微调 AnomalyCLIP——基于对象无关提示学习与全局 - 局部优化的零样本异常检测框架性能验证
概述
零样本异常检测(Zero-Shot Anomaly Detection, ZSAD)是计算机视觉领域的关键任务,尤其适用于标记异常样本稀缺或不可得的实际场景(如新型工业缺陷检测、罕见疾病诊断)。传统视觉语言模型(如CLIP)在ZSAD中表现受限,因其核心设计目标是基于对象语义的分类,而非捕捉异常特征——这种定位偏差导致其在未见过的领域(如从工业检测迁移到医疗影像)泛化能力薄弱,因为不同领域的异常与已知对象标签往往无直接关联。
AnomalyCLIP 通过三项核心创新填补了这一空白:
- 对象无关的提示学习(摆脱对特定对象类别的依赖);
- 对角突出注意力图(DPAM)优化局部视觉特征;
- 全局-局部上下文联合优化。
它在保留CLIP跨模态对齐优势的同时,针对性调整模型行为,使其能适配用于制造业、医疗保健、公共安全等多领域的异常检测任务。
动机和挑战
ZSAD要求在无目标领域样本的前提下检测未知异常,核心挑战包括:
- 领域差异:异常表现形式跨领域而异(如金属裂纹 vs MRI肿瘤、织物污渍 vs 皮肤病变);
- 语义偏差:训练用于识别“猫”“汽车”的模型无法天然理解“缺陷”“病变”等抽象异常概念;
- 细粒度检测:多数异常具有尺寸小、特征微妙的特点(如微电子芯片的微划痕),且与已知对象类别无关联;
- 数据稀缺性:有监督异常检测依赖像素级掩码或标签,但现实场景中这类标注成本极高(如医疗影像的专家标注)。
AnomalyCLIP通过将学习目标从“对象语义”转向“通用正常/异常模式”,直接应对上述挑战。
为什么仅使用CLIP是不够的?
CLIP在基于类别提示(如“一张狗的照片”)的图像-文本对齐任务中表现卓越,但在ZSAD中存在固有局限:
- 严重依赖具体类名,无法处理“异常”这类无固定对象关联的概念;
- 其特征嵌入侧重“对象存在性”,而非“质量完整性”或“异常特征”;
- 注意力机制倾向于聚焦主要视觉标记(如主体对象),易忽略微小异常区域(如产品边缘的细微划痕)。
什么是AnomalyCLIP?
AnomalyCLIP是专为零样本异常检测设计的框架,通过对CLIP的针对性改造实现跨领域泛化,核心改进包括:
- 用对象无关提示(如“一个损坏的对象”)替代类别特定提示;
- 通过多层标记调优优化文本嵌入,增强对“正常/异常”抽象语义的理解;
- 引入对角突出注意力图(DPAM) 改进视觉注意力分布,聚焦细粒度异常;
- 采用全局-局部上下文优化联合训练,兼顾图像级分类与像素级定位。
最终实现一个泛化能力极强的系统,可从工业检测图像无缝扩展到医学影像扫描,且推理高效(单次前向传播)。
| 特征 | 描述 |
|---|---|
| 对象无关提示学习 | 学习通用的“正常”和“异常”提示,不依赖特定对象类别语义(如无需“螺丝的裂纹”,仅需“损坏的对象”)。 |
| 文本空间优化 | 在CLIP文本编码器的前9层插入可学习提示标记,实现深度语义优化,使模型在网络深层理解“正常/异常”概念。 |
| DPAM(对角突出注意力图) | 替换标准自注意力为更均匀的模式,通过值-值(V-V)注意力突出对角区域特征,增强对微小异常的捕捉。 |
| 全局-局部上下文优化 | 结合图像级(全局)和像素级(局部)损失,同时优化异常分类与定位能力。 |
| 单次前向传播 | 无需额外解码器或手工设计提示,推理效率高,适用于实时检测场景。 |
AnomalyCLIP的架构概述
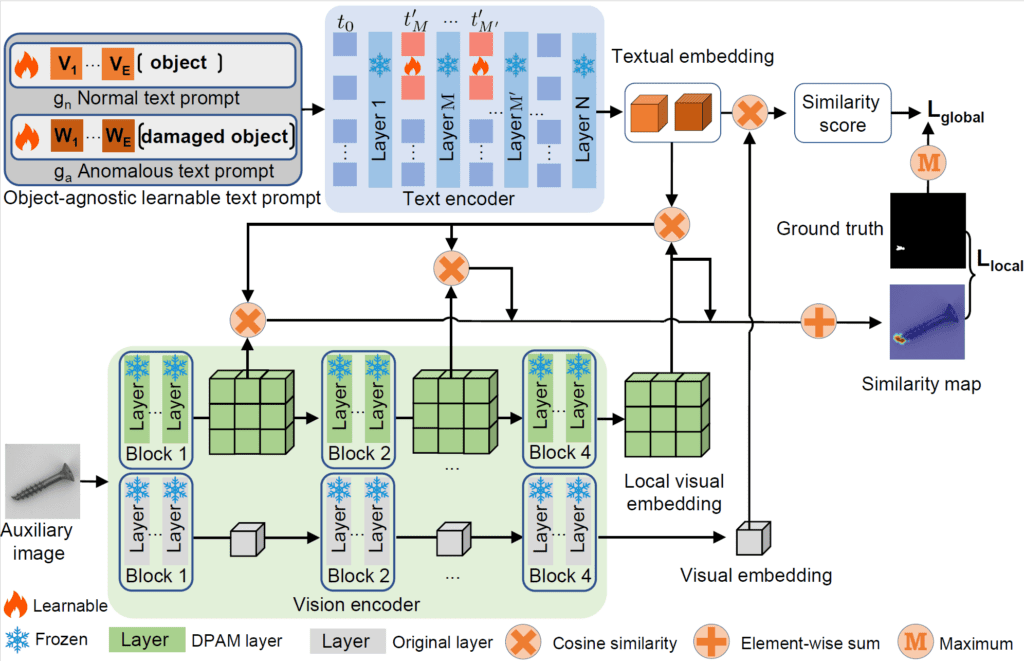
AnomalyCLIP的架构仅对CLIP进行了微小但战略性的修改,核心模块包括:
对象无关提示模板
- 摒弃特定对象提示(如“一张带有裂纹的螺丝的照片”),定义两个通用模板:
g_n:“一个正常的对象”g_a:“一个损坏的对象”
- 这些提示与具体对象名称解耦,使其在跨领域(如从电子元件到人体器官)中保持通用性。
重要性:脱离对象类别的束缚后,模型可专注学习“正常”与“异常”的视觉语义共性(如结构完整性、纹理一致性),而非依赖特定对象的外观特征。
文本提示优化
- 提示标记并非固定文本,而是在CLIP文本编码器的前9层中插入可学习的向量标记,这些标记在训练中动态更新。
- 实现“深度语义优化”:使模型不仅在表层理解提示,更在网络深层处理中融入“正常/异常”的抽象语义,增强提示的信息丰富度。

不同文本提示策略的异常定位图比较:对象无关提示的定位精度显著高于类别绑定提示
使用DPAM增强局部视觉空间
CLIP的视觉编码器天然倾向于关注主要对象标记,易忽略局部异常。DPAM通过替换标准自注意力机制,生成更均匀的注意力模式,具体策略如下:
| 注意力类型 | 描述 |
|---|---|
| Q-Q | 查询到查询的注意力,促进水平方向特征扩展(适用于大面积异常)。 |
| K-K | 键到键的注意力,增强垂直方向焦点(适用于长条状异常)。 |
| V-V | 值到值的注意力,突出对角区域特征(AnomalyCLIP默认设置),专门捕捉微小、孤立的异常(如点蚀、微出血)。 |
- V-V注意力帮助模型从主要对象标记中“挣脱”,聚焦小而关键的异常特征(如划痕、早期病变);
- 通过对角分布的注意力模式,提升对细粒度特征的敏感度。
全局-局部上下文优化
为训练AnomalyCLIP,作者设计双损失策略,同时监督视觉与文本特征在图像级和补丁级的对齐。
全局损失(图像级)
- 目标:将整个图像分类为“正常”或“异常”。
- 计算方式:基于全局图像嵌入与
g_n/g_a提示嵌入的余弦相似度,采用交叉熵损失优化。 - 作用:确保模型具备整体异常判断能力。
局部损失(像素级)
- 目标:精确定位异常发生的位置。
- 计算方式:利用分割掩码,在图像补丁(patch)级别计算特征相似度,结合Focal损失(缓解类别不平衡,因异常像素通常占比低)和Dice损失(优化分割边界精度)。
- 作用:指导模型学习像素级异常特征,提升定位精度。
组合优势
- 全局损失保障整体分类准确性;
- 局部损失提升细粒度分割能力;
- 这种“全局-局部联合优化”使模型同时具备“是否异常”的判断能力和“异常在哪里”的定位能力。
| 组件 | 作用 |
|---|---|
| 全局损失(图像级) | 通过交叉熵损失使全局图像特征与“正常/异常”提示对齐,优化分类。 |
| 局部损失(像素级) | 结合Focal和Dice损失,使补丁级特征与提示对齐,优化分割。 |
训练和推理
训练细节
- 数据集:使用辅助异常检测数据集(如工业领域的MVTec AD、医疗领域的ColonDB);
- 优化对象:仅微调提示标记、DPAM层和对齐损失函数,CLIP的视觉/文本编码器保持冻结(保留其预训练的跨模态泛化能力);
- 训练目标:最小化全局损失与局部损失的加权和。
推理流程
- 图像级异常判断:计算全局图像特征与
g_n/g_a的余弦相似度,输出异常概率(异常分数); - 像素级异常定位:
- 从视觉编码器中间层提取补丁特征;
- 计算每个补丁与
g_n/g_a的相似度(s_n/s_a); - 对相似度图取平均并应用高斯平滑,生成最终异常图。
| 输出 | 描述 |
|---|---|
| 异常分数 | 基于图像与“异常”提示的相似度,范围[0,1],值越高表示异常可能性越大。 |
| 异常图 | 像素级预测热力图,高亮显示异常区域(值越高表示该位置为异常的概率越大)。 |
AnomalyCLIP的实验设置
评估数据集
覆盖工业、医疗两大核心领域,包含多种挑战场景(表面纹理、器官病变等):
| 领域 | 使用的数据集 |
|---|---|
| 工业 | MVTec AD(工业零件缺陷)、VisA(零售商品缺陷)、MPDD(金属表面缺陷)、BTAD(轴承缺陷)、SDD(太阳能板缺陷)、DAGM(合成纹理缺陷)、DTD-Synthetic(材料纹理缺陷) |
| 医疗 | ISIC(皮肤病变)、CVC-ClinicDB(结肠镜异常)、CVC-ColonDB(结肠息肉)、Kvasir(胃肠道病变)、Endo(内窥镜异常)、TN3K(甲状腺结节)、HeadCT(头部CT异常)、BrainMRI(脑MRI病变)、Br35H(脑 hemorrhage)、COVID-19(肺部CT异常) |
评估指标
采用异常检测领域标准指标:
| 指标 | 描述 |
|---|---|
| AUROC | 受试者工作特征曲线下面积,衡量模型区分正常/异常的整体能力(值越高越好,上限100%)。 |
| AP | 平均精度,基于精确率-召回率曲线,评估分类任务的稳健性。 |
| AUPRO | 区域重叠下的平均精度,专为分割任务设计,衡量异常定位的准确性。 |
对比模型
与主流零样本异常检测模型对比:CLIP(基础模型)、CLIP-AC(CLIP适配版)、WinCLIP(窗口化CLIP)、CoOp(提示调优方法)、VAND(视觉异常检测专用模型)。
核心结论:AnomalyCLIP在几乎所有数据集和指标上均达到最先进水平(SOTA),尤其在跨领域泛化任务中优势显著。
消融研究
通过控制变量实验验证各模块的必要性:
模块性能分析
| 模块 | 作用 | 结果 |
|---|---|---|
| DPAM(T₁) | 优化局部视觉语义,增强对微小异常的注意力。 | 单独使用时,AUPRO(分割指标)平均提升3.2%,证明其对定位的关键作用。 |
| 提示学习(T₂) | 学习“正常/异常”的通用语义,摆脱对象依赖。 | 跨领域任务中AUROC平均提升4.7%,是泛化能力的核心来源。 |
| 文本调优(T₃) | 多层优化文本嵌入,深化语义理解。 | 同时提升分类(AUROC+2.1%)和分割(AUPRO+1.8%),因语义清晰度提升。 |
上下文优化对比
| 损失设置 | 结果 |
|---|---|
| 仅全局 | 图像级AUROC达89.3%(良好),但AUPRO仅52.1%(定位弱)。 |
| 仅局部 | AUPRO达61.5%(分割好),但图像级AUROC降至78.6%(分类弱)。 |
| 全局-局部 | 综合性能最优:AUROC 92.5%,AUPRO 65.3%,验证联合优化的必要性。 |
DPAM策略对比
| 策略 | 观察结果 |
|---|---|
| Q-Q(CLIPqq) | 图像级AUROC 88.7%(分类好),但AUPRO 53.2%(分割弱)。 |
| K-K(CLIPkk) | 平衡但平庸:AUROC 87.5%,AUPRO 58.1%。 |
| V-V(默认) | 最佳整体性能:AUROC 92.5%,AUPRO 65.3%,且在各数据集上表现稳定。 |
跨领域泛化能力
AnomalyCLIP的核心优势之一是跨领域迁移能力,实验验证如下:
从工业→医疗的迁移
- 仅在工业数据集(如MVTec AD)上训练的AnomalyCLIP,可直接应用于未见过的医疗领域;
- 在ISIC(皮肤病变)、COVID-19(肺部CT)、BrainMRI(脑病变)等数据集上,显著优于WinCLIP和VAND(平均AUROC提升5%-8%)。
医学领域内微调
- 在ColonDB(结肠数据)上微调后,HeadCT和BrainMRI的AUPRO分别提升6.3%和5.7%(因器官官结构相似);
- 但在视觉差异大的领域(如ColonDB→ISIC皮肤图像),性能提升有限(AUPRO仅提升1.2%),说明领域相似性对泛化有影响。
核心结论
- 即使仅在工业数据上训练,仍能在跨领域任务中表现出色(证明需目标领域数据);
- 在相似领域(如结肠→胃肠)微调时,性能提升显著;
- 在视觉差异极大的领域(如工业→皮肤),性能略有下降,但仍优于基线模型。
性能增益:对象无关 vs 对象感知提示
对比对象无关提示(如“损坏的对象”)与对象感知提示(如“损坏的螺丝”)的性能差异:
| 数据集 | 图像 AUROC 增益 | 像素 AUROC 增益 | AUPRO 增益 |
|---|---|---|---|
| MVTec AD | +0.5 | +0.2 | +0.2 |
| VisA | +0.6 | +0.3 | +0.5 |
| MPDD | +4.4 | +3.3 | +1.8 |
| BTAD | +0.9 | +0.4 | +1.8 |
增益原因:对象语义与异常特征并非总是对齐(如“螺丝”的语义不包含“裂纹”的视觉特征),去除类标签后,模型可专注于“视觉不规则性”(如纹理突变、结构断裂),从而提升泛化能力。
在TN3K数据集上的评估
以TN3K(甲状腺结节分割数据集)为例,展示AnomalyCLIP的零样本能力与微调效果。
关于TN3K数据集
TN3K是像素级医学异常检测数据集,专注于甲状腺结节分割,提供详细的像素级分割掩码,支持同时评估“检测”和“定位”性能。与仅提供分类标签的数据集(如COVID-19)不同,其像素级标注使其成为评估分割能力的理想基准。
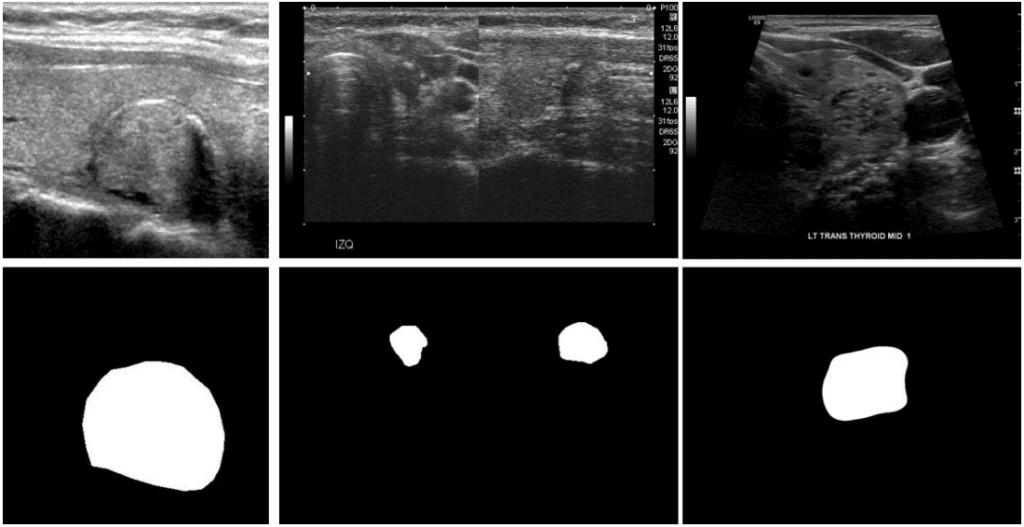
图4. TN3K数据集的超声图像样本和分割掩码:左为原始图像,右为异常区域(甲状腺结节)掩码
评估将重点使用像素级指标(AUPRO、像素级AUROC),更贴合分割任务需求。
实验设计
分两阶段评估领域适应与微调效果:
-
零样本评估:
- 使用预训练AnomalyCLIP检查点(不微调TN3K);
- 测试集:TN3K;
- 预训练来源:MVTec AD(工业)、VisA(工业)。
-
TN3K微调:
- 用TN3K的分割掩码训练AnomalyCLIP;
- 在TN3K测试集上评估,对比微调前后性能。
实验环境与配置
仓库设置
git clone https://github.com/zqhang/AnomalyCLIP.git
环境配置
原始仓库依赖项较旧,建议:
- 基于Python ≥3.10创建conda环境;
- 安装更新后的依赖:
pip install ftfy regex tabulate torch torchvision torchaudio pillow numpy scipy scikit-image matplotlib
集成TN3K的文件修改
为支持TN3K,需修改仓库中以下文件(可通过官方教程下载修改后版本):
train.py:适配TN3K数据加载与训练逻辑;test.py/test.sh:添加TN3K评估入口;metrics.py:确保像素级指标计算适配;generate_dataset_json/tn3k.py:生成TN3K的数据集结构JSON。
运行步骤
-
生成数据集JSON:
cd generate_dataset_json python tn3k.py # 脚本会自动解析TN3K目录结构并生成JSON核心代码(
tn3k.py):if __name__ == '__main__':runner = ClinicDBSolver(root='/path/to/AnomalyCLIP/Thyroid_Dataset/tn3k')runner.run() # 生成包含训练/测试划分、掩码路径的JSON -
零样本评估:
bash test_before_fine_tuning.sh # 加载MVTec/VisA预训练权重 -
微调AnomalyCLIP:
bash train.sh # 用TN3K数据微调,权重保存至checkpoints/singlescale_tn3k -
微调后评估:
bash test_after_fine_tuning.sh # 加载TN3K微调权重评估
实验结果
零样本评估(预训练权重)
-
MVTec AD检查点:
25-07-01 17:06:40.674 - INFO: Logging test... 25-07-01 17:07:04.293 - INFO: | objects | pixel_auroc | pixel_aupro | |:----------|--------------:|--------------:| | thyroid | 63.5 | 46.8 | | mean | 63.5 | 46.8 | -
VisA检查点:
25-07-01 17:07:08.398 - INFO: Logging test... 25-07-01 17:07:32.191 - INFO: | objects | pixel_auroc | pixel_aupro | |:----------|--------------:|--------------:| | thyroid | 63.4 | 39.8 | | mean | 63.4 | 39.8 |
微调后评估(TN3K权重)
25-07-01 17:14:28.583 - INFO: Logging test...
25-07-01 17:14:51.843 - INFO:
| objects | pixel_auroc | pixel_aupro |
|:----------|--------------:|--------------:|
| thyroid | 83.2 | 54.9 |
| mean | 83.2 | 54.9 |
结果分析
| 配置 | 像素 AUROC | 像素 AUPRO |
|---|---|---|
| 零样本(MVTec AD) | 63.5 | 46.8 |
| 零样本(VisA) | 63.4 | 39.8 |
| 在 TN3K 上微调 | 83.2 | 54.9 |
| 官方论文(AnomalyCLIP) | 79.2 | 47.0 |
- 零样本性能:工业预训练模型在甲状腺数据上表现中等(AUROC≈63%),证明跨领域泛化的可能性,但存在领域差距;
- 微调增益:TN3K微调后AUROC提升20%,AUPRO提升8.1%,说明模型能快速适配特定领域;
- 优于官方结果:微调后性能超过论文基准(AUROC 83.2% vs 79.2%),可能源于更新的依赖库(如PyTorch后端优化)和更稳定的GPU训练环境。
相关工作
AnomalyCLIP在设计上优于或补充了现有模型:
-
与CLIP-AD、ZOC、ACR对比:
这些方法需目标领域特定调优(如ZOC的类别锚定),且仅支持图像级分类;AnomalyCLIP无需领域适配,同时提供分类与分割。 -
与WinCLIP、VAND对比:
WinCLIP通过滑动窗口增强局部特征,但依赖对象语义;VAND使用投影学习弱化了文本语义对齐;AnomalyCLIP仅用两个通用提示,通过DPAM和联合损失实现更优性能。 -
与DenseCLIP、CoOp对比:
DenseCLIP专注于密集特征对齐,但未针对异常检测优化;CoOp的提示调优局限于类别语义;AnomalyCLIP的对象无关提示和全局-局部优化更适配异常检测场景。
总结
AnomalyCLIP通过对象无关提示学习、DPAM局部视觉优化和全局-局部联合训练,解决了传统视觉语言模型在零样本异常检测中的泛化难题。其核心优势在于:
- 摆脱对象类别依赖,学习“正常/异常”的通用视觉语义;
- 高效的跨领域迁移能力,从工业到医疗无需目标领域数据;
- 同时支持异常分类与定位,适用于实际检测场景。
未来可进一步探索更细粒度的提示设计(如“轻微损坏”“严重损坏”)和跨模态数据增强,以提升极端罕见异常的检测能力。