CVPR2 2025丨大模型创新技巧:文档+语音+视频“大模型三件套”
关注gongzhonghao【CVPR顶会精选】
近两年,大模型在计算机视觉领域的应用热度持续攀升,相关研究成果在CVPR不断涌现。其核心的自注意力机制,能更为灵活地捕捉图像中的全局信息和长距离依赖关系,突破了传统卷积神经网络局部感受野的限制,为解决复杂的视觉问题提供了全新的思路与方法。这些前沿研究成果极具研读价值,为推动CV领域发展注入新动力。
今天小图给大家精选3篇CVPR有关大模型方向的论文,请注意查收!
论文一:Relation-Rich Visual Document Generator for Visual Information Extraction
方法:
文章首先通过内容生成阶段,利用LLM生成具有实体类别和关系的层次结构文本。然后在布局生成阶段,采用自监督学习方法,仅使用OCR结果作为输入,训练模型生成与内容匹配的多样化布局。最后,通过层次结构学习训练范式,将生成的文档用于训练文档理解模型,显著提升了模型在多个VIE基准测试上的性能。
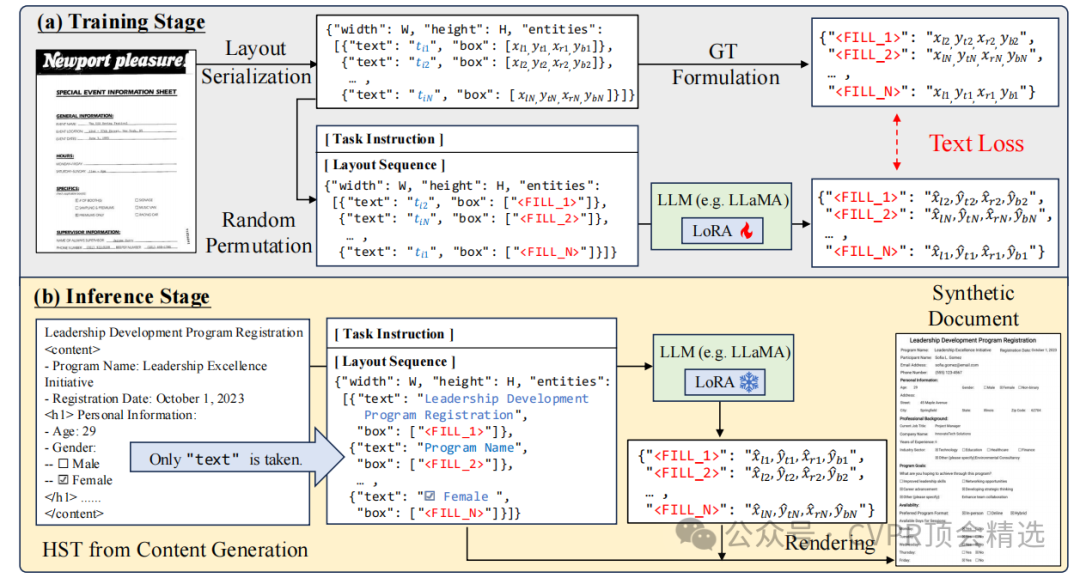
创新点:
提出了首个能够自动合成关系丰富且带有注释的视觉文档的方法,有效解决了现有数据集规模小、标注成本高以及布局多样性不足的问题。
采用两阶段方法:内容生成阶段利用LLM生成包含实体类别和关系的层次结构文本,布局生成阶段通过自监督学习仅依赖OCR结果生成合理布局,无需人工标注。
引入HSL训练范式,通过解析文档的层次结构来增强模型对文档布局和内容关系的理解,进一步提升模型在VIE任务上的性能。

论文链接:
https://arxiv.org/abs/2504.10659
图灵学术论文辅导
论文二:SilVar-Med: A Speech-Driven Visual Language Model for Explainable Abnormality Detection in Medical Imaging
方法:
文章首先通过语音编码器提取语音特征,结合医学图像编码器和大型语言模型,构建了SilVar-Med模型,使其能够处理语音和图像输入并生成推理文本响应。接着,采用两阶段训练方法以增强模型的异常检测和推理能力。最后,通过传统的文本生成评估指标和提出的LLM评估框架,全面评估了SilVar-Med的性能,验证了其在推理和准确性方面的优势。
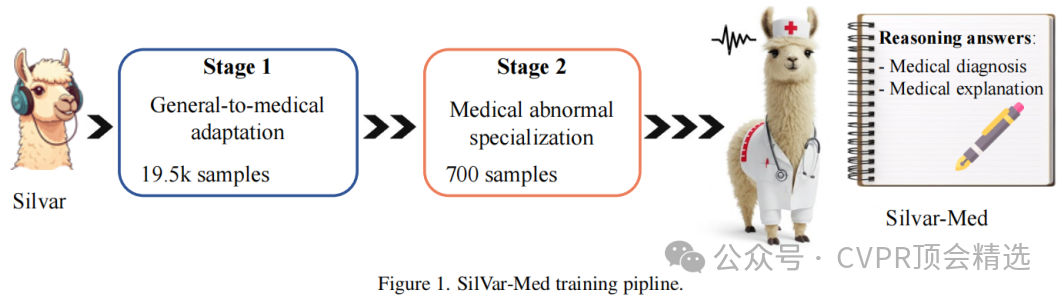
创新点:
提出首个语音驱动的医学视觉语言模型,能够通过语音指令与用户进行交互,显著提升了医疗领域人机交互的便捷性和实用性。
引入了一个针对语音指令医学异常检测的推理数据集,专门用于训练和测试模型的推理能力,填补了该领域的数据空白。
提出了一个基于LLM的推理评估框架,更全面地评估了模型的推理能力,超越了传统的文本相似性评估方法。

论文链接:
https://arxiv.org/abs/2504.10642
图灵学术论文辅导
论文三:GLUS: Global-Local Reasoning Unified into A Single Large Language Model for Video Segmentation
方法:
文章首先将视频帧分为上下文帧和查询帧,上下文帧提供全局信息,查询帧用于局部对象跟踪,从而统一了全局和局部推理。接着,通过端到端训练将预训练的VOS记忆模块与多模态大型语言模型结合,增强了对长期时间信息的处理能力。最后,引入对象对比学习来区分不同对象,并通过自精炼框架识别关键帧,进一步优化了模型的推理能力。

创新点:
提出了全局-局部统一推理框架GLUS,通过设计上下文帧和查询帧,将全局和局部信息融合到单一的视频分割模型中。
引入了端到端优化的VOS记忆模块,增强了模型对长期历史信息的理解,从而提高了局部和全局推理能力。
提出了对象对比学习和自精炼框架,通过区分硬假阳性对象和识别关键帧,进一步提升了模型的性能。
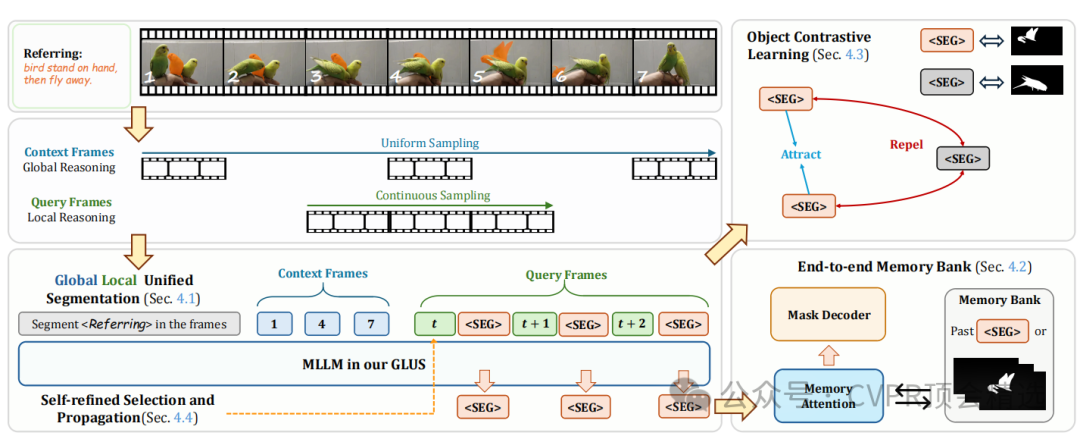
论文链接:
https://arxiv.org/abs/2504.07962
本文选自gongzhonghao【CVPR顶会精选】