IP 分片和组装的具体过程
IP 分片和组装的具体过程
在这里插入图片描述
• 16 位标识(id): 唯一的标识主机发送的报文. 如果 IP 报文在数据链路层被分片了, 那么每一个片里面的这个 id 都是相同的.
• 3 位标志字段: 第一位保留(保留的意思是现在不用, 但是还没想好说不定以后要用到). 第二位置为 1 表示禁止分片, 这时候如果报文长度超过 MTU, IP 模块就会丢弃报文. 第三位表示"更多分片", 如果分片了的话, 最后一个分片置为 0, 其他是 1. 类似于一个结束标记.
• 13 位分片偏移(framegament offset): 是分片相对于原始 IP 报文开始处的偏移. 其实就是在表示当前分片在原报文中处在哪个位置. 实际偏移的字节数是这个值 除以 8 得到的. 因此, 除了最后一个报文之外(之前如果都是 8 的整数倍,最后一片的偏移量也一定是 8 的整数倍), 其他报文的长度必须是 8 的整数倍(否则报文就不连续了).
• 注意:片偏移(13 位)表示本片数据在它所属的原始数据报数据区中的偏移量(以 8 字节为单位)
分片与组装的过程
分片
- 检查 MTU 限制:
○ 当一个 IP 数据报的大小超过了网络的 MTU(最大传输单元)限制时,就需要进行分片。MTU 是数据链路层对 IP 层数据包进行封装时所能接受的最大数据长度。
- 分割数据报:
○ IP 层将原始的 IP 数据报分割成多个较小的片段。
○ 对于每个片段,IP 层会设置相应的标识(Identification)、偏移量(Fragment Offset)和标志位(Flags)等字段。
○ 标识字段用于标识属于同一个数据报的不同分片,确保所有分片能够被正确地重新组装。
○ 偏移量字段指示了当前分片相对于原始数据报的起始位置,以 8 字节为单位。
○ 标志位字段包含了 3 个位,其中 MF(More Fragment)位用于指示是否还有更多的分片,DF(Do Not Fragment)位用于指示数据报是否允许进行分片。
- 添加 IP 头部:
○ 每个分片都会加上自己的 IP 头部,与完整 IP 报文拥有类似的 IP 头结构,但MF 和 Fragment Offset 等字段的值会有所不同。
- 发送分片:
○ 分片在传输过程中独立传输,每个分片都有自己的 IP 头部,并且各自独立地选择路由。
组装
- 接收分片:
○ 当目的主机的 IP 层接收到这些分片后,会根据标识字段将属于同一个数据报的所有分片挑选出来。
- 排序与组装:
○ 利用片偏移字段,IP 层会对属于同一个数据报的分片进行排序。
○ 当所有的分片都到达并正确排序后,IP 层会将这些分片重新组装成一个完整的 IP 数据报。
- 传递给上层协议:
○ 组装好的 IP 数据报会传递给上层的协议进行处理。
注意:
• IP 分片对传输层是透明的,这意味着传输层无需关心数据是否被分片以及如何重新组装。
• 接收方如何得知自己收到的报文分片了?
• 接收方如何得知自己收到的分片收全了?
• 接收方如何组合形成完整的报文?
IP分片是网络层(IP层)的功能,对传输层(如TCP/UDP)透明,即传输层不直接参与分片和重组过程。以下是接收方处理IP分片的核心机制:
1. 接收方如何得知报文被分片了?
通过IP头部中的以下字段判断:
- 分片控制字段:
MF(More Fragments)标志位:MF=1:表示当前分片不是最后一个,后续还有分片。MF=0:表示当前分片是最后一个。
Fragment Offset(分片偏移):- 表示当前分片在原始IP数据报中的偏移量(以8字节为单位)。
- 若
Fragment Offset ≠ 0或MF=1,则说明该报文是分片。
2. 接收方如何得知分片收全了?
通过以下条件综合判断:
- 所有分片的
Identification字段相同:
IP头部中的Identification(标识符)唯一标识同一个原始数据报的所有分片。 - 分片覆盖完整的数据范围:
- 最后一个分片的
MF=0。 - 分片的
Fragment Offset和长度连续覆盖原始数据报(如:前一分片的Offset + Length = 下一分片的Offset)。
- 最后一个分片的
- 重组超时机制:
若在规定时间内未收到全部分片,丢弃已收到的分片(超时时间由系统实现决定,通常为30秒或60秒)。
3. 接收方如何重组分片?
重组流程如下:
- 缓存分片:
接收方根据Identification字段将属于同一数据报的分片暂存到重组缓冲区。 - 排序与去重:
根据Fragment Offset对分片排序,并丢弃重复分片(如因网络重传导致)。 - 完整性检查:
- 检查是否覆盖从
Offset=0到最后一个分片的完整数据。 - 确保所有分片的
MF和Offset逻辑连贯。
- 检查是否覆盖从
- 重组数据报:
按顺序拼接分片数据,去除IP头部(仅保留第一个分片的IP头部),生成完整的原始IP数据报。 - 提交上层协议:
将重组后的数据报交给传输层(如TCP/UDP)处理。
关键IP头部字段
| 字段 | 作用 |
|---|---|
Identification | 唯一标识同一数据报的所有分片(通常由发送方生成)。 |
MF (More Fragments) | 标记是否为最后一个分片。 |
Fragment Offset | 当前分片在原始数据报中的位置(以8字节为单位)。 |
Total Length | 当前分片的总长度(IP头部+数据)。 |
示例:分片重组过程
假设原始IP数据报长度为4000字节(MTU=1500字节),分片如下:
- 分片1:
Offset=0,MF=1,Length=1500(含IP头)。- 数据:字节0~1479(IP头占20字节)。
- 分片2:
Offset=185(185×8=1480),MF=1,Length=1500。- 数据:字节1480~2959。
- 分片3:
Offset=370(370×8=2960),MF=0,Length=1040。- 数据:字节2960~3999。
接收方按Offset排序后拼接数据,检测到MF=0时确认分片完整,重组为原始数据报。
为什么传输层无需关心分片?
- 职责分离:IP层负责分片与重组,传输层只需处理完整的数据报。
- 透明性:传输层的协议头部(如TCP/UDP头部)仅在第一个分片中出现,后续分片仅包含数据部分。
注意事项
- 分片开销:分片会增加延迟和丢包风险(任一分片丢失会导致整个数据报丢弃)。
- 避免分片:
- 传输层可通过
Path MTU Discovery(路径MTU发现)调整报文大小。 - 应用层可主动限制数据包大小(如UDP建议≤1472字节,预留IP+ICMP头空间)。
- 传输层可通过
IP分片机制通过网络层透明化处理,确保了传输层无需感知底层分片细节,但需注意分片对性能和可靠性的潜在影响。
分片与组装过程的示意图
分片组装场景

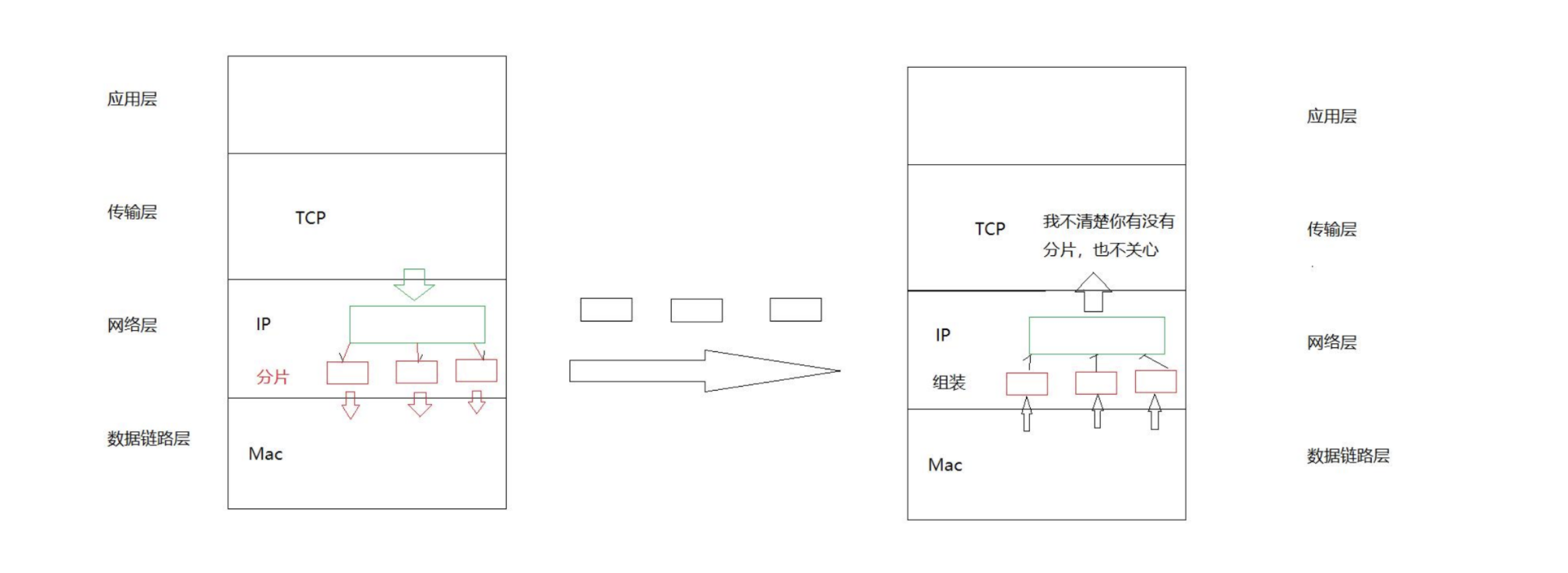
分片组装过程
• 假设在 IP 层,有一个大小为 3000 字节的报文,如何分片?如何组装呢?
假设一个 3000字节的IP数据报(包括20字节IP头部,实际数据部分为2980字节)需要通过一个 MTU(最大传输单元)为1500字节 的网络链路传输。由于MTU限制了单个IP包的大小,因此需要进行分片。以下是分片和组装的详细过程:
1. 分片过程
IP分片的规则:
- 每个分片必须包含IP头部(20字节),因此每个分片的最大数据部分 =
MTU - IP头 = 1500 - 20 = 1480字节。 - 分片偏移量(Fragment Offset)以8字节为单位,因此每个分片的数据长度必须是8的倍数(不够则填充)。
- MF(More Fragments)标志位:
MF=1:表示还有后续分片。MF=0:表示这是最后一个分片。
原始数据报
- 总长度(Total Length) = 3000字节(IP头20 + 数据2980)。
- 需要分片,因为
3000 > MTU (1500)。
分片计算
由于每个分片最多承载1480字节数据,且偏移量按8字节单位计算:
-
第1个分片:
- 数据长度 = 1480字节(满足
1480 % 8 == 0)。 - 偏移量(Fragment Offset) =
0 / 8 = 0。 - MF标志 =
1(还有后续分片)。 - 分片总长度 =
20 (IP头) + 1480 (数据) = 1500字节。 - 剩余数据 =
2980 - 1480 = 1500字节。
- 数据长度 = 1480字节(满足
-
第2个分片:
- 数据长度 = 1480字节(仍然 ≤ 1480)。
- 偏移量 =
1480 / 8 = 185。 - MF标志 =
1(仍有剩余数据)。 - 分片总长度 =
20 + 1480 = 1500字节。 - 剩余数据 =
1500 - 1480 = 20字节。
-
第3个分片:
- 数据长度 = 20字节(最后剩余部分)。
- 偏移量 =
(1480 + 1480) / 8 = 2960 / 8 = 370。 - MF标志 =
0(这是最后一个分片)。 - 分片总长度 =
20 (IP头) + 20 (数据) = 40字节。
分片结果
| 分片 | 偏移量(Fragment Offset) | MF标志 | 数据长度 | 分片总长度 |
|---|---|---|---|---|
| 1 | 0 | 1 | 1480 | 1500 |
| 2 | 185 | 1 | 1480 | 1500 |
| 3 | 370 | 0 | 20 | 40 |
2. 接收方的组装过程
接收方需要缓存所有分片,并按照以下步骤重组原始数据报:
- 识别属于同一数据报的分片:
- 所有分片的
Identification字段相同(由发送方生成,唯一标识这个数据报)。
- 所有分片的
- 检查分片是否完整:
- 第一个分片:
Offset=0,MF=1(表示有后续分片)。 - 中间分片:
Offset递增,MF=1。 - 最后一个分片:
MF=0(表示结束)。
- 第一个分片:
- 按偏移量排序并拼接数据:
- 第1个分片:数据 0~1479。
- 第2个分片:数据 1480~2959。
- 第3个分片:数据 2960~2979。
- 检查是否覆盖全部数据:
- 最后一个分片的
Offset + Length = 370×8 + 20 = 2960 + 20 = 2980,与原始数据长度一致。
- 最后一个分片的
- 重组完整IP数据报:
- 去除后续分片的IP头部,仅保留第1个分片的IP头部。
- 拼接所有数据部分,得到 3000字节的原始数据报。
- 提交给传输层(TCP/UDP):
- 传输层看到的是完整的数据报,并不知道底层进行了分片。
3. 关键点总结
- 分片由IP层完成,传输层(TCP/UDP)不感知分片。
- 接收方通过
Identification、MF、Fragment Offset判断分片关系。 - 所有分片必须全部到达才能重组,否则超时丢弃(通常30~60秒)。
- 分片影响性能(增加延迟、丢包风险),应尽量避免(如使用Path MTU Discovery)。
为什么分片偏移量以8字节为单位?
- 节省IP头部空间:
Fragment Offset字段只有13位(最大8191),以8字节为单位可表示最大8191×8=65528字节的偏移量,足够覆盖最大IP包(65535字节)。
如果某个分片丢失会怎样?
- 接收方等待超时(如30秒)后丢弃所有已收到的分片。
- 传输层(如TCP)会触发超时重传,重新发送整个数据报(而非单个分片)。
ry)。
为什么分片偏移量以8字节为单位?
- 节省IP头部空间:
Fragment Offset字段只有13位(最大8191),以8字节为单位可表示最大8191×8=65528字节的偏移量,足够覆盖最大IP包(65535字节)。
如果某个分片丢失会怎样?
- 接收方等待超时(如30秒)后丢弃所有已收到的分片。
- 传输层(如TCP)会触发超时重传,重新发送整个数据报(而非单个分片)。
IP分片机制确保了大数据报能在不同MTU的网络中传输,但应尽量避免分片以提高效率。