项目实战——矿物识别系统(利用机器学习从化学元素数据中识别矿物,从数据到分类模型)

一 数据初探
现在我们有这样一千多条数据,其中包含各个元素的含量,最后有个矿物类别。
项目目标: 构建一个机器学习模型,能够根据矿物的化学成分(包括pH值)数据,自动、快速、有效地预测其矿物类型。
二 项目框架
看到这样的数据和目标,我们有以下计划
1 数据处理(使用多种方法,找最佳)
2 模型选择(使用多种模型,找最佳)
3 记录下最佳模型,保存使用
三 数据处理
我们注意到数据中有许多异常值和空值,例如/和7..8这样的数据,所以我们要先对数据进行处理。
1 异常值处理
这里我们想法就是把数据中所有异常值转化为空值,例如将\ 和空格和7..8这样的数据转为空值,然后再进行下一步的填充。
代码部分:
data=pd.read_excel('矿物数据.xls')
data=data[data['矿物类型'] != 'E']
# print(data.head())X=data.drop(['序号','矿物类型'],axis=1)
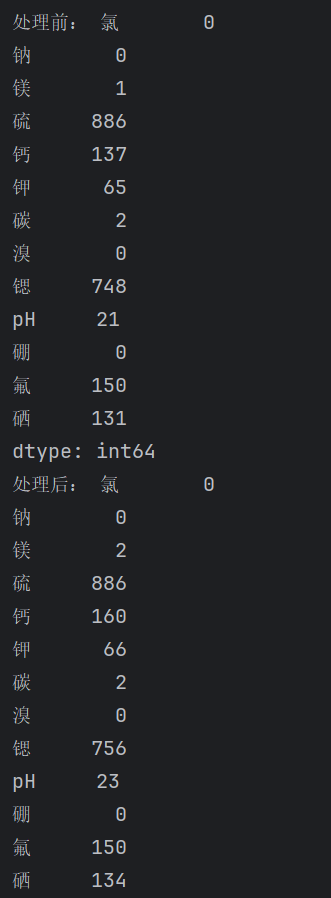
y=data.矿物类型print("处理前:",X.isnull().sum())
for i in data.columns:X[i]=pd.to_numeric(X[i],errors='coerce')print("处理后:",X.isnull().sum())这里就先导入的数据,由于E的数据就只有一条,可能是抄错了或者是怎么了,所以这里我们先把这条数据给去除了。然后我们把数据分为特征集和标签集,然后我们把特征集中的异常值全部转化为了空值,这里我们可以查看空值的数量
2 矿物类型转换
先前我们的特征是ABCD,这里我们转化为0123,然后再转化为pd类型。主要是有利于后面处理。
label_dict={"A":0,"B":1,"C":2,"D":3}
ls=[]
for i in y.values:# print(i)ls.append(label_dict[i])
y=pd.Series(ls,name='矿物类型')3 数据标准化
from sklearn.preprocessing import StandardScaler
scaler =StandardScaler()
X_Z=scaler.fit_transform(X)
X_Z=pd.DataFrame(X_Z,columns=X.columns)我们可以看出数据的数值差距还是很大的,所以这里我们把数据进行标准化。
4 数据集划分
from sklearn.model_selection import train_test_split
train_x,test_x,train_y,test_y=train_test_split(X_Z,y,test_size=0.2)5 空值处理
这里我们采用的五种方法来对空值进行填充,分别是把空值行删除,用该类别该元素的均值填充,中位数值填充,众数填充,线性回归预测填充,随机森林预测填充。下面来一一实现。
下面我对所有填充过程写了一个程序fill_data里面包含了上面6种方法,我们直接调用导入即可。
import fill_data
#删除空值行
# train_x,train_y=fill_data.cca_train_fill(train_x,test_x,train_y,test_y)
# test_x,test_y=fill_data.cca_test_fill(train_x,test_x,train_y,test_y)#填充平均值
# train_x,train_y=fill_data.mean_train_fill(train_x,test_x,train_y,test_y)
# test_x,test_y=fill_data.mean_test_fill(train_x,test_x,train_y,test_y)#填充众数
# train_x,train_y=fill_data.mean_train_fill(train_x,test_x,train_y,test_y)
# test_x,test_y=fill_data.mean_test_fill(train_x,test_x,train_y,test_y)#填充中位数
# train_x,train_y=fill_data.mode_train_fill(train_x,test_x,train_y,test_y)
# test_x,test_y=fill_data.mode_test_fill(train_x,test_x,train_y,test_y)#线性回归填充
# train_x,train_y=fill_data.lr_train_fill(train_x,test_x,train_y,test_y)
# test_x,test_y=fill_data.lr_test_fill(train_x,test_x,train_y,test_y)#随机森林
# train_x,train_y=fill_data.RF_train_fill(train_x,test_x,train_y,test_y)
# test_x,test_y=fill_data.RF_test_fill(train_x,test_x,train_y,test_y)下面是具体实现过程。
5.1空值行删除
def cca_train_fill(train_x,test_x,train_y,test_y):data=pd.concat([train_x,train_y],axis=1)data.dropna(inplace=True)print(data.head())X=data.drop(columns=['矿物类型'])y=data.矿物类型return X,ydef cca_test_fill(train_x,test_x,train_y,test_y):data=pd.concat([test_x,test_y],axis=1)data.dropna(inplace=True)X=data.drop(columns=['矿物类型'])y=data.矿物类型return X,y对于测试集和训练集都一样,我们都是先连接特征和标签,然后使用pandas中的方法dropna(inplace=True),这个方法就是把空值行删除。然后再返回两个值就可以了。
5.2均值填充
def train_mean_m(data):f=data.mean()return data.fillna(f)def mean_train_fill(train_x,test_x,train_y,test_y):data=pd.concat([train_x,train_y],axis=1,ignore_index=False)data = data.reset_index(drop=True)A=data[data['矿物类型']==0]B=data[data['矿物类型']==1]C=data[data['矿物类型']==2]D=data[data['矿物类型']==3]A_fill = train_mean_m(A)B_fill = train_mean_m(B)C_fill = train_mean_m(C)D_fill = train_mean_m(D)data=pd.concat([A_fill,B_fill,C_fill,D_fill],axis=0)# data = data.reset_index(drop=True)X = data.drop(columns=['矿物类型'])y = data.矿物类型return X,ydef test_mean_m(data,Date):f=data.mean()return Date.fillna(f)def mean_test_fill(train_x, test_x, train_y, test_y):data=pd.concat([train_x,train_y],axis=1,ignore_index=False)data = data.reset_index(drop=True)A=data[data['矿物类型']==0]B=data[data['矿物类型']==1]C=data[data['矿物类型']==2]D=data[data['矿物类型']==3]Data =pd.concat([test_x, test_y], axis=1)# Data = Data.reset_index(drop=True)a = Data[Data['矿物类型'] == 0]b = Data[Data['矿物类型'] == 1]c = Data[Data['矿物类型'] == 2]d = Data[Data['矿物类型'] == 3]A_fill = test_mean_m(A,a)B_fill = test_mean_m(B,b)C_fill = test_mean_m(C,c)D_fill = test_mean_m(D,d)data = pd.concat([A_fill, B_fill, C_fill, D_fill], axis=0)X = data.drop(columns=['矿物类型'])y = data.矿物类型return X, y
对于训练集,我们先把数据合成一个,然后把四种数据类型分开,因为要用每种数据类型的该特征的均值来填充这个空值。然后我们这里还写了一个函数用来专门填充每一类的均值,最后把四类连接起来,注意axis=0然后就分开特征集和标签集分开。
对于测试集,我们用的方法差不多,唯一不同就是我们用的是训练集的那个类别那个特征的均值来填充的。(data表示训练集,Data表示测试集)
5.3中位数值填充
def train_media_m(data):f=data.median()return data.fillna(f)def median_train_fill(train_x,test_x,train_y,test_y):data = pd.concat([train_x, train_y], axis=1, ignore_index=False)data = data.reset_index(drop=True)A = data[data['矿物类型'] == 0]B = data[data['矿物类型'] == 1]C = data[data['矿物类型'] == 2]D = data[data['矿物类型'] == 3]A_fill = train_media_m(A)B_fill = train_media_m(B)C_fill = train_media_m(C)D_fill = train_media_m(D)data = pd.concat([A_fill, B_fill, C_fill, D_fill], axis=0)# data = data.reset_index(drop=True)X = data.drop(columns=['矿物类型'])y = data.矿物类型return X, ydef test_median_m(data,Date):f=data.median()return Date.fillna(f)def median_test_fill(train_x, test_x, train_y, test_y):data=pd.concat([train_x,train_y],axis=1,ignore_index=False)data = data.reset_index(drop=True)A=data[data['矿物类型']==0]B=data[data['矿物类型']==1]C=data[data['矿物类型']==2]D=data[data['矿物类型']==3]Data =pd.concat([test_x, test_y], axis=1)# Data = Data.reset_index(drop=True)a = Data[Data['矿物类型'] == 0]b = Data[Data['矿物类型'] == 1]c = Data[Data['矿物类型'] == 2]d = Data[Data['矿物类型'] == 3]A_fill = test_median_m(A,a)B_fill = test_median_m(B,b)C_fill = test_median_m(C,c)D_fill = test_median_m(D,d)data = pd.concat([A_fill, B_fill, C_fill, D_fill], axis=0)X = data.drop(columns=['矿物类型'])y = data.矿物类型return X, y这种方法和上面的很相似,主要区别就是我们的填充函数中的变化,由mean()变成了median(),一个是求均值的一个是求函数的。
5.4众数填充
def train_mode_m(data):f=data.mode()[0]return data.fillna(f)def mode_train_fill(train_x,test_x,train_y,test_y):data = pd.concat([train_x, train_y], axis=1, ignore_index=False)data = data.reset_index(drop=True)A = data[data['矿物类型'] == 0]B = data[data['矿物类型'] == 1]C = data[data['矿物类型'] == 2]D = data[data['矿物类型'] == 3]A_fill = train_media_m(A)B_fill = train_media_m(B)C_fill = train_media_m(C)D_fill = train_media_m(D)data = pd.concat([A_fill, B_fill, C_fill, D_fill], axis=0)# data = data.reset_index(drop=True)X = data.drop(columns=['矿物类型'])y = data.矿物类型return X, ydef test_mode_m(data,Date):f=data.mode()[0]return Date.fillna(f)def mode_test_fill(train_x, test_x, train_y, test_y):data=pd.concat([train_x,train_y],axis=1,ignore_index=False)data = data.reset_index(drop=True)A=data[data['矿物类型']==0]B=data[data['矿物类型']==1]C=data[data['矿物类型']==2]D=data[data['矿物类型']==3]Data =pd.concat([test_x, test_y], axis=1)# Data = Data.reset_index(drop=True)a = Data[Data['矿物类型'] == 0]b = Data[Data['矿物类型'] == 1]c = Data[Data['矿物类型'] == 2]d = Data[Data['矿物类型'] == 3]A_fill = test_median_m(A,a)B_fill = test_median_m(B,b)C_fill = test_median_m(C,c)D_fill = test_median_m(D,d)data = pd.concat([A_fill, B_fill, C_fill, D_fill], axis=0)X = data.drop(columns=['矿物类型'])y = data.矿物类型return X, y这个也和上面两种方法很类似,主要也是变了一个函数,变成了众数的函数mode()。
5.5线性回归预测填充
这种方法就有点复杂了,下面我们一点一点的讲解。
这个的主体思想就是,先找出有空值的特征,然后进行排序,然后我们选填充缺的少的那一个特征,然后我们就先把已经知道的特征作为特征,有空值的那一个为y标签(后面预测)
对于训练集
def lr_train_fill(train_x,test_x,train_y,test_y):data=pd.concat([train_x,train_y],axis=1,ignore_index=False)data = data.reset_index(drop=True)null_index=data.isnull().sum().sort_values(ascending=True)nullname=null_index.index.tolist()predictors = []# print(null_index)# print(nullname)for i in nullname:predictors.append(i)if null_index[i] != 0:t_X=data[predictors].drop(i,axis=1)t_y=data[i]test_row=data[data[i].isnull()].index.tolist()# print(test_row)test=t_X.iloc[test_row]t_X=t_X.drop(test_row)t_y=t_y.drop(test_row)# print(test)lr=linear_model.LinearRegression()lr.fit(t_X,t_y)pre=lr.predict(test)data.loc[test_row,i]= pre# print('完成训练集{0}列的填充,填充数据{1}'.format(i,pre))print('完成训练集{0}列的填充'.format(i))X = data.drop(columns=['矿物类型'])y = data.矿物类型return X, y这里先把数据连接起来,然后把索引重置一下,不然会影响下面操作。
null_index=data.isnull().sum().sort_values(ascending=True)nullname=null_index.index.tolist()这一步是把空值的个数排序,然后把特征名排序,为了后面使用。
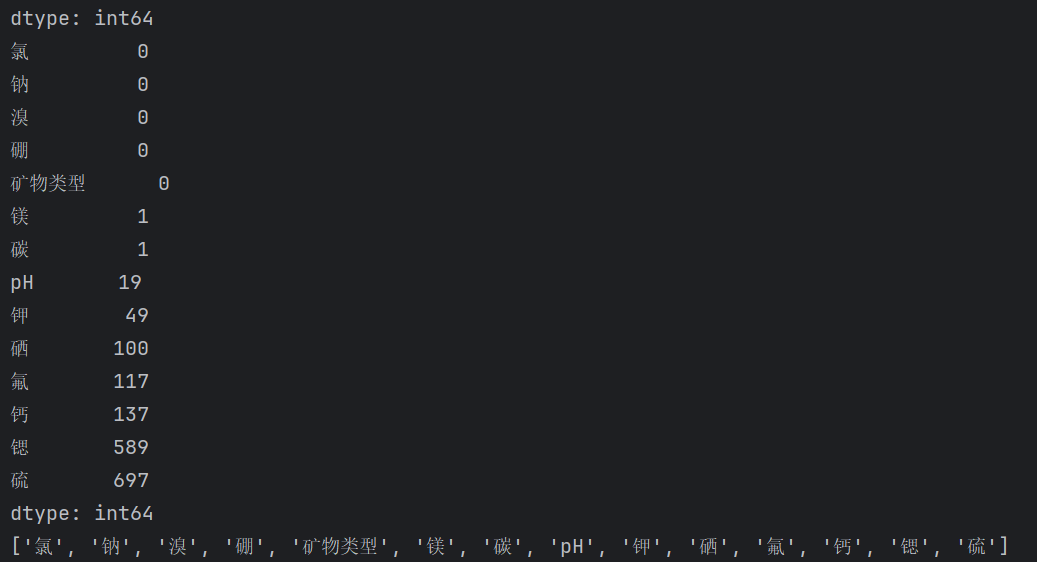
我们先创建了一个空列表,然后循环上面的排序好的列表,前面几个为0的直接添加进去了,然后直到遇到了大于0的,这个时候把我们列表中的特征作为训练集,这个缺失的作为y去预测。这里的data是包含了一个也不缺了,和这个缺失最少的一个特征,所有t_X和t_y是分割数据集和特征集。然后test_row是找出了data哪一列中缺失,然后把那些行的索引以列表返回。然后我们的预测集也找到了就是test_row索引的那一行的数据,刚好缺失一个y值后面可以预测。然后我们也要对t_X和t_y进行更新,因为要去除刚才的缺失的那一行。然后就对这些test数据进行预测,然后按照顺序添加到data数据集中。
predictors = []# print(null_index)# print(nullname)for i in nullname:predictors.append(i)if null_index[i] != 0:t_X=data[predictors].drop(i,axis=1)t_y=data[i]test_row=data[data[i].isnull()].index.tolist()# print(test_row)test=t_X.iloc[test_row]t_X=t_X.drop(test_row)t_y=t_y.drop(test_row)# print(test)lr=linear_model.LinearRegression()lr.fit(t_X,t_y)pre=lr.predict(test)data.loc[test_row,i]= pre# print('完成训练集{0}列的填充,填充数据{1}'.format(i,pre))print('完成训练集{0}列的填充'.format(i))最后再返回一个X和y即可。
对于测试集
def lr_test_fill(train_x,test_x,train_y,test_y):data=pd.concat([train_x,train_y],axis=1,ignore_index=False)data = data.reset_index(drop=True)Data = pd.concat([test_x, test_y], axis=1, ignore_index=False)Data = Data.reset_index(drop=True)null_index=Data.isnull().sum().sort_values(ascending=True)nullname=null_index.index.tolist()predictors = []# print(null_index)# print(nullname)for i in nullname:predictors.append(i)if null_index[i] != 0:t_X=data[predictors].drop(i,axis=1)t_y=data[i]test_row=Data[Data[i].isnull()].index.tolist() #获取包含空行的索引值print(test_row)T_X=Data[predictors].drop(i,axis=1) #获取已知的数据(包含含空值的列)test=T_X.iloc[test_row] #获取包含空值那一行的其他数据作为X# print(test)lr=linear_model.LinearRegression()lr.fit(t_X,t_y)pre=lr.predict(test)Data.loc[test_row,i]= pre# print('完成训练集{0}列的填充,填充数据{1}'.format(i,pre))print('完成训练集{0}列的填充'.format(i))X = data.drop(columns=['矿物类型'])y = data.矿物类型return X, y预测集和训练集的处理方法大体相同,因为测试集的填充是用训练集已经填充好的数据集来训练,然后找出自己缺失的数据来作预测集,然后进行填充。
5.6随机森林预测填充
如果已经懂了上面lr预测填充那么这里的RF的方法也很简单了,主要就是替换了一个模型方法,这里我就直接给出代码了。
def RF_train_fill(train_x,test_x,train_y,test_y):data=pd.concat([train_x,train_y],axis=1,ignore_index=False)data = data.reset_index(drop=True)null_index=data.isnull().sum().sort_values(ascending=True)nullname=null_index.index.tolist()predictors = []# print(null_index)# print(nullname)for i in nullname:predictors.append(i)if null_index[i] != 0:t_X=data[predictors].drop(i,axis=1)t_y=data[i]test_row=data[data[i].isnull()].index.tolist()# print(test_row)test=t_X.iloc[test_row]t_X=t_X.drop(test_row)t_y=t_y.drop(test_row)# print(test)RF=RandomForestRegressor(n_estimators=100)RF.fit(t_X,t_y)pre=RF.predict(test)data.loc[test_row,i]= preprint('完成训练集{0}列的填充'.format(i))# print('完成训练集{0}列的填充,填充数据{1}'.format(i,pre))X = data.drop(columns=['矿物类型'])y = data.矿物类型return X, y#小写训练集,大写测试集
def RF_test_fill(train_x,test_x,train_y,test_y):data=pd.concat([train_x,train_y],axis=1,ignore_index=False)data = data.reset_index(drop=True)Data = pd.concat([test_x, test_y], axis=1, ignore_index=False)Data = Data.reset_index(drop=True)null_index=Data.isnull().sum().sort_values(ascending=True)nullname=null_index.index.tolist()predictors = []# print(null_index)# print(nullname)for i in nullname:predictors.append(i)if null_index[i] != 0:t_X=data[predictors].drop(i,axis=1)t_y=data[i]test_row=Data[Data[i].isnull()].index.tolist() #获取包含空行的索引值T_X=Data[predictors].drop(i,axis=1) #获取已知的数据(包含含空值的列)test=T_X.iloc[test_row] #获取包含空值那一行的其他数据作为X# print(test)RF=RandomForestRegressor(n_estimators=100)RF.fit(t_X,t_y)pre=RF.predict(test)Data.loc[test_row,i]= preprint('完成测试集{0}列的填充'.format(i))# print('完成训练集{0}列的填充,填充数据{1}'.format(i,pre))X = data.drop(columns=['矿物类型'])y = data.矿物类型return X, y唯一替换的部分 RF=RandomForestRegressor(n_estimators=100)
6 过采样
from imblearn.over_sampling import SMOTE#imblearn这个库里面调用, oversampler = SMOTE(random_state=0)#保证数据拟合效果,随机种子 train_x, train_y = oversampler.fit_resample(train_x, train_y)#人工拟合数据
这里我们注意到每个矿物类型数量可能不均衡,所以我们用SMOTE算法进行数据拟合一下。经典算法了,不过多介绍了
7 保存
tem_train=pd.concat([train_x,train_y],axis=1)
data = data.reset_index(drop=True)
tem_test=pd.concat([test_x,test_y],axis=1)
#
tem_train.to_excel('date处理结果/随机森林填充_train.xlsx')
tem_test.to_excel('date处理结果/随机森林填充_test.xlsx')这里还把每个数据都保存下来了,为了后面训练可以直接用数据,不用再去填充了。
总结
上面我们采用了六种方法来填充数据,主要是为了找出最好的那种方法,在不知道哪种方法好的时候就是要一个一个的试。
四 模型训练
这里我们也采用好几种算法模型来进行训练,来找寻最好的模型方法。分别XGboost,adaptboost,随机森林,逻辑回归,SVM支持向量机,高斯贝叶斯这六种算法进行训练。然后对上面每一个数据集进行训练,例如对于平均值填充的数据集,用这六种模型进行训练,然后对其他五种数据集也都使用这几种数据集进行训练,找出最好的结果。
这里我们还要对模型调优,所以这里我们采用了 网格搜索算法,这个就是交叉验证的进阶版本,不用我们for循环一个一个试了。
导入平均值填充的数据集
import pandas as pd#平均值填充
train_date=pd.read_excel('.\date处理结果\平均数填充_train.xlsx')
test_date=pd.read_excel('.\date处理结果\平均数填充_test.xlsx')
print(train_date.head())
train_X=train_date.drop(columns=['矿物类型','Unnamed: 0'],axis=1)
train_y=train_date['矿物类型']test_X=test_date.drop(columns=['矿物类型','Unnamed: 0'],axis=1)
test_y=test_date['矿物类型']1 逻辑回归
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV # 网格搜索
from sklearn import metrics# LR逻辑回归
# 定义超参数搜索网格
param_grid = [# 兼容OvR策略的组合{'solver': ['liblinear'],'penalty': ['l1', 'l2'],'multi_class': ['ovr'], # 必须显式指定ovr'C': [0.001, 0.01, 0.1, 1, 10, 100],'max_iter': [1000] # L1正则需更多迭代},# 兼容Multinomial策略的组合{'solver': ['sag', 'saga', 'lbfgs'],'penalty': ['l2', None],'multi_class': ['multinomial'],'C': [0.001, 0.01, 0.1, 1, 10, 100],'max_iter': [500]}
]# 初始化逻辑回归模型
logreg = LogisticRegression()# 创建网格搜索对象(5折交叉验证)
grid_search = GridSearchCV(logreg, param_grid, cv=5)# 在训练集上执行网格搜索(需提供实际数据)
grid_search.fit(train_X, train_y ) # 注意:train_data_x, train_data_y 需提前定义# 输出最佳参数组合
print("Best parameters set found on development set:")
print(grid_search.best_params_)res=grid_search.best_params_res={'C': 100, 'max_iter': 200, 'multi_class': 'auto', 'penalty': 'l1', 'solver': 'liblinear'}LR={}
lr=LogisticRegression(C = res['C'], max_iter = res['max_iter'], multi_class= res['multi_class'], penalty = res['penalty'], solver = res['solver'])
lr.fit(train_X,train_y)
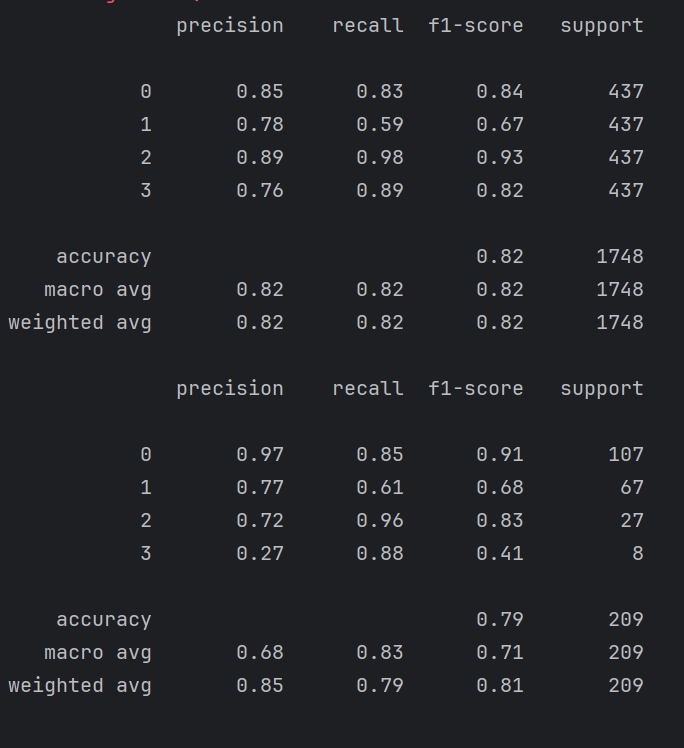
print(metrics.classification_report(train_y,lr.predict(train_X)))
print(metrics.classification_report(test_y,lr.predict(test_X)))
a=(metrics.classification_report(test_y,lr.predict(test_X))).split()
# print(a)
# print(a[5])
# print(a[25])
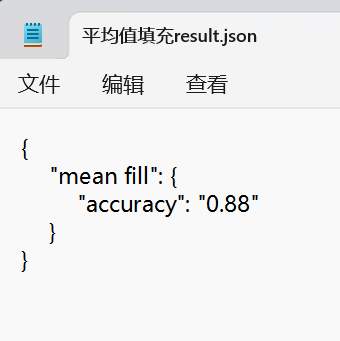
LR['accuracy']=a[21]import json # 数据格式,网络传输。保存提取json类型的数据。csv:表格类型的数据# 创建结果字典 - 用于存储不同填充方法的模型评估结果
result = {}# (示例)单点测试的代码(实际应为赋值操作)
# result {'mean fill': {'LR': {'recall_0': 0.835227, 'recall_1': 0.845}# 核心操作:将填充方法的数据结果存入字典
result['mean fill'] = LR # 将result_data赋值给字典键"mean fill"# 文件存储操作
with open(r'temp_data/平均值填充result.json', 'w', encoding='utf-8') as file:# 使用json.dump()方法将字典转换为JSON格式并写入文件(JSON一般是字典结构)json.dump(result, # 要转换的字典数据file, # 文件对象ensure_ascii=False, # 允许中文等非ASCII字符indent=4 # 4空格缩进格式化)
这里我们使用网格搜索算法找到最优参数,然后把最优参数导入到数据集进行训练就好了,然后保存最终的准确率(最好把每个类型的召回率也保存下来)
这里是我这个模型跑出来的最优模型参数,不过结果准确率也不是很高。
![]()
然后也保存了一个json的文件
2 随机森林
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
import numpy as np
#
# 定义参数网格(根据需求调整范围)
param_grid = {'n_estimators': [100, 200, 500], # 树的数量'max_depth': [None, 10, 20, 30], # 树最大深度(None表示不限制)'min_samples_split': [2, 5, 10], # 分裂所需最小样本数'min_samples_leaf': [1, 2, 4], # 叶节点最小样本数'max_features': ['sqrt', 'log2', 0.5], # 寻找最佳分裂时考虑的特征数量/比例'bootstrap': [True, False], # 是否使用有放回抽样'class_weight': [None, 'balanced', 'balanced_subsample'] # 处理不平衡数据
}# 初始化随机森林模型
rf = RandomForestClassifier(random_state=42) # 设置随机种子保证结果可复现# 创建网格搜索对象(使用5折交叉验证)
grid_search = GridSearchCV(estimator=rf,param_grid=param_grid,cv=5, # 5折交叉验证scoring='accuracy', # 评估指标(可改为f1、roc_auc等)verbose=2, # 输出详细日志(0为不输出,值越大越详细)n_jobs=-1 # 使用所有CPU核心并行计算
)# 执行网格搜索(替换为您的训练数据)
grid_search.fit(train_X, train_y)# 输出最佳参数和交叉验证得分
print("Best parameters found: ")
print(grid_search.best_params_)
print(f"Best cross-validation score: {grid_search.best_score_:.4f}")# 保存最佳模型(可选)
best_rf = grid_search.best_estimator_
# 用joblib保存模型,便于后续部署
from joblib import dump
dump(best_rf, 'random_forest_best_model.joblib')# res= {'bootstrap': False, 'class_weight': None, 'max_depth': 10, 'max_features': 0.5, 'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 100}
res= {'max_depth': 10, 'max_features': 0.5, 'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 100}
RF=RandomForestClassifier(max_depth=10, max_features= 0.5, min_samples_leaf= 1, min_samples_split= 2, n_estimators=100)
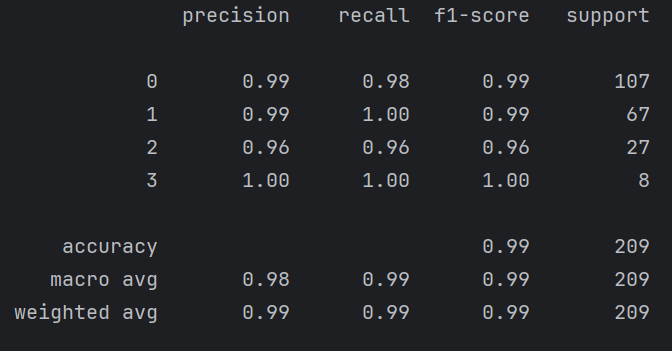
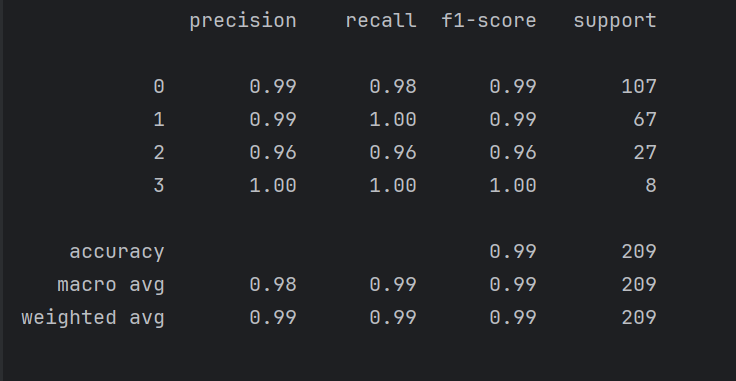
RF.fit(train_X,train_y)print(metrics.classification_report(test_y,RF.predict(test_X)))a=metrics.classification_report(test_y,RF.predict(test_X))
rf={}
rf['accuracy']=a[21]import json # 数据格式,网络传输。保存提取json类型的数据。csv:表格类型的数据# 创建结果字典 - 用于存储不同填充方法的模型评估结果
result = {}# (示例)单点测试的代码(实际应为赋值操作)
# result {'mean fill': {'LR': {'recall_0': 0.835227, 'recall_1': 0.845}# 核心操作:将填充方法的数据结果存入字典
result['mean fill RF'] = rf # 将result_data赋值给字典键"mean fill"
# 文件存储操作
with open(r'temp_data/平均值填充result.json', 'w', encoding='utf-8') as file:# 使用json.dump()方法将字典转换为JSON格式并写入文件(JSON一般是字典结构)json.dump(result, # 要转换的字典数据file, # 文件对象ensure_ascii=False, # 允许中文等非ASCII字符indent=4 # 4空格缩进格式化)可以看出随机深林的准确率和召回率都是特别高的了。在我们交项目的时候极有可能就用这个来交付了。
后面每一种我们都要这样跑一遍,并且话还要对每一个数据集都要跑一遍,这里篇幅有限,而且需要很久的时间才能跑完,所以这里就举出这两个例子,其余的我给出示例
综合
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
import json
import numpy as npdef grid_search_to_json(estimator, param_grid, train_X, train_y, model_name):"""执行网格搜索并将结果保存到JSON"""grid_search = GridSearchCV(estimator=estimator,param_grid=param_grid,cv=5,scoring='accuracy',verbose=2,n_jobs=-1)grid_search.fit(train_X, train_y)return {"model": model_name,"best_params": grid_search.best_params_,"best_score": float(grid_search.best_score_),"best_estimator": str(grid_search.best_estimator_)}# 假设已有训练数据 train_X, train_y
all_results = []# 1. XGBoost
xgb_params = {'n_estimators': [100, 200, 300],'max_depth': [3, 5, 7],'learning_rate': [0.01, 0.1, 0.2],'subsample': [0.8, 1.0],'colsample_bytree': [0.8, 1.0]
}
all_results.append(grid_search_to_json(XGBClassifier(random_state=42, use_label_encoder=False),xgb_params, train_X, train_y, "XGBoost"
))# 2. AdaBoost
adaboost_params = {'n_estimators': [50, 100, 200],'learning_rate': [0.1, 0.5, 1.0],'algorithm': ['SAMME', 'SAMME.R']
}
all_results.append(grid_search_to_json(AdaBoostClassifier(random_state=42),adaboost_params, train_X, train_y, "AdaBoost"
))# 3. 随机森林 (已在图中示例,保持相同)
rf_params = {'n_estimators': [100, 200, 500],'max_depth': [None, 10, 20, 30],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 4],'max_features': ['sqrt', 'log2', 0.5],'bootstrap': [True, False],'class_weight': [None, 'balanced', 'balanced_subsample']
}
all_results.append(grid_search_to_json(RandomForestClassifier(random_state=42),rf_params, train_X, train_y, "RandomForest"
))# 4. 逻辑回归
lr_params = {'penalty': ['l1', 'l2', 'elasticnet', 'none'],'C': [0.001, 0.01, 0.1, 1.0, 10.0],'solver': ['newton-cg', 'lbfgs', 'liblinear', 'sag', 'saga'],'max_iter': [100, 500, 1000]
}
all_results.append(grid_search_to_json(LogisticRegression(random_state=42, multi_class='ovr'),lr_params, train_X, train_y, "LogisticRegression"
))# 5. SVM
svm_params = {'C': [0.1, 1.0, 10.0],'kernel': ['linear', 'poly', 'rbf', 'sigmoid'],'gamma': ['scale', 'auto'],'degree': [2, 3, 4],'class_weight': [None, 'balanced']
}
all_results.append(grid_search_to_json(SVC(random_state=42, probability=True),svm_params, train_X, train_y, "SVM"
))# 6. 高斯贝叶斯
# 注意:GaussianNB 参数较少,主要调整先验概率和平滑参数
nb_params = {'var_smoothing': [1e-9, 1e-8, 1e-7, 1e-6]
}
all_results.append(grid_search_to_json(GaussianNB(),nb_params, train_X, train_y, "GaussianNB"
))# 保存所有结果到JSON文件
with open('model_tuning_results.json', 'w') as f:json.dump(all_results, f, indent=4)print("所有模型调优结果已保存到 model_tuning_results.json")五 总结
这里我们采用了六种填充方法和六种机器学习算法(其实还可以用深度学习的方法来训练,说不定效果更好,后面学习后再来尝试),其中我们使用均值填充的方法和随机森林的方法对这个问题进行解决,最终我们达到了0.99的准确率,说实话这个准确率已经很高了。