矿物分类案列 (一)六种方法对数据的填充
目录
矿物数据项目介绍:
数据问题与处理方案:
数据填充策略讨论:
模型选择与任务类型:
模型训练计划:
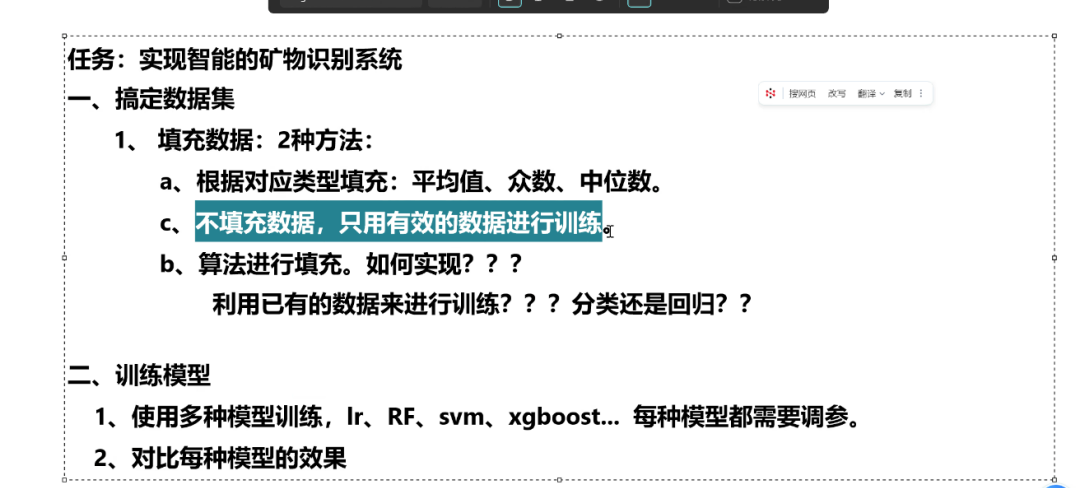
一.数据集填充
1.读取数据
2.把标签转化为数值
3.把异常数据转化为nan
4.数据Z标准化
5.划分训练集测试集
6.创建一个新的fill_data.py文件,用来存放填充训练数据和填充测试数据的方法
方法①:删除有缺失值的行
方法②:平均值填充处理(测试集用训练集对应的平均值来填充)
方法③:中位数填充处理(测试集用训练集对应的中位数来填充)
方法④:众数填充处理(测试集用训练集对应的众数来填充)
7.调用填充方法,生成各自方法填充后的数据,并保存到各自的excel文件中
矿物数据项目介绍:
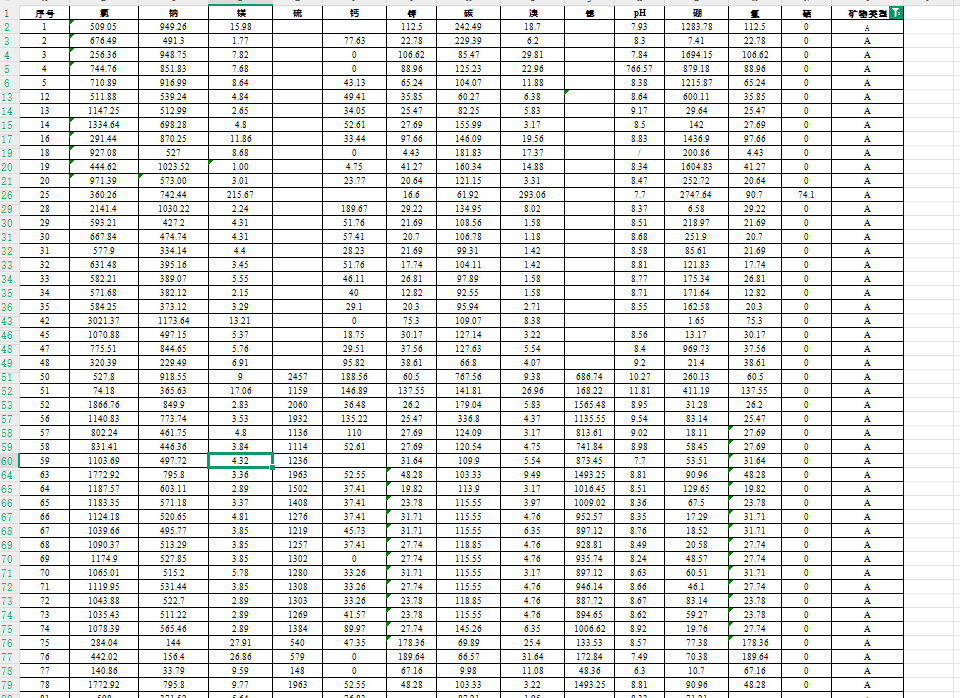
数据类型:每行记录矿物微量元素(氯、钠、镁等)及类别(A/B/C/D/E)(注意:发现类别 E 仅有一条数据,无法用于模型训练,所以我们应该删除该数据)
任务目标:构建分类模型,通过微量元素自动识别矿物类型(A/B/C/D)
数据问题与处理方案:
异常值:如“7.97”(应为7.97)、“41.12”(应为41.12)等输入错误,需手动修正。
缺失值填充:
方法A:按类别分组填充(如A类用A类均值/众数/中位数)。
方法B:智能填充(如逻辑回归、随机森林等算法预测缺失值)。
特征工程:特征数量较少(约10个),无需降维。
发现数据中存在隐藏空格(如“思”列),导致NaN检测失败,需手动清理空格干扰。
其他问题:斜杠(如PH值列)、单一类别数据列(如“异”列)需删除或特殊处理。
数据填充策略讨论:
优先填充缺失值最少的列(如F列仅缺3个值),以增加完整数据量,便于后续预测其他列(如K列)。
填充顺序:从缺失少的列到缺失多的列,以提高填充准确性。
强调利用已有数据(包括部分缺失的数据)进行训练,而非仅依赖完全完整的数据。
模型选择与任务类型:
确定当前任务为回归问题(因预测目标Y为连续型数据)。
可用回归模型包括:SVR(SVM变体)、KNN、随机森林、线性回归等。
模型训练计划:
多模型对比:尝试逻辑回归、随机森林、支持向量机、XGBoost等,调参后评估效果(准确率、召回率等)。
步骤:
数据预处理(清洗、填充缺失值)。
分模型训练与调参(交叉验证)。
生成对比表格,选择最优模型。
=========================================================================
下面我们先用四种方法来填充数据分别是删除空白数据行处理,平均值填充处理,中位数填充处理,众数填充处理
一.数据集填充
部分数据如下
1.读取数据
删除仅有一行数据的‘E’类数据,并删除无关列‘序号’
import pandas as pd
data=pd.read_excel('矿物数据.xlsx')
data=data[data['矿物类型']!='E']
data=data.drop('序号',axis=1)
x_whole=data.iloc[:,:-1]
y_whole=data.iloc[:,-1]2.把标签转化为数值
把矿物类型A,B,C,D类转化成机器可读的数字1,2,3,4
labels_dict={'A':1,'B':2,'C':3,'D':4}
en_labels=[labels_dict[label] for label in data['矿物类型']]
y_whole=pd.Series(en_labels,name='矿物类型')3.把异常数据转化为nan
用pandas库将可以转化为数字类型的数据转化为数字,不能转化的数据写为nan
# 异常数据转化为nan
for column_name in x_whole.columns:x_whole[column_name]=pd.to_numeric(x_whole[column_name],errors='coerce')4.数据Z标准化
#对数据Z标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
X_whole_Z=scaler.fit_transform(x_whole)
X_whole_Z=pd.DataFrame(X_whole_Z,columns=x_whole.columns)5.划分训练集测试集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(X_whole_Z,y_whole)6.创建一个新的fill_data.py文件,用来存放填充训练数据和填充测试数据的方法
方法①:删除有缺失值的行
import pandas as pd
#只保留完整数据集
def cca_train_fill(x_train,y_train):data=pd.concat([x_train,y_train],axis=1)data=data.reset_index(drop=True)data=data.dropna()return data.iloc[:,:-1],data.iloc[:,-1]
def cca_test_fill(x_test,y_test):data=pd.concat([x_test,y_test],axis=1)data=data.reset_index(drop=True)data=data.dropna()return data.iloc[:,:-1],data.iloc[:,-1]方法②:平均值填充处理(测试集用训练集对应的平均值来填充)
由于每一类的平均值都要分开处理所以我们先将每一类分别提取出来
def mean_train_fill(x_train,y_train):data=pd.concat([x_train,y_train],axis=1)data=data.reset_index(drop=True)A=data[data['矿物类型']==1]B=data[data['矿物类型']==2]C=data[data['矿物类型']==3]D=data[data['矿物类型']==4]A=mean_method_train(A)B=mean_method_train(B)C=mean_method_train(C)D=mean_method_train(D)data=pd.concat([A,B,C,D])return data.drop('矿物类型',axis=1),data['矿物类型']
def mean_test_fill(x_train,y_train,x_test,y_test):data_train = pd.concat([x_train, y_train], axis=1)data_train = data_train.reset_index(drop=True)A_train = data_train[data_train['矿物类型'] == 1]B_train = data_train[data_train['矿物类型'] == 2]C_train = data_train[data_train['矿物类型'] == 3]D_train = data_train[data_train['矿物类型'] == 4]data_test = pd.concat([x_test, y_test], axis=1)data_test = data_test.reset_index(drop=True)A_test = data_test[data_test['矿物类型'] == 1]B_test = data_test[data_test['矿物类型'] == 2]C_test = data_test[data_test['矿物类型'] == 3]D_test = data_test[data_test['矿物类型'] == 4]A_test=mean_method_test(A_train,A_test)B_test = mean_method_test(B_train, B_test)C_test = mean_method_test(C_train,C_test)D_test = mean_method_test(D_train, D_test)data = pd.concat([A_test, B_test, C_test, D_test])return data.drop('矿物类型', axis=1), data['矿物类型']def mean_method_train(data):fill_values=data.mean()data=data.fillna(fill_values)return data
def mean_method_test(train_data,test_data):fill_values=train_data.mean()test_data=test_data.fillna(fill_values)return test_data方法③:中位数填充处理(测试集用训练集对应的中位数来填充)
def median_train_fill(x_train,y_train):data = pd.concat([x_train, y_train], axis=1)data = data.reset_index(drop=True)A = data[data['矿物类型'] == 1]B = data[data['矿物类型'] == 2]C = data[data['矿物类型'] == 3]D = data[data['矿物类型'] == 4]A = median_method_train(A)B = median_method_train(B)C = median_method_train(C)D = median_method_train(D)data = pd.concat([A, B, C, D])return data.drop('矿物类型', axis=1), data['矿物类型']
def median_test_fill(x_train,y_train,x_test,y_test):data_train = pd.concat([x_train, y_train], axis=1)data_train = data_train.reset_index(drop=True)A_train = data_train[data_train['矿物类型'] == 1]B_train = data_train[data_train['矿物类型'] == 2]C_train = data_train[data_train['矿物类型'] == 3]D_train = data_train[data_train['矿物类型'] == 4]data_test = pd.concat([x_test, y_test], axis=1)data_test = data_test.reset_index(drop=True)A_test = data_test[data_test['矿物类型'] == 1]B_test = data_test[data_test['矿物类型'] == 2]C_test = data_test[data_test['矿物类型'] == 3]D_test = data_test[data_test['矿物类型'] == 4]A_test=median_method_test(A_train,A_test)B_test = median_method_test(B_train, B_test)C_test = median_method_test(C_train,C_test)D_test = median_method_test(D_train, D_test)data = pd.concat([A_test, B_test, C_test, D_test])return data.drop('矿物类型', axis=1), data['矿物类型']
def median_method_train(data):fill_values = data.median()data = data.fillna(fill_values)return data
def median_method_test(train_data,test_data):fill_values=train_data.median()test_data=test_data.fillna(fill_values)return test_data方法④:众数填充处理(测试集用训练集对应的众数来填充)
def mode_train_fill(x_train,y_train): data = pd.concat([x_train, y_train], axis=1)data = data.reset_index(drop=True)A = data[data['矿物类型'] == 1]B = data[data['矿物类型'] == 2]C = data[data['矿物类型'] == 3]D = data[data['矿物类型'] == 4]A = mode_method_train(A)B = mode_method_train(B)C = mode_method_train(C)D = mode_method_train(D)data = pd.concat([A, B, C, D])return data.drop('矿物类型', axis=1), data['矿物类型']
def mode_test_fill(x_train,y_train,x_test,y_test):data_train = pd.concat([x_train, y_train], axis=1)data_train = data_train.reset_index(drop=True)A_train = data_train[data_train['矿物类型'] == 1]B_train = data_train[data_train['矿物类型'] == 2]C_train = data_train[data_train['矿物类型'] == 3]D_train = data_train[data_train['矿物类型'] == 4]data_test = pd.concat([x_test, y_test], axis=1)data_test = data_test.reset_index(drop=True)A_test = data_test[data_test['矿物类型'] == 1]B_test = data_test[data_test['矿物类型'] == 2]C_test = data_test[data_test['矿物类型'] == 3]D_test = data_test[data_test['矿物类型'] == 4]A_test=mode_method_test(A_train,A_test)B_test = mode_method_test(B_train, B_test)C_test = mode_method_test(C_train,C_test)D_test = mode_method_test(D_train, D_test)data = pd.concat([A_test, B_test, C_test, D_test])return data.drop('矿物类型', axis=1), data['矿物类型']
def mode_method_train(data):fill_values = data.apply(lambda x: x.mode().iloc[0] if len(x.mode())>0 else None)data = data.fillna(fill_values)return data
def mode_method_test(train_data,test_data):fill_values=train_data.apply(lambda x: x.mode().iloc[0] if len(x.mode())>0 else None)test_data=test_data.fillna(fill_values)return test_data
7.调用填充方法,生成各自方法填充后的数据,并保存到各自的excel文件中
由于训练集样本不平衡,我们采用smote过采样来平衡数据
import fill_data
#1.删除空白数据行处理
# x_train_fill,y_train_fill=fill_data.cca_train_fill(x_train,y_train)
# x_test_fill,y_test_fill=fill_data.cca_train_fill(x_test,y_test)
#2.平均值填充处理
# x_train_fill,y_train_fill=fill_data.mean_train_fill(x_train,y_train)
# x_test_fill,y_test_fill=fill_data.mean_test_fill(x_train_fill,y_train_fill,x_test,y_test)
#中位数填充处理
# x_train_fill,y_train_fill=fill_data.median_train_fill(x_train,y_train)
# x_test_fill,y_test_fill=fill_data.median_test_fill(x_train_fill,y_train_fill,x_test,y_test)
# 众数填充处理
x_train_fill,y_train_fill=fill_data.mode_train_fill(x_train,y_train)
x_test_fill,y_test_fill=fill_data.mode_test_fill(x_train_fill,y_train_fill,x_test,y_test)
#smote拟合数据
from imblearn.over_sampling import SMOTE
oversample=SMOTE(k_neighbors=1,random_state=42)#保证数据拟合效果,随机种子
x_train_fill,y_train_fill=oversample.fit_resample(x_train_fill,y_train_fill)#数据存入excel
train_data=pd.concat([y_train_fill,x_train_fill],axis=1)
train_data.to_excel('训练集[众数填充].xlsx',index=False)
test_data=pd.concat([y_test_fill,x_test_fill],axis=1)