java基础(十)sql的mvcc
一、事务特性与实现原理
1. ACID特性详解
| 特性 | 说明 | 实现机制 | 生活案例 |
|---|---|---|---|
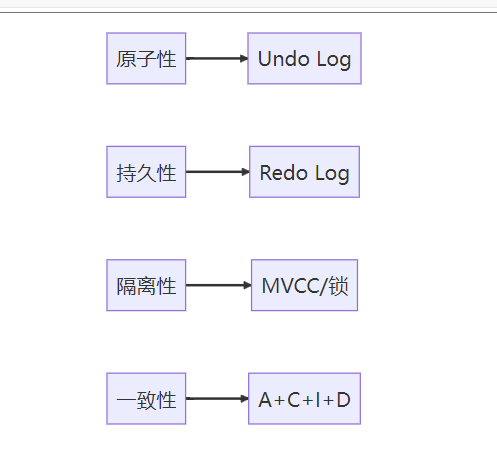
| 原子性 | 事务操作要么全部成功,要么全部回滚 | Undo Log | 网购:支付成功则商品发货,支付失败则资金退回 |
| 一致性 | 事务前后数据库保持完整性约束 | ACID共同保证 | 转账:A账户-200、B账户+200后,总额保持不变 |
| 隔离性 | 并发事务相互隔离,互不干扰 | MVCC/锁机制 | 电影院售票:多个售票窗口同时卖票不会出售同一座位 |
| 持久性 | 事务提交后数据永久存储,故障不丢失 | Redo Log | 银行存钱:柜台确认存款后,即使断电记录也不会丢失 |
2. 事务实现机制
Undo Log:记录数据修改前的状态,用于事务回滚
-- 更新前记录旧值到Undo Log UPDATE users SET balance=800 WHERE id=1; -- Undo Log: {id:1, balance:1000}Redo Log:记录物理修改,确保故障恢复
/* 修改流程: 1. 内存更新Buffer Pool 2. 写Redo Log: "pageX offsetY更新为800" 3. 后台刷脏页到磁盘 */
二、并发问题与解决方案
1. 三大并发问题
| 问题类型 | 现象描述 | 案例场景 |
|---|---|---|
| 脏读 | 读取到未提交的临时数据 | 财务系统看到未提交的工资调整,导致报表错误 |
| 不可重复读 | 同事务内两次读取结果不一致 | 机票查询:第一次看到余票3张,付款时提示余票0 |
| 幻读 | 同条件查询返回的记录数不同 | 统计在线用户:第一次10人,刷新后变成12人 |
2. 隔离级别对比
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 实现方式 |
|---|---|---|---|---|
| 读未提交(Read Uncommitted) | ✓ | ✓ | ✓ | 直接读最新数据 |
| 读已提交(Read Committed) | ✗ | ✓ | ✓ | 每次SELECT前生成Read View |
| 可重复读(Repeatable Read) | ✗ | ✗ | △ | 事务开始生成Read View |
| 串行化(Serializable) | ✗ | ✗ | ✗ | 读写锁阻塞访问 |
注:MySQL默认隔离级别为可重复读,能解决幻读大部分场景
3. 幻读特殊场景示例
-- 事务A(YA33操作)
BEGIN;
SELECT * FROM orders WHERE amount>1000; -- 返回0条
-- 事务B插入并提交
INSERT INTO orders VALUES(5,2000,'B');
-- 事务A尝试更新"不存在"的数据
UPDATE orders SET user='YA33' WHERE amount>1000; -- 影响1行
SELECT * FROM orders WHERE amount>1000; -- 出现幻读!解决方案:对关键操作使用锁定读
SELECT * FROM orders WHERE amount>1000 FOR UPDATE; -- 加Next-Key Lock三、MVCC多版本并发控制
1. 核心组件
| 组件 | 作用 |
|---|---|
| Read View | 事务的数据快照 |
| trx_id | 记录最后修改事务ID的隐藏列(当前的事务被那个id维护) |
| roll_pointer | 指向Undo Log旧版本链的指针(指向你的老数据) |
2. Read View工作流程
首先read view 维护了四个关键的数据
当前事务的id
未提交事务id(维护很多已经开始未提交,安升序排序)
未开始事务id
========================================================================
当一个读取事务进来,与最小的活跃事务id进行比较,小就读,不小就继续
然后与最大的事务id进行比较,大就不读,小就继续
判断是否与本身的事务id相等,相等就读,不相等就继续
判断是否在活跃事务列表里面,在就不读,不在就读
3. 不同隔离级别的Read View
读已提交:每次SELECT生成新Read View
可重复读:首次SELECT生成Read View,整个事务复用
四、锁机制深度剖析
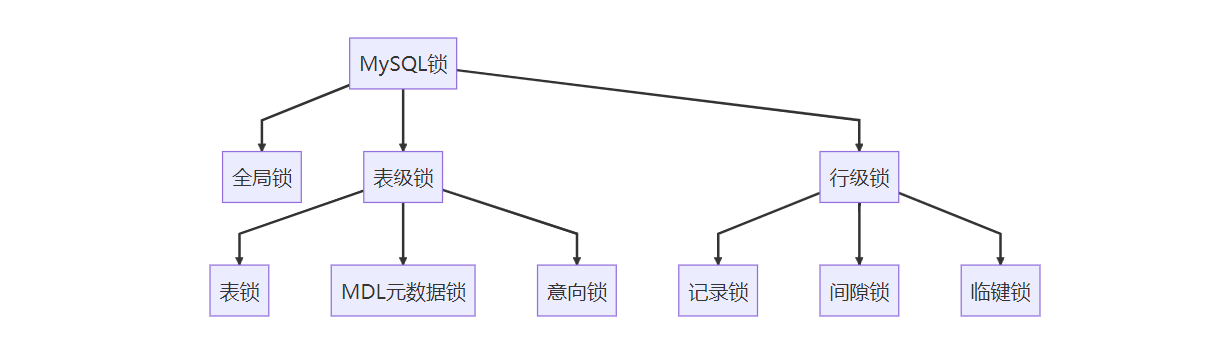
1. 锁类型全景
2. 行锁冲突矩阵
| X(排他锁) | S(共享锁) | |
|---|---|---|
| X锁 | 冲突 | 冲突 |
| S锁 | 冲突 | 兼容 |
3. 锁优化实践
场景1:范围更新不阻塞
-- 事务A(YA33操作)
UPDATE users SET score=score+1 WHERE id<10; -- 锁(-∞,10)
-- 事务B
UPDATE users SET vip=1 WHERE id>15; -- 锁(15,+∞) 不冲突场景2:无索引全表锁
-- 无索引字段更新导致全表锁
UPDATE products SET status=0 WHERE name LIKE '%清仓%'; -- 慎用!五、日志系统工作原理
1. 日志类型对比
| 日志类型 | 层级 | 作用 | 关键特性 |
|---|---|---|---|
| Redo Log | 存储引擎层 | 故障恢复 | 物理日志,顺序写 |
| Undo Log | 存储引擎层 | 事务回滚/MVCC | 逻辑日志,链式存储 |
| Binlog | Server层 | 主从复制/数据恢复 | 逻辑日志,三种格式 |
| Relay Log | Server层 | 从库中转主库Binlog | 临时中转日志 |
2. Binlog三种格式
| 格式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| STATEMENT | 日志量小 | 函数结果可能不一致 | 简单SQL |
| ROW | 数据绝对一致 | 日志量大 | 数据安全要求高 |
| MIXED | 自动选择最优模式 | 切换策略复杂 | 通用场景 |
3. 两阶段提交流程
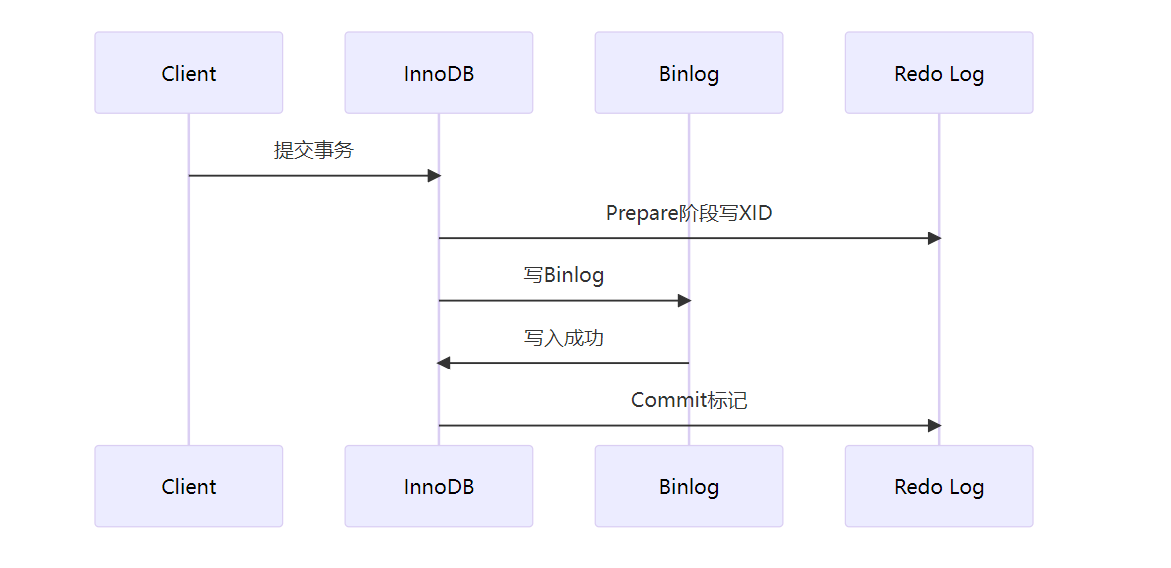
崩溃恢复规则:
发现Prepare的Redo Log:检查Binlog
Binlog存在 → 提交事务
Binlog不存在 → 回滚事务
六、性能调优实战
1. EXPLAIN关键字段解读
EXPLAIN SELECT * FROM users WHERE name='YA33';| 字段 | 值 | 优化建议 |
|---|---|---|
| type | ref | 理想范围:const/ref/range |
| key | idx_name | 实际使用索引名 |
| rows | 1 | 扫描行数越少越好 |
| Extra | Using index | 出现Using filesort需优化 |
2. 常见优化方案
场景1:深分页优化
-- 低效写法
SELECT * FROM logs ORDER BY id LIMIT 1000000,10;
-- 高效写法(YA33操作)
SELECT * FROM logs WHERE id>1000000 ORDER BY id LIMIT 10;场景2:索引失效避免
- SELECT * FROM users WHERE YEAR(create_time)=2023; -- 索引失效
+ SELECT * FROM users WHERE create_time BETWEEN '2023-01-01' AND '2023-12-31';3. 强制索引使用
-- 优化器选错索引时干预
SELECT /*+ INDEX(products idx_price) */ *
FROM products FORCE INDEX(idx_price)
WHERE price BETWEEN 100 AND 500;七、高可用架构
1. 主从复制流程

2. 分库分表策略
| 拆分方式 | 特点 | 适用场景 |
|---|---|---|
| 垂直分库 | 按业务拆分(订单/用户) | 业务耦合度低 |
| 水平分库 | 数据分片到不同服务器 | 单库性能瓶颈 |
| 垂直分表 | 大表拆小表(商品+商品详情) | 字段访问频率差异大 |
| 水平分表 | 单表数据拆分(按用户ID取模) | 单表数据量超大 |
示例:订单表分片
-- 原始表
CREATE TABLE orders (id BIGINT, user_id INT, amount DECIMAL);
-- 分片后(YA33的user_id=12345)
INSERT INTO orders_5 (user_id,amount) VALUES (12345,99.9);
-- 分片规则: user_id % 10 = 5 → orders_5通过全面理解MySQL的事务机制、锁策略、日志系统及优化技巧,可构建高性能高可用的数据库架构。在实际应用中,需根据业务场景灵活选择隔离级别、锁机制和分片策略,如YA33在处理金融交易时应采用串行化隔离级别,而在用户日志分析场景可使用读已提交级别提升并发性能。