Infusing fine-grained visual knowledge to Vision-Language Models
Infusing fine-grained visual knowledge to Vision-Language Models
Authors: Nikolaos-Antonios Ypsilantis, Kaifeng Chen, André Araujo, Ondřej Chum
Deep-Dive Summary:
视觉-语言模型中注入细粒度视觉知识
摘要
大规模对比预训练产生了强大的视觉-语言模型(VLMs),这些模型能够生成对多种视觉和多模态任务有效的表示(嵌入)。然而,这些预训练的嵌入对于细粒度的开放集视觉检索仍然不够理想,在这一领域中,当前最先进的结果需要使用带标注的领域特定样本对视觉编码器进行微调。单纯地进行这种微调通常会导致灾难性遗忘,严重削弱模型的通用视觉和跨模态能力。
在本文中,我们提出了一种明确设计的微调方法,旨在在细粒度领域适应和保留预训练VLM广泛多模态知识之间实现最佳平衡。受到持续学习文献的启发,我们系统地分析了旨在知识保留的标准正则化技术,并提出了一种高效且有效的组合策略。此外,我们还解决了验证集设计和超参数调整这些常被忽视但至关重要的方面,以确保跨数据集和预训练模型的可重复性和稳健泛化能力。我们在细粒度和粗粒度的图像-图像和图像-文本检索基准上广泛评估了我们的方法。我们的方法始终取得了强劲的结果,特别是在微调过程中不使用任何文本数据或原始文本编码器的情况下,仍然保留了视觉-文本对齐。代码和模型检查点:https://github.com/nikosips/infusing。
1. 引言
视觉与语言模型(Vision-and-Language Models, VLMs),如 CLIP [23]、SigLIP [40] 和 TIPS [14],通过在大规模图像-文本对数据集上进行预训练,在各种视觉和多模态任务中展现出了卓越的性能。这些模型学习到了丰富的通用多模态嵌入,使得通过基于嵌入的相似性搜索实现有效的跨模态和视觉检索成为可能。因此,VLMs 已成为众多应用领域的基础工具,涵盖从通用图像检索到特定领域的专业应用。
一个关键的特定应用领域是细粒度开放集视觉检索。这类任务包括服装检索 [26]、食物识别 [19] 和物种识别 [29] 等,模型需要在视觉上相似但语义上不同的类别之间进行区分。在这些情况下,通常仅使用 VLM 的视觉编码器,将其用于离线索引大规模图像数据库,并在推理时处理基于图像的查询。为了提高效果,视觉编码器通常使用专家标注的细粒度数据集进行训练,但部署时需要对未见过的类别执行检索,因此称为开放集。
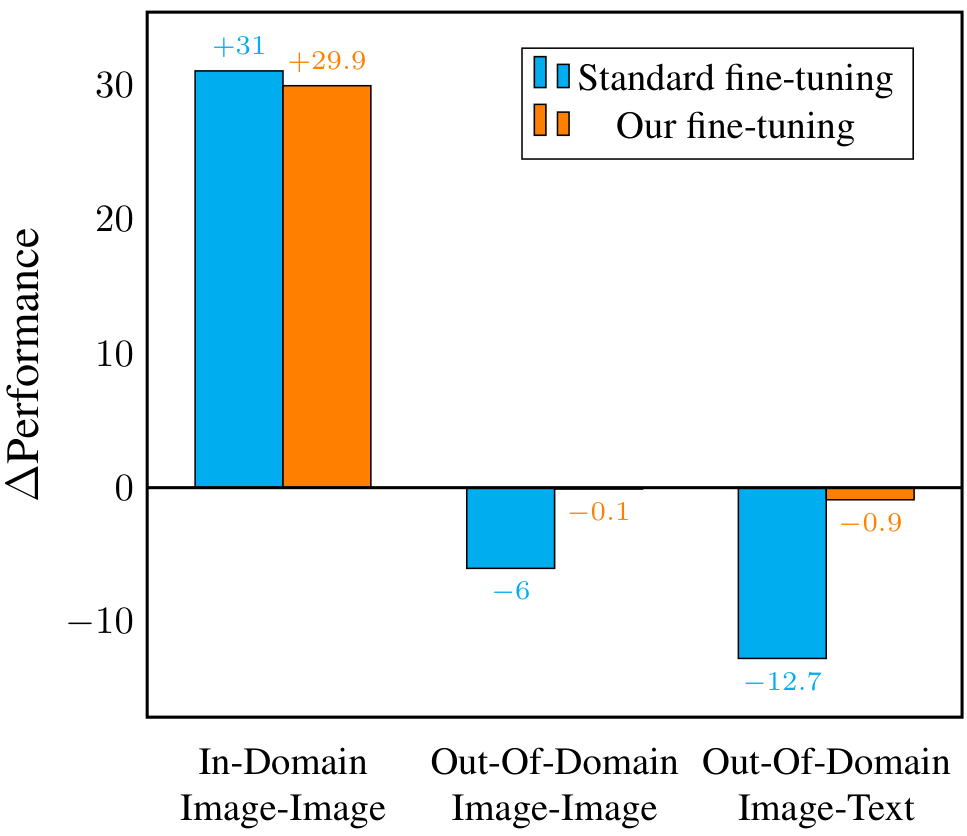
虽然预训练的 VLM 视觉编码器在通用视觉理解方面代表了当前最先进的技术 [14, 15, 28, 40],但在未经领域特定微调的情况下,它们在细粒度识别任务上的表现并非最优 [37]。当前的最佳实践 [7, 22, 24, 30, 37, 38] 涉及使用领域特定的标注数据对视觉编码器进行微调,显著提升目标领域内的性能。然而,这种方法存在显著的局限性。首先,在领域特定数据上进行微调通常会削弱模型的通用能力,降低其在领域外视觉任务上的表现,并减少跨模态对齐能力(见图 1)。其次,通用能力的下降迫使从业者为不同任务维护多个专业化模型,增加了计算开销、存储需求和操作复杂性。
在本文中,我们提出了一种专门设计用于解决这些挑战的微调策略。我们的主要目标是将细粒度视觉知识“注入”到 VLM 中,即在不牺牲其原始通用视觉理解和跨模态检索性能的前提下,增强 VLM 在特定视觉领域上的细粒度识别能力。受到持续学习技术的启发,我们采用了两种互补的正则化方法:针对预训练模型的参数空间正则化,以及通过预训练表示蒸馏的嵌入空间正则化。虽然这些技术在持续学习文献中分别有先例,但我们的工作专门探索了它们在细粒度视觉检索上下文中的整合和行为。我们提供了关于如何有效结合这些正则化技术的实证见解,构建了一个强大的微调框架,在细粒度领域专业化和更广泛的多模态表示质量之间保持了良好的平衡。
此外,我们还解决了现有文献中的方法论缺陷,特别是忽视了在微调过程中准确预测领域内和领域外泛化性能所必需的验证策略。我们提出了一个严格的验证框架,利用特定的验证集以透明可靠地评估这两个性能方面。我们的验证方法确保了稳健的超参数调整,促进了我们方法更广泛的适用性和可重复性。
我们的贡献总结如下:
- 我们对持续学习中广泛使用的两种不同类型的正则化损失进行了分析,研究了它们在细粒度开放集视觉检索设置中保留预训练模型知识时的适用性。
- 我们提出了一种微调方法,用于在显著提升 VLM 细粒度开放集视觉检索性能的同时,保留通用多模态能力,解决了一个重要但未被探索的问题(见图 1)。
- 我们提供了一个透明的验证集设计,明确旨在可靠地预测领域内专业化和领域外泛化能力。
- 我们在大规模、真实的数据库上进行了广泛的实证评估,展示了我们方法在图像单模和图像-文本检索任务中的有效性和鲁棒性,突出了其实用价值和泛化能力。
2. 相关工作
以下是对论文中“相关工作”部分的中文总结,保留了原文中可能的图像部分(如果有的话)在适当位置的原始格式。
2.1 预训练视觉编码器的微调与灾难性遗忘
在将预训练的视觉编码器(如视觉语言模型(VLMs)中的视觉变换器(ViTs))适应下游任务时,标准方法是进行全模型微调。全模型微调通常在结合检索或细粒度识别任务的度量学习目标时,能在域内取得最佳性能。然而,这常常导致灾难性遗忘,即在预训练过程中学习到的通用视觉特征被侵蚀,模型过度特化于微调任务。
为了缓解遗忘问题,部分微调策略被提出,例如冻结早期层、应用逐层学习率衰减,或仅更新特定参数(如前馈网络(FFN)或注意力子层)。这些方法减少了表示漂移,但如果限制过多可能牺牲任务性能,并引入大量额外超参数。参数高效微调(PEFT)方法,如视觉提示调优(VPT)、适配器(Adapters)和低秩适应(LoRA),通过引入最小的可训练参数,试图最小化预训练模型能力的遗忘。
与本文工作最相关的是正则化方法,与持续学习子领域密切相关。这些方法通过约束与预训练模型参数或嵌入的偏差来防止遗忘。LDIFS 和 L2-SP 通过显式损失函数约束微调后的特征或权重,使其接近预训练模型。本文采用了这两种方法,并结合细粒度表示学习损失进行研究。与先前工作不同,本文发现仅对预训练参数进行正则化不足以保留模型的通用能力;与 LDIFS 不同,本文在与微调数据集域无关的通用数据上进行嵌入正则化,且仅对最后一层的嵌入进行正则化,以适应更大规模的设置。
此外,本文评估了两种更现代的视觉语言模型(SigLIP 和 TIPS),而非 CLIP 模型,且在训练过程中不依赖文本编码器或文本数据。基于锚点的鲁棒微调(ARF)通过从外部通用数据集检索相关示例并丰富微调过程,展示了改进的分布外(OOD)鲁棒性,但本文发现使用与微调域无关的数据是更优选择。
2.2 权重插值方法
权重插值方法(如 WiSE-FT)通过事后混合预训练和微调模型的权重,平衡任务特化与原始能力的保留。然而,这需要维护多组权重,且假设插值不会显著损害任一目标。本文与 WiSE-FT 进行了比较,并显示其在整体能力上逊于本文方法。
2.3 细粒度表示学习
细粒度表示学习通常被建模为开放集检索,即在细粒度域(如汽车型号、蘑菇种类等)的类上训练模型,然后在同一视觉域的不同类上测试。先前工作通过开发更好的架构、损失函数或样本挖掘策略,专注于最大化域内性能,但未评估微调过程对预训练知识的影响。
最近的持续学习研究包括细粒度数据集的评估,但主要以零样本分类方式进行。本文考虑更大规模、更现实的数据集(如 iNaturalist、Food2k 等),并在开放集场景中进行评估。对于文本-图像能力的保留评估,本文使用更现实的图像-文本评估数据集(如 Flickr30k 和 COCO),而非仅评估视觉语言模型的零样本性能。
2.4 泛化与验证集选择
验证集的选择对预测模型最终测试性能至关重要,尤其是在优化域内性能和通用知识保留这两个对立目标时。先前工作要么使用域内数据作为验证集,无法同时有效优化两个目标,要么未明确说明权衡权重是在域内还是域外数据上调整的。本文致力于提供选择具有上述特性的验证集的合适方法,并提出如何选择混合权重的简化流程。
3. 视觉语言模型的微调
在这一部分中,我们提出了一种专门设计的微调流程,旨在将预训练的图像嵌入适应到细粒度视觉领域,同时尽可能保留预训练视觉语言模型(VLM)中的知识。我们深入分析了两种不同的正则化方法,并开发了一种结合损失函数,融合了它们的互补优势。此外,我们强调了基于原则的超参数调整和验证的必要性,以通过合理的方法实现最佳性能。
3.1 预备知识
图像嵌入由视觉语言基础模型的视觉编码器产生(通常实现为视觉变换器 ViT),我们将其称为“骨干网络”。在本研究中,图像嵌入对应于标准 ViT 架构的 [CLS] 令牌;然而,也可以选择其他嵌入和骨干架构。设 fθ:X→RDf_\theta : X \rightarrow \mathbb{R}^Dfθ:X→RD 表示视觉变换器输出的 l2l_2l2 归一化嵌入,它将输入图像 x∈Xx \in Xx∈X 映射到 [CLS] 令牌 fθ∈RDf_\theta \in \mathbb{R}^Dfθ∈RD。为了符号简洁,如果网络参数 θ\thetaθ 从上下文中可以明确,我们将使用 f(x)f(x)f(x)。值得注意的是,我们的微调流程仅利用视觉编码器,完全排除了文本编码器。我们的方法的示意图如图 2 所示。待微调的模型(橙色,顶部)
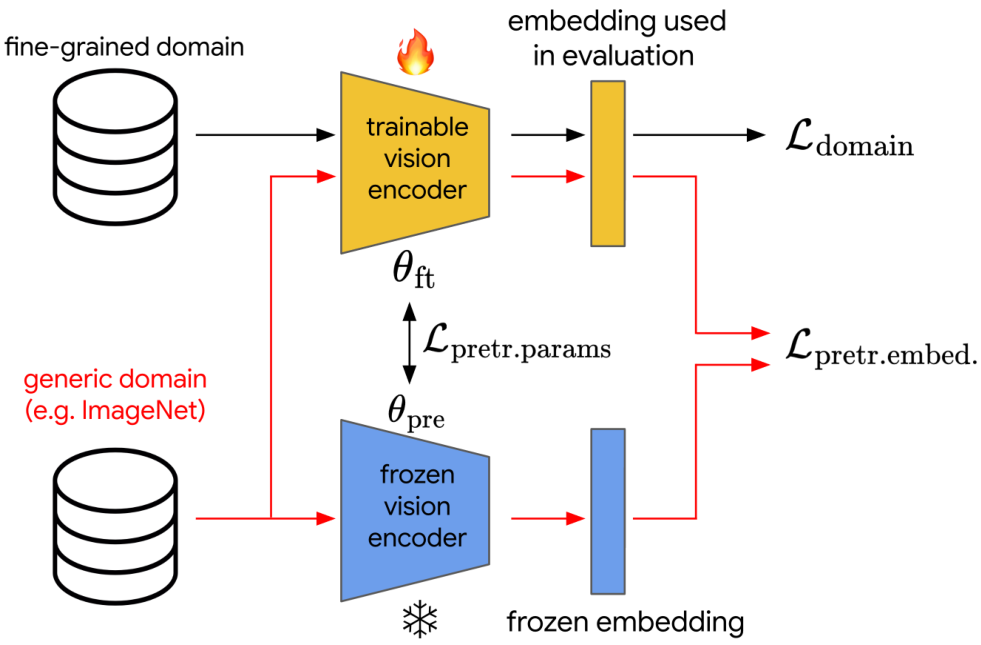
模型初始化为预训练 VLM 的视觉编码器参数,生成的嵌入将同时获取新呈现领域的细粒度知识,并保留冻结编码器嵌入中集中的通用知识。
3.2 基于类别监督的领域学习
为了将预训练嵌入适应到手头的细粒度领域,我们采用了基于分类的表示学习方法。具体来说,给定标注的细粒度数据(图像-标签对),通过在嵌入之上附加一个余弦分类器 [39],并通过嵌入反向传播常用的归一化交叉熵损失 [39],实现嵌入的微调。损失函数定义为:
Ldomain=−1B∑j=1Byjlog(y^j)=−1B∑j=1Blog(exp(pyj⊤fθ(xj))∑k=1Kexp(pk⊤fθ(xj))).\begin{array}{l} {\mathcal{L}_{\mathrm{domain}}=-\frac{1}{B}\sum_{j=1}^{B}y_{j}\log(\hat{y}_{j})}\\ {\displaystyle=-\frac{1}{B}\sum_{j=1}^{B}\log\left(\frac{\exp\left(p_{y_{j}}^{\top}f_{\theta}(x_{j})\right)}{\sum_{k=1}^{K}\exp\left(p_{k}^{\top}f_{\theta}(x_{j})\right)}\right)} \end{array}. Ldomain=−B1∑j=1Byjlog(y^j)=−B1j=1∑Blog∑k=1Kexp(pk⊤fθ(xj))exp(pyj⊤fθ(xj)).
其中,BBB 是批次大小,yjy_jyj 是样本 jjj 的独热真实标签向量,y^j\hat{y}_jy^j 是分类器为样本 jjj 产生的经过 softmax 处理的预测概率向量,KKK 是类别数量,pkp_kpk 表示类别 kkk 的 l2l_2l2 归一化可学习分类器原型。类别数量 KKK 由手头细粒度领域的训练集定义;然而,请注意,此分类器在测试时被丢弃,因为测试类别是未知的,即检索任务是开放集的。
3.3. 针对预训练知识的正则化
分类损失确保模型学习到其正在进行微调的细粒度领域的具体特征。然而,通过改变模型嵌入以区分训练类别,预训练视觉语言模型(VLM)中编码的知识会被抹去。为了缓解这种影响,我们引入了两种正则化方法的组合,试图保留预训练模型的多模态空间语义的嵌入结构。
参数正则化:这种损失与输入样本无关,它将微调网络的内部参数推向预训练网络的参数 θpre\theta_{\mathrm{pre}}θpre。在文献[34]中提出的 L2-SP 正则化定义为:
LPTetr.params=1N∑i=1N∣∣θft(i)−θpre(i)∣∣22,\mathcal{L}_{\mathrm{PTetr.params}}=\frac{1}{N}\sum_{i=1}^{N}\left|\left|\theta_{\mathrm{ft}}^{(i)}-\theta_{\mathrm{pre}}^{(i)}\right|\right|_{2}^{2}, LPTetr.params=N1i=1∑Nθft(i)−θpre(i)22,
其中 NNN 表示网络参数的索引。
嵌入正则化:为了明确限制嵌入漂移,我们采用了受 LDIFS [20] 启发的正则化方法,该方法将预训练网络的主干嵌入(目标嵌入)蒸馏到正在微调的网络的主干嵌入中:
LPIetrembed.=1B∑j=1B∣∣fθft(xj)−fθpr(xj)∣∣22,{\mathcal{L}}_{\mathrm{PIetrembed.}}=\frac{1}{B}\sum_{j=1}^{B}\left|\right|f_{\theta_{\mathrm{ft}}}(x_{j})-f_{\theta_{\mathrm{pr}}}(x_{j})\left|\right|_{2}^{2}, LPIetrembed.=B1j=1∑B∣∣fθft(xj)−fθpr(xj)∣∣22,
其中 BBB 是批次大小,jjj 表示批次中样本的索引。在我们的方法中,此损失仅应用于与 geNet [25] 无关的外部通用数据集的图像,因为该数据集易于访问且广泛使用。ImageNet 的批次以轮询方式输入,与正在微调的领域批次交替进行。实际上,在训练期间不会通过预训练(冻结)的视觉编码器进行前向传播以产生蒸馏目标;相反,嵌入在训练前一次性离线提取,从而节省计算资源和时间。
目标函数:最终的损失函数是三种损失的加权组合:

在接下来的章节中,我们将对两种正则化损失提供直观的解释,并提出设置权重 XembX_{\mathrm{emb}}Xemb 和 XoX_{\mathrm{o}}Xo 的方法。
3.4 正则化功能
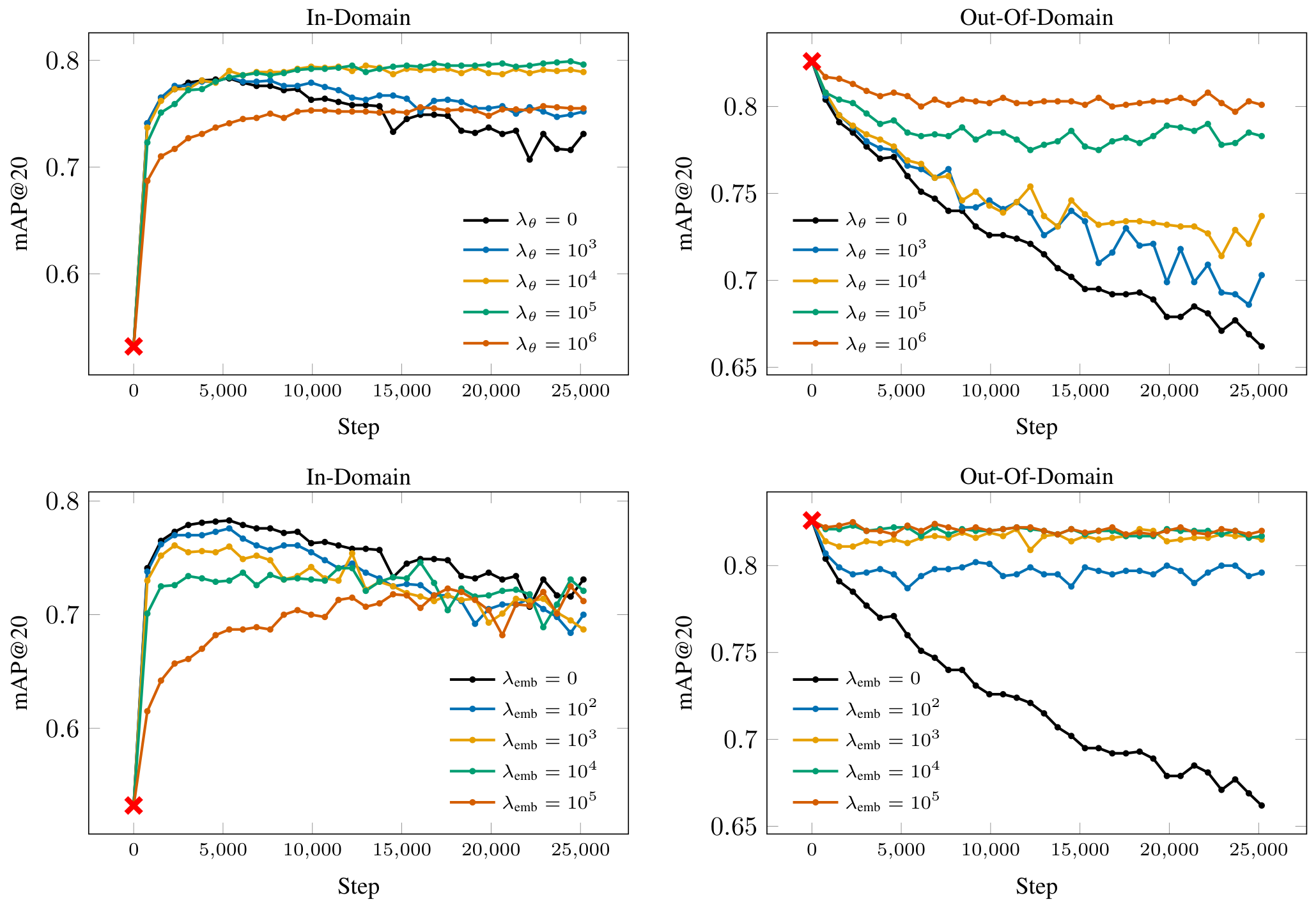
为了阐述我们提出的微调方法,我们首先独立评估每个正则化项,以展示它们对域内适应和域外泛化的各自影响。我们以在 SOP [26] 数据集(在线产品图像域)上进行微调,并以 Food2k [19](食品图像域)作为域外评估的运行示例,参见图 3。请注意,域外数据的值在训练过程中从未被使用或获得——这里仅作为说明示例,以证明我们引入的微调技术的合理性。
参数正则化:在这一段中,我们研究了损失函数(公式 4)中权重 XoX_oXo 的影响,同时设置 Xemb=0X_{emb} = 0Xemb=0。图 3(顶部面板)展示了不同参数正则化损失权重的影响。使用最小的或无正则化进行微调会迅速提高域内性能,但最终会导致过拟合,这一点通过 SOP 验证集性能的后续下降得以体现。引入适度的参数正则化(例如,权重 10410^4104)可以有效遏制这种过拟合,从而在整个训练过程中保持更稳定的域内准确率。然而,随着正则化强度的进一步增加,对细粒度域的适应受到越来越大的限制。从域外角度看(图 3,顶部面板,右侧面板),仅靠参数正则化不足以在不相关域上保持性能:无论正则化强度如何(除非强度大到网络完全不适应),嵌入分布仍然可能偏离预训练的分布。这导致域外准确率迅速下降,凸显了仅约束网络参数的局限性。这与之前工作 [20] 的结论形成对比,在之前的工作中,参数正则化似乎是有效的。我们推测这与微调任务的不同性质有关。
嵌入正则化:与参数正则化相反,嵌入正则化明确限制了学习表示与预训练嵌入的漂移,但也带来了自身的权衡。如图 3(底部面板,右侧面板)所示,足够强的嵌入正则化几乎可以将域外性能冻结在初始值,有效防止灾难性遗忘。然而,这以降低对细粒度域的适应为代价:增加嵌入损失权重始终会降低域内性能(底部面板,左侧面板)。
3.5. 联合验证的损失权重
在最终的损失函数(公式4)中,结合了三种损失。我们的微调流程的有效性在于域适应和知识保留之间的平衡。这种平衡通过分配给参数和嵌入正则化项的权重(XeX_eXe, XembX_{emb}Xemb)来控制。实际上,这些超参数对域内和域外性能都有显著影响,需要仔细调整。如果仅使用域内验证进行模型选择或提前停止,得到的模型可能会表现出强烈的适应性但对预训练知识的保留较差,反之亦然。为了解决这个问题,我们采用了具有双重成分的验证策略:
- 对于域内成分,使用细粒度数据集的标准验证集,测量相关的检索指标。
- 对于域外成分,保留一个大型通用数据集的子集,在我们的案例中是ImageNet训练集的一个保留部分,并使用相同的指标来监控性能。
在训练过程中,最终的验证分数计算为域内和域外指标的平均值。这一综合指标用于超参数调整(选择正则化损失的最佳权重)和提前停止。通过优化平均值而不仅仅是微调域,我们明确鼓励模型在适应新域和保留通用预训练知识之间取得平衡。这种验证协议对于实现可靠和可重复的结果至关重要。如果没有域外验证集,选择的模型可能会过拟合到微调域,失去大部分泛化能力,这是先前工作中常常被忽视的一个限制。
4. 实验
在本节中,我们进行了彻底的实验评估,以评估所提出的微调流程的好处,重点是两种正则化技术在不同域中的有效性。
4.1 实验设置
数据集与评估协议
我们在多个细粒度视觉领域对我们的方法进行了评估,以确保其通用性和鲁棒性。具体来说,我们选择了以下五个开放集细粒度图像检索数据集作为目标领域进行微调:
- 斯坦福在线产品数据集(Stanford Online Products, SOP)[26](产品领域)
- InShop [18](服装领域)
- 斯坦福 Cars196 [16](汽车领域)
- iNaturalist 2018 [29](自然世界领域)
- Food2k [19](食品领域)
为保持一致性,我们采用了通用嵌入数据集(Universal Embeddings Dataset, UnED)[37]的数据划分。每个评估测试集被分为查询集和索引集,用于开放集最近邻检索。
为了严格评估模型对通用预训练知识的保留,我们构建了一个基准测试,其中模型在一个目标领域上进行微调,并在其他所有细粒度领域以及较粗粒度的 ImageNet 领域上进行评估,通过对其未见测试集的评估(采用留一法检索设置)。此外,为了评估模型原始视觉-语言对齐能力的保留,我们在 COCO [4] 和 Flickr30k [36] 测试集上执行跨模态检索(图像到文本和文本到图像),始终保持文本编码器冻结。
评估指标
对于所有纯图像检索任务,我们报告 mAP@20。对于文本-图像检索任务,按照既定惯例报告 Recall@1 (R@1)。文本嵌入始终由原始的、冻结的文本编码器生成,来自相应的视觉-语言模型(VLM)骨干网络。为了总结性能,我们计算了以下三个聚合指标:
- 图像-图像领域内(In-Domain):在微调领域的测试集(未见类别,图像-图像检索)上的 mAP@20。
- 图像-图像领域外(Out-of-Domain, O-o-D)平均值:在其他细粒度数据集和 ImageNet 上的平均 mAP@20(图像-图像检索)。
- 文本-图像领域外(Out-of-Domain, O-o-D)平均值:在所有四种文本-图像检索设置(2个数据集,两个方向)上的平均 R@1。
- 领域内-领域外平均值(In-Out Avg.):领域内得分和总体领域外得分的简单平均,提供了一个综合的适应性和泛化能力衡量指标。
预训练模型
我们在两个广泛采用的视觉-语言基础模型上评估了我们的方法,即 SigLIP [40] 和 TIPS [14]。选择这些骨干网络是因为它们在多模态学习任务中表现出色且多样化,确保我们的研究结果不局限于单一预训练模型。
基线与竞争方法
为了评估我们方法的有效性,我们将其与几种基线和竞争方法进行了比较:
- 标准微调(Standard):仅使用分类损失(公式 1)进行无约束适应,如 [37] 所述。
- L2-SP [34]:仅使用参数正则化损失(λemb=0\lambda_{emb} = 0λemb=0)。
- WISE-FT [31]:在预训练模型和独立微调模型之间进行参数平均。
- (我们的)LDIFS 变体 [20]:仅应用嵌入正则化损失(λ0=0\lambda_0 = 0λ0=0),类似于 LDIFS(为公平起见,排除中间层)。
需要注意的是,为了更好地比较,(我们的)LDIFS 变体使用我们提出的复合验证集来选择嵌入正则化损失的权重,而不是像原始工作中那样仅使用领域内验证。在这种情况下,它甚至无法启用正则化损失,因为权重为 0 会最大化领域内性能。这一调整导致领域外结果更强,如第 3.5 节所述。值得强调的是,据我们所知,以前的工作没有系统地解决正则化权重选择 [41] 的挑战,也没有在模型选择中明确使用领域外验证 [20]。
实现细节
所有实验均使用批量大小为 128,骨干网络的学习率为 10−510^{-5}10−5,分类器原型学习率为 10−310^{-3}10−3。原型初始化为训练样本的嵌入,其表示最接近于类均值嵌入,由预训练网络计算。微调和评估均使用 224×224224 \times 224224×224 的图像分辨率,并采用 ViT-Base 骨干网络,补丁大小为 16。上述超参数遵循先前工作 [37],未进一步调整,因为它们不是我们贡献的核心。对于 TIPS 视觉编码器,我们使用其两个 CLS 令牌中的第一个。尽管 TIPS 以补丁大小为 14 进行预训练,但为保持实验一致性,我们使用 16;如果使用与其预训练设置匹配的默认补丁大小,可能会获得更好的性能。
其余超参数通过我们提出的验证协议进行网格搜索选择:λemb∈{102,103,104,105}\lambda_{emb} \in \{10^2, 10^3, 10^4, 10^5\}λemb∈{102,103,104,105} 和 λ∈{103,104,105,106}\lambda \in \{10^3, 10^4, 10^5, 10^6\}λ∈{103,104,105,106}。我们的实现基于 Scenic 框架 [5],使用 JAX [1] 和 Flax [10],所有实验均在 Google Cloud TPU v2 和 v3 硬件 [21] 上进行。
4.2 结果
除非另有说明,每次实验的最佳正则化权重对 (Xemb,XeX_{emb}, X_eXemb,Xe) 都是通过在第 3.5 节描述的复合验证指标上进行网格搜索选出的。

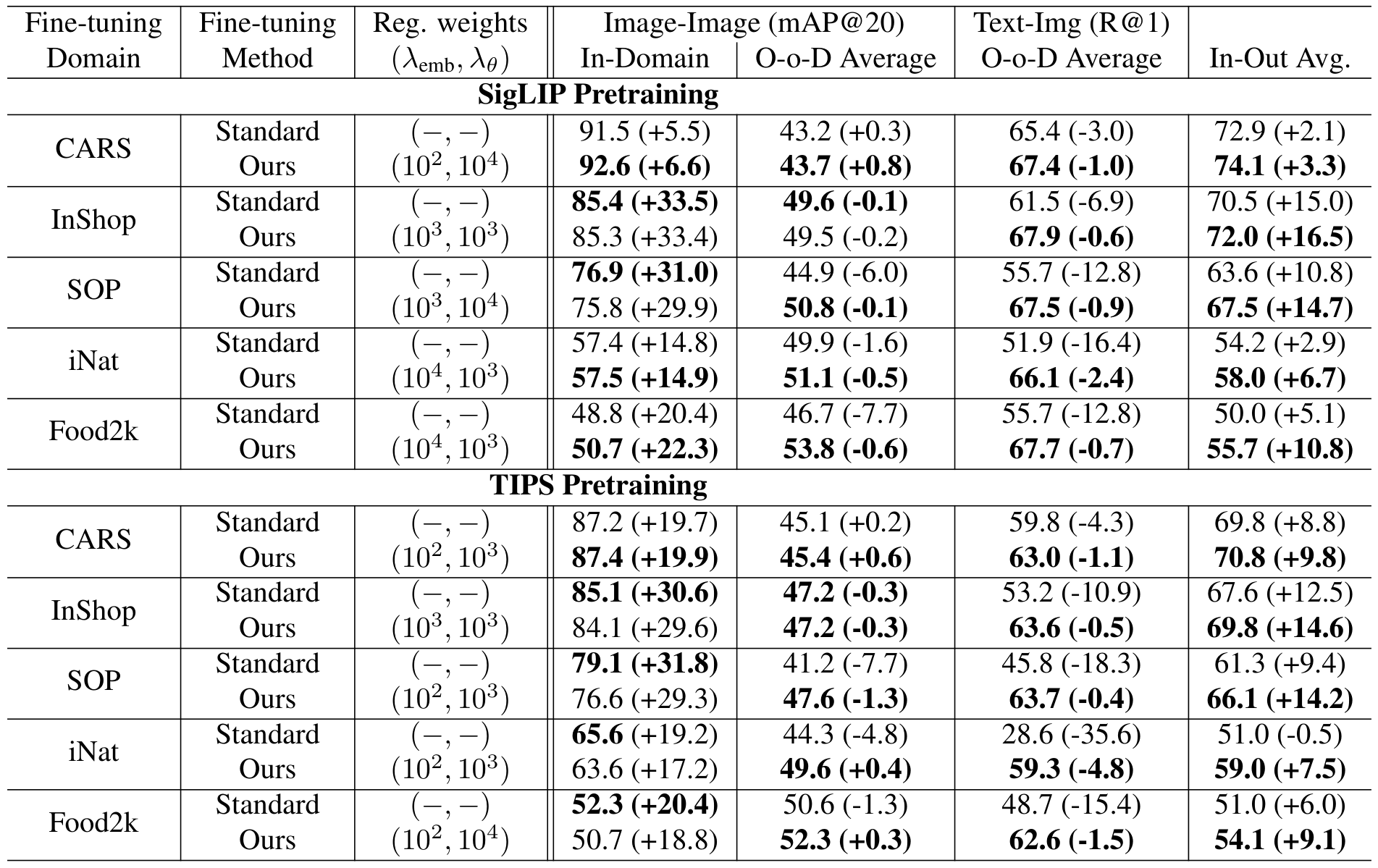
与标准微调的比较:表 1 总结了我们的方法与标准(无正则化)微调在 SigLIP 和 TIPS 预训练模型以及所有五个细粒度数据集上的结果对比。我们的方法在域内适应和域外泛化之间始终保持了良好的平衡。与标准微调不同,标准微调虽然能快速特化,但会导致灾难性遗忘,而我们的方法在微调过程中即使不使用文本数据或文本编码器,也能保留模型原始的泛化能力和视觉-语言对齐能力。值得注意的是,最佳正则化权重因预训练和目标数据集而异,这强调了原则性超参数选择的重要性,与早期使用固定或统一设置的工作 [20, 41] 形成对比。
与其他基线的比较:表 2 提供了在 SigLIP ViT-Base/16 上对 SOP 数据集进行微调时与所有基线的直接比较。结果显示了不同的行为:无约束模型在域内性能上达到了最佳,但域外知识退化严重。L2-SP(仅参数正则化)在域内性能上略有下降,但对域外性能的保留没有显著作用。LDIFS(嵌入正则化)使用域内目标时,域外分数略有提升,但由于嵌入目标来自正在特化的相同数据,域内适应受到显著限制。使用外部图像替换域内图像进行嵌入正则化(LDIFS 使用通用样本)通过提供更广泛的预训练嵌入空间覆盖,同时提升了域内和域外性能。WISE-FT(参数平均)保留了良好的域外泛化能力,但牺牲了域内特化能力。我们的方法在保持新域上的稳健性能的同时,没有显著损失泛化能力,实现了最佳权衡。
外部数据集选择:我们进一步分析了用于嵌入正则化的外部数据集的影响。使用在 SOP 上微调的 SigLIP ViT-Base/16,选择了 LAION 的一个子集(与 ImageNet 大小大致相同)作为外部数据集进行正则化,结果如表 3 所示。需要注意的是,本实验使用的验证集是我们的方法中以 ImageNet 作为域外成分的复合验证集。原因在于 LAION 没有类级别标签,因此无法在其上计算检索指标。结果支持我们选择 ImageNet 的理由:它提供了通用视觉概念的全面覆盖,作为在适应过程中保留预训练能力的有效锚点。其他数据集也是可能的,但 ImageNet 的可访问性和多样性使其特别适合此目的。

5. 结论
在这项工作中,我们开发了一种针对大型视觉-语言基础模型的鲁棒微调方法,该方法在细粒度视觉领域显著提高了性能,同时保留了在大规模多模态预训练过程中获得的丰富通用知识。我们同时使用了两种具有不同功能和影响的正则化技术,并对每种正则化技术进行了分析和直观的解释。此外,通过引入严格的验证策略,我们解决了先前工作中存在的方法论差距。该策略明确评估了领域内专业化和领域外泛化性能,确保超参数调整和提前停止决策是有原则且可重复的。
Original Abstract: Large-scale contrastive pre-training produces powerful Vision-and-Language
Models (VLMs) capable of generating representations (embeddings) effective for
a wide variety of visual and multimodal tasks. However, these pretrained
embeddings remain suboptimal for fine-grained open-set visual retrieval, where
state-of-the-art results require fine-tuning the vision encoder using annotated
domain-specific samples. Naively performing such fine-tuning typically leads to
catastrophic forgetting, severely diminishing the model’s general-purpose
visual and cross-modal capabilities.
In this work, we propose a fine-tuning method explicitly designed to achieve
optimal balance between fine-grained domain adaptation and retention of the
pretrained VLM’s broad multimodal knowledge. Drawing inspiration from continual
learning literature, we systematically analyze standard regularization
techniques aimed at knowledge retention and propose an efficient and effective
combination strategy. Additionally, we address the commonly overlooked yet
critical aspects of validation set design and hyperparameter tuning to ensure
reproducibility and robust generalization across datasets and pretrained
models. We extensively evaluate our method on both fine-grained and
coarse-grained image-image and image-text retrieval benchmarks. Our approach
consistently achieves strong results, notably retaining the visual-text
alignment without utilizing any text data or the original text encoder during
fine-tuning. Code and model checkpoints: https://github.com/nikosips/infusing .
PDF Link: 2508.12137v1
部分平台可能图片显示异常,请以我的博客内容为准
