特征工程学习笔记
特征处理
标准化
为什么要标准化

方法1: StandardScaler().fit_transform(x)
from sklearn.preprocessing import StandardScaler
#标准化
xs = StandardScaler().fit_transform(x)
xs方法2:
StandardScaler().fit(X_train)+ scaler.transform(X_train)
# 1. 先划分数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 2. 只对训练集 fit
scaler = StandardScaler().fit(X_train)# 3. 用训练集的均值和标准差转换训练集和测试集
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test) # 测试集必须用训练集的规则!区别:

第一个是直接全部都标准化了,如果划分训练集和测试集的时候,就会影响标准化的值,
所以需要用第二个方法
最小-最大标准化

from sklearn.preprocessing import MinMaxScaler
#最小-最大标准化
xs = MinMaxScaler().fit_transform(x)
归一化

from sklearn.preprocessing import Normalizer
#归一化
xs = Normalizer().fit_transform(x)定量特征二值化
设定一个阈值,大于阈值赋值为1,小于阈值的赋值为0。
from sklearn.preprocessing import Binarizerxs = Binarizer(threshold = 1.5).fit_transform(x)独热编码

import pandas as pd
x = ['A','B','C','A','C','D']
pd.get_dummies(x)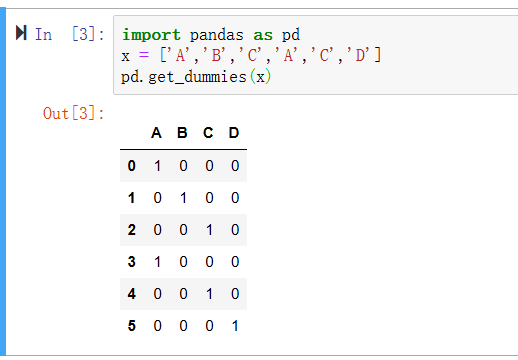
对数变换
from numpy import log1p
from sklearn.preprocessing import FunctionTransformer#log1p = log(x+1)
xs = FunctionTransformer(log1p).fit_transform(x)
xs特征选择
Filter:过滤法
过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
方差选择法
使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。使用feature_selection库的VarianceThreshold类来选择特征
from sklearn.feature_selection import VarianceThreshold
#方差选择法,返回值是特征筛选后的结果
xs = VarianceThreshold(threshold = 0.5).fit_transform(x)
当然也可以
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold(threshold=0.1) # 剔除方差<0.1的特征
X_selected = selector.fit_transform(X)卡方检验
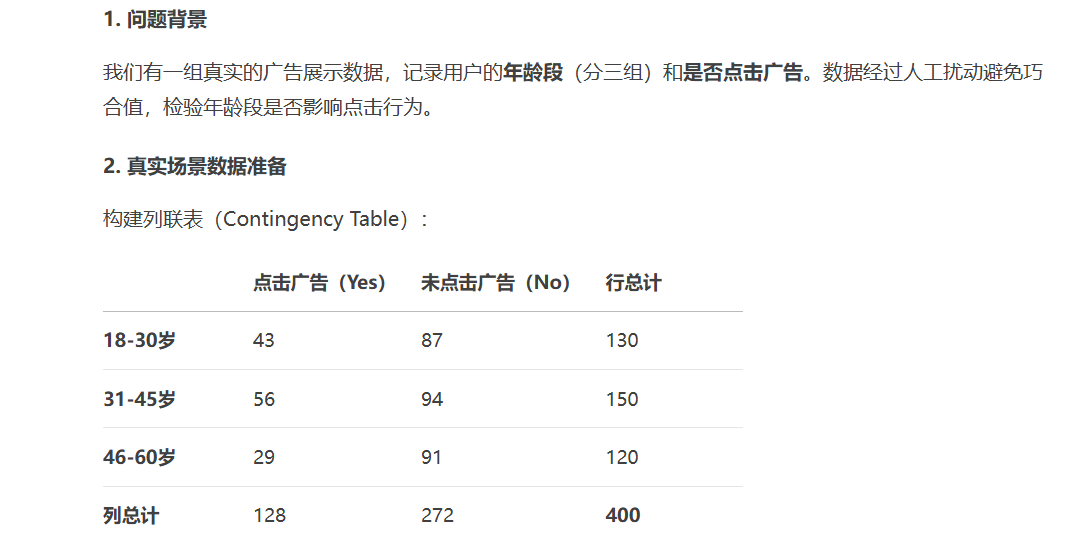
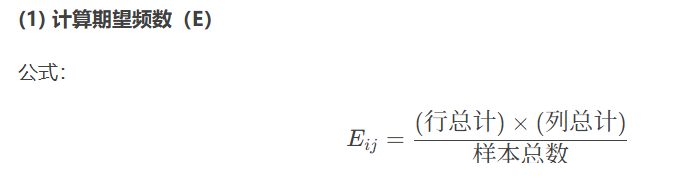

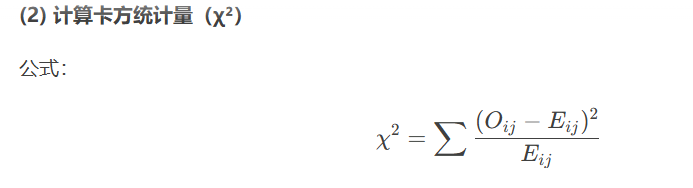


#选择K个最好的特征,返回的就是选择后的特征
from sklearn.feature_selection import SelectKBest, chi2
selector = SelectKBest(chi2, k=10) # 选择Top 10特征
X_selected = selector.fit_transform(X, y)互信息(Mutual Information)
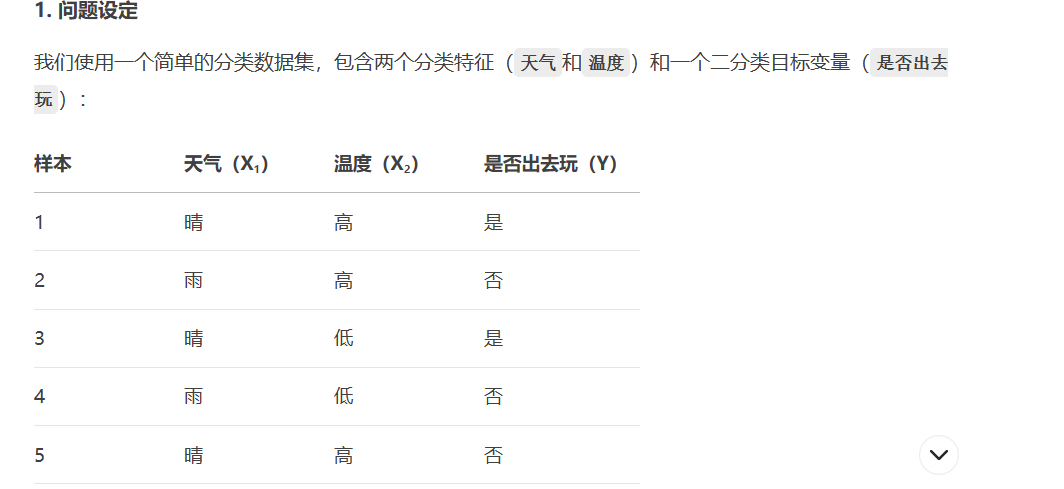

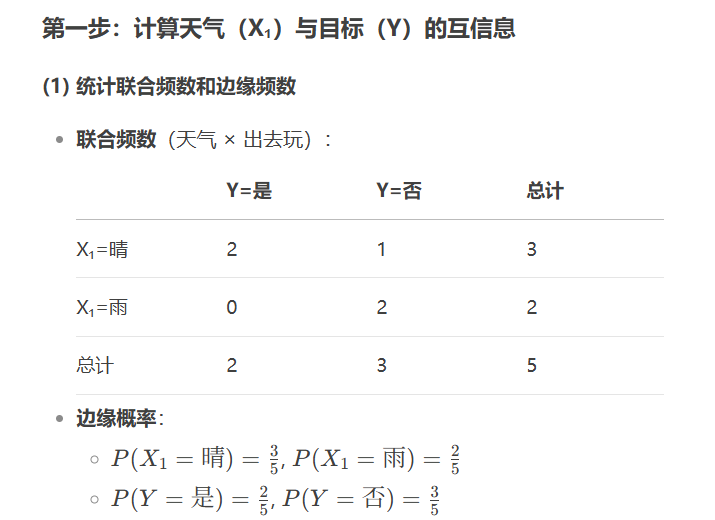
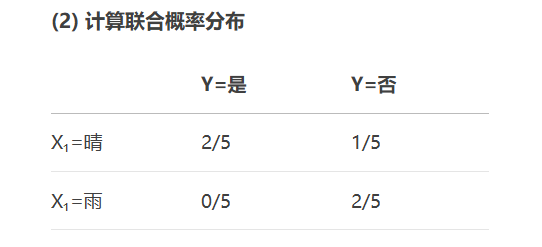

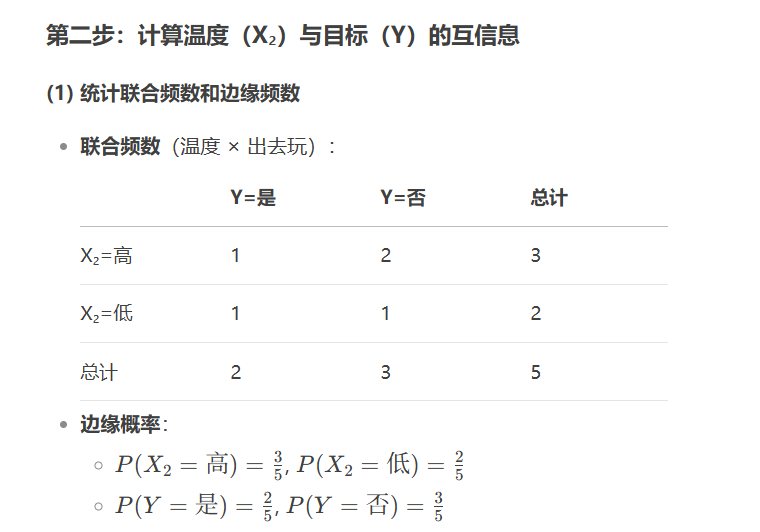
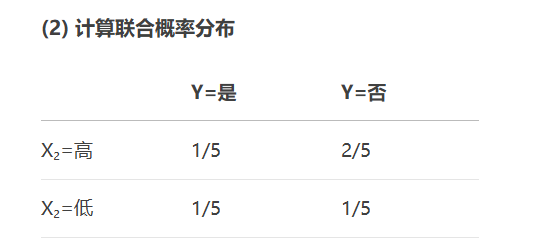

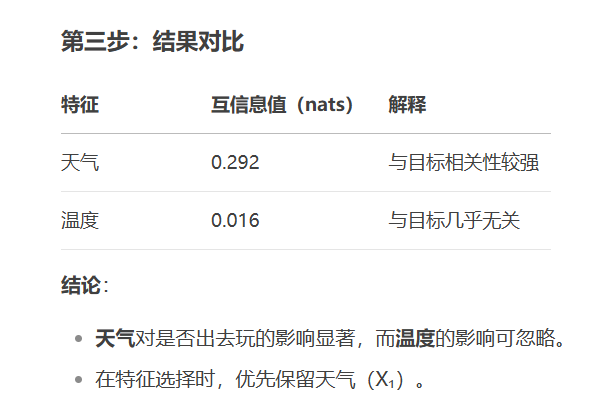
from sklearn.feature_selection import mutual_info_classif
mi_scores = mutual_info_classif(X, y)包裹法(Wrapper Methods)
递归特征消除法
逐步剔除最不重要的特征(基于模型权重)。




from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
selector = RFE(model, n_features_to_select=5) # 选择5个特征
X_selected = selector.fit_transform(X, y)顺序特征选择(SFS)
前向/后向逐步添加或删除特征。

前向




向后


forward=True是前进
forward=False是后退
from mlxtend.feature_selection import SequentialFeatureSelector
sfs = SequentialFeatureSelector(model, k_features=3, forward=True)
sfs.fit(X, y)Embedded:嵌入法

先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣
基于惩罚项的特征选择法
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression# 使用带L2惩罚性的逻辑回归作为基础模型的特征选择
xs = SelectFromModel(LogisticRegression(penalty='l2', C=0.1)).fit_transform(x, y)
xs# 直接使用带惩罚性的逻辑回归,看看每个特征的权重顺序
clf = LogisticRegression(penalty='l2', C=0.1)
clf.fit(x, y) # 训练模型# 查看模型的特征重要性评估
importances = clf.coef_
abs(importances[0])基于树模型的特征选择法
# 导入必要的库
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer # 示例数据集# 1. 加载示例数据集(乳腺癌数据集)
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.targetprint("原始特征维度:", X.shape)# 2. 使用随机森林进行特征选择
# 初始化随机森林分类器
rf = RandomForestClassifier(n_estimators=100, random_state=42)# 使用SelectFromModel进行特征选择(默认阈值是特征重要性的均值)
selector = SelectFromModel(rf)
X_selected = selector.fit_transform(X, y)# 获取被选中的特征
selected_features = X.columns[selector.get_support()]
print("\n选中的特征数量:", len(selected_features))
print("选中的特征:", selected_features.tolist())# 3. 单独训练随机森林并查看特征重要性
# 初始化并训练随机森林
rf_full = RandomForestClassifier(n_estimators=100, random_state=42)
rf_full.fit(X, y)# 获取特征重要性
importances = rf_full.feature_importances_
indices = np.argsort(importances)[::-1] # 按重要性降序排列# 4. 打印特征重要性排序
print("\n特征重要性排序:")
for i, idx in enumerate(indices):print(f"{i+1}. {X.columns[idx]}: {importances[idx]:.4f}")# 5. 可视化特征重要性(可选)
import matplotlib.pyplot as pltplt.figure(figsize=(12, 6))
plt.title("Feature Importances")
plt.bar(range(X.shape[1]), importances[indices], align="center")
plt.xticks(range(X.shape[1]), X.columns[indices], rotation=90)
plt.xlim([-1, X.shape[1]])
plt.tight_layout()
plt.show()