VLN视觉与语言导航(1)——数学与人工智能基础理论
这是课上做的笔记,因此很多记得比较急,之后会逐步完善,每节课的逻辑流程写在大纲部分。
大纲
首先介绍了VLN的含义、模块组成以及流程(各模块如何工作):
模块:视觉感知-》语言理解-》路劲规划-》动作执行与反馈
关键技术包括:
多模态融合:将视觉(图像/视频)和语言(文本指令)数据统一编码(如用CLIP模型)。
强化学习(RL):通过试错优化导航策略(如DQN、PPO算法)。
仿真环境:使用AI2-THOR、Habitat等平台训练和测试VLN模型。
评估指标:
路径长度(PL):导航路径的总距离。
成功率(SR):是否准确到达目标位置。
路径效率(SPL):结合路径长度和成功率的综合评分。
4. 典型流程(以“去卧室拿一本书”为例)
输入指令:用户说出导航目标。
环境感知:智能体通过摄像头捕捉周围场景(如门、走廊)。
指令解析:NLP模型提取关键词(“卧室”“书”)。
路径生成:在地图中标记卧室位置并规划路线。
避障执行:实时调整路径,避开障碍物(如宠物、家具)。
目标确认:到达卧室后,通过视觉识别书本并抓取。
接着开始介绍基础数学知识:
联合概率=AB两件事同时发生的概率
边际概率=已知联合概率求A为某一情况时,B所有可能发生的概率和
条件概率=A发生前提下B发生概率
常用公式:
贝叶斯方程,已知X对Y的条件概率,可以求出Y对X的条件概率
以上概率也适用于连续分布的概率和离散分布的概率
描述概率分布:
伯努利分布 平均分布 泊松分布 高斯分布 二项分布 整体分布
接着介绍了监督学习,包括两类任务:
回归任务:线性回归、 多元线性回归、 参数更新模式、 评价标准、 过拟合和正则化、 性能评估指标
分类任务: 逻辑回归分类器、 多项式逻辑回归(Softmax)、 性能评估指标
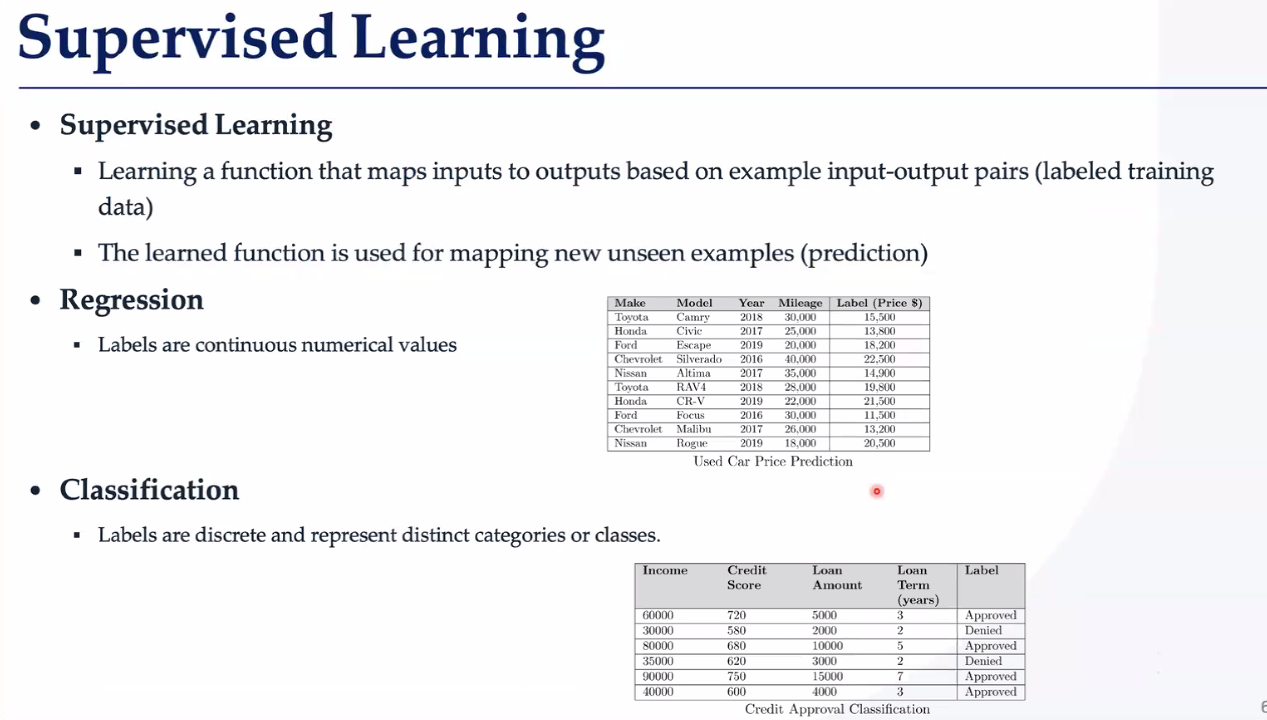
回归 标签是连续的数值;分类 标签是离散的,表示不同的类别或类。
接着分别阐述了两种任务的如何做(处理手段)-做的怎么样(评估方法)-有什么问题(缺点)-如何改进
对于回归任务和分类任务的处理手段,我单独写在了CSDN上。
对于回归任务的评估函数:MSE(均方根,放大误差) RMSE(MSE开根,变为原始单位) MAE(差的绝对值) R平方(1-模型误差/平均值误差,描述模型对数据波动的解释性)
【评估误差的处理】
这样的评价函数有问题——数据划分巧合会导致误判
因此提出了改进方法——K-交叉验证
把数据分成K份,轮流用其中一份当测试集,剩下的当训练集,最终取平均成绩。
这样也使得小数据集也能充分利用。
【过拟合的处理】
学习任务都有一个问题,就是过拟合
L2 岭回归正则化 防止过拟合——这个思想非常广泛,在最小二乘法求运动学逆解时为了防止雅可比不可逆导致末端速度爆炸,引入了阻尼系数。在这里为了防止权重爆炸,也使用了惩罚项
正则化——惩罚函数——过拟合往往是某一w权值过高引起的,因此添加惩罚项,防止wj过大
接着是分类问题的处理方法,我也写在CSDN了
其中对于二分类,采用找超平面的方法(找比特征低一维的曲面)。
如何找超平面呢?方法就是逻辑回归,我们常用交叉熵+Softmax。
交叉熵——这个在李沐老师的课里讲得很清楚。
具体步骤就是
仿射函数线性输出-》
激活函数转化为非线性概率分布-》
交叉熵损失函数计算误差-》
优化函数调整参数减小损失
整个过程就是最大似然估计,最大似然估计就是逻辑回归的一种实现形式。
对于二分类都好解决,对于多分类问题就必须要引入softmax函数了。
评估的方式往往使用独热编码与真实类别向量的差作为误差函数。
【数据的不平均的处理】【评估方法的处理】
独热编码会因为数据的不平均导致评估出错,因此改进评估方法——混淆矩阵
传统指标(如准确率)会掩盖模型对少数类的失效。模型可能偏向多数类(如负类),忽略少数类(如正类)。
因此使用召回率、F1、AUC等指标,或通过数据/算法调整平衡类别影响。
比如一个是答对的/真实猫(召回),一个是答对的/预测猫(命中/准确率)
通过这个评判标准,逻辑回归得出的结果就不是完美的(可能准确高但召回低),因此考虑一个使得准确率和召回率都很高的方法,就是ROC曲线:
【处理方法的优化处理】
ROC曲线让逻辑回归从“一刀切”升级为“灵活调参”,之前超过50%就认为是这个类,现在可以动态调整分类了。
除此之外还介绍了其他的一些分类方法。
K邻近(取最近的K个邻居,看多数属于哪类就判哪类,不需要训练)
支持向量机 (找一个超平面(比如直线)把两类分开,最大化间隔:选离两边样本最远的那个分界线)
朴素贝叶斯(计算每个特征在不同类别下的概率,假设所有特征互相独立,根据特征组合计算类别概率)
【判断垃圾邮件:统计"免费"、"中奖"等词在垃圾邮件中的出现概率,新邮件出现这些词就判为垃圾。】
决策树 (选最佳分裂点:遍历所有特征,找让数据最"纯"的分割(比如"收入>1万"能把好坏客户分得最开)。
递归分裂:对分割后的子集重复上述过程,直到满足停止条件(如深度限制)。
叶子投票:新样本从根节点走到叶子节点,按叶子中多数类别判断。)
【比如预测贷款违约:先按"收入>1万"分,再按"信用分>700"分... 最后落到"违约率80%"的叶子 → 拒绝贷款。】
核方法 (原空间非线性用核函数映射到高维空间再线性分类)
【分类螺旋数据:用高斯核把数据映射到3维空间,用一个平面切开。】
可以按照功能选择:
要简单快速:逻辑回归
数据量小且懒得训练:KNN
数据维度高:SVM
数据量大要速度快:朴素贝叶斯
需要解释性:决策树
数据特别复杂:核方法
VLN(Vision-and-Language Navigation)
VLN(视觉与语言导航) 是一种让智能体(如机器人或虚拟AI)根据自然语言指令(如“去厨房拿一杯水”),在真实或虚拟的3D环境中进行视觉导航的技术。
| 模块 | 功能 | 示例 |
|---|---|---|
| 视觉感知 | 通过摄像头或RGB-D传感器获取环境图像/深度信息。 | 识别门、桌子、楼梯等物体。 |
| 语言理解 | 解析自然语言指令,提取关键动作和目的地。 | 指令:“向左转,在第二个房间找红色椅子。” |
| 路径规划 | 结合视觉输入和语义理解,规划可行路径。 | 避开障碍物,选择最短路线。 |
| 动作执行 | 控制智能体移动(前进、转向等)。 | 机器人执行“右转30度”命令。 |
3. 关键技术
- 多模态融合:将视觉(图像/视频)和语言(文本指令)数据统一编码(如用CLIP模型)。
- 强化学习(RL):通过试错优化导航策略(如DQN、PPO算法)。
- 仿真环境:使用AI2-THOR、Habitat等平台训练和测试VLN模型。
- 评估指标:
- 路径长度(PL):导航路径的总距离。
- 成功率(SR):是否准确到达目标位置。
- 路径效率(SPL):结合路径长度和成功率的综合评分。
4. 典型流程(以“去卧室拿一本书”为例)
- 输入指令:用户说出导航目标。
- 环境感知:智能体通过摄像头捕捉周围场景(如门、走廊)。
- 指令解析:NLP模型提取关键词(“卧室”“书”)。
- 路径生成:在地图中标记卧室位置并规划路线。
- 避障执行:实时调整路径,避开障碍物(如宠物、家具)。
- 目标确认:到达卧室后,通过视觉识别书本并抓取。
离散空间的概率分布
联合概率
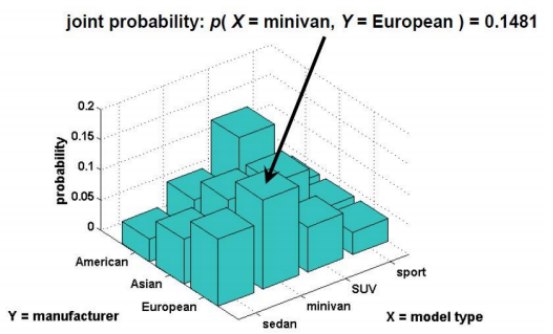
联合概率 = 同时发生的概率
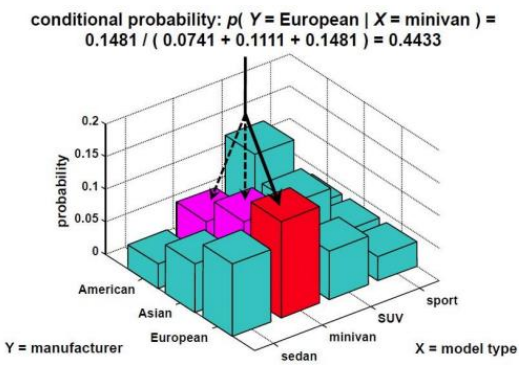
比如:一辆车既是“欧洲产”(Y=European)又是“小型货车”(X=minivan)的概率是 0.1481(见图中柱状图高度)。
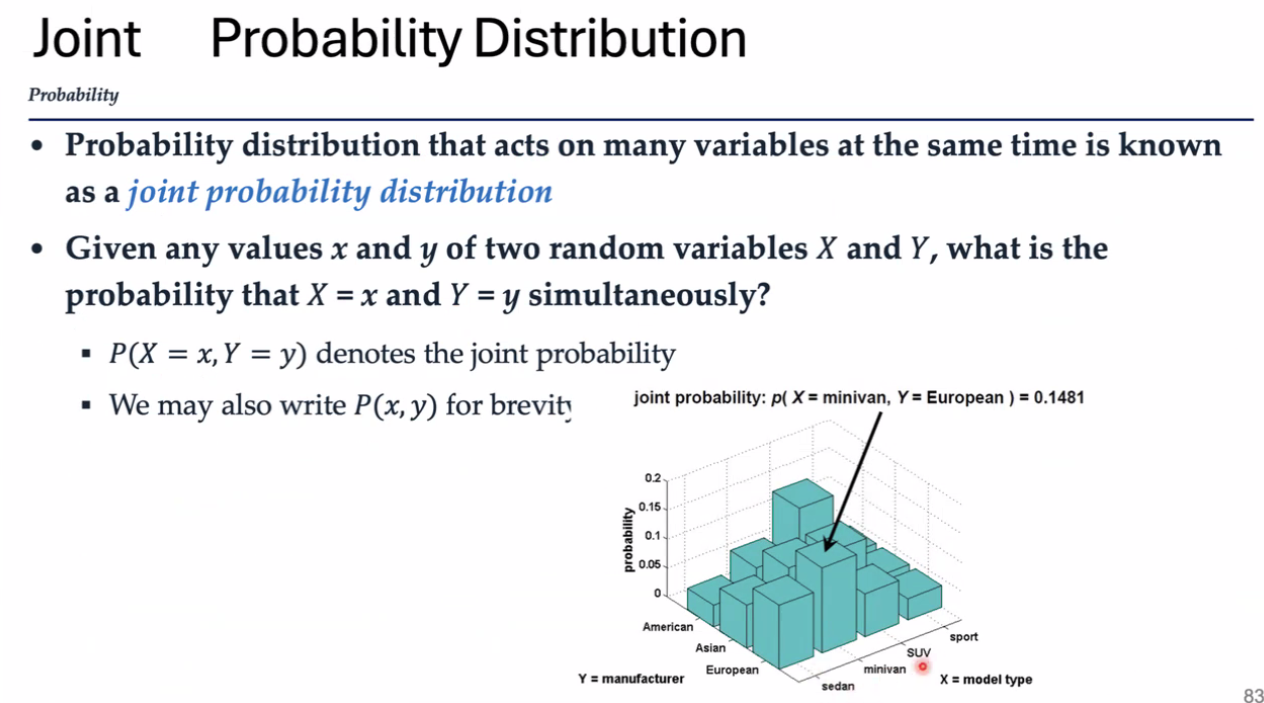
边际概率
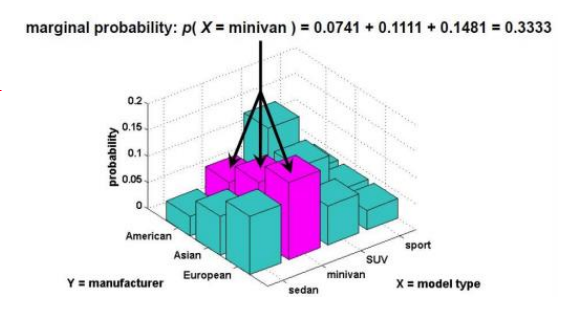
从联合概率分布中“剥离”出单个变量的概率分布。
已知车型(X)和产地(Y)的联合概率,求“所有产地的SUV车型概率总和”就是X的边际概率。

条件概率
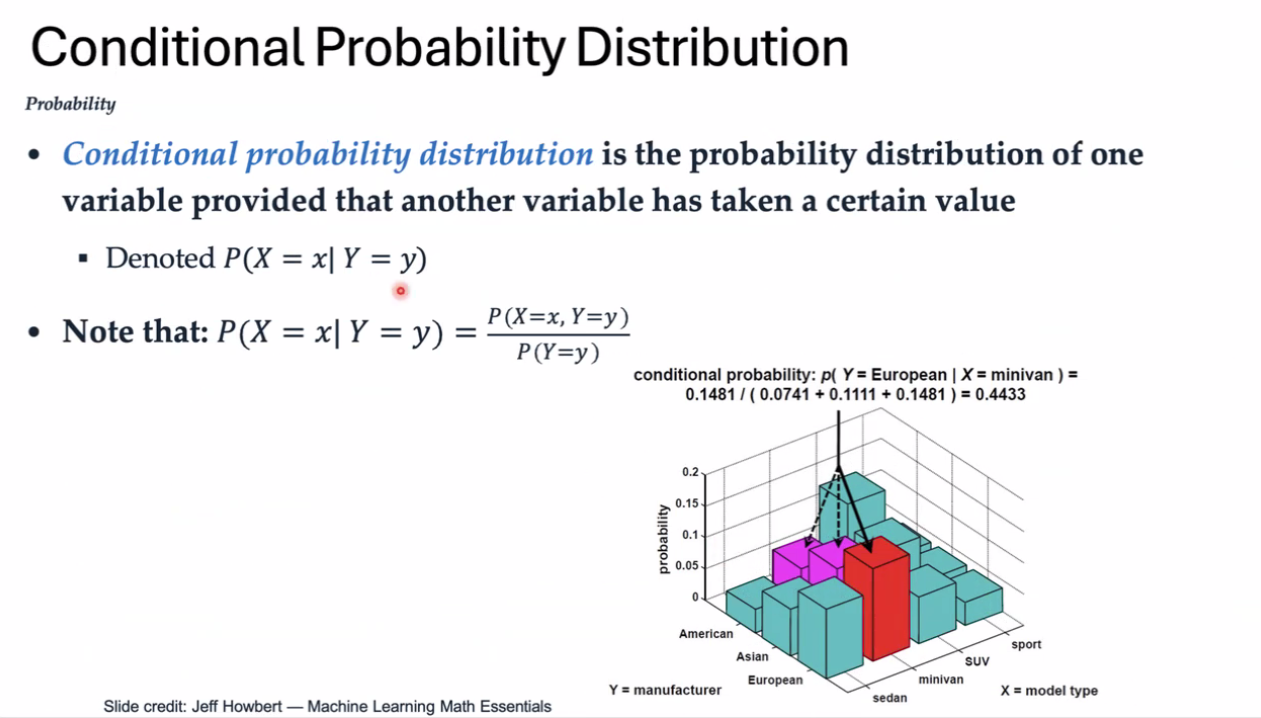
贝叶斯方程
计算条件概率

联合概率是两件事同时发生的概率,边缘概率是锁定一个变量,另一件事发生的概率之和;
条件概率是一件事在另一件事发生的条件下发生的概率。
已知一X对Y的条件概率,可以求出Y对X的条件概率。
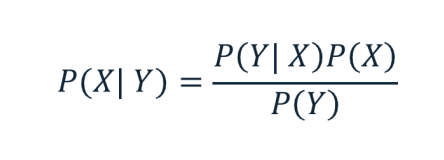
以上概率业适用于连续分布的概率
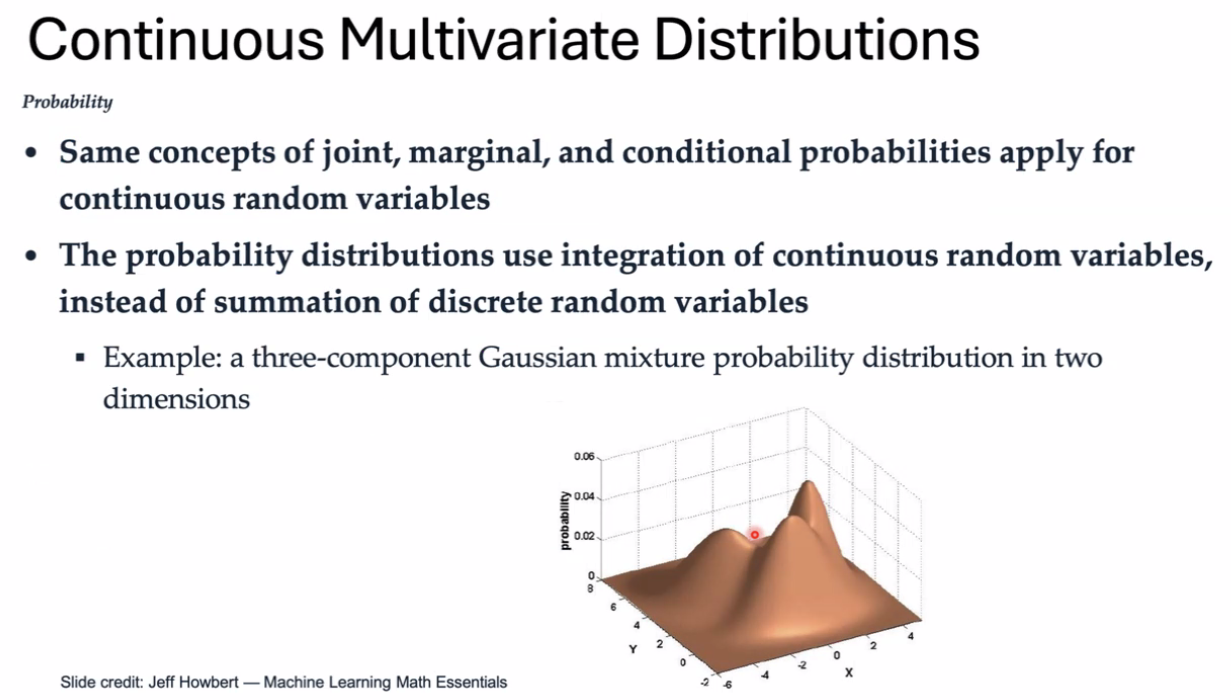
连续空间的概率分布
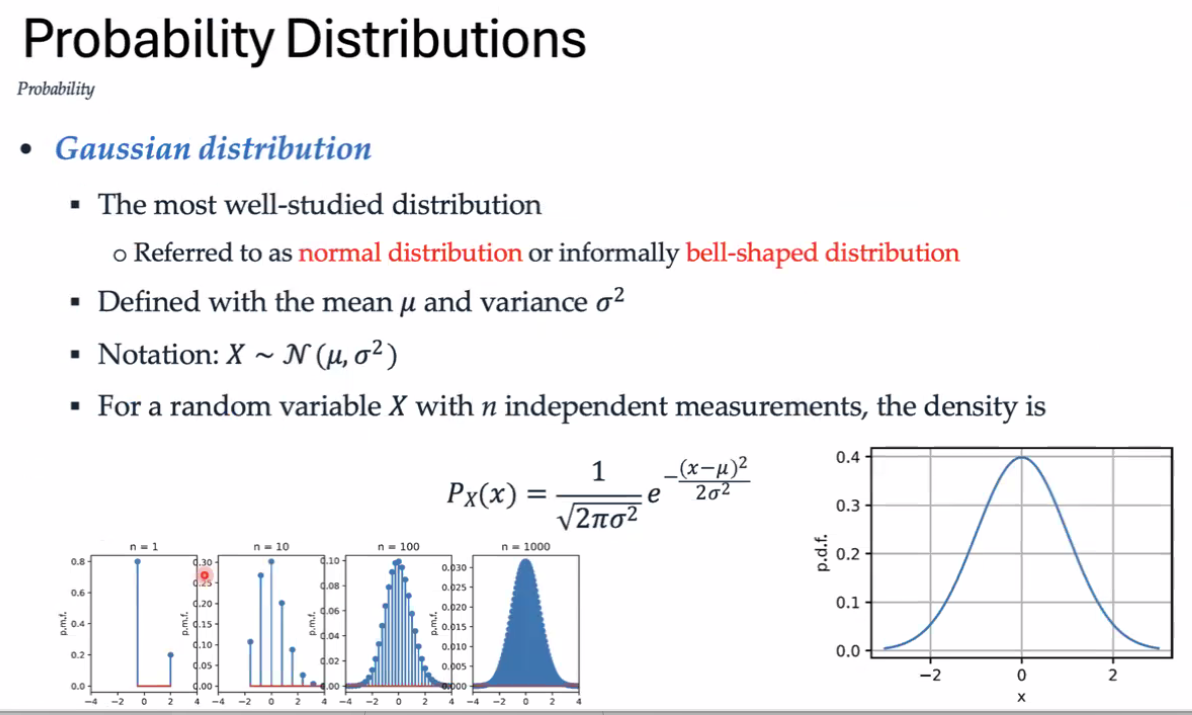
伯努利分布 平均分布 泊松分布 高斯分布 二项分布

高斯分布 正态分布 高斯混合模型

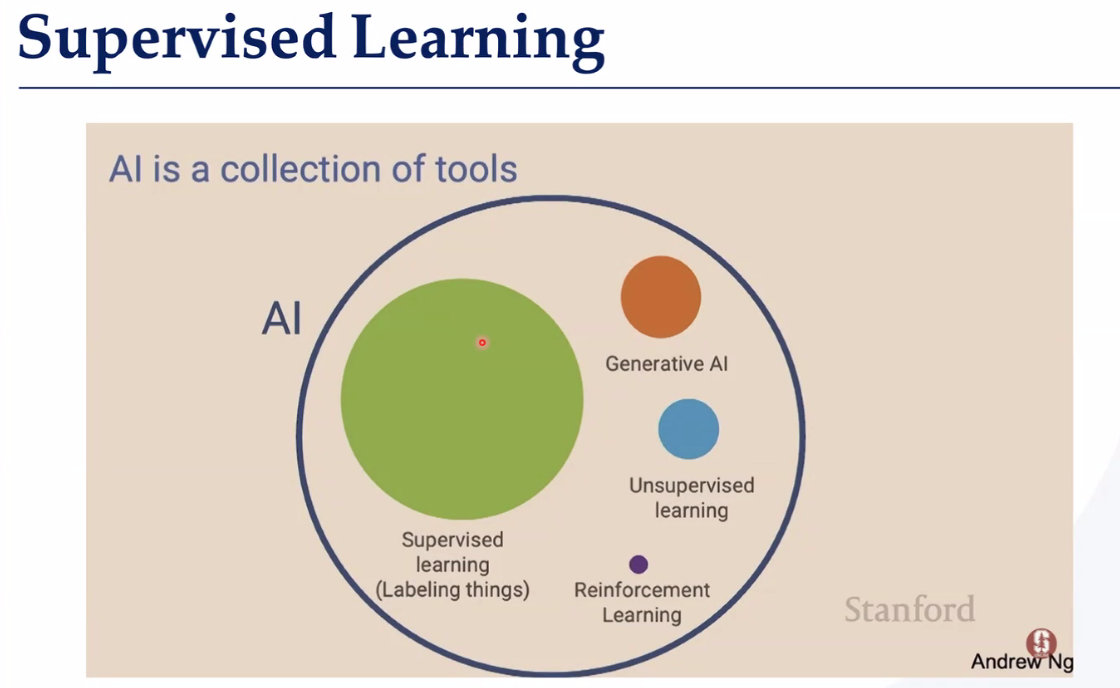
监督学习 包括
回归任务:线性回归、 多元线性回归、 参数更新模式、 评价标准、 过拟合和正则化、 性能评估指标
分类任务: 逻辑回归分类器、 多项式逻辑回归(Softmax)、 性能评估指标
回归 标签是连续的数值 •分类 标签是离散的,表示不同的类别或类

怎么做?线性问题的解决思路,回归问题和分类问题

梯度下降
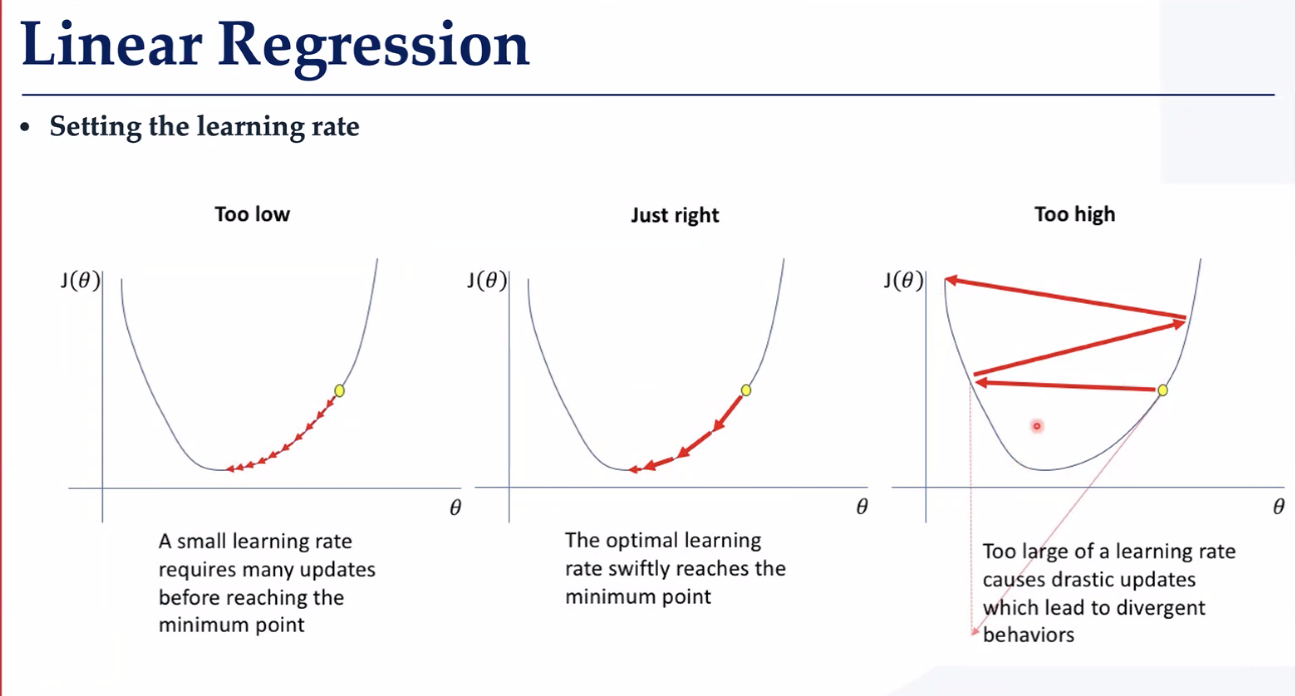

参数更新模式
一批训练完 小批次 一个数据更新一次(噪声很大)

非线性变换

基函数
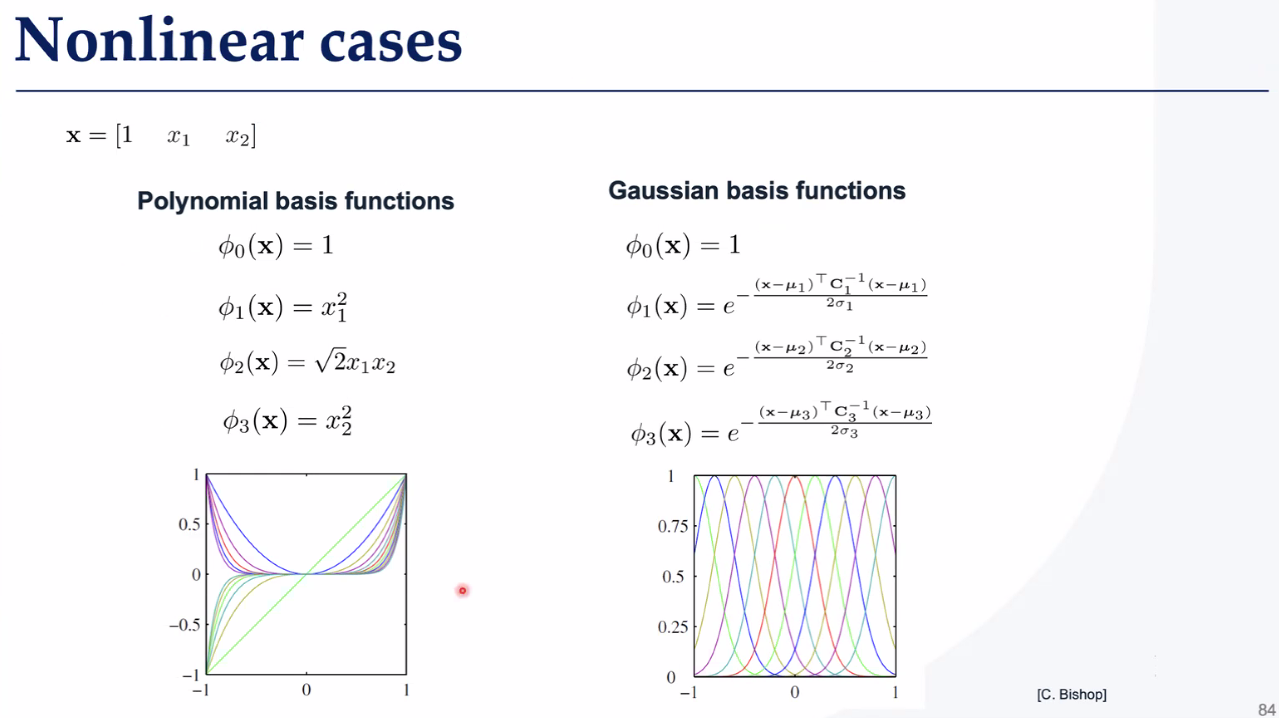
做得怎么样?如何评价结果?评估函数
常见有



K-交叉验证——K-交叉验证是一种“轮流当考官”的验证方法,把数据分成K份,轮流用其中一份当测试集,剩下的当训练集,最终取平均成绩。
为什么?
防作弊:避免数据划分巧合导致误判(比如测试集全是简单题)。
省数据:小数据集也能充分利用(每一份数据都既练过又考过)。
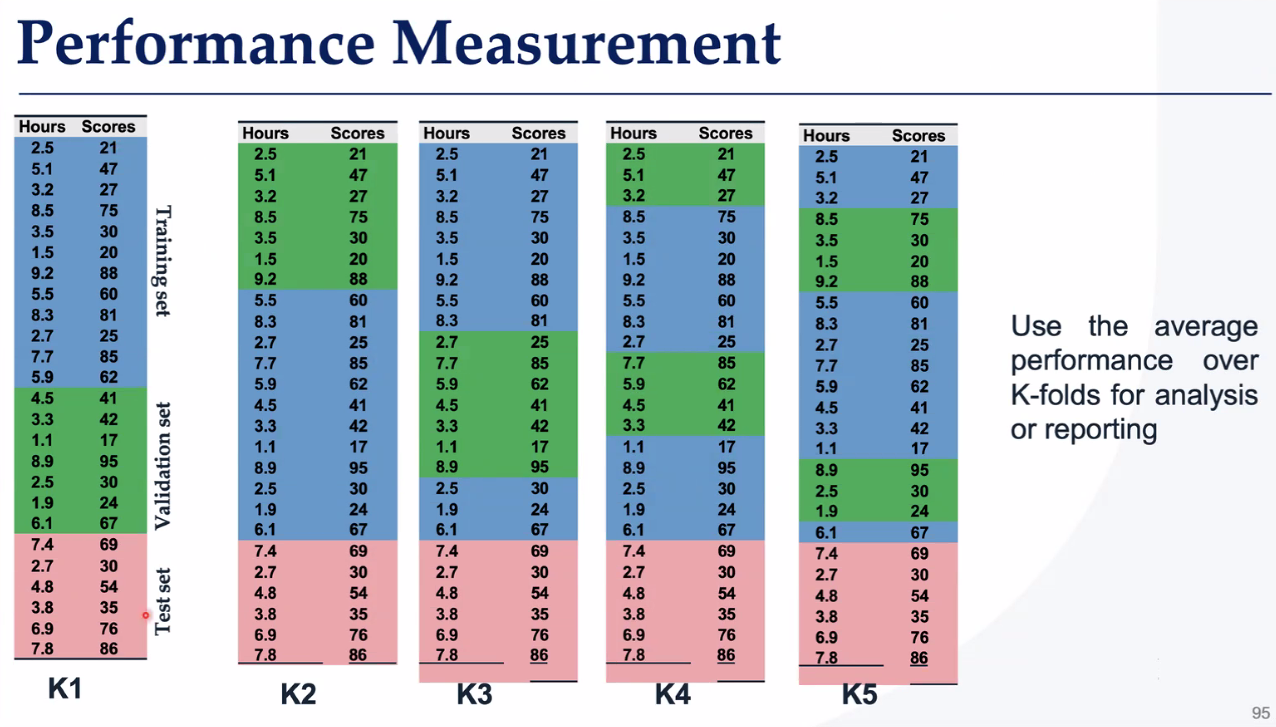
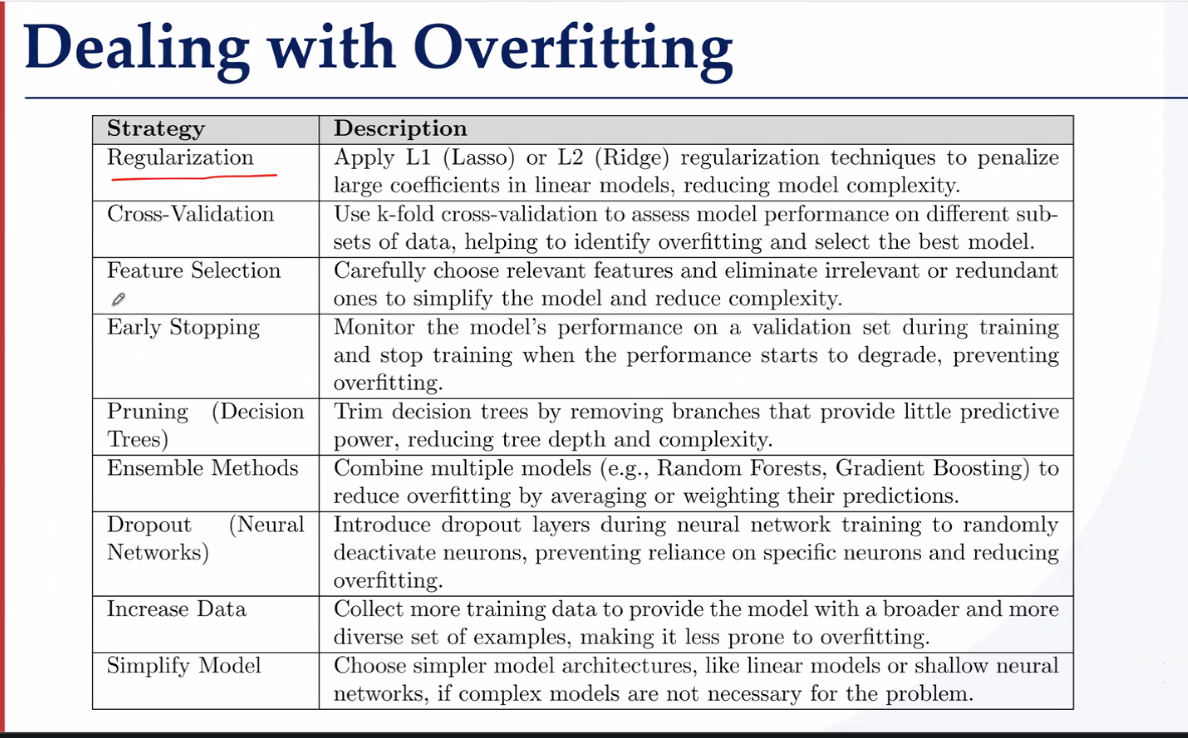
这么做有什么问题?如何解决过拟合问题
L2 岭回归正则化 防止过拟合——这个思想非常广泛,在最小二乘法求运动学逆解时为了防止雅可比不可逆导致末端速度爆炸,引入了阻尼系数。在这里为了防止权重爆炸,也使用了惩罚项

正则化——惩罚函数——过拟合往往是某一w权值过高引起的,因此添加惩罚项,防止wj过大

正则化的方式:
分类问题的处理方法——找超平面
二分类
以下方法不平滑,不可微,因此不能用sgd
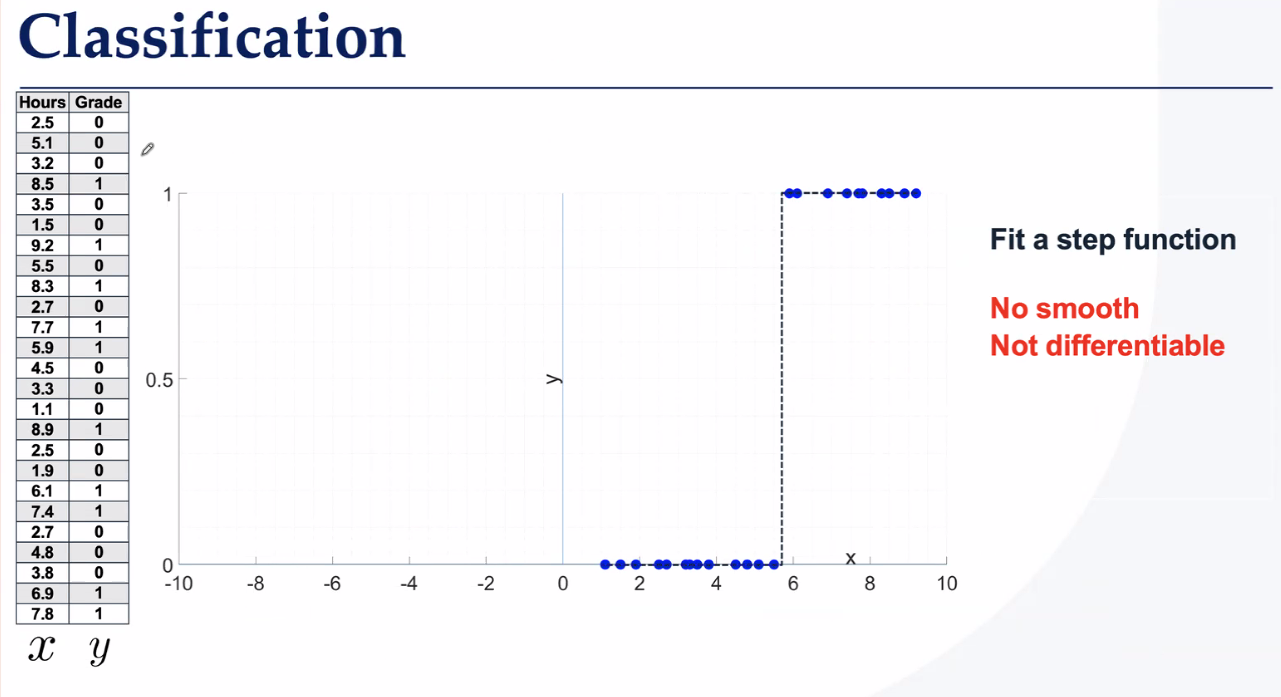
一维分类找曲线
逻辑函数,参数是w1w0
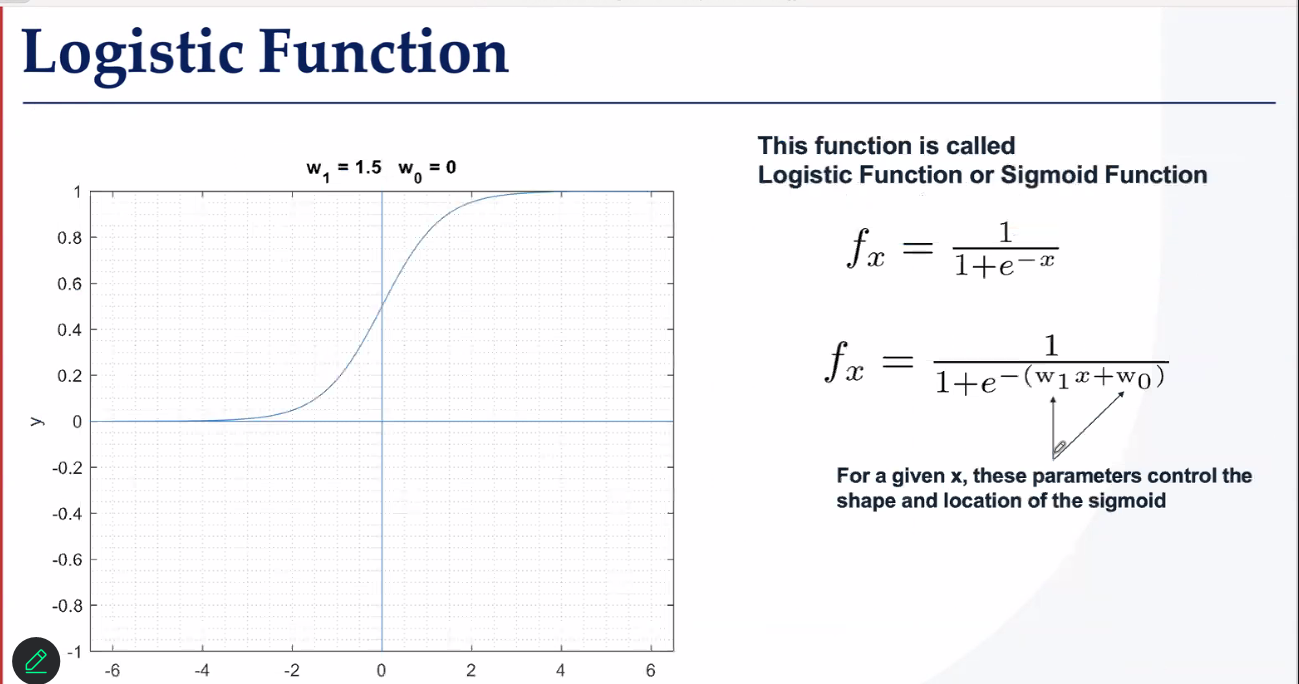
二维分类找曲面
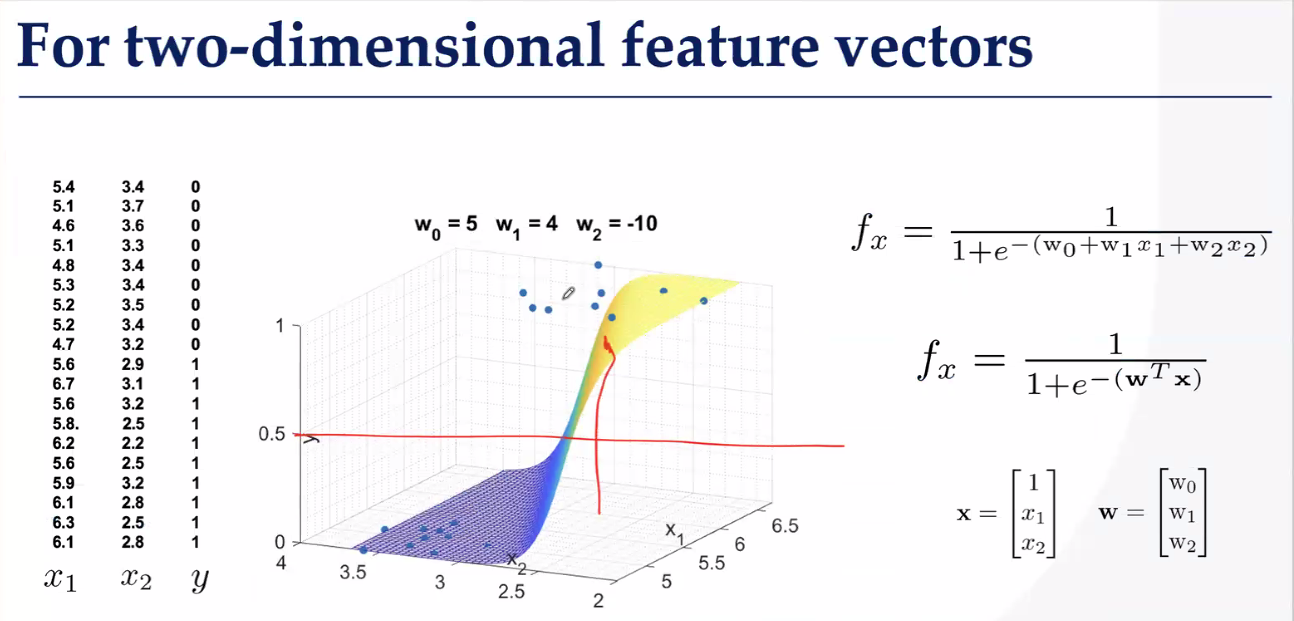
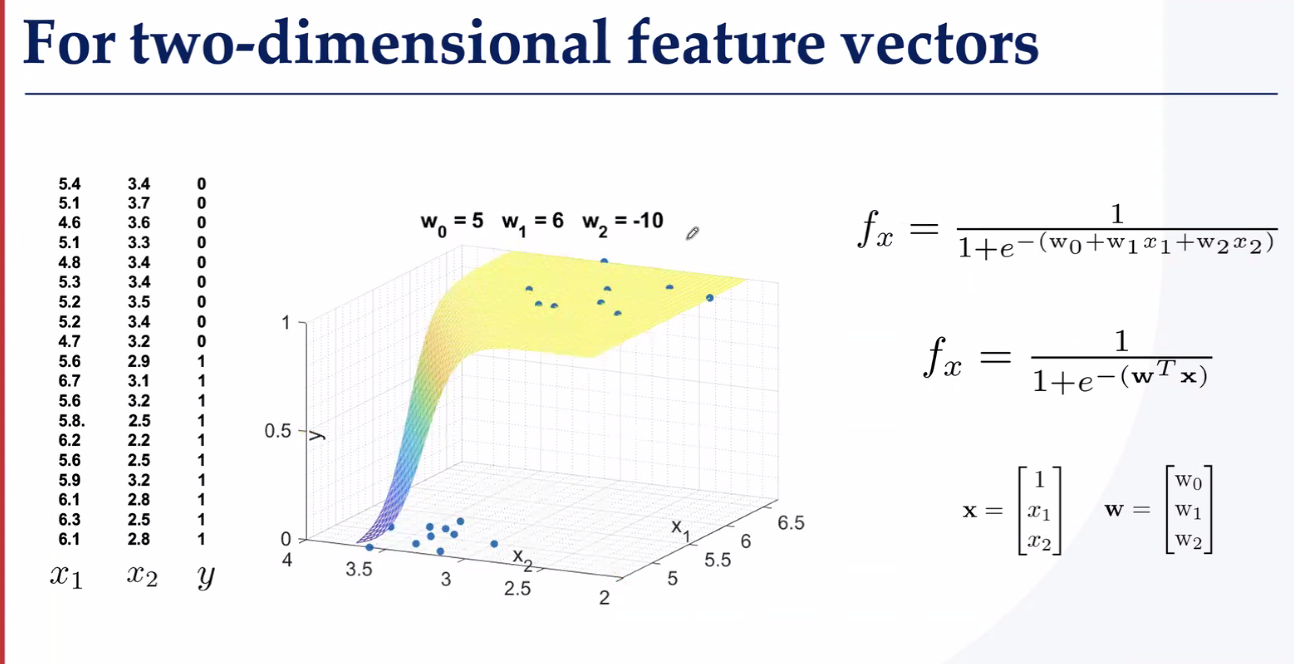
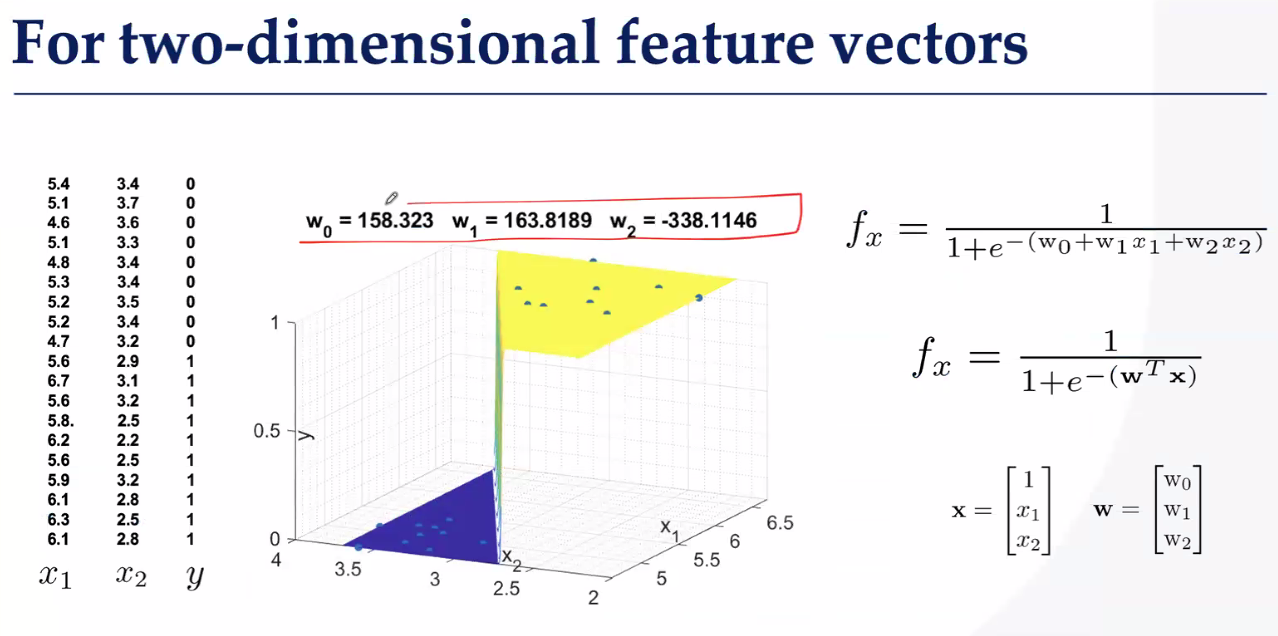
如何去找这个超平面呢?方法就是逻辑回归,我们常用交叉熵+Softmax?
交叉熵——这个在李沐老师的课里讲得很清楚,详细阐述了
熵:数据随机程度。
信息量:意外带来的信息。
在分类问题,绝大多数样本都符合某一个分类标准,正确的概率很大,那么这些数据的熵就很低,信息量自然很小。模型训练时有可能标错标签,这种情况概率很低,但其信息量很大,我们希望这种影响尽可能小。
而 交叉熵 H(P,Q) 表示 预测分布 Q 描述 真实分布 P 所需的平均信息量:
当 Q 与 P 差异很大时,需要更多信息量存储差异信息。
也就是说,如果错标一个数据,其就会产生很大的信息量,使得H(P, Q)变得很大,我们就能知道如何调整参数了。
所以你理解为什么公式中带log了吗,一旦模型标错数据,log映射就会将这个错误放大很多倍,称为梯度爆炸。
这就是为什么交叉熵适合衡量分类问题误差的原因。
具体步骤就是
仿射函数线性输出-》
激活函数转化为非线性概率分布-》
交叉熵损失函数计算误差-》
优化函数调整参数减小损失
整个过程就是最大似然估计,最大似然估计就是逻辑回归的一种实现形式。


当然分类也会遇到过拟合问题,解决的方式依然是正则化、更新模式、交叉验证、调节学习率
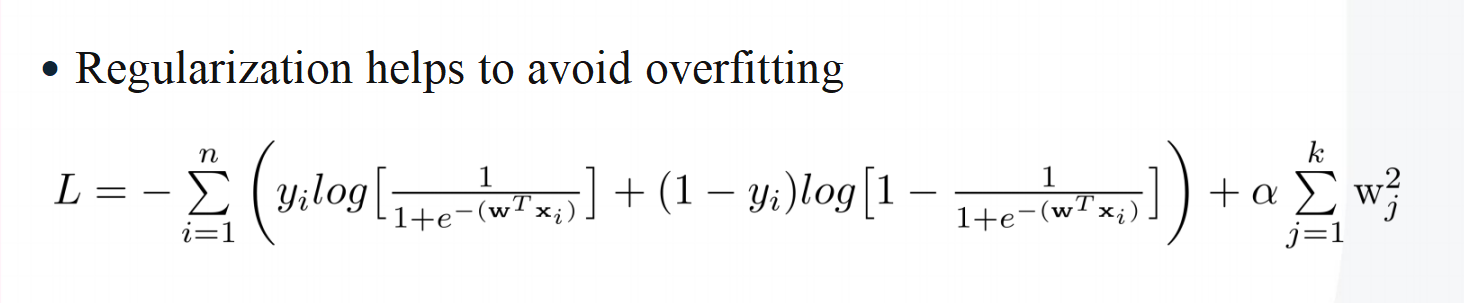
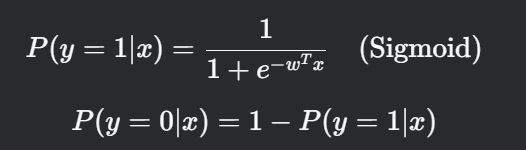
之前提到的逻辑回归是二分类的解决方案,sigmoid tanh 这些函数可以处理,但多酚类问题就必须引入softmax了


这么做有什么问题?独热编码会因为数据的不平均导致评估出错,因此改进评估方法——混淆矩阵
问题:数据不均衡时,传统指标(如准确率)会掩盖模型对少数类的失效。
模型可能偏向多数类(如负类),忽略少数类(如正类)。
解决:改用召回率、F1、AUC等指标,或通过数据/算法调整平衡类别影响。



对多分类也适用:
一个是答对的/真实猫(召回),一个是答对的/预测猫(命中/准确率)



通过这个评判标准,逻辑回归得出的结果就不是完美的(可能准确高但召回低),因此考虑一个使得准确率和召回率都很高的方法,就是ROC曲线:
ROC曲线与分类阈值
当所属概率超过阈值就算是这个类,直接记为1
作用:用来评估二分类模型(比如判断“生病/健康”)的好坏,不受分类阈值影响。
核心思想:
阈值严格(如0.9)→ 只抓最明显的正例(少误报,但漏诊多)。
阈值宽松(如0.1)→ 宁可错杀不放过的(抓全正例,但误诊也多)。
图形化:横轴是误诊率(FPR),纵轴是抓真率(TPR),曲线越靠近左上角越好。
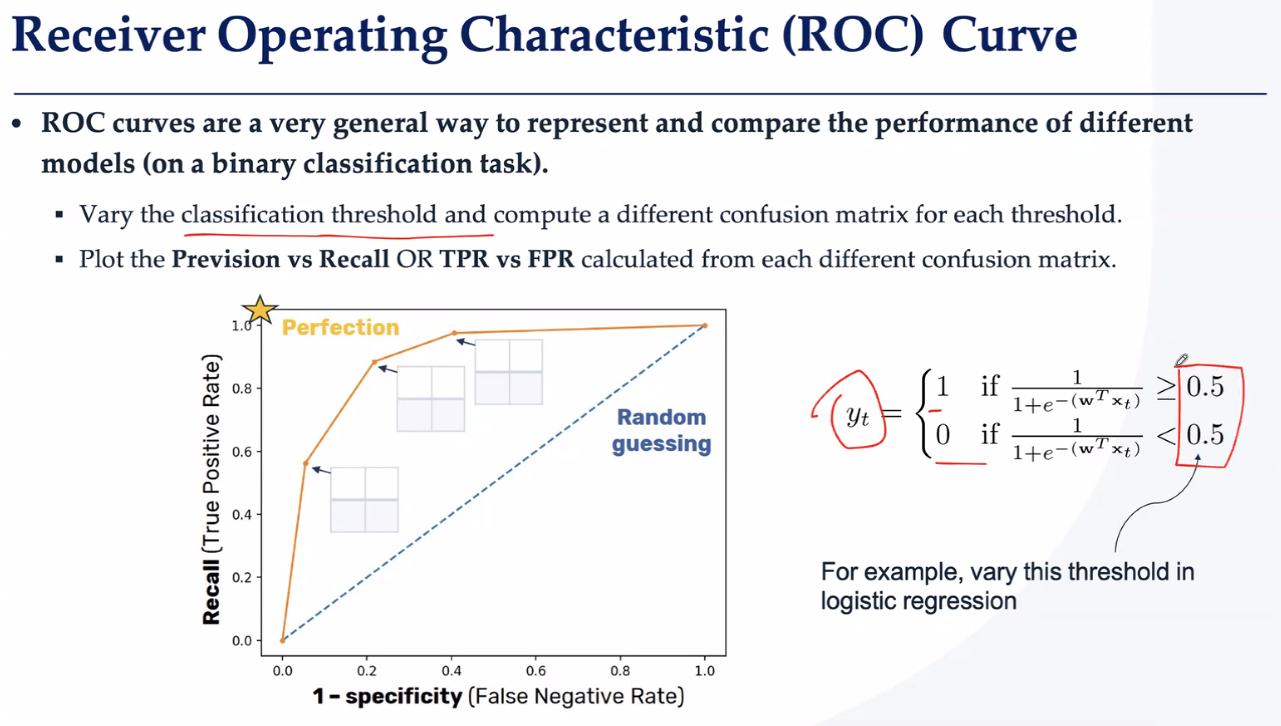

ROC曲线让逻辑回归从“一刀切”升级为“灵活调参”

知识向量机:学习一条线、一个面离不同的样本最远,但是对outliner不敏感,训练困难
K-邻接:根据邻居绝对分类,不需要训练,加入那群人就是那群人
决策树:
一个神经元就是一个线性+一个非线性的激活函数

自然语言+计算机视觉=VLN
机器学习和AI是函数F,让Ffit训练数据