数据结构:深入解析常见数据结构及其特性
线性结构
数组
数组是一种非常基础且常用的线性数据结构,它具有一个显著的特性 —— 随机访问性。所谓随机访问性,是指我们可以通过元素的索引值,直接定位并访问数组中的任意元素,不需要像某些结构那样逐个遍历。就好比在一个编排好号码的储物柜群中,我们可以根据储物柜的编号直接找到对应的柜子,而无需从第一个柜子开始逐个查找。这种特性使得数组在查找元素时效率极高,时间复杂度为 O (1)。
二分查找
二分查找是一种基于数组随机访问性的高效查找算法。它的原理是:在一个有序的数组中,先找到数组的中间元素,将目标值与中间元素进行比较。如果目标值等于中间元素,则查找成功;如果目标值小于中间元素,则在数组的左半部分继续进行二分查找;如果目标值大于中间元素,则在数组的右半部分继续查找。如此反复,直到找到目标值或者确定数组中不存在该目标值。
class Solution {public int search(int[] nums, int target) {int left=0;int right=nums.length-1;int middle=0;while(right>=left){middle=left+(right-left)/2;if(nums[middle]<target){left=middle+1;}else if(nums[middle]>target){right=middle-1;}else{return middle;}}return -1;}
}二分查找的适用条件是数组必须是有序的,其时间复杂度为 O (logn),相比线性查找的 O (n),在数据量较大时,效率提升非常明显。例如,在一个包含 1000 个元素的有序数组中,使用线性查找最坏情况下需要比较 1000 次,而二分查找最坏情况下只需 10 次左右。
数组与链表的对比
数组和链表都属于线性结构,但它们在特性和适用场景上有很大的区别。
- 访问方式:数组具有随机访问性,能通过索引直接访问元素;而链表只能通过指针逐个遍历元素,不支持随机访问,访问某个元素的时间复杂度为 O (n)。
- 插入和删除效率:数组在插入和删除元素时,需要移动大量的元素,时间复杂度为 O (n);而链表在插入和删除元素时,只需修改相关节点的指针,时间复杂度为 O (1)(在已知前驱节点的情况下)。
- 内存存储:数组在内存中是连续存储的,需要预先分配固定大小的内存空间,可能会造成内存浪费或溢出;而链表在内存中是分散存储的,节点之间通过指针连接,内存利用率更高,且可以动态扩展。
树结构
红黑树
红黑树是一种自平衡的二叉查找树,它通过一系列规则来保证树的平衡,从而确保查找、插入和删除操作的时间复杂度都能保持在 O (logn)。红黑树的规则如下:
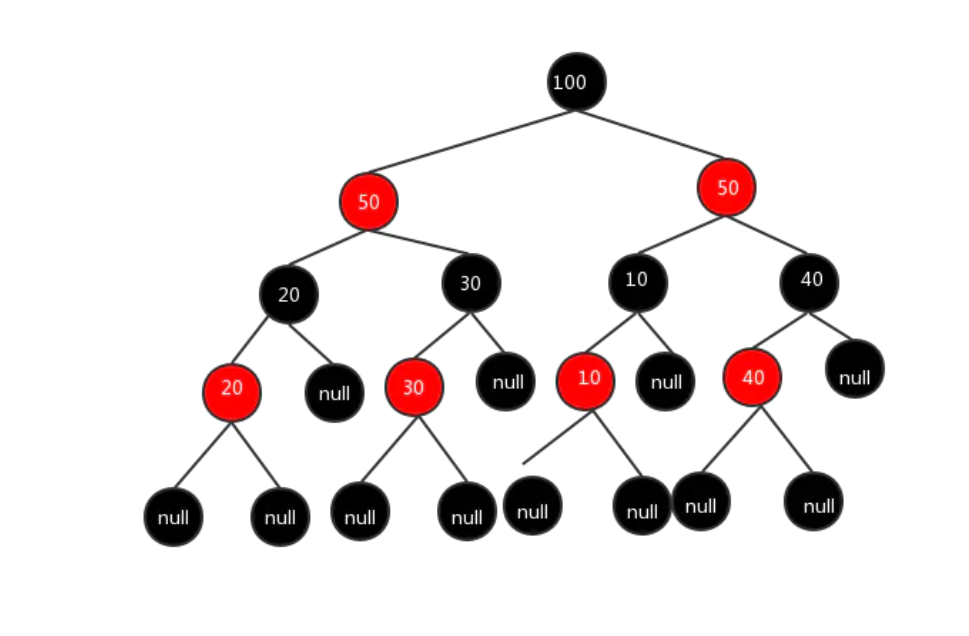
- 根节点是黑色的。
- 所有的叶子节点都是黑色的(这里的叶子节点通常指的是空节点)。
- 每个节点非红即黑。
- 如果一个节点是红色的,则它的子节点必须是黑色的,也就是说不会有连续的红色节点。在一些情况下,一个节点最多临时会有 3 个子节点,中间是黑色节点,左右是红色节点。
- 从任意节点到它的叶子节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。在红黑树中,每一层都只是有一个节点贡献了树高决定平衡性,这个节点就是对应红黑树中的黑色节点。
这些规则共同作用,使得红黑树在进行插入、删除等操作时,能够通过旋转和变色等方式保持平衡,保证了高效的操作性能。
B + 树
B + 树是 B - 树的变体,也是一种多路搜索树,它在数据库索引等场景中有着广泛的应用。其定义基本与 B - 树相同,但存在一些区别:
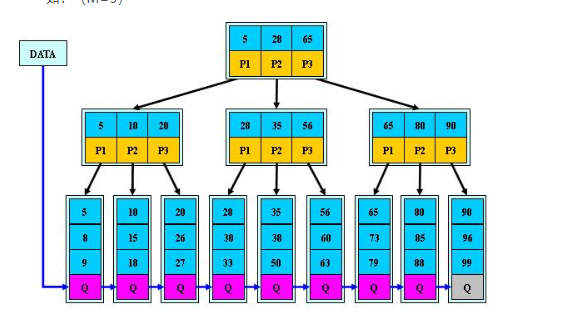
- 非叶子结点的子树指针与关键字个数相同。
- 非叶子结点的子树指针 P [i],指向关键字值属于 [K [i], K [i+1]) 的子树(B - 树是开区间)。
- 为所有叶子结点增加一个链指针,这样可以方便地进行范围查询。
- 所有关键字都在叶子结点出现,非叶子节点只起到索引的作用。
由于所有关键字都存储在叶子节点,且叶子节点之间通过链指针连接,B + 树非常适合范围查询操作,这也是它在数据库索引中被广泛使用的重要原因。
其他相关知识
类的结构
在 Java 中,一个类文件里只能有一个 public class,并且这个 public class 的类名必须与文件名相同。这是 Java 语言的语法规定,这样做可以保证编译器能够正确地识别和编译类文件。
在 main 方法中调用其他方法时,由于 main 方法是 static 方法,而 static 方法属于类,不属于实例对象,所以在调用非 static 方法时会出现问题。解决这个问题有两种方式:
- 将被调用的方法也声明为 static,这样就可以在 main 方法中直接调用。
- 在 main 方法中创建该类的实例对象,然后通过实例对象来调用非 static 方法。例如:
public class Solution {public void method() {// 方法体}public static void main(String[] args) {Solution s = new Solution();s.method();}
}
hashset 的底层实现
hashset 是 Java 中的一种集合,它的底层实现是 hashmap。hashset 中的元素作为 hashmap 的 key 存储,而 hashmap 的 value 则是一个固定的 Object 对象。这样实现的原因是 hashmap 的 key 具有唯一性,正好符合 hashset 中元素不可重复的特性。
hashset 继承了 hashmap 的一些特性,例如它的元素是无序的,查找元素的时间复杂度平均为 O (1) 等。同时,hashset 也没有提供像 hashmap 那样的 get 方法,因为它只关注元素的存在性,而不关注与元素相关联的值。