【QT入门到晋级】进程间通信(IPC)-socket(包含性能优化案例)
前言
本文适合对原生socket、指针不熟悉的QT开发者阅读。前半篇从系统内核与socket的关系回顾socket的知识点,后半篇从C++ QT的网络编程切入来理解socket编程及典型的性能优化方法(零拷贝、IPC-共享内存、环形队列)。
上一篇【QT入门到晋级】进程间通信(IPC)--管道(包含代码)-CSDN博客篇尾提到少量数据流的进程间通信场景,管道的性能明显比socket套接字高,以下从内核的角度详细的展示。
socket简顾
来源
socket套接字是米国加州大学伯克利分校的计算机系统研究组共享出来的“网络编程组件”,目的是解决不同主机的进程之间进行通信的问题。
与内核(TCP/IP协议栈)的关系
系统内核的网络通信是通过TCP/IP协议栈构成的,相当于网络通信的基础规则集,而Socket是开发者调用这些规则的“工具包”。通过Socket接口,应用程序无需直接操作协议栈即可实现高效通信。
比如当客户端调用connect()函数发起TCP连接时,会触发TCP协议的三次握手过程,这个过程开发者不需要在socket编程中编写3次握手的规则,由协议栈自动完成交互。
比如TCP通信中,send()发送数据之后,如果数据丢包,会自动重传,不需要在socket编程中编写重传机制。
模型层级及协议栈层级
计算机网络知识中,常接触的两种模型:OSI七层模型和TCP/IP四层模式,以下是对比分享
| OSI七层模型 | TCP/IP四层模型 | 说明 |
|---|---|---|
| 应用层 表示层 会话层 | 应用层 | HTTP、FTP、DHCP、TELNET、DNS、RTSP、RTMP等协议, 由用户态应用程序实现 |
| 传输层 | 传输层 | TCP/UDP协议(RTP/RTCP) 运行于内核态 |
| 网络层 | 网际层(IP层) | IP、ICMP、IPSec、ARP 运行于内核态 |
| 数据链路层 物理层 | 网络接口层 | 驱动程序和硬件交互(如网卡DMA--零拷贝)由内核处理 用户态可通过DPDK等框架直接操作数据链路层 |
说明:ARP在TCP/IP四层模型中属于网际层,因其依赖IP地址进行寻址,且与IP协议协同工作;但在OSI模型中属于数据链路层,因其核心功能是通过IP地址解析MAC地址,直接服务于链路层通信。
从以上表格的说明中,涉及到内核态的即是TCP/IP协议栈的工作内容:不包含处于用户态的应用层,以及操控硬件的物理层。完全运行于操作系统内核态,负责数据包的封装、路由、传输控制等核心功能
| 层级 | 所属空间 | 功能 | 典型协议 |
|---|---|---|---|
| 应用层 | 用户态 | 生成/解析用户数据 | HTTP, FTP, DNS |
| 传输层 | 内核态 | 端到端数据传输控制 | 连续的字节流:TCP(数据重组,丢失重传) 独立的报文:UDP(数据不重组,允许丢失) |
| 网络层 | 内核态 | 寻址、路由、分片 | ICMP协议:网络诊断与错误控制(ping、 IP协议:处理数据包路由 ARP协议:处理IP寻址 |
| 链路层 | 内核态 | 通过网卡驱动,控制网卡硬件,完成数据帧传输 | Ethernet, Wi-Fi 将IP包封装为以太网帧(添加MAC头),通过DMA写入网卡缓冲区 |
ARP的寻址:当主机A需要向同一局域网内的主机B发送数据时,若不知道B的MAC地址,会广播ARP请求包(包含目标IP地址),主机B收到请求后,单播回复ARP响应包,携带自己的MAC地址(TCP/IP协议栈中会记录这个ARP表,下次主机A再向主机B发送数据时,会先查此ARP表获取B的MAC地址)。
数据流向图
以下是以socket接口为起始,到物理层发送数据的数据流向图:
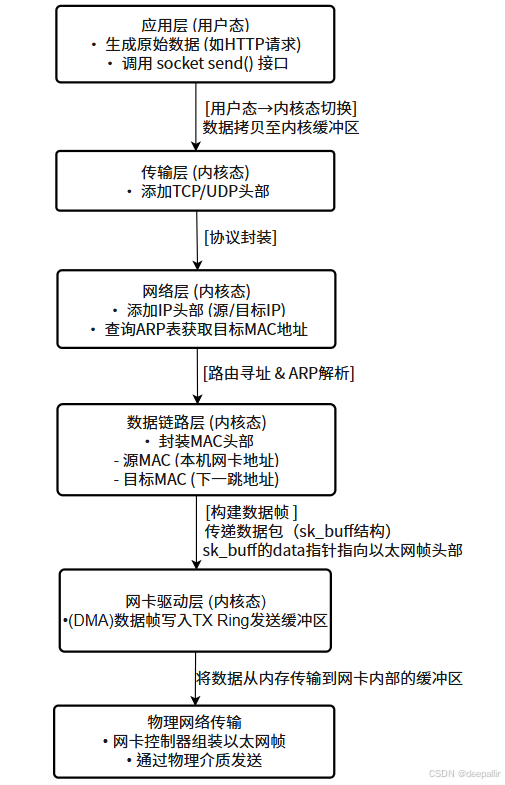
socket开发
socket套接字是解决不同主机的进程之间进行通信,因为基于网络,也常直接称其为网络编程。在进程间通信(IPC),socket套接字专注于跨主机的进程之间的通信(同一台主机的进程之间也可以通过socket通信,但是经过以上数据流程的封装,效率肯定是几种IPC中最低的)。
两端想要通信,那么至少要存在一个服务端,绑定IP和端口对外提供访问服务。以下通过QT提供的QTcpServer和QTcpSocket接口,讲解TCP服务端和客户端。
QT--TCP服务端开发
原生socket搭建服务端至少要4个步骤:socket()→ bind()→ listen()→ accept()
QT的QTcpSocket简化为2步+信号处理:构造对象→ listen()→newConnection()信号
| 操作步骤 | 传统 Socket API |
|
|---|---|---|
| 创建 Socket |
| 构造函数自动完成 |
| 绑定地址端口 |
|
|
| 启动监听 |
|
|
| 接受连接 |
|
|
需要注意的是,QTcpServer仅负责接收连接,返回已连接的QTcpSocket对象,完成以上步骤之后,QT需要在onNewConnection槽函数中通过QTcpSocket进行数据传输:
//等待链接的槽函数
void MyTcpServer::onNewConnection() {QTcpSocket *clientSocket = nextPendingConnection();//获取新连接的 QTcpSocket对象QString clientIp = clientSocket->peerAddress().toString();//获取对端的IP地址//连接 readyRead 信号,接收数据connect(clientSocket, &QTcpSocket::readyRead, this, &MyTcpServer::onClientReadyRead);// 自动释放资源//connect(clientSocket, &QTcpSocket::disconnected, clientSocket, &QTcpSocket::deleteLater);
}//接收数据的槽函数
void MyTcpServer::onClientReadyRead() {QTcpSocket *socket = qobject_cast<QTcpSocket*>(sender());if (!socket) return;QByteArray data = socket->readAll();//读取全部数据QString clientIp = clientMap.value(socket);// 回复消息给客户端---不一定回复,只是展示怎么发送数据给客户端socket->write("data recv OK");
}实际上原生的socket也需要定义两个socket描述符分别用于处理连接和接收数据,QT封装的方法更容易让人理解。
封装的非阻塞模式
QT对QTcpServer接口进行了深度封装,网络通信是异步的,不是信号和槽机制带来的异步特性,而且加入了多路复用I/O(linux-epoll,window-IOCP/select)机制,此机制基本能支持千级的并发量,因为epoll本身是单线程处理大量并发连接(典型的例子--数据缓存工具redis),如果需要万级以上时,可以加入多线程管理机制来提高并发量。
原生socket的accept()默认是阻塞模式,即同一时间Server只能处理一个Client请求,在使用当前连接的socket和client进行交互的时候,不能够accept新的连接请求。没有并发需求的场景下可以用这种代码简易的阻塞模式(socket()→ bind()→ listen()→ accept())。
当然socket服务端也可以使用非阻塞模式,可以通过fcntl设置非阻塞模式+select轮询机制来实现,关键代码如下:
fcntl(sock, F_SETFL, flags | O_NONBLOCK);
while(1){int res = select(maxfd + 1, &readfds, NULL, NULL, &timeout);if (res == -1) {perror("select failed");exit(EXIT_FAILURE);} else if (res == 0) {fprintf(stderr, "no socket ready for read within %d secs\n", SELECT_TIMEOUT);continue;}//... ...
}提高性能
即使是简单的一对一的server<-->client应用场景,比如文件传输,当需要传输大量的文件时,需要在基础的传输机制上进行性能优化,此时需要深入理解TCP/IP协议栈,以及C++的特性(多线程、文件读写、内存管理等特性)。
用户态<-->内核态切换
应用程序一般申请的缓存都是在用户态,此时会涉及一次用户态的IO操作(比如应用程序读取一个文件内容到内存中),应用程序把用户态的内容组装后调用socket的发送函数send()的,用户态到内核态的切换又涉及一次IO操作,此时如果传输的是大量的文件,就会产生大量的IO操作。
针对以上IO频繁调用的问题,linux的原生socket提供了系统级零拷贝函数sendfile(),其实现原理如下:
- 用户调用 sendfile后,内核通过 DMA 控制器将磁盘文件数据直接加载到内核页缓存中,无需 CPU 参与;
- CPU 将内核缓冲区的文件描述符(内存地址、数据长度等元数据) 复制到 Socket 缓冲区,而非数据本身;
- DMA 控制器读取 Socket 缓冲区中的描述符,直接从内核页缓存中抓取数据并发送到网卡,完全绕过 CPU 数据拷贝。
以下是与传统的wirte对比
| 步骤 | 传统 | |
|---|---|---|
| 头部封装 | 协议栈在 | 协议栈在 |
| 数据拷贝次数 | 4 次(磁盘→内核→用户→内核→网卡) | 2 次(磁盘→内核→网卡,仅 DMA) |
| CPU 参与数据搬运 | 是 | 否(仅头部封装) |
| 用户态切换次数 | 4 次 | 0 次(全程内核态) |
以上性能优化,适用于静态文件传输(大文件、或者文件多)的场景,不适用于需实时处理数据(比如需要对数据进行实时加密、压缩)的场景。
需要注意的是,QT并没有封装sendfile()函数,需要自己调用原生的socket接口。
#include <sys/sendfile.h>
#include <unistd.h>qint64 send_file(int sock_fd, QFile &file) {off_t offset = 0;return sendfile(sock_fd, file.handle(), &offset, file.size());
}// 在QTcpSocket连接后调用
QTcpSocket *socket = new QTcpSocket;
socket->connectToHost("server", 1234);
if (socket->waitForConnected()) {QFile file("largefile.bin");if (file.open(QIODevice::ReadOnly)) {send_file(socket->socketDescriptor(), file);}
}共享内存
如果传输的不是静态文件,而是图片等动态获取到的数据,保存到本地再传,起不到提升性能的效果。反而是要契合“动态”的特性进行性能提升,共享内存即是很好的方案。
共享内存(Shared Memory)也是进程间通信(IPC)方式之一,本文不详细讲解共享内存,仅通过以下特性分享本人曾经项目中结合socket+共享内存实现的一个高效率的零拷贝方案,方便阅读者从实际项目应用中了解到技术结合点。
- 多个进程可直接访问同一块物理内存区域实现数据共享;
- 物理内存由内核管理(内核态),用户态的进程可以通过内存映射的方式直接读写共享内存区域。
项目场景
这是一个上网行为管理器设备项目,在一个具备路由功能的Linux服务器上实现对流经数据的上网行为分析。
首先,这是一个具备路由功能的Linux服务器,上网行为分析不能影响到路由功能,旁路模式,是正常数据流的一个完整拷贝,不干扰正常数据通信。
其次,上网行为分析由多个行为分析应用组成(即多个应用进程),分析的数据都是旁路拷贝过来的(一份)数据,这个生产消费模式契合共享内存的【多个进程】之间访问一份数据(存放于共用的物理内存区域)特性。
以下先给出项目零拷贝方案与普通方案的对比流程图,下面逐步讲解。
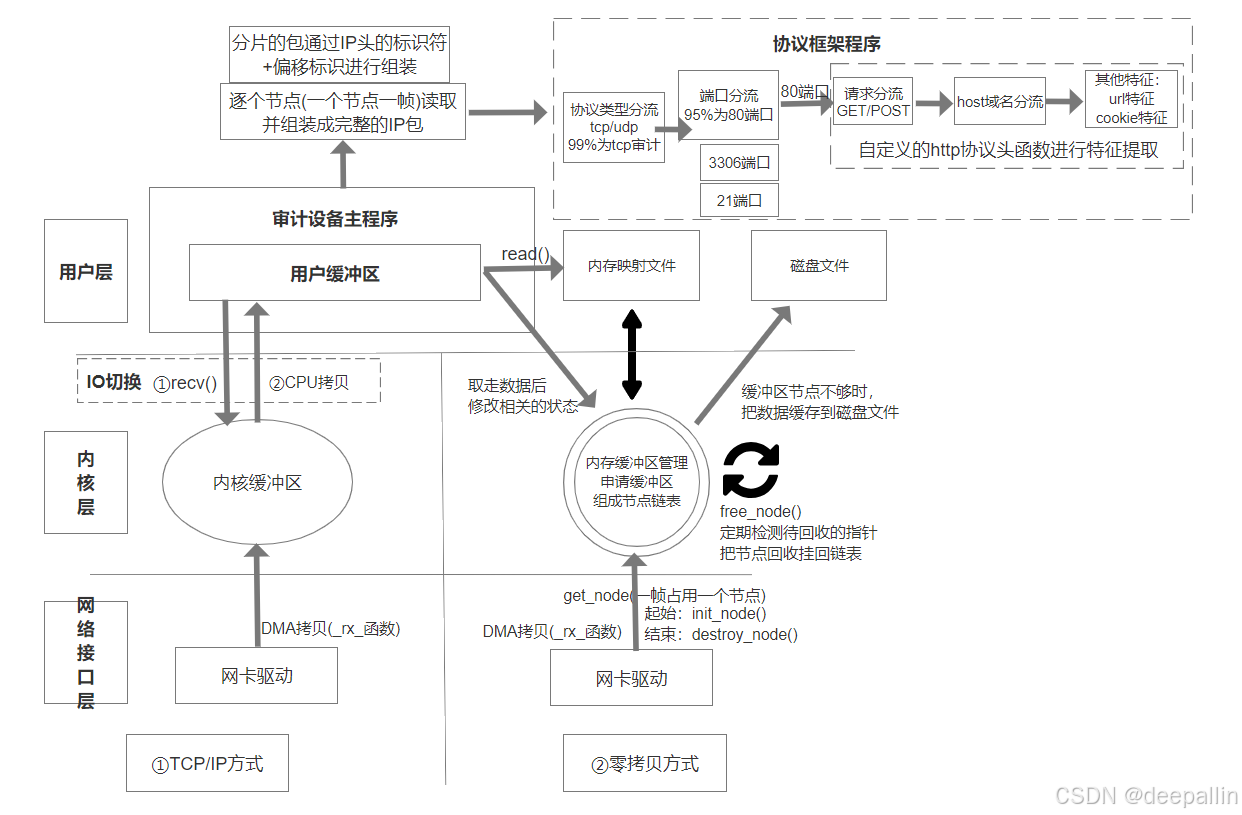
左边是常规的socket开发的数据流程图,可以在设置为混杂模式的情况下,通过qcap抓包后进行分析,这种方法仅适合流经数据很少的场景,大流量数据就会导致TCP/IP协议栈的内核缓冲区被塞满,导致数据丢失及延迟等现象。
右边是零拷贝方案,把旁路上传的数据存在共享内存申请的内存缓冲区中(自己管理数据的写入和释放),多个审计设备主程序(行为分析应用进程),通过内存映射,不需要把数据拷贝到用户层,直接遍历共享内存中的数据链表节点数据,并提交行为分析数据给到协议框架(协议框架与应用层交互,这个内容超出共享内存,流程图不做展示)。
同时,共享内存是一个环状的链表(首尾合一的环形缓冲区),能让数据更高效的覆盖式擦写数据,可参考这篇模拟环形缓冲区的文章
【Linux C/C++开发】队列缓存--环形缓冲区(包含C++ QT代码)_qt环形缓冲区-CSDN博客
这篇文章用的用户态常见的容器来演示案例,方便理解技术点的构建,通过共享内存实现的案例需要自己找deepseek提供,或者我在后续的IPC-共享内存中提供。
篇尾
网络上两个终端设备得以通信,是系统内核的TCP/IP协议栈提供了稳定的支撑,Socket是TCP/IP协议栈实现高效通信的“工具包”,也是因为TCP/IP协议栈必须经历的封装流程,导致socket通信是进程间通信“最慢”的,但是,如果数据很多,并发要求又不是很高的场景,其实也是可以选择socket,而不是一定要用共享内存的。