自然语言处理(NLP)技术的发展历史
自然语言处理(NLP)作为人工智能的重要分支,其发展历程跨越了大半个世纪,从早期的规则式尝试到如今的大模型时代,技术路径不断迭代,核心目标始终是实现人机间的自然语言交互。以下从关键阶段、技术突破和标志性成果三个维度,展开介绍 NLP 的发展历史:
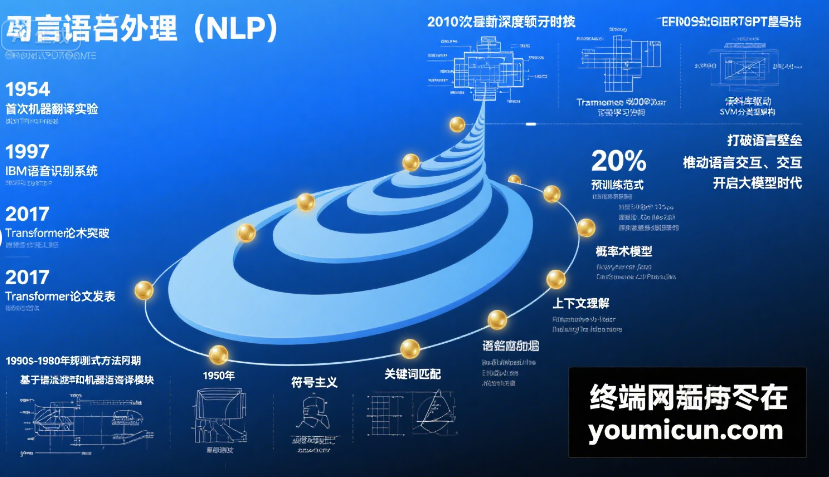
一、萌芽期(20 世纪 50-70 年代):规则驱动的初步探索
这一阶段的核心思路是通过人工定义语言规则来实现简单的语言处理,依赖语言学专家的知识编码。
- 标志性成果:
- 1954 年,IBM 与乔治城大学合作实现了首个机器翻译系统,将 60 句俄语自动翻译成英语,开创了 NLP 研究的先河。但受限于规则复杂度,翻译质量极低,且仅能处理特定领域短句。
- 1966 年,美国语言学家韦曾鲍姆(Joseph Weizenbaum)开发ELIZA,这是首个聊天机器人。它通过模式匹配(如识别 “我感到难过” 时回复 “你为什么感到难过?”)模拟对话,虽无真正理解能力,却让人们首次感受到人机对话的可能。
- 局限性:规则需人工编写,难以覆盖复杂语法、歧义语境和多样化表达,导致系统扩展性极差,很快陷入瓶颈。
二、统计学习期(20 世纪 80-90 年代):数据驱动的范式转变
随着计算机算力提升和语料库建设,NLP 从 “规则驱动” 转向 “统计驱动”,通过数学模型从数据中学习语言规律。
- 核心技术:
- 隐马尔可夫模型(HMM):广泛应用于语音识别和词性标注,通过概率计算处理语言序列的不确定性(如识别 “苹果” 是水果还是公司时,结合上下文概率判断)。
- 最大熵模型、条件随机场(CRF):提升命名实体识别(如识别 “北京” 是城市名)、句法分析等任务的准确率。
- 里程碑事件:
- 1994 年,Penn Treebank 语料库发布,包含大量标注了词性、句法结构的英语文本,为统计模型提供了标准化训练数据,推动了 NLP 的工程化落地。
- 2000 年左右,统计机器翻译(SMT)取代规则翻译成为主流,通过双语平行语料库(如汉英对照文本)学习翻译概率,翻译准确率较早期系统提升 30% 以上。
- 局限:依赖人工特征工程(如手动设计 “词性 + 上下文窗口” 特征),对长文本依赖和语义理解能力依然薄弱。
三、深度学习期(2010 年代):神经网络的颠覆性突破
2010 年后,深度学习技术(尤其是神经网络)主导 NLP 发展,通过多层非线性网络自动学习语言特征,摆脱了对人工特征的依赖。
- 关键突破:
- 词向量(Word Embedding):2013 年,Mikolov 等人提出 Word2Vec,将词语转化为低维稠密向量(如 “国王 - 男人 + 女人≈女王”),首次实现了词语语义的数值化表示,解决了传统 “独热编码” 无法捕捉语义关联的问题。
- 循环神经网络(RNN/LSTM/GRU):通过时序结构处理文本序列,在机器翻译、情感分析等任务中表现优于统计模型。2014 年,基于 LSTM 的神经机器翻译(NMT)系统问世,翻译质量远超统计方法。
- Transformer 架构:2017 年,Google 团队在《Attention Is All You Need》中提出 Transformer,以 “自注意力机制” 替代 RNN 的时序依赖,可并行处理文本,同时捕捉长距离语义关联(如一句话中 “他” 与前文 “小明” 的指代关系)。这一架构成为后续所有大模型的基础,标志着 NLP 进入 “预训练时代”。
- 代表性模型:
- 2018 年,Google 发布BERT(双向预训练模型),通过 “掩码语言模型(MLM)” 学习上下文语义,在问答、情感分析等 11 项任务中刷新纪录,推动 NLP 从 “单任务训练” 转向 “预训练 + 微调” 模式。
- 同期,OpenAI 的GPT 系列(生成式预训练模型)采用自回归方式生成文本,GPT-1(2018)、GPT-2(2019)逐步提升模型参数规模(GPT-2 达 15 亿参数),展现出强大的文本生成能力(如续写故事、撰写新闻)。
四、大模型时代(2020 年至今):通用智能的跨越
随着算力(如 GPU 集群)和数据量(万亿级文本语料)的爆发,NLP 进入 “大模型时代”,模型参数从百亿级跃升至万亿级,能力从 “专项任务” 向 “通用智能” 突破。
- 里程碑模型:
- GPT-3(2020):OpenAI 推出 1750 亿参数的 GPT-3,无需微调即可通过 “提示词(Prompt)” 完成翻译、编程、创作等多任务,展现出 “少样本学习” 能力,让人们看到通用人工智能(AGI)的曙光。
- GPT-4(2023):支持文本、图像等多模态输入,逻辑推理、复杂任务处理能力大幅提升(如解析图表、生成法律文书),成为商业化落地的标杆。
- 其他代表性模型:Google 的 PaLM(5400 亿参数)、 Anthropic 的 Claude(侧重安全性)、国内的百度文心一言、阿里通义千问等,推动大模型向行业场景渗透。
- 技术趋势:
- 多模态融合:NLP 与计算机视觉、语音识别结合(如 “文本 + 图像” 生成视频、“语音 + 手势” 交互),突破单一模态限制。
- 高效训练与压缩:通过模型量化、知识蒸馏等技术,降低大模型部署成本(如 GPT-3 的轻量版可在手机端运行)。
- 安全与对齐:通过 “人类反馈强化学习(RLHF)” 减少模型偏见,确保生成内容符合伦理规范(如避免虚假信息、歧视性言论)。
总结:NLP 发展的核心逻辑
从 “人工规则” 到 “统计学习”,再到 “深度学习” 和 “大模型”,NLP 的发展史本质是 **“数据 + 算力 + 算法” 协同进化 ** 的过程:数据规模从百万级到万亿级,算力从单机到分布式集群,算法从线性模型到复杂神经网络。未来,随着技术进一步突破,NLP 将更深度地融入日常生活,成为连接人类与智能系统的 “自然语言桥梁”。