeatTimeout": 1000,"maxRetryCount": 3,"minSwitchTimeInterval": 300,"showLog": false,"slaveThreshold": 0.0},"masters": ["dw0"],"maxCon": 2000,"name": "c0","readBalanceType": "BALANCE_ALL","replicas": ["dr0"],"switchType": "SWITCH"
}10.4 全局表(广播表)配置
定义:全局表是在所有分库中都存在完全相同副本的表,数据在所有分库中保持一致。
特点:
- 表结构和数据在每个分库中完全相同(同步更新)。
- 通常是数据量小、变动少、被频繁关联查询的表(如字典表、配置表)。
10.4.1 创建数据库
CREATE DATABASE db1 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
10.4.2 创建表
use db1;CREATE TABLE `sys_dict` ( `id` bigint NOT NULL AUTO_INCREMENT,`dict_type` int ,`dict_name` varchar(100) DEFAULT NULL,`dict_value` int , PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 BROADCAST;
# 上面的SQL中有一个BROADCAST 这个就是全局表的标识。10.4.3 查看结果
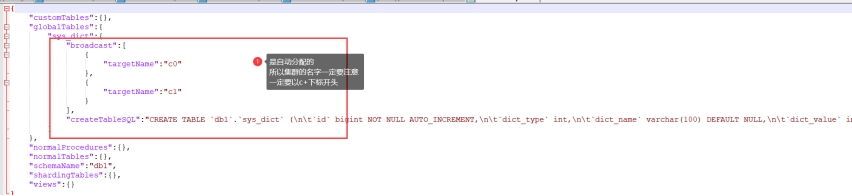
MyCAT的配置文件中:做完这一步才可以在主库这些地方看到数据库db1
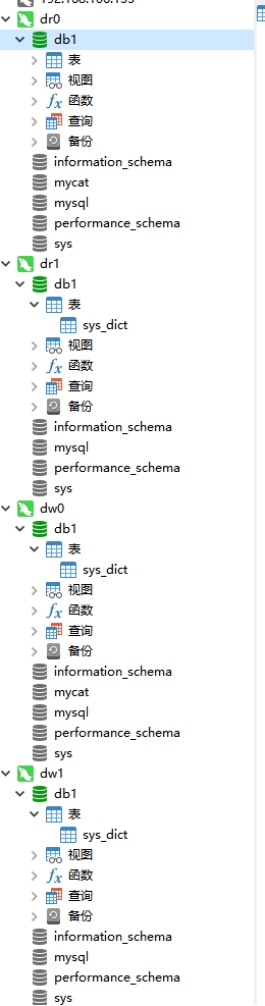
后端数据库中发现所有的表全部出现了。
10.4.4 添加数据查看结果 在mycat里
INSERT INTO sys_dict(dict_type,dict_name,dict_value) VALUES(1,"男",1);
INSERT INTO sys_dict(dict_type,dict_name,dict_value) VALUES(1,"女",0);# 所有的库中都有的数据10.5 分片表配置【重点】
定义:分片表是按一定规则(如哈希、范围、枚举)拆分到多个分库 / 分表中的表,单表数据被分散存储。
特点:
- 表结构相同,但数据分散在不同分库 / 分表中(每个分库只存一部分数据)。
- 依赖分片规则(如
mod_hash(CUSTOMER_ID))决定数据存储位置。
10.5.1 创建表
这个命令在主库1里创出来的库名叫db1_0 主库2:db1_1
主库1里的表orders_0 主库2: orders_1
相当于主1和主2加起来是完整的,从1和从2是对应主的备份。
CREATE TABLE orders( ID BIGINT NOT NULL AUTO_INCREMENT,ORDER_TYPE INT, CUSTOMER_ID INT,AMOUNT DECIMAL(10,2), PRIMARY KEY(ID)) ENGINE=INNODB DEFAULT CHARSET=utf8mb4 dbpartition BY mod_hash(CUSTOMER_ID) tbpartition By mod_hash(CUSTOMER_ID) tbpartitions 1 dbpartitions 2;# dbpartition BY mod_hash(CUSTOMER_ID): 指定数据库的分片算法及使用哪一条数据进行分片
# tbpartition BY mod_hash(CUSTOMER_ID) :指定表的分片算法及使用哪一条数据进行分片
# tbpartitions 1 表的分片数量
# dbpartitions 2 数据库的分片数量10.5.3 添加数据
INSERT INTO ORDERS(ID,ORDER_TYPE,CUSTOMER_ID,AMOUNT) VALUES(1,101,100,100101);
INSERT INTO ORDERS(ID,ORDER_TYPE,CUSTOMER_ID,AMOUNT) VALUES(2,101,100,100101);
INSERT INTO ORDERS(ID,ORDER_TYPE,CUSTOMER_ID,AMOUNT) VALUES(3,101,100,100101);
INSERT INTO ORDERS(ID,ORDER_TYPE,CUSTOMER_ID,AMOUNT) VALUES(4,102,101,101102);
INSERT INTO ORDERS(ID,ORDER_TYPE,CUSTOMER_ID,AMOUNT) VALUES(5,102,101,101102);
INSERT INTO ORDERS(ID,ORDER_TYPE,CUSTOMER_ID,AMOUNT) VALUES(6,102,101,101102);在mycat里查看结果SELECT * FROM orders;
10.5.4 查询后台物理库
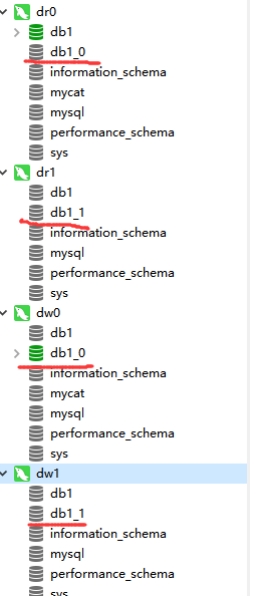
从图中我们可以看到数据库生成了。打开数据库后,里面的表也生成了,里面的数据也分开了,并不在一个表里。
10.5.5 MyCAT中查询
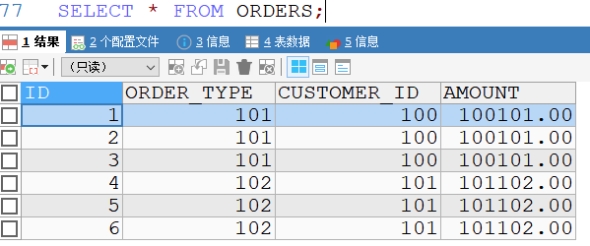
从上图中,我们发现查询的结果也帮我们合并了。
10.6 ER表配置
定义:ER 表是与主表存在强关联关系(如父子关系)的表,跟随主表的分片规则存储,确保关联数据在同一分库。
特点:
- 依赖主表的分片键(如主表按
user_id分片,ER 表也按user_id分片)。 - 主表和 ER 表的数据一定在同一个分库,避免跨库关联。
10.6.1 创建表
CREATE TABLE orders_detail( id BIGINT AUTO_INCREMENT,detail VARCHAR(2000),order_id BIGINT, PRIMARY KEY(ID)) ENGINE=INNODB DEFAULT CHARSET=utf8mb4 dbpartition BY mod_hash(order_id) tbpartition By mod_hash(order_id) tbpartitions 1 dbpartitions 2;# dbpartition BY mod_hash(order_id) :指定数据库的分片算法及使用哪一条数据进行分片HASHtbpartition
# BY mod_hash(order_id) :指定表的分片算法及使用哪一条数据进行分片
# HASHtbpartitions 1 表的分片数量
# dbpartitions 2 数据库的分片数量
10.6.2 查看MyCAT生成的配置
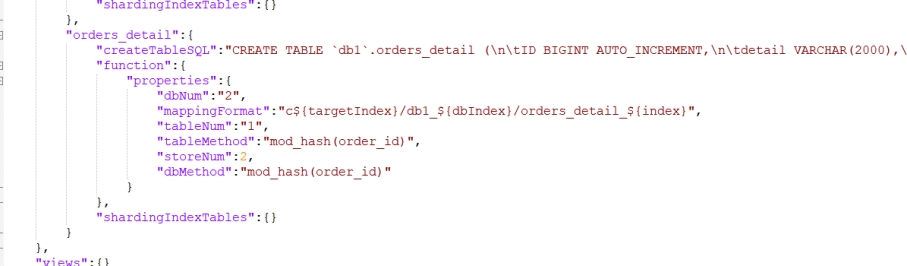
从上图中我们可以出已经放到分片表里面了。
10.6.3 添加数据
INSERT INTO orders_detail VALUES(1,"详情1",1);
INSERT INTO orders_detail VALUES(2,"详情2",2);
INSERT INTO orders_detail VALUES(3,"详情3",3);
INSERT INTO orders_detail VALUES(4,"详情4",4);
INSERT INTO orders_detail VALUES(5,"详情5",5);
INSERT INTO orders_detail VALUES(6,"详情6",6);
10.6.4 查询后台物理库
select * from orders_detail_0;
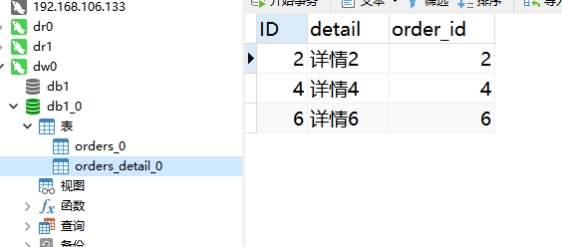
从上图可知,dw0里面只存了三条。
select * from orders_detail_1;
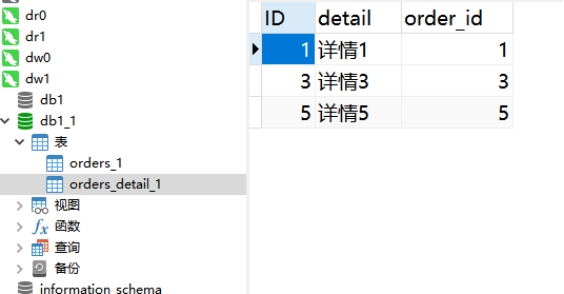
发现dw1里面也存放了三条。
10.6.5 MyCAT中关联查询
select * from orders_detail;
| select * from orders o inner join orders_detail od on(o.id=od.order_id) |
|---|
|

10.6.6 疑问
从物理库中我们看到一个库里面的详情数据和定义数据不配套,那是为什么呢?在1.6的版本里面是不允许的。
接下来我们说明下原因:
1)MyCAT2在涉及两个表的JOIN分片字段等价关系的时候可以完成JOIN的下推。
2)MyCAT2无需要指定ER表,是自动识别的。
3)查询配置的表是否具有ER关系 使用如下注释:
/*+ mycat:showErGroup{}*/
结果如下:

上面的group_id 表示相同的组,该组中的表具有相同的存储分布(在MyCAT2中它是这么规定的)。
当然
如果我只想做两台主,设备不要从设备,想要达到双主分库分表
mysql不用做到主从同步,什么都不用做,在mycat上配置文件修改的时候注意
如果是两台主的话,那就需要有两个不同的配置文件,而不是都写在同一个配置文件中

10.7 分片算法简介
一、核心作用:解决 “数据量大” 的问题
当单表数据量达到千万 / 亿级时,查询和写入性能会急剧下降。分片算法通过以下方式解决:
- 数据分散存储:将一张大表拆分成多个小表,分散到不同数据库节点,降低单库单表压力。
- 路由定位:根据分片键(如
id、user_id)计算数据存储的位置,确保查询时能快速定位到目标库表。 - 适配业务场景:不同业务的数据特点(如用户 ID 均匀分布、订单按时间增长)需要不同的分片策略,避免数据倾斜(某一分片数据过多)。
二、各算法的特点及适用场景
1. 取模哈希分片(MOD_HASH)
核心逻辑:基于分片键的哈希值取模,计算分库 / 分表下标。
- 同键分片(分库键 = 分表键):先算总表下标,再推导库下标(确保数据在同一库的对应表)。
- 异键分片(分库键≠分表键):库和表下标独立计算。
适用场景:
- 分片键是数值或字符串(会自动哈希为数值),且值分布均匀(如
user_id、order_id)。 - 适合高频按分片键查询的场景(如 “查询某用户的所有订单”)。
- 例:用户 ID 哈希取模后,可将不同用户的数据均匀分散到多个库表,避免热点用户集中。
2. 范围哈希分片(RANGE_HASH)
核心逻辑:优先按第一个字段分片,不存在则用第二个字段;字符串会截取部分内容后哈希取模。
适用场景:
- 需要多字段联合分片的场景(如优先按
id分片,id不存在时按user_id)。 - 字符串分片(如按手机号后 4 位分片,通过
截取下标参数控制)。 - 例:订单表优先按
order_id分片,无order_id时按user_id,灵活适配不同数据录入场景。
3. 字符串哈希分片(UNI_HASH)
核心逻辑:专为字符串优化的哈希算法,同键时通过复杂计算确保库和表的均匀分布。
适用场景:
- 分片键是字符串(如
username、device_id),需要更均匀的分布。 - 相比
MOD_HASH,对字符串的哈希计算更精细,减少哈希冲突导致的数据倾斜。 - 例:用户表按
username分片,确保不同长度 / 格式的用户名能均匀分布到各库表。
4. 日期哈希分片(YYYYDD)
核心逻辑:基于 “年 + 年内天数” 计算哈希(如 2023 年第 100 天 → 2023100),仅用于分库。
适用场景:
- 时间相关的表(如日志表、交易流水表),按时间范围查询频繁。
- 例:订单表按创建时间的
YYYYDD分片,可将 “2023 年 5 月” 的订单集中到部分库,方便按时间范围归档或查询。
三、为什么需要多种算法?
不同业务的数据特点差异很大:
- 电商订单表:
order_id是均匀增长的数值,适合MOD_HASH。 - 日志表:按时间生成,适合
YYYYDD按天分片,方便冷热数据分离。 - 用户表:
username是字符串,适合UNI_HASH确保均匀分布。
选择合适的算法能避免 “数据倾斜”(某一分片数据过多),并提升查询效率(按分片键查询时直接定位到目标库表)。
总结
这些分片算法是分库分表的 “核心路由规则”,决定了数据如何 “拆” 和 “查”:
- 拆:将大表分散到多个物理库表,突破存储和性能瓶颈。
- 查:通过分片键快速定位数据位置,避免全表扫描。
实际使用时需根据分片键类型(数值 / 字符串 / 日期)、数据分布特点(均匀 / 时间增长)和查询模式(按 ID 查 / 按时间查)选择合适的算法。
10.7.1 取模哈希分片 MOD_HASH
1)如果分片值是字符串则先对字符串进行Hash转换为数值类型
2)分库键和分表键是同键
3)分表下标=分片值%(分库数量*分表数量)
4)分库下标=分表下标/分表数量
5)分库键和分表键是不同键
6)分表下标= 分片值%分表数量
7)分库下标= 分片值%分库数量
create table travelrecord ( ....) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by MOD_HASH (id) dbpartitions 6 tbpartition by MOD_HASH (id) tbpartitions 6;
10.7.2 范围哈希分片 RANGE_HASH
1)RANGE_HASH(字段1, 字段2, 截取开始下标)
2)仅支持数值类型,字符串类型
3)当时字符串类型时候,第三个参数生效
4)计算时候优先选择第一个字段,找不到选择第二个字段
5)如果是字符串则根据下标截取其后部分字符串,然后该字符串hash成数值
6)根据数值按分片数取余
7)要求截取下标不能少于实际值的长度
8)两个字段的数值类型要求一致
create table travelrecord(...)ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by RANGE_HASH(id,user_id,3) dbpartitions 3 tbpartition by RANGE_HASH(id,user_id,3) tbpartitions 3;
10.7.3 字符串哈希分片 UNI_HASH
1)如果分片值是字符串则先对字符串进行hash转换为数值类型
2)分库键和分表键是同键
3)分库下标=分片值%分库数量
4)分表下标=(分片值%分库数量)*分表数量+(分片值/分库数量)%分表数量
5)分库键和分表键是不同键
6)分表下标= 分片值%分表数量
7)分库下标=分片值%分库数量
create table travelrecord ( ....) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by UNI_HASH (id) dbpartitions 6tbpartition by UNI_HASH (id) tbpartitions 6;
10.7.4 日期哈希分片 YYYYDD
1)仅用于分库
2)DD是一年之中的天数
3)(YYYY*366+DD)%分库数
create table travelrecord ( ....) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by YYYYDD(xxx) dbpartitions 8tbpartition by xxx(xxx) tbpartitions 12;